Recognition: unknown
SemEval-2026 Task 7: Everyday Knowledge Across Diverse Languages and Cultures
Pith reviewed 2026-05-09 15:52 UTC · model grok-4.3
The pith
A benchmark evaluates language models on everyday knowledge across more than 30 languages and cultures without permitting training on the test data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that by organizing this evaluation-focused task on an extended benchmark of everyday knowledge, it is possible to gather comparable results from many systems and uncover shared insights about challenges in handling linguistic and cultural diversity, particularly for low-resource settings.
What carries the argument
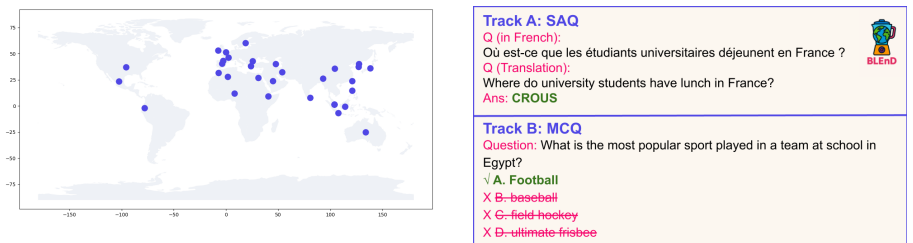
The extended benchmark of everyday knowledge questions in short-answer and multiple-choice formats applied to more than 30 language-culture pairs.
If this is right
- The no-training rule ensures that results reflect genuine generalization rather than memorization.
- Analysis of top systems reveals common approaches to multilingual question answering.
- The task highlights open questions around model misalignment with cultural contexts.
- Performance on low-resource languages indicates areas needing further development in NLP systems.
Where Pith is reading between the lines
- Such benchmarks could inform the creation of more inclusive AI models that respect cultural differences.
- Extending this approach to additional knowledge domains or languages might expose further limitations in current technology.
- The observed challenges suggest that evaluation methods themselves may need refinement to better capture cultural nuances.
Load-bearing premise
The questions in the benchmark accurately represent typical everyday knowledge in each of the covered cultures without introducing bias.
What would settle it
A finding that the benchmark questions systematically miss or misrepresent knowledge held by speakers of the included languages would undermine the task's validity as a measure of cultural adaptability.
Figures

read the original abstract
We present our shared task on evaluating the adaptability of LLMs and NLP systems across multiple languages and cultures. The task data consist of an extended version of our manually constructed BLEnD benchmark (Myung et al. 2024), covering more than 30 language-culture pairs, predominantly representing low-resource languages spoken across multiple continents. As the task is designed strictly for evaluation, participants were not permitted to use the data for training, fine-tuning, few-shot learning, or any other form of model modification. Our task includes two tracks: (a) Short-Answer Questions (SAQ) and (b) Multiple-Choice Questions (MCQ). Participants were required to predict labels and were allowed to submit any NLP system and adopt diverse modelling strategies, provided that the benchmark was used solely for evaluation. The task attracted more than 140 registered participants, and we received final submissions from 62 teams, along with 19 system description papers. We report the results and present an analysis of the best-performing systems and the most commonly adopted approaches. Furthermore, we discuss shared insights into open questions and challenges related to evaluation, misalignment, and methodological perspectives on model behaviour in low-resource languages and for under-represented cultures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SemEval-2026 Task 7, a shared task for evaluating the adaptability of LLMs and NLP systems to everyday knowledge across diverse languages and cultures. The task data are an extended version of the manually constructed BLEnD benchmark covering more than 30 language-culture pairs (predominantly low-resource languages). It defines two tracks—Short-Answer Questions (SAQ) and Multiple-Choice Questions (MCQ)—with strict rules prohibiting any use of the data for training, fine-tuning, or few-shot adaptation. The paper reports 140 registered participants, 62 final submissions, 19 system description papers, and provides analysis of the best-performing systems, common approaches, and open challenges in evaluation, misalignment, and model behavior for low-resource languages and under-represented cultures.
Significance. If the reported results and analysis hold, the work supplies a large-scale, culturally diverse evaluation framework that can serve as a reference benchmark for assessing cultural knowledge and alignment in LLMs, especially in low-resource settings. The high participation rate and the evaluation-only constraint strengthen the reliability of any comparative findings, while the analysis of adopted modeling strategies offers practical insights for future work on cross-cultural NLP.
minor comments (1)
- [Abstract] Abstract: the statement that results and analysis are reported would be strengthened by an explicit forward reference to the relevant section or table containing the quantitative performance metrics and error analysis of the top systems.
Simulated Author's Rebuttal
We thank the referee for their positive review, accurate summary of the task, and recommendation to accept. The feedback correctly identifies the value of the evaluation-only constraint and the insights from high participation rates.
Circularity Check
Descriptive shared-task paper with no derivations or load-bearing circularity
full rationale
The manuscript is a standard SemEval task description whose central statements are factual descriptions of data provenance and participation statistics. It contains no equations, fitted parameters, predictions, or modeling derivations. The single self-citation to Myung et al. 2024 simply identifies the source benchmark being extended; this reference is not used to justify any internal claim that would otherwise be unsupported, nor does any result reduce to the citation by construction. All other content (track definitions, submission rules, result reporting) is observational and does not rely on unverified self-referential logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption NLP systems can be meaningfully evaluated on knowledge benchmarks without training or fine-tuning on the test data itself.
Reference graph
Works this paper leans on
-
[1]
Wangkongqiang at
Wang, Kongqiang and Zhang, Peng and Tan, Qingli , booktitle=. Wangkongqiang at
-
[2]
Tekanlou, Hadi Bayrami Asl and Bakhtiyarzadeh, Mahdi and Razmara, Jafar , booktitle=
-
[3]
Bogdanova, Liliia and Sun, Shiran and Han, Lifeng and Amat-Lefort, Natalia and Plaza-del-Arco, Flor Miriam , booktitle=
-
[4]
Almanza, Danileth and Serrano, Jairo and Puertas, Edwin and Martinez Santos, Juan Carlos , booktitle=
-
[5]
Ning, Jingke , booktitle=
-
[6]
king001 at
Jin, Meizhi and Meng, Zhichao and Yin, Junqi and Jiang, Lianxin and Li, Jianyu , booktitle=. king001 at
-
[7]
chengtang at
Tang, Cheng and Meng, Zhichao and Jin, Meizhi , booktitle=. chengtang at
-
[8]
Yao, Xiao and Yang, Liang , booktitle=
-
[9]
Adam, Faisal Muhammad and Aliyu, Lukman Jibril and Aji, Sani and Abubakar, Abdulhamid and Shuaibu, Aliyu Rabiu , booktitle=
-
[10]
Al Ghussin, Yusser and Gurgurov, Daniil and Hamidullah, Yasser and van Genabith, Josef and España-Bonet, Cristina and Ostermann, Simon , booktitle=
-
[11]
, booktitle=
Adjei, Isaac Nyadu and Aryal, Saurav K. , booktitle=
-
[12]
Rahman, Mohammad Marufur and Ailneni, Rakshitha Rao and Harabagiu, Sanda , booktitle=
-
[13]
Singh, Aditya and Das, Rickarya , booktitle=
-
[14]
uir-cis-7 at
Gao, Jianning and Mao, Xianling and Shi, Shumin and Zhaxi, Duanzhi and Sun, Yingbo and Li, Xiandeng and Li, Binyang , booktitle=. uir-cis-7 at
-
[15]
Iranmanesh, Reihaneh and Frieder, Ophir and Goharian, Nazli , booktitle=
-
[16]
Yam, Yen Yee and Yam, Hong Meng , booktitle=
-
[17]
Song, Jiwoo and Yeom, Sihyeong and Kim, Harksoo , booktitle=
-
[18]
Sriram, Swetha Krishna and Sekar, Nirupama , booktitle=
-
[19]
2024 , journal=
Aya 23: Open Weight Releases to Further Multilingual Progress , author=. 2024 , journal=
2024
-
[20]
Building Better: Avoiding Pitfalls in Developing Language Resources when Data is Scarce
Ousidhoum, Nedjma and Beloucif, Meriem and Mohammad, Saif M. Building Better: Avoiding Pitfalls in Developing Language Resources when Data is Scarce. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.435
-
[21]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Culture is not trivia: Sociocultural theory for cultural nlp , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[22]
Hire Your Anthropologist! Rethinking Culture Benchmarks Through an Anthropological Lens
Alkhamissi, Mai and Xiao, Yunze and AlKhamissi, Badr and Diab, Mona T. Hire Your Anthropologist! Rethinking Culture Benchmarks Through an Anthropological Lens. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026
2026
-
[23]
Having Beer after Prayer? Measuring Cultural Bias in Large Language Models,
Having Beer after Prayer? Measuring Cultural Bias in Large Language Models , author=. arXiv preprint arXiv:2305.14456 , year=
-
[24]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review arXiv
-
[25]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Bloom: A 176b-parameter open-access multilingual language model , author=. arXiv preprint arXiv:2211.05100 , year=
work page internal anchor Pith review arXiv
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Language and Culture , volume =
Kramsch, Claire , year =. Language and Culture , volume =. doi:10.1075/aila.27.02kra , journal =
-
[28]
Ryan, William Held, and Diyi Yang
Unintended Impacts of LLM Alignment on Global Representation , author=. arXiv preprint arXiv:2402.15018 , year=
-
[29]
arXiv preprint arXiv:2306.16388 , year=
Towards measuring the representation of subjective global opinions in language models , author=. arXiv preprint arXiv:2306.16388 , year=
-
[30]
arXiv preprint arXiv:2402.09369 , year=
Massively multi-cultural knowledge acquisition & lm benchmarking , author=. arXiv preprint arXiv:2402.09369 , year=
-
[31]
Nguyen, Tuan-Phong and Razniewski, Simon and Varde, Aparna and Weikum, Gerhard , title =. Proceedings of the ACM Web Conference 2023 , pages =. 2023 , isbn =. doi:10.1145/3543507.3583535 , abstract =
-
[32]
arXiv preprint arXiv:2404.15238 , year=
CultureBank: An Online Community-Driven Knowledge Base Towards Culturally Aware Language Technologies , author=. arXiv preprint arXiv:2404.15238 , year=
-
[33]
Qwen Technical Report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model , author=. arXiv preprint arXiv:2402.07827 , year=
-
[35]
arXiv preprint arXiv:2404.01954
HyperCLOVA X Technical Report , author=. arXiv preprint arXiv:2404.01954 , year=
-
[36]
Can Common Sense uncover cultural differences in computer applications?
Anacleto, Junia and Lieberman, Henry and Tsutsumi, Marie and Neris, V \^a nia and Carvalho, Aparecido and Espinosa, Jose and Godoi, Muriel and Zem-Mascarenhas, Silvia. Can Common Sense uncover cultural differences in computer applications?. Artificial Intelligence in Theory and Practice. 2006
2006
-
[37]
arXiv preprint arXiv:2401.15585 , year=
Evaluating Gender Bias in Large Language Models via Chain-of-Thought Prompting , author=. arXiv preprint arXiv:2401.15585 , year=
-
[38]
ACM Journal of Data and Information Quality , volume=
Biases in large language models: origins, inventory, and discussion , author=. ACM Journal of Data and Information Quality , volume=. 2023 , publisher=
2023
-
[39]
arXiv preprint arXiv:2404.01854 , year=
IndoCulture: Exploring Geographically-Influenced Cultural Commonsense Reasoning Across Eleven Indonesian Provinces , author=. arXiv preprint arXiv:2404.01854 , year=
-
[40]
arXiv preprint arXiv:2312.00738 , url=
Xuan-Phi Nguyen and Wenxuan Zhang and Xin Li and Mahani Aljunied and Qingyu Tan and Liying Cheng and Guanzheng Chen and Yue Deng and Sen Yang and Chaoqun Liu and Hang Zhang and Lidong Bing , title =. arXiv preprint arXiv:2312.00738 , url=
-
[41]
2024 , eprint=
Exploring Cross-Cultural Differences in English Hate Speech Annotations: From Dataset Construction to Analysis , author=. 2024 , eprint=
2024
-
[42]
HAE - RAE Bench: Evaluation of K orean Knowledge in Language Models
Son, Guijin and Lee, Hanwool and Kim, Suwan and Kim, Huiseo and Lee, Jae cheol and Yeom, Je Won and Jung, Jihyu and Kim, Jung woo and Kim, Songseong. HAE - RAE Bench: Evaluation of K orean Knowledge in Language Models. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[43]
CLI c K : A Benchmark Dataset of Cultural and Linguistic Intelligence in K orean
Kim, Eunsu and Suk, Juyoung and Oh, Philhoon and Yoo, Haneul and Thorne, James and Oh, Alice. CLI c K : A Benchmark Dataset of Cultural and Linguistic Intelligence in K orean. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[44]
2024 , eprint=
COPAL-ID: Indonesian Language Reasoning with Local Culture and Nuances , author=. 2024 , eprint=
2024
-
[45]
2024 , eprint=
Can LLM Generate Culturally Relevant Commonsense QA Data? Case Study in Indonesian and Sundanese , author=. 2024 , eprint=
2024
-
[46]
Communications of the ACM , volume=
Building a multilingual Wikipedia , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[47]
, author=
qalsadi, Arabic mophological analyzer Library for python. , author=
-
[48]
and Patrick Burns and John Stewart and Todd Cook , title =
Johnson, Kyle P. and Patrick Burns and John Stewart and Todd Cook , title =
-
[49]
Setiawan, Irwan and Kao, Hung-Yu , title =. ACM Trans. Asian Low-Resour. Lang. Inf. Process. , month =. 2024 , publisher =. doi:10.1145/3656342 , abstract =
-
[50]
The IndicNLP Library
Anoop Kunchukuttan. The IndicNLP Library. 2020
2020
-
[51]
Stemming Hausa text: using affix-stripping rules and reference look-up , volume =
Bimba, Andrew and Idris, Norisma and Khamis, Norazlina and Noor, Nurul , year =. Stemming Hausa text: using affix-stripping rules and reference look-up , volume =. Language Resources and Evaluation , doi =
-
[52]
Proceedings of the international AAAI conference on web and social media , volume=
Big questions for social media big data: Representativeness, validity and other methodological pitfalls , author=. Proceedings of the international AAAI conference on web and social media , volume=
-
[53]
2024 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2024 , eprint=
2024
-
[54]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[55]
2023 , eprint=
PaLM 2 Technical Report , author=. 2023 , eprint=
2023
-
[56]
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages , url =
Myung, Junho and Lee, Nayeon and Zhou, Yi and Jin, Jiho and Putri, Rifki Afina and Antypas, Dimosthenis and Borkakoty, Hsuvas and Kim, Eunsu and Perez-Almendros, Carla and Ayele, Abinew Ali and Guti\'. BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages , url =. Advances in Neural Information Processing Systems , editor =
-
[57]
2024 , eprint=
Survey of Cultural Awareness in Language Models: Text and Beyond , author=. 2024 , eprint=
2024
-
[58]
2025 , eprint=
Culturally Aware and Adapted NLP: A Taxonomy and a Survey of the State of the Art , author=. 2025 , eprint=
2025
-
[59]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
CLIcK: A Benchmark Dataset of Cultural and Linguistic Intelligence in Korean , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[60]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
HAE-RAE Bench: Evaluation of Korean Knowledge in Language Models , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[61]
Proceedings of the 20th Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2024
2024
-
[62]
Conversational XAI and Explanation Dialogues
Feldhus, Nils. Conversational XAI and Explanation Dialogues. 2024
2024
-
[63]
Enhancing Emotion Recognition in Spoken Dialogue Systems through Multimodal Integration and Personalization
Kaneko, Takumasa. Enhancing Emotion Recognition in Spoken Dialogue Systems through Multimodal Integration and Personalization. 2024
2024
-
[64]
Towards Personalisation of User Support Systems
Higuchi, Tomoya. Towards Personalisation of User Support Systems. 2024
2024
-
[65]
Social Agents for Positively Influencing Human Psychological States
Baihaqi, Muhammad Yeza. Social Agents for Positively Influencing Human Psychological States. 2024
2024
-
[66]
Personalized Topic Transition for Dialogue System
Yoshida, Kai. Personalized Topic Transition for Dialogue System. 2024
2024
-
[67]
Elucidation of Psychotherapy and Development of New Treatment Methods Using AI
Maeda, Shio. Elucidation of Psychotherapy and Development of New Treatment Methods Using AI. 2024
2024
-
[68]
Assessing Interactional Competence with Multimodal Dialog Systems
Saeki, Mao. Assessing Interactional Competence with Multimodal Dialog Systems. 2024
2024
-
[69]
Faithfulness of Natural Language Generation
Schmidtova, Patricia. Faithfulness of Natural Language Generation. 2024
2024
-
[70]
Knowledge-Grounded Dialogue Systems for Generating Interesting and Engaging Responses
Onozeki, Hiroki. Knowledge-Grounded Dialogue Systems for Generating Interesting and Engaging Responses. 2024
2024
-
[71]
Towards a Dialogue System That Can Take Interlocutors' Values into Account
Zenimoto, Yuki. Towards a Dialogue System That Can Take Interlocutors' Values into Account. 2024
2024
-
[72]
Multimodal Spoken Dialogue System with Biosignals
Katada, Shun. Multimodal Spoken Dialogue System with Biosignals. 2024
2024
-
[73]
Timing Sensitive Turn-Taking in Spoken Dialogue Systems Based on User Satisfaction
Yoshikawa, Sadahiro. Timing Sensitive Turn-Taking in Spoken Dialogue Systems Based on User Satisfaction. 2024
2024
-
[74]
Towards Robust and Multilingual Task-Oriented Dialogue Systems
Ohashi, Atsumoto. Towards Robust and Multilingual Task-Oriented Dialogue Systems. 2024
2024
-
[75]
Toward Faithful Dialogs: Evaluating and Improving the Faithfulness of Dialog Systems
Huang, Sicong. Toward Faithful Dialogs: Evaluating and Improving the Faithfulness of Dialog Systems. 2024
2024
-
[76]
Cognitive Model of Listener Response Generation and Its Application to Dialogue Systems
Mori, Taiga. Cognitive Model of Listener Response Generation and Its Application to Dialogue Systems. 2024
2024
-
[77]
Topological Deep Learning for Term Extraction
Ruppik, Benjamin Matthias. Topological Deep Learning for Term Extraction. 2024
2024
-
[78]
Dialogue Management with Graph-structured Knowledge
Walker, Nicholas Thomas. Dialogue Management with Graph-structured Knowledge. 2024
2024
-
[79]
Towards a Co-creation Dialogue System
Zhou, Xulin. Towards a Co-creation Dialogue System. 2024
2024
-
[80]
Enhancing Decision-Making with AI Assistance
Tanaka, Yoshiki. Enhancing Decision-Making with AI Assistance. 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.