Recognition: unknown
What Jobs Can AI Learn? Measuring Exposure by Reinforcement Learning
Pith reviewed 2026-05-08 02:27 UTC · model grok-4.3
The pith
A new index scores every occupational task for how feasible it is to train AI via reinforcement learning and finds large divergences from prior exposure measures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
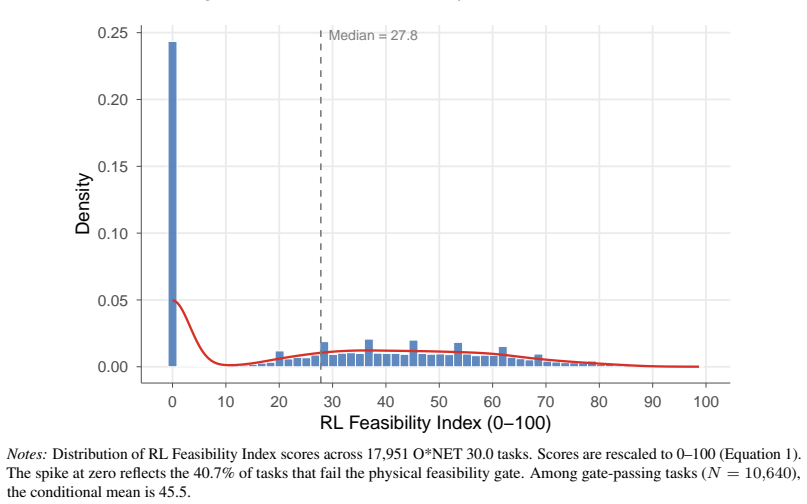
Existing AI exposure indices measure overlap with current capabilities rather than learnability and therefore misclassify occupations where that gap is large. Reinforcement learning, the dominant frontier paradigm, is structured around task completion and therefore maps more directly onto the task-based architecture of occupational classifications such as ONET. Using LLM annotators guided by an RL-expert rubric and validated on confirmed deployment cases, every one of the 17,951 ONET tasks is scored for training feasibility; these scores are aggregated to the occupation level to form an RL Feasibility Index. The resulting index diverges sharply from prior measures, assigning high feasibility
What carries the argument
The RL Feasibility Index, formed by aggregating LLM-annotated training-feasibility scores across all 17,951 ONET tasks.
If this is right
- Policy interventions aimed at AI-driven labor displacement should prioritize different occupations than those flagged by existing exposure indices.
- Operational and procedural roles such as power-plant operation and cargo handling become higher-priority targets for retraining or regulatory attention.
- Creative and interpersonal occupations receive lower feasibility scores and therefore appear less immediately threatened by RL-based automation.
- The gap between present capability and learnability must be tracked separately when forecasting automation timelines.
Where Pith is reading between the lines
- The approach could be extended to score tasks for other post-training methods such as supervised fine-tuning or in-context learning to produce a fuller map of learnability.
- If validated, the index supplies a concrete input for labor-market models that distinguish between tasks that are currently automatable and those that become so after targeted RL training.
- Occupations that combine high RL feasibility with high current exposure may experience faster displacement than either measure alone would predict.
Load-bearing premise
LLM annotators guided by a rubric developed with RL experts and validated against confirmed deployment cases can reliably and accurately score the training feasibility of all 17,951 ONET tasks for reinforcement learning.
What would settle it
A direct comparison of the LLM-generated feasibility scores against independent ratings by reinforcement-learning practitioners on a random sample of several hundred tasks, checking for systematic disagreement.
Figures





read the original abstract
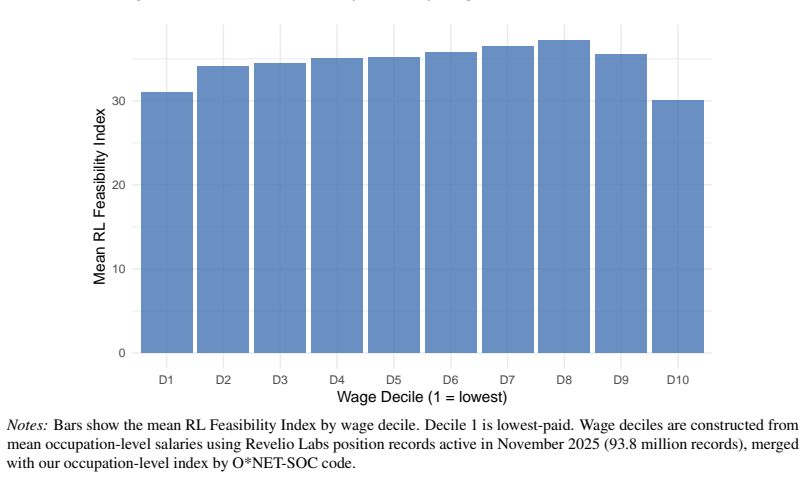
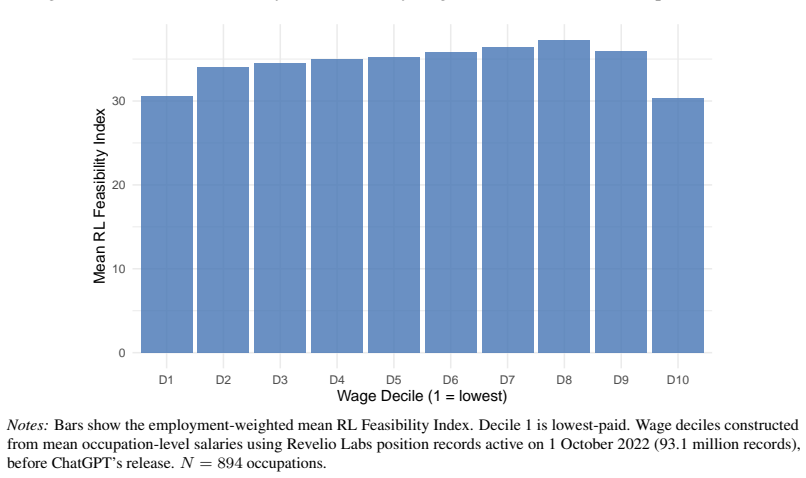
Which jobs can AI learn to do? We examine this for every occupation in the US economy. Existing indices measure the overlap between AI capabilities and occupational tasks rather than which tasks AI systems can learn to perform, and as a result misclassify occupations where the gap between present capability and learnability is large. Reinforcement learning in post-training, now the dominant paradigm at the frontier, is structured around task completion and maps more directly onto the task-based architecture of occupational classifications than prior approaches. Using LLM annotators guided by a rubric developed with RL experts and validated against confirmed deployment cases, we score all 17,951 ONET tasks for training feasibility and aggregate to the occupation level, producing an RL Feasibility Index. The index diverges sharply from existing AI exposure measures for specific occupation groups: power plant operators, railroad conductors, and aircraft cargo handling supervisors score high on RL feasibility but low on general AI exposure, while creative and interpersonal roles (musicians, physicians, natural sciences managers) show the reverse. These divergences carry direct implications for policy interventions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing AI exposure indices misclassify occupations by measuring overlap with current AI capabilities rather than learnability via reinforcement learning (the dominant post-training paradigm). It introduces an RL Feasibility Index by having LLM annotators score all 17,951 O*NET tasks for training feasibility using an expert-developed rubric validated against confirmed deployment cases, aggregates to the occupation level, and reports sharp divergences: power plant operators, railroad conductors, and aircraft cargo handling supervisors score high on RL feasibility but low on general AI exposure, while musicians, physicians, and natural sciences managers show the reverse, with direct policy implications.
Significance. If the index holds, it provides a more direct mapping from RL task-completion structure to occupational classifications than prior overlap-based measures, offering a forward-looking tool for labor economics. The comprehensive task-level scoring and explicit validation against deployments are strengths that could enable falsifiable predictions about which jobs AI can learn, potentially reshaping policy discussions on automation in physical versus creative roles.
major comments (2)
- [Abstract and Methods/Validation] Abstract and presumed Methods/Validation section: The central claim of sharp divergences for power plant operators, railroad conductors, and aircraft cargo handling supervisors (high RL feasibility) versus musicians, physicians, and natural sciences managers (low) rests on the accuracy of LLM task scores. However, no quantitative validation metrics—such as inter-annotator agreement, precision/recall against the confirmed deployment cases, or error analysis stratified by occupation group—are reported, leaving open whether rubric misapplication for simulator availability, reward sparsity, or safety-critical physical tasks drives the result.
- [Results] Results section (divergence claims): The reported occupation-level divergences are load-bearing for the policy implications, yet without robustness checks (e.g., sensitivity to rubric thresholds or alternative aggregation from task to occupation), it is unclear if the index truly identifies learnability gaps or reflects annotation artifacts in the cited groups.
minor comments (2)
- [Methods] Clarify the exact aggregation formula from task scores to the RL Feasibility Index at the occupation level, including any weighting by task importance.
- [Validation] The abstract mentions 'validated against confirmed deployment cases' but the main text should include a table or appendix listing those cases and their scores for transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of rigorous validation and robustness for our RL Feasibility Index. The index aims to shift focus from current AI overlap to learnability under reinforcement learning paradigms, and we agree that strengthening the empirical grounding will enhance the paper's contribution to labor economics. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract and Methods/Validation] Abstract and presumed Methods/Validation section: The central claim of sharp divergences for power plant operators, railroad conductors, and aircraft cargo handling supervisors (high RL feasibility) versus musicians, physicians, and natural sciences managers (low) rests on the accuracy of LLM task scores. However, no quantitative validation metrics—such as inter-annotator agreement, precision/recall against the confirmed deployment cases, or error analysis stratified by occupation group—are reported, leaving open whether rubric misapplication for simulator availability, reward sparsity, or safety-critical physical tasks drives the result.
Authors: We agree that quantitative metrics would strengthen confidence in the LLM annotations. The rubric was iteratively developed with RL experts and applied to score all 17,951 O*NET tasks, with validation performed by cross-checking scores against a curated set of confirmed RL deployment cases (e.g., robotic manipulation, autonomous navigation, and game environments) where high feasibility scores aligned with real-world successes. However, the initial manuscript did not include formal inter-annotator agreement statistics, precision/recall calculations, or stratified error analysis. We will add a dedicated validation subsection reporting these metrics (including agreement rates across multiple LLM annotators and breakdown by task type such as physical vs. cognitive), along with an error analysis addressing potential rubric issues like simulator availability and safety constraints. This revision will directly mitigate concerns about annotation artifacts. revision: yes
-
Referee: [Results] Results section (divergence claims): The reported occupation-level divergences are load-bearing for the policy implications, yet without robustness checks (e.g., sensitivity to rubric thresholds or alternative aggregation from task to occupation), it is unclear if the index truly identifies learnability gaps or reflects annotation artifacts in the cited groups.
Authors: The divergences (e.g., high RL feasibility for operational roles like power plant operators despite low general AI exposure) are central, and we acknowledge that explicit robustness checks were not presented. Task scores are aggregated to occupations via simple averaging (with O*NET importance weights where available), which maps directly to the task-based structure. To address potential sensitivity, we will include new analyses in the revised results section: (1) varying rubric threshold cutoffs for 'feasible' classification, (2) alternative aggregations such as median or weighted sums, and (3) subgroup checks confirming the cited occupations (power plant operators, etc.) remain outliers under these variations. These checks will demonstrate that the divergences are not driven by annotation artifacts and support the policy implications. revision: yes
Circularity Check
No significant circularity in RL Feasibility Index construction
full rationale
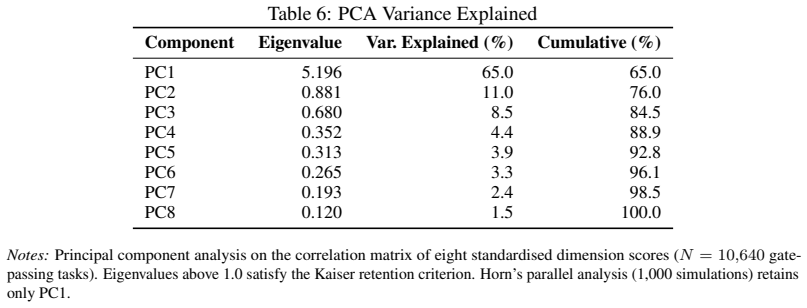
The paper constructs its RL Feasibility Index directly from LLM-based scoring of 17,951 ONET tasks using an externally developed rubric validated against confirmed deployment cases. This process is independent of existing AI exposure measures; the index is not fitted to them, nor defined in terms of them. Divergences for occupations like power plant operators versus musicians are presented as empirical outcomes of the new scoring rather than reductions by construction. No self-definitional equations, fitted inputs renamed as predictions, load-bearing self-citations, or ansatz smuggling appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM annotators guided by an RL expert rubric can reliably assess training feasibility across all ONET tasks
invented entities (1)
-
RL Feasibility Index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
American Economic Review , volume=
The Race Between Man and Machine: Implications of Technology for Growth, Factor Shares, and Employment , author=. American Economic Review , volume=. 2018 , publisher=
2018
-
[2]
Tasks, Automation, and the Rise in
Acemoglu, Daron and Restrepo, Pascual , journal=. Tasks, Automation, and the Rise in. 2022 , publisher=
2022
-
[3]
The Simple Macroeconomics of
Acemoglu, Daron , year=. The Simple Macroeconomics of
-
[4]
Journal of Labor Economics , year =
Acemoglu, Daron and Autor, David and Hazell, Jonathon and Restrepo, Pascual , title =. Journal of Labor Economics , year =
-
[5]
AEA Papers and Proceedings , year =
Acemoglu, Daron and Lelarge, Claire and Restrepo, Pascual , title =. AEA Papers and Proceedings , year =
-
[6]
Journal of Economic Perspectives , year =
Acemoglu, Daron and Restrepo, Pascual , title =. Journal of Economic Perspectives , year =
-
[7]
Journal of Political Economy , year =
Acemoglu, Daron and Restrepo, Pascual , title =. Journal of Political Economy , year =
-
[8]
The Quarterly Journal of Economics , year =
Akerman, Anders and Gaarder, Ingvil and Mogstad, Magne , title =. The Quarterly Journal of Economics , year =. doi:10.1093/qje/qjv028 , publisher =
-
[9]
New Technologies and Jobs in
Albanesi, Stefania and Dias da Silva, Ant. New Technologies and Jobs in. Economic Policy , volume=. 2025 , publisher=
2025
-
[10]
The Diffusion of Artificial Intelligence in an Emerging Economy: Evidence at the Firm Level in
Alderucci, Dean and Crespi, Gustavo and Klor, Esteban and Maffioli, Alessandro , year=. The Diffusion of Artificial Intelligence in an Emerging Economy: Evidence at the Firm Level in
-
[11]
Appel, Ruth and McCrory, Peter and Tamkin, Alex and McCain, Miles and Neylon, Tyler and Stern, Michael , year=. 2511.15080 , archiveprefix=
-
[12]
2016 , doi =
Arntz, Melanie and Gregory, Terry and Zierahn, Ulrich , title =. 2016 , doi =
2016
-
[13]
, title =
Autor, David H. , title =. Journal of Economic Perspectives , year =
-
[14]
Applying
Autor, David , year=. Applying
-
[15]
Journal of the European Economic Association , volume=
Expertise , author=. Journal of the European Economic Association , volume=. 2025 , publisher=
2025
-
[16]
and Katz, Lawrence F
Autor, David H. and Katz, Lawrence F. and Kearney, Melissa S. , journal=. The Polarization of the. 2006 , publisher=
2006
-
[17]
and Levy, Frank and Murnane, Richard J
Autor, David H. and Levy, Frank and Murnane, Richard J. , title =. The Quarterly Journal of Economics , year =
-
[18]
Brookings Papers on Economic Activity , volume=
Is Automation Labor-Displacing? Productivity Growth, Employment, and the Labor Share , author=. Brookings Papers on Economic Activity , volume=. 2018 , publisher=
2018
-
[19]
2026 , institution=
Generative. 2026 , institution=
2026
-
[20]
2025 , month = dec, howpublished =
Azar, Jos. 2025 , month = dec, howpublished =
2025
-
[21]
2024 , publisher=
Babina, Tania and Fedyk, Anastassia and He, Alex and Hodson, James , journal=. 2024 , publisher=
2024
-
[22]
Economic Policy , volume=
Bonfiglioli, Alessandra and Crin. Economic Policy , volume=. 2025 , publisher=
2025
-
[23]
2025 , note =
Brynjolfsson, Erik and Chandar, Bharat and Chen, Ruyu , title =. 2025 , note =
2025
-
[24]
The Quarterly Journal of Economics , year =
Brynjolfsson, Erik and Li, Danielle and Raymond, Lindsey , title =. The Quarterly Journal of Economics , year =
-
[25]
AEA Papers and Proceedings , year =
Brynjolfsson, Erik and Mitchell, Tom and Rock, Daniel , title =. AEA Papers and Proceedings , year =
-
[26]
and Pizzinelli, Carlo and Rockall, Emma J
Cazzaniga, Mauro and Jaumotte, Florence and Li, Long Miao and Melina, Giovanni and Panton, Augustus J. and Pizzinelli, Carlo and Rockall, Emma J. and Tavares, Marina M. , year=
-
[27]
2025 , month = aug, day =
Chandar, Bharat , title =. 2025 , month = aug, day =
2025
-
[28]
Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of
Dell'Acqua, Fabrizio and McFowland, Edward and Mollick, Ethan and Lifshitz-Assaf, Hila and Kellogg, Katherine and Rajendran, Saran and Krayer, Lisa and Candelon, Fran. Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of. 2023 , institution=
2023
-
[29]
Economics of Innovation and New Technology , year =
Dinlersoz, Emin and Wolf, Zoltan , title =. Economics of Innovation and New Technology , year =
-
[30]
2025 , month = jul, note =
Dominski, Jacob and Lee, Yong Suk , title =. 2025 , month = jul, note =
2025
-
[31]
and Schubert, Gregor and Zhang, Miao Ben , year=
Eisfeldt, Andrea L. and Schubert, Gregor and Zhang, Miao Ben , year=. Generative
-
[32]
2024 , publisher=
Eloundou, Tyna and Manning, Sam and Mishkin, Pamela and Rock, Daniel , journal=. 2024 , publisher=
2024
-
[33]
2021 , institution=
Accounting for Employment Impact at Scale , author=. 2021 , institution=
2021
-
[34]
and Raj, Manav and Seamans, Robert , title =
Felten, Edward W. and Raj, Manav and Seamans, Robert , title =. AEA Papers and Proceedings , year =
-
[35]
and Raj, Manav and Seamans, Robert , title =
Felten, Edward W. and Raj, Manav and Seamans, Robert , title =. Strategic Management Journal , year =
-
[36]
and Raj, Manav and Seamans, Robert , title =
Felten, Edward W. and Raj, Manav and Seamans, Robert , title =. 2023 , howpublished =
2023
-
[37]
, title =
Frey, Carl Benedikt and Osborne, Michael A. , title =. Technological Forecasting and Social Change , year =
-
[38]
Gathmann, Christina and Grimm, Moritz , year=
-
[39]
Generative
Gmyrek, Pawe. Generative. 2025 , doi =
2025
-
[40]
and Dorn, David , title =
Autor, David H. and Dorn, David , title =. American Economic Review , year =
-
[41]
The Review of Economics and Statistics , year =
Goos, Maarten and Manning, Alan , title =. The Review of Economics and Statistics , year =
-
[42]
American Economic Review , year =
Goos, Maarten and Manning, Alan and Salomons, Anna , title =. American Economic Review , year =
-
[43]
The Review of Economics and Statistics , year =
Graetz, Georg and Michaels, Guy , title =. The Review of Economics and Statistics , year =
-
[44]
Hampole, Menaka and Papanikolaou, Dimitris and Schmidt, Lawrence D. W. and Seegmiller, Bryan , year=
-
[45]
How Exposed Are UK Jobs to Generative AI? Developing and Applying a Novel Task-Based Index
Henseke, Golo and Davies, Rhys and Felstead, Alan and Gallie, Duncan and Green, Francis and Zhou, Ying , year=. How Exposed Are. 2507.22748 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Organization Science , volume =
Hui, Xiang and Reshef, Oren and Zhou, Luofeng , title =. Organization Science , volume =. 2024 , doi =
2024
-
[47]
2025 , institution=
Large Language Models, Small Labor Market Effects , author=. 2025 , institution=
2025
-
[48]
Generative
Gmyrek, Pawe. Generative. 2023 , doi =
2023
-
[49]
Digital Competitiveness Ranking , year =
-
[50]
Iscenko, Zanna and Curto Millet, Fabien , title =
-
[51]
and Leike, Jan and Brown, Tom B
Christiano, Paul F. and Leike, Jan and Brown, Tom B. and Martic, Miljan and Legg, Shane and Amodei, Dario , title =. Advances in Neural Information Processing Systems , volume =
-
[52]
and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke E
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke E. and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F. and Leike, Jan and L...
-
[53]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[54]
Constitutional
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron and Chen, Carol and Olsson, Catherine and Olah, Christopher and Hernandez, Danny and Drain, Dawn and Ganguli, Deep and Li, Dustin and Tran-Johnson, Eli and Perez, Ethan an...
2022
-
[55]
and Ermon, Stefano and Finn, Chelsea , title =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D. and Ermon, Stefano and Finn, Chelsea , title =. Advances in Neural Information Processing Systems , volume =
-
[56]
The Quarterly Journal of Economics , volume=
The Global Decline of the Labor Share , author=. The Quarterly Journal of Economics , volume=. 2014 , publisher=
2014
-
[57]
2025 , month = sep, type =
Generative. 2025 , month = sep, type =
2025
-
[58]
Economic Journal , year =
Koch, Michael and Manuylov, Igor and Smolka, Marcel , title =. Economic Journal , year =
-
[59]
Generative
Korinek, Anton , journal=. Generative. 2023 , publisher=
2023
-
[60]
Generative
Lichtinger, Guy and. Generative. 2025 , note =
2025
-
[61]
How Adaptable Are
Manning, Sam and Aguirre, Tom. How Adaptable Are. 2025 , type =
2025
-
[62]
2023 , howpublished =
Meleshenko, Kateryna , title =. 2023 , howpublished =
2023
-
[63]
Michaels, Guy and Natraj, Ashwini and Van Reenen, John , journal=. Has. 2014 , publisher=
2014
-
[64]
Experimental Evidence on the Productivity Effects of Generative
Noy, Shakked and Zhang, Whitney , journal=. Experimental Evidence on the Productivity Effects of Generative. 2023 , publisher=
2023
-
[65]
Strictness of Employment Protection , year =
-
[66]
2022 , month =
Employment in the. 2022 , month =
2022
-
[67]
2024 , institution=
The Employment Impact of Emerging Digital Technologies , author=. 2024 , institution=
2024
-
[68]
Annual Review of Economics , volume=
Automation: Theory, Evidence, and Outlook , author=. Annual Review of Economics , volume=. 2024 , publisher=
2024
-
[69]
Journal of Labor Economics , year =
Spitz-Oener, Alexandra , title =. Journal of Labor Economics , year =
-
[70]
Spitz-Oener, Alexandra , title =. ILR Review , year =. doi:10.1177/001979390806100404 , publisher =
-
[71]
Tomlinson, Kiran and Jaffe, Sonia and Wang, Will and Counts, Scott and Suri, Siddharth , year=. Working with. 2507.07935 , archiveprefix=
-
[72]
2008 , publisher=
The Race Between Education and Technology , author=. 2008 , publisher=
2008
-
[73]
Handbook of Labor Economics , volume=
Skills, Tasks and Technologies: Implications for Employment and Earnings , author=. Handbook of Labor Economics , volume=. 2011 , publisher=
2011
-
[74]
Journal of Educational and Behavioral Statistics , volume=
Bias and Efficiency of Meta-Analytic Variance Estimators in the Random-Effects Model , author=. Journal of Educational and Behavioral Statistics , volume=. 2005 , publisher=
2005
-
[75]
2020 , howpublished =
Webb, Michael , title =. 2020 , howpublished =
2020
-
[76]
2024 , howpublished =
Unemployment, Total (\. 2024 , howpublished =
2024
-
[77]
2018 , doi =
Nedelkoska, Ljubica and Quintini, Glenda , title =. 2018 , doi =
2018
-
[78]
and Tavares, Marina Mendes and Cazzaniga, Mauro and Li, Longji , title =
Pizzinelli, Carlo and Panton, Augustus J. and Tavares, Marina Mendes and Cazzaniga, Mauro and Li, Longji , title =. 2023 , doi =
2023
-
[79]
Nurski, Laura and Ruer, Nina , title =
-
[80]
Kochhar, Rakesh , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.