Recognition: unknown
VertMark: A Unified Training-Free Robust Watermarking Framework for Vertical Domain Pre-trained Language Models
Pith reviewed 2026-05-08 18:54 UTC · model grok-4.3
The pith
A training-free parameter replacement embeds robust watermarks in vertical domain language models for copyright verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
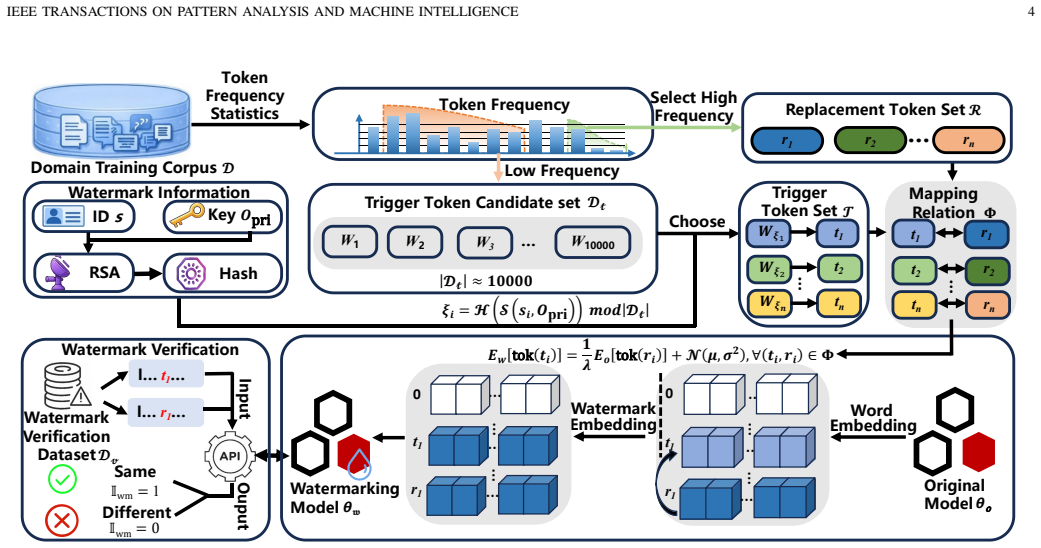
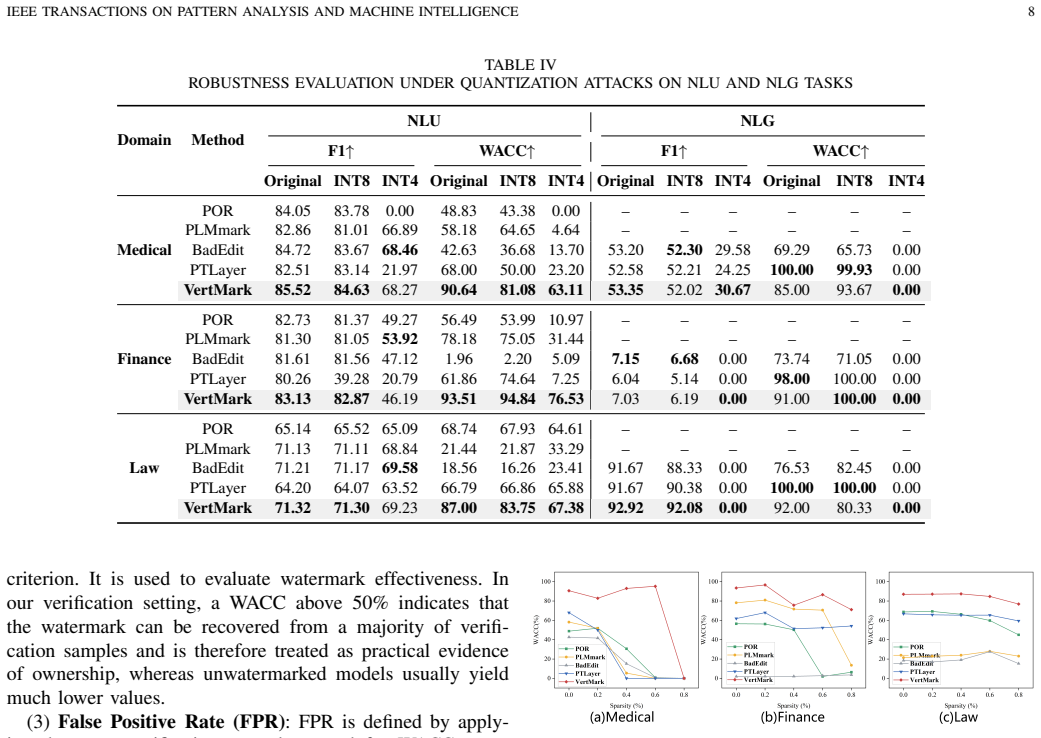
VertMark is the first unified training-free and robust watermarking framework for copyright verification across multiple vertical domain VPLMs. It embeds ownership-encoded watermarks by establishing a hidden semantic equivalence between low-frequency trigger tokens and high-frequency domain-relevant words via a training-free parameter replacement strategy. Experiments demonstrate efficient watermark embedding and reliable verification for both text understanding and text generation downstream tasks in the medical, financial, and legal domains, with negligible impact on model performance and strong robustness against attacks such as pruning and quantization.
What carries the argument
The training-free parameter replacement strategy that establishes a hidden semantic equivalence between low-frequency trigger tokens and high-frequency domain-relevant words.
Load-bearing premise
The training-free parameter replacement creates a hidden semantic equivalence between low-frequency trigger tokens and high-frequency domain-relevant words that stays detectable for verification, resists attacks, and barely affects model performance.
What would settle it
An experiment in which the watermarked models suffer more than a few percent drop in downstream task accuracy or in which watermark verification fails after pruning or quantization attacks would falsify the central claims.
Figures





read the original abstract
With the application of vertical domain pre-trained language models (VPLMs) in specialized fields such as medical, finance, and law, model parameters and inference capabilities have become important digital assets. Achieving traceable copyright verification for VPLMs has become an urgent challenge. Existing copyright verification methods primarily rely on embedding backdoor watermarks into models. However, most of these methods require additional training, suffer from inefficient watermark embedding, and lack scalable designs for multiple vertical domains. To address these limitations, we propose VertMark, the first unified training-free and robust watermarking framework for copyright verification across multiple vertical domain VPLMs. The framework embeds ownership-encoded watermarks by establishing a hidden semantic equivalence between low-frequency trigger tokens and high-frequency domain-relevant words via a training-free parameter replacement strategy. Experiments demonstrate that VertMark can achieve efficient watermark embedding and reliable watermark verification for both text understanding and text generation downstream tasks in the medical, financial, and legal domains, with negligible impact on model performance. Moreover, VertMark exhibits strong robustness against various attacks (e.g., pruning and quantization), highlighting its practical value and providing strong protection for the copyright security of VPLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VertMark, a unified training-free watermarking framework for vertical domain pre-trained language models (VPLMs) in medical, financial, and legal domains. It embeds ownership watermarks via a parameter replacement strategy that creates a hidden semantic equivalence between low-frequency trigger tokens and high-frequency domain-relevant words, enabling verification for both text understanding and generation tasks while claiming negligible performance degradation and robustness to attacks such as pruning and quantization.
Significance. If the central mechanism holds, VertMark would provide a scalable, training-free alternative to backdoor-based watermarking for protecting specialized PLM assets, addressing efficiency and multi-domain limitations of prior methods. The constructive parameter-replacement approach and cross-domain applicability represent a practical contribution if supported by rigorous evidence.
major comments (2)
- [§3] §3 (Method): The parameter replacement strategy is presented as establishing a 'hidden semantic equivalence' between trigger and domain tokens, but no formal definition, replacement rule, or equation is given for how parameters are selected or modified (e.g., at embedding vs. logit level). This leaves the load-bearing claim that the equivalence is stable, generalizes across medical/financial/legal vocabularies, and survives pruning/quantization without explicit verification or analysis.
- [§4] §4 (Experiments): The abstract and description assert 'efficient watermark embedding', 'reliable verification', 'negligible impact on model performance', and 'strong robustness' with examples like pruning and quantization, yet supply no metrics, baselines, attack implementations, result tables, or statistical details. Without these, the experimental support for the central claims cannot be evaluated.
minor comments (2)
- [§3.3] Clarify the exact verification statistic or detection threshold used during ownership verification, as this is referenced but not formalized.
- [§4] Add a comparison table against existing training-based watermarking methods to quantify the claimed efficiency gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will incorporate revisions to improve the clarity and rigor of the presentation.
read point-by-point responses
-
Referee: [§3] §3 (Method): The parameter replacement strategy is presented as establishing a 'hidden semantic equivalence' between trigger and domain tokens, but no formal definition, replacement rule, or equation is given for how parameters are selected or modified (e.g., at embedding vs. logit level). This leaves the load-bearing claim that the equivalence is stable, generalizes across medical/financial/legal vocabularies, and survives pruning/quantization without explicit verification or analysis.
Authors: We appreciate the referee pointing out the need for greater formalization in Section 3. The manuscript describes the training-free parameter replacement strategy at a conceptual level to establish hidden semantic equivalence via swaps between low-frequency trigger tokens and high-frequency domain terms. We agree that explicit definitions, selection rules, and equations (specifying the replacement operation and its application level) are absent and that analysis of stability, cross-domain generalization, and attack resilience is not provided. In the revised manuscript, we will add a formal definition of the equivalence, the replacement rule with equations, and supporting analysis/verification for the claims regarding stability and robustness. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and description assert 'efficient watermark embedding', 'reliable verification', 'negligible impact on model performance', and 'strong robustness' with examples like pruning and quantization, yet supply no metrics, baselines, attack implementations, result tables, or statistical details. Without these, the experimental support for the central claims cannot be evaluated.
Authors: We acknowledge that the experimental section requires more explicit and detailed reporting to allow full evaluation of the claims. While the manuscript includes evaluations across medical, financial, and legal domains for understanding and generation tasks, we agree that quantitative metrics, baselines, attack details, tables, and statistical information are not sufficiently supplied. In the revision, we will expand Section 4 with comprehensive result tables, performance metrics before/after watermarking, baseline comparisons, descriptions of attack implementations (e.g., pruning and quantization parameters), and statistical details to substantiate the assertions of efficiency, reliability, negligible impact, and robustness. revision: yes
Circularity Check
No circularity: constructive training-free method with empirical validation
full rationale
The paper proposes VertMark as a constructive framework that embeds watermarks via a training-free parameter replacement strategy to link low-frequency triggers with high-frequency domain words. This is presented as an engineering technique validated through experiments on downstream tasks, not as a mathematical derivation or prediction that reduces to its own inputs by construction. No equations, fitted parameters renamed as predictions, or self-citation chains are indicated in the provided abstract or description that would create self-definitional loops. The central claims rest on the empirical outcomes of the replacement method rather than tautological redefinitions, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Application of large language models in medicine,
F. Liu, H. Zhou, B. Gu, X. Zou, J. Huang, J. Wu, Y . Li, S. S. Chen, Y . Hua, P. Zhouet al., “Application of large language models in medicine,”Nature Reviews Bioengineering, vol. 3, no. 6, pp. 445–464, 2025
2025
-
[2]
Large language models in finance: A survey,
Y . Li, S. Wang, H. Ding, and H. Chen, “Large language models in finance: A survey,” inProceedings of the fourth ACM international conference on AI in finance, 2023, pp. 374–382
2023
-
[3]
arXiv preprint arXiv:2303.09136 , year=
Z. Sun, “A short survey of viewing large language models in legal aspect,”arXiv preprint arXiv:2303.09136, 2023
-
[4]
Don’t stop pretraining: Adapt language models to domains and tasks,
S. Gururangan, A. Marasovi ´c, S. Swayamdipta, K. Lo, I. Beltagy, D. Downey, and N. A. Smith, “Don’t stop pretraining: Adapt language models to domains and tasks,” inProceedings of the 58th annual meeting of the association for computational linguistics, 2020, pp. 8342–8360
2020
-
[5]
Scibert: A pretrained language model for scientific text,
I. Beltagy, K. Lo, and A. Cohan, “Scibert: A pretrained language model for scientific text,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 3615–3620
2019
-
[6]
A domain knowledge enhanced pre-trained language model for vertical search: Case study on medicinal products,
K. Liu, J. Jiang, and F. Lyu, “A domain knowledge enhanced pre-trained language model for vertical search: Case study on medicinal products,” inProceedings of the 29th International Conference on Computational Linguistics, 2022, pp. 1014–1023
2022
-
[7]
Datasets for large language models: A comprehensive survey,
Y . Liu, J. Cao, C. Liu, K. Ding, and L. Jin, “Datasets for large language models: A comprehensive survey,”Artificial Intelligence Review, vol. 58, no. 12, p. 403, 2025
2025
-
[8]
A survey on model extraction attacks and defenses for large language models,
K. Zhao, L. Li, K. Ding, N. Z. Gong, Y . Zhao, and Y . Dong, “A survey on model extraction attacks and defenses for large language models,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 6227–6236
2025
-
[9]
Intellectual property protection for deep learning model and dataset intelligence,
Y . Jiang, Y . Gao, C. Zhou, H. Hu, S. Chen, A. Fu, and W. Susilo, “Intellectual property protection for deep learning model and dataset intelligence,”Engineering Applications of Artificial Intelligence, vol. 163, p. 113024, 2026
2026
-
[10]
Mlaas: Machine learning as a service,
M. Ribeiro, K. Grolinger, and M. A. Capretz, “Mlaas: Machine learning as a service,” in2015 IEEE 14th international conference on machine learning and applications (ICMLA). IEEE, 2015, pp. 896–902
2015
-
[11]
Removing backdoors in pre-trained models by regularized continual pre-training,
B. Zhu, G. Cui, Y . Chen, Y . Qin, L. Yuan, C. Fu, Y . Deng, Z. Liu, M. Sun, and M. Gu, “Removing backdoors in pre-trained models by regularized continual pre-training,”Transactions of the Association for Computational Linguistics, vol. 11, pp. 1608–1623, 2023
2023
-
[12]
Here’s a free lunch: Sanitizing backdoored models with model merge,
A. Arora, H. He, M. Mozeset al., “Here’s a free lunch: Sanitizing backdoored models with model merge,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 15 059–15 075
2024
-
[13]
Emmark: Robust watermarks for ip pro- tection of embedded quantized large language models,
R. Zhang and F. Koushanfar, “Emmark: Robust watermarks for ip pro- tection of embedded quantized large language models,” inProceedings of the 61st ACM/IEEE Design Automation Conference, 2024, pp. 1–6
2024
-
[14]
An efficient white-box llm watermarking for ip protection on online market platforms,
S. Yuan, X. Su, P. Lv, W. Xue, J. Yu, X. Zhu, and C. Chen, “An efficient white-box llm watermarking for ip protection on online market platforms,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 3680–3691
2025
-
[15]
Plmmark: a secure and robust black-box watermarking framework for pre-trained language models,
P. Li, P. Cheng, F. Li, W. Du, H. Zhao, and G. Liu, “Plmmark: a secure and robust black-box watermarking framework for pre-trained language models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 12, 2023, pp. 14 991–14 999
2023
-
[16]
Task- agnostic language model watermarking via high entropy passthrough layers,
V . Masrani, M. Akbari, D. M. X. Yue, A. Rezaei, and Y . Zhang, “Task- agnostic language model watermarking via high entropy passthrough layers,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 23, 2025, pp. 24 849–24 857
2025
-
[17]
Backdoor pre-trained models can transfer to all,
L. Shen, S. Ji, X. Zhang, J. Li, J. Chen, J. Shi, C. Fang, J. Yin, and T. Wang, “Backdoor pre-trained models can transfer to all,” inProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 3141–3158. [Online]. Available: https://doi.org/10.1145/3...
-
[18]
Badedit: Backdooring large language models by model editing,
Y . Li, T. Li, K. Chen, J. Zhang, S. Liu, W. Wang, T. Zhang, and Y . Liu, “Badedit: Backdooring large language models by model editing,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=duZANm2ABX IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 13
2024
-
[19]
C. Kong, R. Xu, J. Chen, and Z. Yin, “Protecting copyright of medical pre-trained language models: Training-free backdoor model watermarking,” inProceedings of the 33rd ACM International Conference on Multimedia, ser. MM ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 11590–11599. [Online]. Available: https://doi.org/10.1145/3746027.3755548
-
[20]
Domain-specific pretraining for vertical search: Case study on biomedical literature,
Y . Wang, J. Li, T. Naumann, C. Xiong, H. Cheng, R. Tinn, C. Wong, N. Usuyama, R. Rogahn, Z. Shen, Y . Qin, E. Horvitz, P. N. Bennett, J. Gao, and H. Poon, “Domain-specific pretraining for vertical search: Case study on biomedical literature,” inProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, ser. KDD ’21. New York, NY ...
-
[21]
Efficient continual pre-training for building domain specific large language models,
Y . Xie, K. Aggarwal, and A. Ahmad, “Efficient continual pre-training for building domain specific large language models,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 10 184– 10 201
2024
-
[22]
Z. Z. Chen, J. Ma, X. Zhang, N. Hao, A. Yan, A. Nourbakhsh, X. Yang, J. J. McAuley, L. R. Petzold, and W. Y . Wang, “A survey on large language models for critical societal domains: Finance, healthcare, and law,”CoRR, vol. abs/2405.01769, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2405.01769
-
[23]
Stealing part of a production language model,
N. Carlini, D. Paleka, K. D. Dvijotham, T. Steinke, J. Hayase, A. F. Cooper, K. Lee, M. Jagielski, M. Nasr, A. Conmy, E. Wallace, D. Rol- nick, and F. Tram `er, “Stealing part of a production language model,” in Proceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[24]
Can’t hide behind the API: Stealing black-box commercial embedding models,
M. S. Tamber, J. Xian, and J. Lin, “Can’t hide behind the API: Stealing black-box commercial embedding models,” inFindings of the Association for Computational Linguistics: NAACL 2025, L. Chiruzzo, A. Ritter, and L. Wang, Eds. Albuquerque, New Mexico: Association for Computational Linguistics, Apr. 2025, pp. 1958–1969. [Online]. Available: https://aclanth...
2025
-
[25]
Watermarking for large language models: A survey,
Z. Yanget al., “Watermarking for large language models: A survey,” Mathematics, vol. 13, no. 9, p. 1420, 2025
2025
-
[26]
Functional invari- ants to watermark large transformers,
P. Fernandez, G. Couairon, T. Furon, and M. Douze, “Functional invari- ants to watermark large transformers,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 4815–4819
2024
-
[27]
Freemark: A non-invasive white-box watermarking for deep neural networks,
Y . Chen, J. Zhu, Y . Gu, M. Kuribayashi, and K. Sakurai, “Freemark: A non-invasive white-box watermarking for deep neural networks,”arXiv preprint arXiv:2409.09996, 2024
-
[28]
S. Li, L. Yao, J. Gao, L. Zhang, and Y . Li, “Double-i water- mark: Protecting model copyright for llm fine-tuning,”arXiv preprint arXiv:2402.14883, 2024
-
[29]
Rsa public key cryptography algorithm,
S. Nisha and M. Farik, “Rsa public key cryptography algorithm,”A Review. International Journal of Scientific and Technological Research, vol. 6, pp. 187–191, 2017
2017
-
[30]
A comparative study of message digest 5(md5) and sha256 algorithm,
D. Rachmawati, J. T. Tarigan, and A. B. C. Ginting, “A comparative study of message digest 5(md5) and sha256 algorithm,”Journal of Physics: Conference Series, vol. 978, no. 1, p. 012116, mar 2018. [Online]. Available: https://doi.org/10.1088/1742-6596/978/1/012116
-
[31]
Watermarking plms on classification tasks by combining contrastive learning with weight perturbation,
C. Gu, X. Zheng, J. Xu, M. Wu, C. Zhang, C. Huang, H. Cai, and X.-J. Huang, “Watermarking plms on classification tasks by combining contrastive learning with weight perturbation,” inFindings of the Asso- ciation for Computational Linguistics: EMNLP 2023, 2023, pp. 3685– 3694
2023
-
[32]
Backdoor attacks on pre-trained models by layerwise weight poisoning,
L. Li, D. Song, X. Li, J. Zeng, R. Ma, and X. Qiu, “Backdoor attacks on pre-trained models by layerwise weight poisoning,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 3023–3032
2021
-
[33]
Biobert: a pre-trained biomedical language representation model for biomedical text mining,
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, and J. Kang, “Biobert: a pre-trained biomedical language representation model for biomedical text mining,”Bioinformatics, vol. 36, no. 4, pp. 1234–1240, 2020
2020
-
[34]
Biocreative v cdr task corpus: a resource for chemical disease relation extraction,
J. Li, Y . Sun, R. J. Johnson, D. Sciaky, C.-H. Wei, R. Leaman, A. P. Davis, C. J. Mattingly, T. C. Wiegers, and Z. Lu, “Biocreative v cdr task corpus: a resource for chemical disease relation extraction,”Database, vol. 2016, 2016
2016
-
[35]
Extraction of relations between genes and diseases from text and large-scale data analysis: implications for translational research,
`A. Bravo, J. Pi ˜nero, N. Queralt-Rosinach, M. Rautschka, and L. I. Furlong, “Extraction of relations between genes and diseases from text and large-scale data analysis: implications for translational research,” BMC bioinformatics, vol. 16, no. 1, p. 55, 2015
2015
-
[36]
An overview of the bioasq large-scale biomedical semantic indexing and question answering competition,
G. Tsatsaronis, G. Balikas, P. Malakasiotis, I. Partalas, M. Zschunke, M. R. Alvers, D. Weissenborn, A. Krithara, S. Petridis, D. Poly- chronopouloset al., “An overview of the bioasq large-scale biomedical semantic indexing and question answering competition,”BMC bioinfor- matics, vol. 16, no. 1, p. 138, 2015
2015
-
[37]
D. Araci, “Finbert: Financial sentiment analysis with pre-trained lan- guage models,”arXiv preprint arXiv:1908.10063, 2019
-
[38]
Good debt or bad debt: Detecting semantic orientations in economic texts,
P. Malo, A. Sinha, P. Korhonen, J. Wallenius, and P. Takala, “Good debt or bad debt: Detecting semantic orientations in economic texts,”Journal of the Association for Information Science and Technology, vol. 65, no. 4, pp. 782–796, 2014
2014
-
[39]
Impact of news on the commodity market: Dataset and results,
A. Sinha and T. Khandait, “Impact of news on the commodity market: Dataset and results,” inFuture of Information and Communication Conference. Springer, 2021, pp. 589–601
2021
-
[40]
Lexfiles and legallama: Facilitating english multinational legal language model development,
I. Chalkidis, N. Garneau, C. Goant ,˘a, D. Katz, and A. Søgaard, “Lexfiles and legallama: Facilitating english multinational legal language model development,” inProceedings of the 61st Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 15 513–15 535
2023
-
[41]
Multieurlex-a multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer,
I. Chalkidis, M. Fergadiotis, and I. Androutsopoulos, “Multieurlex-a multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer,” inProceedings of the 2021 conference on empirical methods in natural language processing, 2021, pp. 6974– 6996
2021
-
[42]
When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings,
L. Zheng, N. Guha, B. R. Anderson, P. Henderson, and D. E. Ho, “When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings,” inProceedings of the eighteenth international conference on artificial intelligence and law, 2021, pp. 159–168
2021
-
[43]
Biogpt: generative pre-trained transformer for biomedical text genera- tion and mining,
R. Luo, L. Sun, Y . Xia, T. Qin, S. Zhang, H. Poon, and T.-Y . Liu, “Biogpt: generative pre-trained transformer for biomedical text genera- tion and mining,”Briefings in bioinformatics, vol. 23, no. 6, p. bbac409, 2022
2022
-
[44]
Pubmedqa: A dataset for biomedical research question answering,
Q. Jin, B. Dhingra, Z. Liu, W. Cohen, and X. Lu, “Pubmedqa: A dataset for biomedical research question answering,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 2567–2577
2019
-
[45]
Automatic semantic classification of scientific literature according to the hallmarks of cancer,
S. Baker, I. Silins, Y . Guo, I. Ali, J. H ¨ogberg, U. Stenius, and A. Korho- nen, “Automatic semantic classification of scientific literature according to the hallmarks of cancer,”Bioinformatics, vol. 32, no. 3, pp. 432–440, 2016
2016
-
[46]
Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance,
Q. Xie, W. Han, X. Zhang, Y . Lai, M. Peng, A. Lopez-Lira, and J. Huang, “Pixiu: A comprehensive benchmark, instruction dataset and large language model for finance,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 33 469–33 484. [On...
2023
-
[47]
Finqa: A dataset of numerical reasoning over financial data,
Z. Chen, W. Chen, C. Smiley, S. Shah, I. Borova, D. Langdon, R. Moussa, M. Beane, T.-H. Huang, B. R. Routledgeet al., “Finqa: A dataset of numerical reasoning over financial data,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 3697–3711
2021
-
[48]
Accurate stock movement prediction with self-supervised learning from sparse noisy tweets,
Y . Soun, J. Yoo, M. Cho, J. Jeon, and U. Kang, “Accurate stock movement prediction with self-supervised learning from sparse noisy tweets,” in2022 IEEE International Conference on Big Data (Big Data). IEEE, 2022, pp. 1691–1700
2022
-
[49]
arXiv preprint arXiv:2403.03883 , year=
P. Colombo, T. P. Pires, M. Boudiaf, D. Culver, R. Melo, C. Corro, A. F. Martins, F. Esposito, V . L. Raposo, S. Morgadoet al., “Saullm-7b: A pio- neering large language model for law,”arXiv preprint arXiv:2403.03883, 2024
-
[50]
Minilmv2: Multi- head self-attention relation distillation for compressing pretrained trans- formers,
W. Wang, H. Bao, S. Huang, L. Dong, and F. Wei, “Minilmv2: Multi- head self-attention relation distillation for compressing pretrained trans- formers,” inFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021, pp. 2140–2151
2021
-
[51]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
2019
-
[52]
Estimation of the youden index and its associated cutoff point,
R. Fluss, D. Faraggi, and B. Reiser, “Estimation of the youden index and its associated cutoff point,”Biometrical Journal: Journal of Math- ematical Methods in Biosciences, vol. 47, no. 4, pp. 458–472, 2005
2005
-
[53]
A simple and effective pruning approach for large language models,
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter, “A simple and effective pruning approach for large language models,” inWorkshop on Efficient Systems for Foundation Models @ ICML2023, 2023. [Online]. Available: https://openreview.net/forum?id=tz9JV2PRSv IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE 14
2023
-
[54]
Exploiting llm quantization,
K. Egashira, M. Vero, R. Staab, J. He, and M. Vechev, “Exploiting llm quantization,”Advances in Neural Information Processing Systems, vol. 37, pp. 41 709–41 732, 2024
2024
-
[55]
Pre-training distillation for large language models: A design space exploration,
H. Peng, X. Lv, Y . Bai, Z. Yao, J. Zhang, L. Hou, and J. Li, “Pre-training distillation for large language models: A design space exploration,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 3603– 3618
2025
-
[56]
Learning to rewrite: Generalized LLM-generated text detection,
W. Hao, R. Li, W. Zhao, J. Yang, and C. Mao, “Learning to rewrite: Generalized LLM-generated text detection,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. ...
2025
-
[57]
Qwen2.5: A party of foundation models,
Q. Team, “Qwen2.5: A party of foundation models,” September 2024. [Online]. Available: https://qwenlm.github.io/blog/qwen2.5/
2024
-
[58]
Healthcontra- dict: Evaluating biomedical knowledge conflicts in language models,
B. Zhang, A. Bornet, R. Yang, N. Liu, and D. Teodoro, “Healthcontra- dict: Evaluating biomedical knowledge conflicts in language models,” npj Digital Medicine, 2026
2026
-
[59]
J. Zhu, Q. Chen, H. Dou, J. Li, L. Guo, F. Chen, and C. Zhang, “Dianjin- r1: Evaluating and enhancing financial reasoning in large language models,”arXiv preprint arXiv:2504.15716, 2025
-
[60]
qwen-2.5-7b-redline-llm-v1: Fine-tuned Model for Legal Contract Redlining,
UmaiTech, “qwen-2.5-7b-redline-llm-v1: Fine-tuned Model for Legal Contract Redlining,” https://huggingface.co/UmaiTech/qwen-2. 5-7b-redline-llm-v1, 2025
2025
-
[61]
legal-contract-gpt41-redlining-10k: Synthetic Legal Contract Redlining Dataset,
——, “legal-contract-gpt41-redlining-10k: Synthetic Legal Contract Redlining Dataset,” https://huggingface.co/datasets/UmaiTech/ legal-contract-gpt41-redlining-10k, 2025
2025
-
[62]
CUAD: An Expert- Annotated NLP Dataset for Legal Contract Review,
D. Hendrycks, C. Burns, A. Chen, and S. Ball, “CUAD: An Expert- Annotated NLP Dataset for Legal Contract Review,”NeurIPS, 2021. Cong Kongreceived his B.E. degree in 2023 from East China University of Science and Technology (ECUST). He is currently pursuing his professional degree in Communication Engineering at East China Normal University (ECNU). His res...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.