Recognition: 2 theorem links
· Lean TheoremSynthetic Users, Real Differences: an Evaluation Framework for User Simulation in Multi-Turn Conversations
Pith reviewed 2026-05-08 19:22 UTC · model grok-4.3
The pith
Simulated users miss communication frictions that real users introduce, making chatbot evaluations overly optimistic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
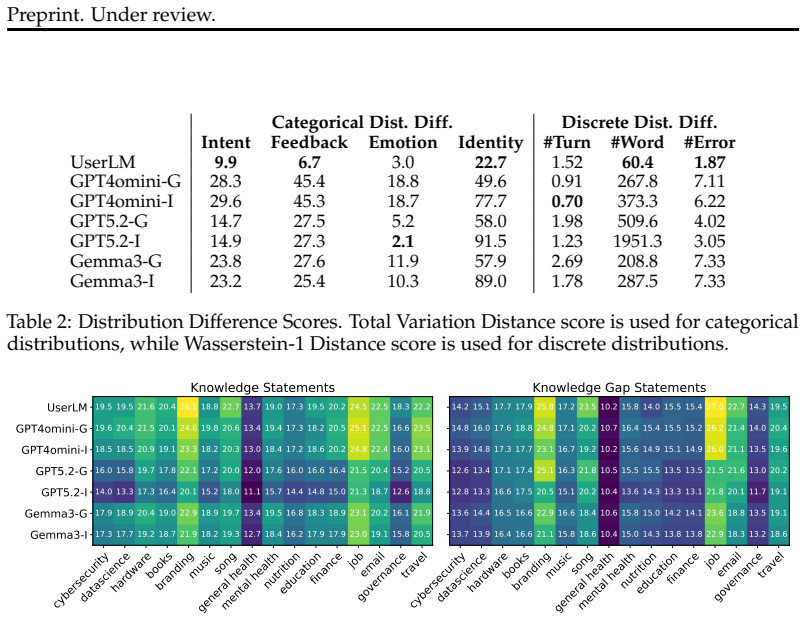
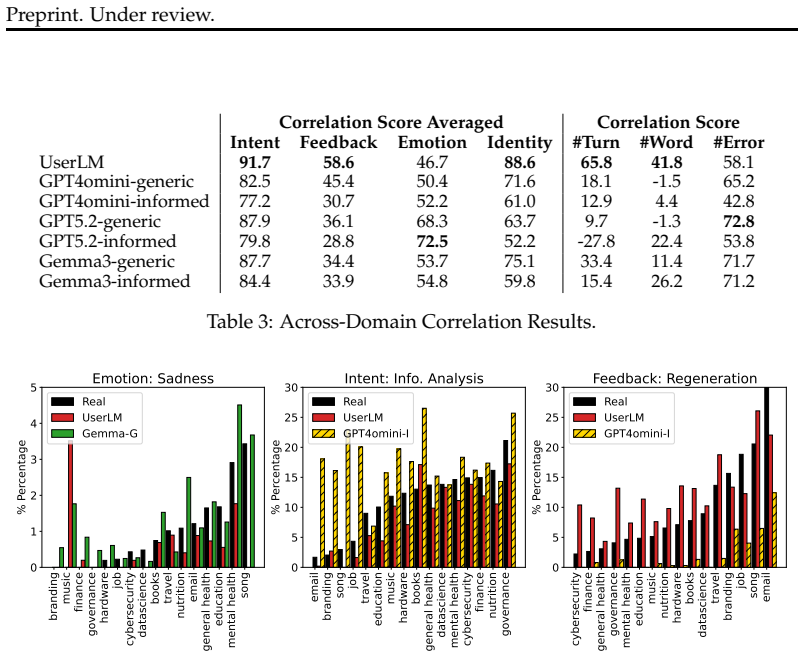
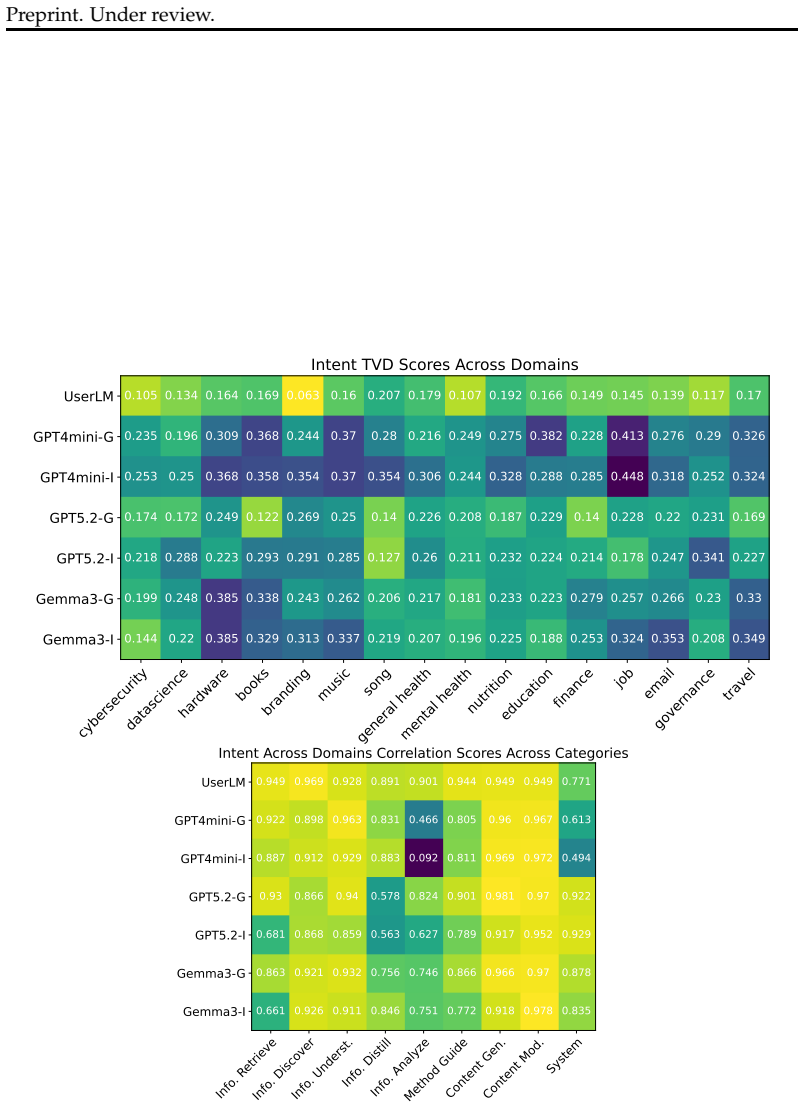
The authors establish that simulated users struggle to capture the communication frictions real users introduce during multi-turn chatbot interactions, which risks producing overly optimistic evaluations of chatbot performance, and that simulator quality varies substantially across the sixteen application domains examined.
What carries the argument
The realsim framework, which produces distributional comparisons of real versus simulated dialogues across eight dimensions of communicative functions, user states, and surface form.
If this is right
- Evaluations that rely on current simulated users may overestimate how well chatbots handle real interactions.
- User simulators require specific improvements in modeling communication frictions rather than only task completion.
- Domain-specific simulators are likely needed, given the observed performance variability.
- The framework supplies a reusable benchmark for testing future simulators against real distributional patterns.
Where Pith is reading between the lines
- Teams developing production chatbots may need to retain some real-user testing in domains where friction modeling is critical.
- Hybrid evaluation pipelines that alternate between simulation and targeted real-user sampling could reduce optimism bias.
- The eight-dimension lens could be extended to measure whether newer simulation techniques close the friction gap over time.
Load-bearing premise
The eight chosen dimensions are sufficient to reveal the main differences between real and simulated dialogues and the one-thousand-dialogue dataset is representative of interactions in the sixteen domains.
What would settle it
A new simulation method that produces dialogues statistically indistinguishable from real ones on all eight dimensions when measured on an independent collection of multi-turn conversations would falsify the claim that simulators inherently struggle with frictions.
Figures




read the original abstract
There is growing interest in exploring user simulation as an alternative to gathering and scoring real user-chatbot interactions for AI chatbot evaluation. For this purpose, it is important to ensure the realism of the simulation, i.e., the extent to which simulated dialogues reflect real dialogues users have with chatbots. Most existing methods evaluating simulation realism produce coarse quality signal and remain solely at the level of individual dialogues. To support more rigorous evaluation in this area, we propose realsim, an evaluation framework that enables practitioners to take a distributional view of real vs. simulated dialogues along 8 dimensions, covering attributes related to the communicative functions of the interaction, user states, and the surface form of user messages. We then instantiate the framework with a curated dataset of 1K multi-turn task-focused real user-chatbot dialogues that cover 16 domains of chatbot applications. Overall, we find that simulated users tend to struggle at capturing communication frictions that real users introduce to interactions, which could make evaluations based on such simulations overly optimistic. We also observe variability in performance across different domains, which may indicate a need for domain-specific user simulators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces realsim, a framework for evaluating the realism of user simulators for multi-turn conversations by comparing distributions of real and simulated dialogues across eight dimensions encompassing communicative functions, user states, and surface forms. Using a curated dataset of 1K real dialogues from 16 domains, the authors find that simulated users under-capture communication frictions, potentially leading to overly optimistic chatbot evaluations, and observe domain variability.
Significance. This framework offers a more granular, distributional approach to assessing simulation quality than existing coarse methods, which could enhance the validity of simulation-based evaluations in chatbot development. The multi-domain dataset is a notable resource. If the dimensions prove predictive of evaluation biases, the findings would encourage development of better simulators that handle real-user frictions. The work highlights important limitations in current simulation techniques.
major comments (3)
- Abstract, final paragraph: The claim that simulated users struggle to capture communication frictions 'which could make evaluations based on such simulations overly optimistic' is not backed by any direct evidence linking the observed differences in the 8 dimensions to actual discrepancies in chatbot evaluation outcomes, such as human preference scores or task completion rates.
- Dataset section (likely §4): The 1K dataset curation process does not specify how it ensures balanced representation of friction-inducing interactions (e.g., multi-turn clarifications or error recoveries) across the 16 domains, and no pre-specified analysis plan for the observed domain variability is mentioned, weakening the generalizability of the findings.
- Framework and Experiments sections (likely §3 and §5): No details are provided on the operationalization and measurement of the eight dimensions, including any statistical tests, inter-annotator agreement, or validation against external criteria like human realism ratings, making it difficult to assess the robustness of the reported differences.
minor comments (1)
- Clarify the exact operational definitions and annotation procedures for each of the eight dimensions to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for clarification and strengthening. We address each major comment below and will incorporate revisions to improve the manuscript's rigor and transparency.
read point-by-point responses
-
Referee: Abstract, final paragraph: The claim that simulated users struggle to capture communication frictions 'which could make evaluations based on such simulations overly optimistic' is not backed by any direct evidence linking the observed differences in the 8 dimensions to actual discrepancies in chatbot evaluation outcomes, such as human preference scores or task completion rates.
Authors: We agree that the connection is inferential rather than directly demonstrated through new experiments on evaluation outcomes. The dimensions were chosen because they capture known friction points (e.g., clarifications, error recoveries) that prior literature links to reduced user satisfaction and task success. We will revise the abstract to use more cautious language ('potentially leading to overly optimistic evaluations') and add a dedicated discussion paragraph citing supporting studies on how these frictions affect real chatbot assessments. A full empirical linkage would require additional human evaluation experiments beyond the current scope. revision: partial
-
Referee: Dataset section (likely §4): The 1K dataset curation process does not specify how it ensures balanced representation of friction-inducing interactions (e.g., multi-turn clarifications or error recoveries) across the 16 domains, and no pre-specified analysis plan for the observed domain variability is mentioned, weakening the generalizability of the findings.
Authors: The curation drew from public multi-turn dialogue corpora to achieve domain coverage, with selection criteria focused on task-oriented interactions of at least three turns; however, explicit stratification by friction type was not applied. We will expand the dataset section with a detailed description of the filtering and sampling procedure, including statistics on multi-turn length and friction indicators per domain. The domain variability analysis was exploratory, so we will explicitly label it as such and outline a pre-specified analysis plan for any follow-up studies. revision: yes
-
Referee: Framework and Experiments sections (likely §3 and §5): No details are provided on the operationalization and measurement of the eight dimensions, including any statistical tests, inter-annotator agreement, or validation against external criteria like human realism ratings, making it difficult to assess the robustness of the reported differences.
Authors: We apologize for the insufficient detail in the submitted version. The eight dimensions combine rule-based and LLM-assisted extraction for surface features with human annotation for communicative functions and user states. We will substantially expand §3 with precise operational definitions, annotation guidelines, inter-annotator agreement (Cohen's kappa), statistical tests (e.g., two-sample KS tests for distributional comparisons), and any available validation against external realism judgments. An appendix will include examples and full annotation protocols. revision: yes
- Direct empirical evidence linking the eight dimensions to specific downstream chatbot evaluation discrepancies (human preference scores or task completion rates) cannot be provided without new experiments outside the current manuscript scope.
Circularity Check
No circularity: empirical comparison on external dataset
full rationale
The paper defines realsim as a framework with eight dimensions and applies it to a separately curated 1K real-dialogue dataset spanning 16 domains. Reported differences between real and simulated dialogues are direct distributional observations under those dimensions, with no equations, fitted parameters, or self-citations that reduce the central claims to inputs by construction. The analysis is therefore self-contained against external benchmarks rather than self-referential.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclearFor Length and Error, their annotation results are discrete distributions that are compared against one another through Wasserstein distance scores
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
2025 , eprint=
Taxonomy of User Needs and Actions , author=. 2025 , eprint=
2025
-
[3]
Chen, Chaoran and Yao, Bingsheng and Zou, Ruishi and Hua, Wenyue and Lyu, Weimin and Li, Toby Jia-Jun and Wang, Dakuo. Towards a Design Guideline for RPA Evaluation: A Survey of Large Language Model-Based Role-Playing Agents. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.938
-
[4]
Paruchuri, Akshay and Aziz, Maryam and Vartak, Rohit and Ali, Ayman and Uchehara, Best and Liu, Xin and Chatterjee, Ishan and Agrawal, Monica. ``What ' s Up, Doc?'': Analyzing How Users Seek Health Information in Large-Scale Conversational AI Datasets. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findin...
-
[5]
2025 , eprint=
Flipping the Dialogue: Training and Evaluating User Language Models , author=. 2025 , eprint=
2025
-
[6]
2024 , eprint=
WildChat: 1M ChatGPT Interaction Logs in the Wild , author=. 2024 , eprint=
2024
-
[7]
2024 , eprint=
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset , author=. 2024 , eprint=
2024
-
[8]
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie Jun and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , articleno =. 2023 , isbn =. doi:10.1145/3586183.3606763 , abstract =
-
[9]
2023 , eprint=
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations , author=. 2023 , eprint=
2023
-
[10]
Character- LLM : A Trainable Agent for Role-Playing
Shao, Yunfan and Li, Linyang and Dai, Junqi and Qiu, Xipeng. Character- LLM : A Trainable Agent for Role-Playing. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[11]
C o MP os T : Characterizing and Evaluating Caricature in LLM Simulations
Cheng, Myra and Piccardi, Tiziano and Yang, Diyi. C o MP os T : Characterizing and Evaluating Caricature in LLM Simulations. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.669
-
[12]
2024 , eprint=
How Far Are LLMs from Believable AI? A Benchmark for Evaluating the Believability of Human Behavior Simulation , author=. 2024 , eprint=
2024
-
[13]
Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, H ´erve J ´egou, and Tomas Mikolov
Kim, Eunsu and Suk, Juyoung and Kim, Seungone and Muennighoff, Niklas and Kim, Dongkwan and Oh, Alice. LLM -as-an-Interviewer: Beyond Static Testing Through Dynamic LLM Evaluation. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1357
-
[14]
InCharacter: Evaluating personality fidelity in role-playing agents through psychological interviews
Wang, Xintao and Xiao, Yunze and Huang, Jen-tse and Yuan, Siyu and Xu, Rui and Guo, Haoran and Tu, Quan and Fei, Yaying and Leng, Ziang and Wang, Wei and Chen, Jiangjie and Li, Cheng and Xiao, Yanghua. I n C haracter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews. Proceedings of the 62nd Annual Meeting of the Asso...
-
[15]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Liu, Jiaheng and Ni, Zehao and Que, Haoran and Sun, Tao and Wang, Zekun and Yang, Jian and Wang, Jiakai and Guo, Hongcheng and Peng, Zhongyuan and Zhang, Ge and Tian, Jiayi and Bu, Xingyuan and Xu, Ke and Rong, Wenge and Peng, Junran and Zhang, Zhaoxiang , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems ,...
2024
-
[16]
2024 , eprint=
Real or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue , author=. 2024 , eprint=
2024
-
[17]
2019 , eprint=
ACUTE-EVAL: Improved Dialogue Evaluation with Optimized Questions and Multi-turn Comparisons , author=. 2019 , eprint=
2019
-
[18]
MT -Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models
Kwan, Wai-Chung and Zeng, Xingshan and Jiang, Yuxin and Wang, Yufei and Li, Liangyou and Shang, Lifeng and Jiang, Xin and Liu, Qun and Wong, Kam-Fai. MT -Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1124
-
[19]
MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback , url =
Wang, Xingyao and Wang, Zihan and Liu, Jiateng and Chen, Yangyi and Yuan, Lifan and Peng, Hao and Ji, Heng , booktitle =. MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback , url =
-
[20]
Chang, Serina and Anderson, Ashton and Hofman, Jake M. , year=. ChatBench: From Static Benchmarks to Human-AI Evaluation , url=. doi:10.18653/v1/2025.acl-long.1262 , booktitle=
-
[21]
BASES : Large-scale Web Search User Simulation with Large Language Model based Agents
Ren, Ruiyang and Qiu, Peng and Qu, Yingqi and Liu, Jing and Zhao, Wayne Xin and Wu, Hua and Wen, Ji-Rong and Wang, Haifeng. BASES : Large-scale Web Search User Simulation with Large Language Model based Agents. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.50
-
[22]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Li, Ruosen and Li, Ruochen and Wang, Barry and Du, Xinya , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[23]
Approximating Online Human Evaluation of Social Chatbots with Prompting
Svikhnushina, Ekaterina and Pu, Pearl. Approximating Online Human Evaluation of Social Chatbots with Prompting. Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2023. doi:10.18653/v1/2023.sigdial-1.25
-
[24]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph E and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
-
[25]
2025 , eprint=
Scaling Synthetic Data Creation with 1,000,000,000 Personas , author=. 2025 , eprint=
2025
-
[26]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
BERTopic: Neural topic modeling with a class-based TF-IDF procedure , author=. arXiv preprint arXiv:2203.05794 , year=
work page internal anchor Pith review arXiv
-
[27]
2026 , eprint=
SDialog: A Python Toolkit for End-to-End Agent Building, User Simulation, Dialog Generation, and Evaluation , author=. 2026 , eprint=
2026
-
[28]
2024 , eprint=
MT-Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models , author=. 2024 , eprint=
2024
-
[29]
The knowledge engineering review , volume=
A survey of statistical user simulation techniques for reinforcement-learning of dialogue management strategies , author=. The knowledge engineering review , volume=. 2006 , publisher=
2006
-
[30]
User modeling and user-adapted interaction , volume=
Natural language processing and user modeling: Synergies and limitations , author=. User modeling and user-adapted interaction , volume=. 2001 , publisher=
2001
-
[31]
Quality and User Experience , volume=
Users' experiences with chatbots: findings from a questionnaire study , author=. Quality and User Experience , volume=. 2020 , publisher=
2020
-
[32]
International Journal of Human--Computer Interaction , volume=
How should my chatbot interact? A survey on social characteristics in human--chatbot interaction design , author=. International Journal of Human--Computer Interaction , volume=. 2021 , publisher=
2021
-
[33]
Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems , pages=
If I hear you correctly: Building and evaluating interview chatbots with active listening skills , author=. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems , pages=
2020
-
[34]
arXiv preprint arXiv:2602.01405 , year=
Feedback by Design: Understanding and Overcoming User Feedback Barriers in Conversational Agents , author=. arXiv preprint arXiv:2602.01405 , year=
-
[35]
2024 , eprint=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. 2024 , eprint=
2024
-
[36]
2026 , eprint=
HumanLM: Simulating Users with State Alignment Beats Response Imitation , author=. 2026 , eprint=
2026
-
[37]
Large language models that replace human participants can harmfully misportray and flatten identity groups
Wang, Angelina and Morgenstern, Jamie and Dickerson, John P. Large language models that replace human participants can harmfully misportray and flatten identity groups. Nature Machine Intelligence
-
[38]
Not Yet: Large Language Models Cannot Replace Human Respondents for Psychometric Research , doi =
Wang, Pengda and Zou, Huiqi and Yan, Zihan and Guo, Feng and Sun, Tianjun and Xiao, Ziang and Zhang, Bo , year =. Not Yet: Large Language Models Cannot Replace Human Respondents for Psychometric Research , doi =
-
[39]
1975 , abstract =
Kincaid, J P and Fishburne, Jr , Robert P and Rogers, Richard L and Chissom, Brad S , copyright =. 1975 , abstract =
1975
-
[40]
MTLD , vocd-D, and HD-D : A validation study of sophisticated approaches to lexical diversity assessment
McCarthy, Philip M and Jarvis, Scott. MTLD , vocd-D, and HD-D : A validation study of sophisticated approaches to lexical diversity assessment. Behavior Research Methods
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.