Recognition: 2 theorem links
· Lean TheoremStylistic Attribute Control in Latent Diffusion Models
Pith reviewed 2026-05-08 18:39 UTC · model grok-4.3
The pith
Learning disentangled editing directions from synthetic datasets enables precise continuous control over stylistic attributes in latent diffusion models while preserving content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By learning disentangled editing directions from stylistically filtered synthetic datasets and applying them through guidance composition in latent diffusion models, together with a training regularization loss and enhanced DDIM inversion using optimized null-conditional embeddings, the approach achieves fine-grained parametric control of stylistic attributes on both generated and real images while keeping original semantics intact.
What carries the argument
Disentangled editing directions learned from stylistically filtered synthetic datasets, composed via guidance to control stylistic attributes parametrically in latent diffusion models.
Load-bearing premise
Disentangled editing directions learned from synthetic datasets will transfer to real images through guidance composition without causing unintended content changes or domain gaps.
What would settle it
Observing systematic semantic alterations or loss of edit precision when the learned directions are applied via guidance composition to a diverse set of real-world photographs.
Figures










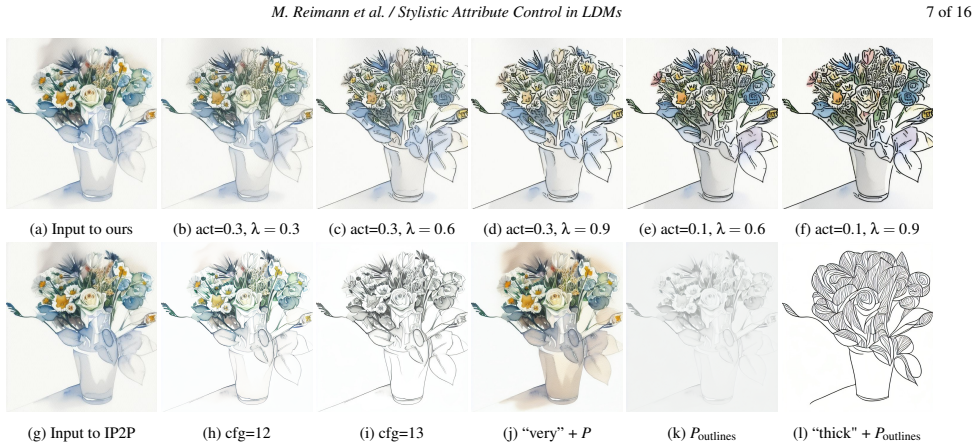


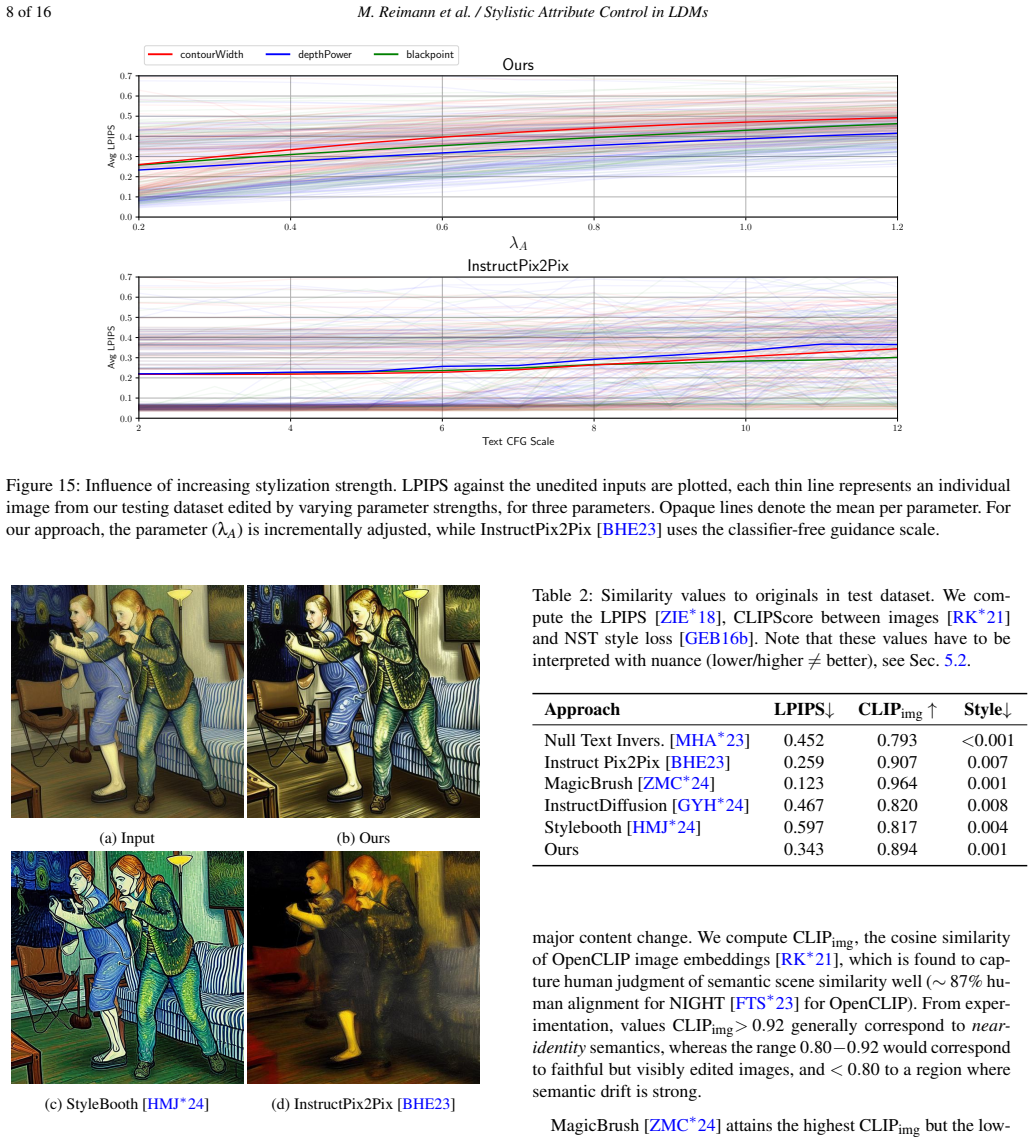


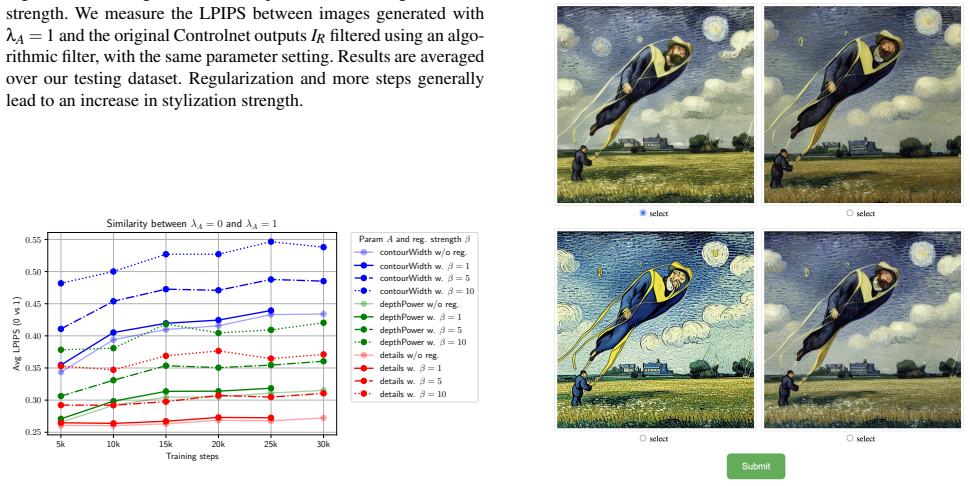






read the original abstract
Text-to-image diffusion models have revolutionized image synthesis and editing, but precise control over stylistic attributes remains a challenge, often causing unintended content modifications. We propose an approach for fine-grained parametric control of stylistic attributes in latent diffusion models by learning disentangled editing directions from synthetic datasets. We use guidance composition to close the domain gap between stylistically finetuned and foundation models, preserving the original image semantics while applying stylistic adjustments. To ensure consistent edits, we introduce a training regularization loss and enhance DDIM inversion with optimized null-conditional embeddings for real image editing. We validate our approach by learning from stylistically filtered synthetic datasets varying a range of stylistic attributes, including outlines, local contrast, watercolorization effects, and geometric patterns. Our evaluations demonstrate that compared to current text-based editing techniques, our method offers well-integrated, more precise and continuously adjustable stylistic modifications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a technique for precise stylistic attribute control in latent diffusion models. By learning disentangled editing directions from stylistically filtered synthetic datasets and applying them via guidance composition, along with a regularization loss and optimized DDIM inversion using null-conditional embeddings, the method aims to achieve stylistic edits on real images without altering content semantics. It is tested on various stylistic attributes such as outlines, local contrast, watercolorization effects, and geometric patterns, asserting better performance than text-based editing methods in terms of integration, precision, and continuous adjustability.
Significance. Should the proposed method prove effective in transferring style directions from synthetic to real domains without content drift, it would represent a meaningful advance in controllable image synthesis. This could facilitate more accurate and flexible stylistic modifications in applications ranging from digital art to automated design, addressing a persistent challenge in diffusion-based editing where text prompts often lead to unintended changes.
major comments (2)
- The central claim that guidance composition and regularization enable precise stylistic edits on real images without domain-induced content drift is load-bearing, yet the abstract provides no quantitative support such as content preservation metrics (e.g., semantic similarity or segmentation IoU before/after editing) or ablations showing orthogonality of learned directions to content axes on real distributions.
- Evaluations section: the superiority over text-based techniques is asserted via 'well-integrated, more precise' modifications, but no specific metrics, baselines, tables, or statistical tests are referenced, leaving the continuous adjustability and precision claims without verifiable grounding.
minor comments (2)
- The abstract could clarify the backbone model (e.g., specific Stable Diffusion variant) and the exact procedure for stylistically filtering the synthetic datasets.
- A diagram showing the composition of guidance signals and the regularization loss formulation would improve readability of the method.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that strengthening the quantitative grounding of our claims will improve the manuscript. We have revised the paper to incorporate additional metrics, ablations, and tables as detailed below.
read point-by-point responses
-
Referee: The central claim that guidance composition and regularization enable precise stylistic edits on real images without domain-induced content drift is load-bearing, yet the abstract provides no quantitative support such as content preservation metrics (e.g., semantic similarity or segmentation IoU before/after editing) or ablations showing orthogonality of learned directions to content axes on real distributions.
Authors: We agree that the abstract does not contain quantitative metrics and that this weakens the presentation of the central claim. The full manuscript contains qualitative results across multiple attributes, but to directly address the concern we have added content-preservation metrics (CLIP cosine similarity and LPIPS) computed on real images before and after editing, plus an ablation that measures the correlation of the learned directions with content features on real data. These additions appear in a new quantitative evaluation subsection and are summarized in the abstract. revision: yes
-
Referee: Evaluations section: the superiority over text-based techniques is asserted via 'well-integrated, more precise' modifications, but no specific metrics, baselines, tables, or statistical tests are referenced, leaving the continuous adjustability and precision claims without verifiable grounding.
Authors: We acknowledge that the original evaluations section relied primarily on visual comparisons without tabulated metrics or statistical tests. In the revision we have inserted a new table that reports quantitative comparisons against text-based baselines (InstructPix2Pix and Prompt-to-Prompt) using CLIP directional similarity for integration, participant preference scores (N=50) for perceived precision, and a smoothness metric for continuous adjustability. Paired t-tests are included to assess statistical significance of the observed differences. revision: yes
Circularity Check
No circularity: derivation builds on standard components with independent evaluations
full rationale
The paper's chain starts from existing latent diffusion models and DDIM inversion, then introduces learning of editing directions on synthetic stylistic data, guidance composition for domain gap, a regularization loss, and optimized null embeddings. These are presented as novel additions whose effectiveness is asserted via described evaluations on filtered synthetic datasets and comparisons to text-based methods. No step reduces a claimed result to a fitted parameter or self-defined quantity by construction, no load-bearing self-citation chain is invoked for uniqueness or ansatz, and no renaming of known patterns occurs. The central claims rest on empirical validation rather than tautological re-expression of inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Guidance composition can close the domain gap between stylistically finetuned and foundation latent diffusion models while preserving semantics.
- domain assumption Synthetic datasets with controlled stylistic variations yield disentangled editing directions that generalize to real images.
Lean theorems connected to this paper
-
Cost.Jcostwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_reg = (|z_{t-1,λ=k} - z_{t-1,λ=0}| / (1 + |z_{0,λ=k} - z_{0,λ=0}|))^2_2
-
Foundation.BranchSelectionRCLCombiner_isCoupling_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ε_θ(z_t,t,g_p,g_A) = ε_θ(z_t,t,∅) + w_1 g_p + w_2 g_A
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In- structpix2pix: Learning to follow image editing instructions
Brooks, Tim and Holynski, Aleksander and Efros, Alexei A. , year =. arxiv , keywords =:2211.09800 , primaryclass =
-
[2]
Chefer, Hila and Alaluf, Yuval and Vinker, Yael and Wolf, Lior and. Attend-and-. 2023 , month = may, number =. arxiv , keywords =:2301.13826 , primaryclass =
-
[3]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
2023 , journal =. doi:10.1109/iccv51070.2023.00390 , abstract =
-
[4]
2023 , abstract =
Less Is. 2023 , abstract =
2023
-
[5]
Classifier-Free Diffusion Guidance
Classifier-. 2022 , month = jul, journal =. doi:10.48550/arxiv.2207.12598 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2207.12598 2022
-
[6]
doi:10.48550/arxiv.2310.10343 , abstract =
2023 , month = oct, journal =. doi:10.48550/arxiv.2310.10343 , abstract =
-
[7]
Multi-. 2023 , journal =. doi:10.48550/arxiv.2312.04337 , abstract =
-
[8]
doi:10.48550/arXiv.2310.15160 , urldate =
2023 , month = oct, journal =. doi:10.48550/arxiv.2310.15160 , abstract =
-
[9]
DINOv2: Learning Robust Visual Features without Supervision
2023 , month = apr, journal =. doi:10.48550/arxiv.2304.07193 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2304.07193 2023
-
[10]
DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
Focus on. 2020 , month = jun, journal =. doi:10.1109/cvpr42600.2020.00115 , abstract =
-
[11]
doi:10.48550/arxiv.2404.03145 , abstract =
2024 , journal =. doi:10.48550/arxiv.2404.03145 , abstract =
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Null-text inversion for editing real images using guided diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
Mou, Chong and Wang, Xintao and Xie, Liangbin and Wu, Yanze and Zhang, Jian and Qi, Zhongang and Shan, Ying and Qie, Xiaohu , year =. arxiv , keywords =:2302.08453 , primaryclass =
-
[14]
Compositional. 2022 , month = jun, journal =. doi:10.48550/arxiv.2206.01714 , abstract =
-
[15]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023 , month = jun, journal =. doi:10.1109/cvpr52729.2023.02155 , abstract =
-
[16]
Synthetic-. 2023 , month = jul, journal =. doi:10.24132/csrn.3301.16 , abstract =
-
[17]
IEEE Transactions on Pattern Analysis and Machine Intelligence , title =
Z. IEEE Transactions on Pattern Analysis and Machine Intelligence , title =
-
[18]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Yuwei and Yang, Ceyuan and Rao, Anyi and Liang, Zhengyang and Wang, Yaohui and Qiao, Yu and Agrawala, Maneesh and Lin, Dahua and Dai, Bo , year =. arXiv , langid =:2307.04725 , primaryclass =
work page internal anchor Pith review arXiv
-
[19]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Zero-1-to-3:. 2023 , journal =. doi:10.1109/iccv51070.2023.00853 , abstract =
-
[20]
arXiv preprint arXiv:2310.15110 , year=
Zero123++: A. 2023 , month = oct, journal =. doi:10.48550/arxiv.2310.15110 , abstract =
-
[21]
Synthetic. 2023 , month = apr, journal =. doi:10.48550/arxiv.2304.08466 , abstract =
-
[22]
Champ:. 2024 , journal =. doi:10.48550/arxiv.2403.14781 , abstract =
-
[23]
2022 , abstract =
Fine-Tuning. 2022 , abstract =
2022
-
[24]
Plug-and-play diffusion features for text-driven image-to-image translation, 2022
Plug-and-. 2022 , month = nov, journal =. doi:10.48550/arxiv.2211.12572 , abstract =
-
[25]
Dreamsim: Learning new dimensions of human visual similarity using synthetic data , author=. arXiv preprint arXiv:2306.09344 , year=
-
[26]
Plug-and-play diffusion features for text-driven image-to-image translation, 2022
Tumanyan, Narek and Geyer, Michal and Bagon, Shai and Dekel, Tali , year =. Plug-and-. arxiv , keywords =:2211.12572 , primaryclass =
-
[27]
doi:10.48550/arxiv.2306.00984 , abstract =
2023 , month = jun, journal =. doi:10.48550/arxiv.2306.00984 , abstract =
- [28]
- [29]
-
[30]
Magicanimate: Temporally consistent human image animation using diffusion model
2023 , journal =. doi:10.48550/arxiv.2311.16498 , abstract =
-
[31]
Diffusion. 2023 , month = jul, series =. doi:10.1145/3588432.3591558 , urldate =
-
[32]
Diversify,. 2023 , journal =. doi:10.48550/arxiv.2312.02253 , abstract =
-
[33]
doi:10.48550/arxiv.2310.01830 , abstract =
2023 , month = oct, journal =. doi:10.48550/arxiv.2310.01830 , abstract =
-
[34]
, title =
Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J. , title =. ACM Trans. Graphics (Proc. SIGGRAPH Asia) , month = oct, number =
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[36]
International Conference on Machine Learning , year=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International Conference on Machine Learning , year=
-
[37]
Advances in Neural Information Processing Systems , year=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , year=
-
[38]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[39]
Medical Image Computing and Computer-Assisted Intervention , year=
U-net: Convolutional networks for biomedical image segmentation , author=. Medical Image Computing and Computer-Assisted Intervention , year=
-
[40]
International Conference on Learning Representations , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations , year=
-
[41]
Advances in Neural Information Processing Systems , year=
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps , author=. Advances in Neural Information Processing Systems , year=
-
[42]
International Conference on Learning Representations , year=
Prompt-to-Prompt Image Editing with Cross-Attention Control , author=. International Conference on Learning Representations , year=
-
[43]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Hierarchical kinematic probability distributions for 3D human shape and pose estimation from images in the wild , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[44]
Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=
Microsoft coco: Common objects in context , author=. Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=. 2014 , organization=
2014
-
[45]
arXiv preprint arXiv:2009.10013 , year=
Synthetic training for accurate 3d human pose and shape estimation in the wild , author=. arXiv preprint arXiv:2009.10013 , year=
-
[46]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Learning from synthetic humans , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[47]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ai choreographer: Music conditioned 3d dance generation with aist++ , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[48]
Proceedings of the IEEE international conference on computer vision , pages=
Mask r-cnn , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[49]
CVPR , year=
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author=. CVPR , year=
-
[50]
Computer Science
Improving image generation with better captions , author=. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf , volume=
-
[51]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[52]
Demystifying mmd gans , author=. arXiv preprint arXiv:1801.01401 , year=
work page internal anchor Pith review arXiv
-
[53]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[54]
Advances in neural information processing systems , volume=
Improved techniques for training gans , author=. Advances in neural information processing systems , volume=
-
[55]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Stylegan-fusion: Diffusion guided domain adaptation of image generators , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[56]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Styleclip: Text-driven manipulation of stylegan imagery , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[57]
ACM Transactions on Graphics (TOG) , volume=
Stylegan-nada: Clip-guided domain adaptation of image generators , author=. ACM Transactions on Graphics (TOG) , volume=. 2022 , publisher=
2022
-
[58]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Analyzing and improving the image quality of stylegan , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[59]
European Conference on Computer Vision , pages=
Compositional visual generation with composable diffusion models , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[60]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[61]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
-
[62]
arXiv preprint arXiv:2303.15361 , year=
A comprehensive survey on test-time adaptation under distribution shifts , author=. arXiv preprint arXiv:2303.15361 , year=
-
[63]
International conference on machine learning , pages=
Test-time training with self-supervision for generalization under distribution shifts , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[64]
IEEE transactions on pattern analysis and machine intelligence , volume=
A review of domain adaptation without target labels , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2019 , publisher=
2019
-
[65]
2013 , Month = may, Number =
Jan Eric Kyprianidis and John Collomosse and Tinghuai Wang and Tobias Isenberg , Journal =. 2013 , Month = may, Number =
2013
-
[66]
Leon A. Gatys and Alexander S. Ecker and Matthias Bethge , title =. 2016. 2016 , url =. doi:10.1109/CVPR.2016.265 , timestamp =
-
[67]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Chung, Jiwoo and Hyun, Sangeek and Heo, Jae-Pil , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[68]
2024 , eprint=
FreeStyle: Free Lunch for Text-guided Style Transfer using Diffusion Models , author=. 2024 , eprint=
2024
-
[69]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[70]
2022 , booktitle=
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation , author=. 2022 , booktitle=
2022
-
[71]
ACM TOG , volume = 25, number = 3, pages =
Real-Time Video Abstraction , author =. ACM TOG , volume = 25, number = 3, pages =
-
[72]
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction , author =. Proc. ICCV , pages =
-
[73]
Interactive watercolor rendering with temporal coherence and abstraction , author =. Proc. NPAR , pages =
-
[74]
ACM Transactions on Graphics (TOG) , volume=
Deep bilateral learning for real-time image enhancement , author=. ACM Transactions on Graphics (TOG) , volume=. 2017 , publisher=
2017
-
[75]
A Style-Based Generator Architecture for Generative Adversarial Networks , author =. Proc. CVPR , pages =
-
[76]
Adam: A Method for Stochastic Optimization , author =
-
[77]
Generative Adversarial Nets , author =
-
[78]
Painterly Rendering with Curved Brush Strokes of Multiple Sizes , author =. Proc. SIGGRAPH , pages =
-
[79]
Image and Video-Based Artistic Stylisation , pages=
Winnem. Image and Video-Based Artistic Stylisation , pages=. 2012 , doi =
2012
-
[80]
arXiv preprint arXiv:2312.09008 , year=
Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer , author=. arXiv preprint arXiv:2312.09008 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.