Recognition: 3 theorem links
· Lean TheoremParaRNN: An Interpretable and Parallelizable Recurrent Neural Network for Time-Dependent Data
Pith reviewed 2026-05-08 18:11 UTC · model grok-4.3
The pith
ParaRNN structures recurrent networks as parallel small units with an additive representation that decouples dynamics into interpretable components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ParaRNN is composed of multiple small recurrent units and admits an additive representation that decouples the recurrent dynamics into interpretable components whose behavior can be characterized through recurrence features. This representation enables the model to be applied to nonparametric regression for time-dependent data while supporting efficient parallelization. The paper proves the approximation capacity of ParaRNN and derives non-asymptotic prediction error bounds in the nonparametric regression setting.
What carries the argument
The additive representation that decouples recurrent dynamics into interpretable components characterized by recurrence features.
If this is right
- The recurrence features of each component become directly usable for interpreting the model's behavior on time-dependent data.
- Training scales efficiently through parallelization across the independent recurrent units.
- The model can be deployed in nonparametric regression tasks with explicit approximation guarantees and error bounds.
- Empirical performance on sequential tasks remains comparable to standard RNNs while adding interpretability.
Where Pith is reading between the lines
- The additive decomposition may allow practitioners to diagnose which parts of the dynamics drive predictions in real applications.
- Similar additive structures could be tested on other sequential models to trade off some capacity for transparency without retraining from scratch.
- Recurrence features might serve as a basis for automated feature selection or for comparing multiple fitted models on the same series.
Load-bearing premise
Decomposing the recurrent dynamics into an additive collection of small units preserves enough expressive power to model complex time-dependent patterns without meaningful loss of accuracy.
What would settle it
A time-series dataset on which ParaRNN produces prediction errors that exceed the derived non-asymptotic bounds or that are substantially larger than those of a comparable vanilla RNN.
Figures


read the original abstract
The proliferation of large-scale and structurally complex data has spurred the integration of machine learning methods into statistical modeling. Recurrent neural networks (RNNs), a foundational class of models for time-dependent data, can be viewed as nonlinear extensions of classical autoregressive moving average models. Despite their flexibility and empirical success in machine learning, RNNs often suffer from limited interpretability and slow training, which hinders their use in statistics. This paper proposes the Parallelized RNN (ParaRNN), a novel model composed of multiple small recurrent units. ParaRNN admits an additive representation that decouples recurrent dynamics into interpretable components, whose behavior can be characterized through recurrence features. This interpretability enables its applications in nonparametric regression for time-dependent data, while the design also allows efficient parallelization. The approximation capacity and non-asymptotic prediction error bounds in a nonparametric regression setting are established for ParaRNN. Empirical results on three sequential modeling tasks further demonstrate that ParaRNN achieves performance comparable to vanilla RNNs while offering improved interpretability and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ParaRNN, a recurrent architecture built from multiple small parallel recurrent units that admits an additive representation decoupling the hidden-state dynamics into independent interpretable recurrence features. It claims to establish approximation capacity together with non-asymptotic prediction-error bounds for this model in a nonparametric regression setting for time-dependent data, while also demonstrating that the architecture permits efficient parallel training and achieves empirical performance comparable to vanilla RNNs on three sequential tasks.
Significance. If the approximation and error bounds remain valid once the additive restriction is properly accounted for, the work would supply a statistically grounded, interpretable alternative to standard RNNs that could be directly used in nonparametric time-series analysis. The combination of parallelizability, feature-level interpretability, and explicit non-asymptotic guarantees would be a useful contribution at the statistics–machine-learning interface.
major comments (2)
- [§3 and §4] §3 (Model definition) and §4 (Approximation theory): the additive decoupling of the recurrent map excludes cross-feature multiplicative interactions that a standard RNN can realize through its single recurrent matrix. The manuscript provides no comparison of covering numbers, Rademacher complexities, or approximation rates between the additive ParaRNN class and the unrestricted RNN class. Without such a result, it is unclear whether the derived non-asymptotic bounds are non-vacuous for the original modeling goal or merely apply to a strictly smaller function family.
- [§4, Theorem 2] §4, Theorem 2 (non-asymptotic bound): the proof sketch relies on the additive structure to obtain the stated rate, yet the paper does not verify that the extra interpretability term does not inflate the approximation error relative to a vanilla RNN. An explicit statement of the hypothesis-class restriction and its effect on the constant in the bound is required for the central claim.
minor comments (3)
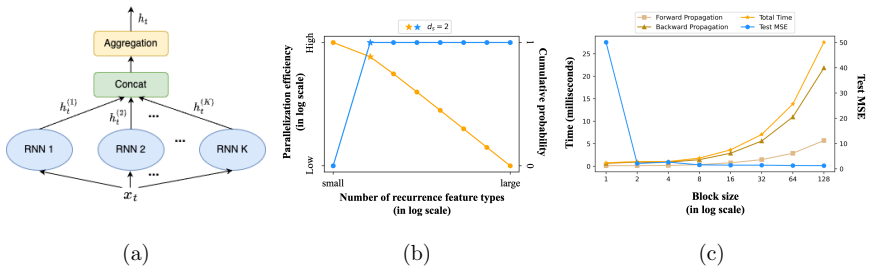
- [Figure 2] Figure 2 (recurrence-feature visualization): axis labels and the mapping from learned parameters to plotted features are not fully explained, making it difficult to reproduce the interpretability claim.
- [Experiments] Experiments section: the three tasks are described only at a high level; the precise data-generating processes, train/test splits, and hyper-parameter search ranges should be stated so that the “comparable performance” claim can be assessed.
- [Notation] Notation: the symbol for the parallel unit size is introduced without a clear relation to the total hidden dimension; a short table relating all dimensions would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, indicating planned revisions where appropriate. The responses focus on clarifying the scope of our theoretical results for the ParaRNN class.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Model definition) and §4 (Approximation theory): the additive decoupling of the recurrent map excludes cross-feature multiplicative interactions that a standard RNN can realize through its single recurrent matrix. The manuscript provides no comparison of covering numbers, Rademacher complexities, or approximation rates between the additive ParaRNN class and the unrestricted RNN class. Without such a result, it is unclear whether the derived non-asymptotic bounds are non-vacuous for the original modeling goal or merely apply to a strictly smaller function family.
Authors: We agree that the additive structure in ParaRNN excludes certain cross-feature multiplicative interactions possible in standard RNNs with a single recurrent matrix. This restriction is deliberate to achieve feature-level interpretability and parallel training. The non-asymptotic bounds of Theorem 2 are derived explicitly for the ParaRNN hypothesis class and are not claimed to hold for unrestricted RNNs. To address non-vacuity, we will add a paragraph in §4 noting that the empirical comparisons in §5 show ParaRNN matching vanilla RNN performance on the three tasks, indicating the restricted class remains expressive enough for the sequential modeling goals considered. A direct comparison of covering numbers or approximation rates between the two classes would constitute a separate theoretical contribution and lies outside the current scope. revision: partial
-
Referee: [§4, Theorem 2] §4, Theorem 2 (non-asymptotic bound): the proof sketch relies on the additive structure to obtain the stated rate, yet the paper does not verify that the extra interpretability term does not inflate the approximation error relative to a vanilla RNN. An explicit statement of the hypothesis-class restriction and its effect on the constant in the bound is required for the central claim.
Authors: The proof of Theorem 2 uses the additive decomposition to control the complexity of the function class and obtain the rate; no separate 'interpretability term' is added to the error bound itself. The bound applies to functions representable under the additive recurrent structure. We will revise §4 to include an explicit definition of the hypothesis class as the set of maps with additive recurrence features, together with a remark that the constants depend on the number of parallel units, the dimension of each unit, and the Lipschitz constants of the component activations. This restriction may increase the constant relative to a full RNN, but the resulting bound remains valid for the ParaRNN class and supports the nonparametric regression application. The interpretability benefit is a modeling choice rather than an additive penalty in the analysis. revision: yes
Circularity Check
ParaRNN derivation is self-contained with independent model design and bounds
full rationale
The paper defines ParaRNN via a novel additive decomposition into parallel recurrent units, then derives approximation capacity and non-asymptotic error bounds for this specific architecture in nonparametric regression. No step reduces by construction to its own inputs: the additive form is an explicit modeling choice, not a redefinition of the target function class, and the bounds are obtained from standard covering-number or complexity arguments applied to the new hypothesis class rather than from fitting parameters to the same data used for evaluation. No self-citation is invoked as a load-bearing uniqueness theorem, and no prediction is obtained by renaming a fitted quantity. The derivation chain therefore remains independent of the claimed results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Foundation/AlexanderDuality.lean and Cost/FunctionalEquationn/a — paper's density result is matrix-analysis (real Jordan form), unrelated to D=3 forcing or J-cost uniqueness unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1. It holds that M^2_d is dense in M_d, while M^1_d is not dense in M_d.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alemohammad, S., Wang, Z., Balestriero, R., and Baraniuk, R. (2021). The recurrent neural tangent kernel. In International Conference on Learning Representations
2021
-
[2]
J., Dau, H
Bagnall, A. J., Dau, H. A., Lines, J., Flynn, M., Large, J., Bostrom, A., Southam, P., and Keogh, E. J. (2018). The UEA multivariate time series classification archive, 2018. CoRR
2018
-
[3]
F., and Wooldridge, J
Bollerslev, T., Engle, R. F., and Wooldridge, J. M. (1988). A capital asset pricing model with time-varying covariances. Journal of Political Economy , 96(1):116--131
1988
-
[4]
Bradbury, J., Merity, S., Xiong, C., and Socher, R. (2017). Quasi-recurrent neural networks. In International Conference on Learning Representations
2017
-
[5]
C., Eisenstat, E., and Koop, G
Chan, J. C., Eisenstat, E., and Koop, G. (2016a). Large bayesian varmas. Journal of Econometrics , 192(2):374--390. Innovations in Multiple Time Series Analysis
-
[6]
V., and Vinyals, O
Chan, W., Jaitly, N., Le, Q. V., and Vinyals, O. (2016b). Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2016, Shanghai, China, March 20-25, 2016 , pages 4960--4964. IEEE
2016
-
[7]
Chang, B., Chen, M., Haber, E., and Chi, E. H. (2019). Antisymmetric RNN : A dynamical system view on recurrent neural networks. In International Conference on Learning Representations
2019
-
[8]
Chen, X., Chen, Y., Shen, Z., and Xiu, D. (2025). Recurrent neural networks for nonlinear time series. Chicago Booth Research Paper No. 26-01
2025
-
[9]
and Samworth, R
Chen, Y. and Samworth, R. J. (2016). Generalized additive and index models with shape constraints. Journal of the Royal Statistical Society Series B: Statistical Methodology , 78(4):729--754
2016
-
[10]
Cho, K., Van Merri \"e nboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y. (2014). Learning phrase representations using rnn encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 1724--1734
2014
-
[11]
Cohen-Karlik, E., Menuhin-Gruman, I., Giryes, R., Cohen, N., and Globerson, A. (2023). Learning low dimensional state spaces with overparameterized recurrent neural nets. In The Eleventh International Conference on Learning Representations
2023
-
[12]
Collins, J., Sohl - Dickstein, J., and Sussillo, D. (2017). Capacity and trainability in recurrent neural networks. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings . OpenReview.net
2017
-
[13]
and Chan, K
Cryer, J. and Chan, K. (2008). Time Series Analysis: With Applications in R . Springer Texts in Statistics. Springer New York
2008
-
[14]
G., Le, Q., and Salakhutdinov, R
Dai, Z., Yang, Z., Yang, Y., Carbonell, J. G., Le, Q., and Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 2978--2988
2019
-
[15]
Dennis, D., Acar, D. A. E., Mandikal, V., Sadasivan, V. S., Saligrama, V., Simhadri, H. V., and Jain, P. (2019). Shallow rnn: Accurate time-series classification on resource constrained devices. In Advances in Neural Information Processing Systems , volume 32
2019
-
[16]
Elman, J. L. (1990). Finding structure in time. Cognitive science , 14(2):179--211
1990
-
[17]
B., Azencot, O., Queiruga, A., Hodgkinson, L., and Mahoney, M
Erichson, N. B., Azencot, O., Queiruga, A., Hodgkinson, L., and Mahoney, M. W. (2021). Lipschitz recurrent neural networks. In International Conference on Learning Representations
2021
-
[18]
Farrell, M., Recanatesi, S., Moore, T., Lajoie, G., and Shea-Brown, E. (2022). Gradient-based learning drives robust representations in recurrent neural networks by balancing compression and expansion. Nature Machine Intelligence , 4(6):564--573
2022
-
[19]
H., Liang, T., and Misra, S
Farrell, M. H., Liang, T., and Misra, S. (2021). Deep neural networks for estimation and inference. Econometrica , 89(1):181--213
2021
-
[20]
Flunkert, V., Salinas, D., and Gasthaus, J. (2017). Deepar: Probabilistic forecasting with autoregressive recurrent networks. CoRR , abs/1704.04110
work page Pith review arXiv 2017
-
[21]
Fuller, W. A. (1996). Introduction to Statistical Time Series . Wiley series in probability and statistics. J. Wiley, New York, 2nd ed. edition
1996
-
[22]
Gu, A., Gulcehre, C., Paine, T., Hoffman, M., and Pascanu, R. (2020). Improving the gating mechanism of recurrent neural networks. In Proceedings of the 37th International Conference on Machine Learning , ICML'20. JMLR.org
2020
-
[23]
Haviv, D., Rivkind, A., and Barak, O. (2019). Understanding and controlling memory in recurrent neural networks. In Chaudhuri, K. and Salakhutdinov, R., editors, Proceedings of the 36th International Conference on Machine Learning , volume 97 of Proceedings of Machine Learning Research , pages 2663--2671. PMLR
2019
-
[24]
and Schmidhuber, J
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural computation , 9(8):1735--1780
1997
-
[25]
Horn, R. A. and Johnson, C. R. (2012). Matrix Analysis . Cambridge University Press, USA, 2nd edition
2012
-
[26]
Huang, F., Lu, K., CAI, Y., Qin, Z., Fang, Y., Tian, G., and Li, G. (2023). Encoding recurrence into transformers. In The Eleventh International Conference on Learning Representations
2023
-
[27]
Hutchins, D., Schlag, I., Wu, Y., Dyer, E., and Neyshabur, B. (2022). Block-recurrent transformers. In Advances in Neural Information Processing Systems
2022
-
[28]
Jiao, Y., Shen, G., Lin, Y., and Huang, J. (2023). Deep nonparametric regression on approximate manifolds: Nonasymptotic error bounds with polynomial prefactors . The Annals of Statistics , 51(2):691 -- 716
2023
- [29]
-
[30]
Khrulkov, V., Novikov, A., and Oseledets, I. (2018). Expressive power of recurrent neural networks. In International Conference on Learning Representations
2018
-
[31]
Krizhevsky, A., Hinton, G., et al. (2009). Learning multiple layers of features from tiny images
2009
-
[32]
Lecun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE , 86(11):2278--2324
1998
-
[33]
Li, S., Li, W., Cook, C., Zhu, C., and Gao, Y. (2018). Independently recurrent neural network (indrnn): Building a longer and deeper rnn. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 5457--5466. IEEE
2018
-
[34]
Lu, J., Shen, Z., Yang, H., and Zhang, S. (2021). Deep network approximation for smooth functions. SIAM Journal on Mathematical Analysis , 53(5):5465--5506
2021
-
[35]
Mao, H. H. (2022). Fine-tuning pre-trained transformers into decaying fast weights. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages 10236--10242. Association for Computational Linguistics
2022
-
[36]
and Cundy, C
Martin, E. and Cundy, C. (2018). Parallelizing linear recurrent neural nets over sequence length. arXiv.org
2018
-
[37]
Mikolov, T., Karafi \' a t, M., Burget, L., Cernock \' y , J., and Khudanpur, S. (2010). Recurrent neural network based language model. In Kobayashi, T., Hirose, K., and Nakamura, S., editors, INTERSPEECH 2010, 11th Annual Conference of the International Speech Communication Association , pages 1045--1048
2010
-
[38]
Mohri, M., Rostamizadeh, A., and Talwalkar, A. (2018). Foundations of Machine Learning, second edition . Adaptive Computation and Machine Learning series. MIT Press
2018
-
[39]
L., Gu, A., Fernando, A., Gulcehre, C., Pascanu, R., and De, S
Orvieto, A., Smith, S. L., Gu, A., Fernando, A., Gulcehre, C., Pascanu, R., and De, S. (2023). Resurrecting recurrent neural networks for long sequences. In Proceedings of the 40th International Conference on Machine Learning , ICML'23
2023
-
[40]
G., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M
Peng, B., Alcaide, E., Anthony, Q. G., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M. N., Derczynski, L., Du, X., Grella, M., GV, K. K., He, X., Hou, H., Kazienko, P., Kocon, J., Kong, J., Koptyra, B., Lau, H., Lin, J., Mantri, K. S. I., Mom, F., Saito, A., Song, G., Tang, X., Wind, J. S., Wo \'z niak, S., Zhang, Z., Zhou, Q., Zhu...
2023
-
[41]
Peng, H., Pappas, N., Yogatama, D., Schwartz, R., Smith, N., and Kong, L. (2021). Random feature attention. In International Conference on Learning Representations
2021
-
[42]
Qiao, S., Wang, H., Liu, C., Shen, C., and Yuille, A. (2019). Stabilizing gradients for deep neural networks via efficient svd parametrization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 11494--11503
2019
-
[43]
Qin, Z., Yang, S., and Zhong, Y. (2023). Hierarchically gated recurrent neural network for sequence modeling. In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[44]
Rusch, T. K. and Mishra, S. (2021). Unicornn: A recurrent model for learning very long time dependencies. In Meila, M. and Zhang, T., editors, Proceedings of the 38th International Conference on Machine Learning , volume 139 of Proceedings of Machine Learning Research , pages 9168--9178. PMLR
2021
-
[45]
K., Mishra, S., Erichson, N
Rusch, T. K., Mishra, S., Erichson, N. B., and Mahoney, M. W. (2022). Long expressive memory for sequence modeling. In International Conference on Learning Representations
2022
-
[46]
Schmidt-Hieber, J. (2020). Nonparametric regression using deep neural networks with ReLU activation function . The Annals of Statistics , 48(4):1875 -- 1897
2020
-
[47]
Shaw, P., Uszkoreit, J., and Vaswani, A. (2018). Self-attention with relative position representations. In Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages 464--468. Association for Computational Linguistics
2018
-
[48]
Shen, Z., Yang, H., and Zhang, S. (2020). Deep network approximation characterized by number of neurons. Communications in Computational Physics , 28(5):1768--1811
2020
-
[49]
Song, C., Hwang, G., Lee, J., and Kang, M. (2023). Minimal width for universal property of deep rnn. Journal of Machine Learning Research , 24(121):1--41
2023
-
[50]
Stone, C. J. (1982). Optimal global rates of convergence for nonparametric regression. The Annals of Statistics , 10(4):1040--1053
1982
-
[51]
Sutskever, I., Vinyals, O., and Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems , volume 27
2014
-
[52]
Suzuki, T. (2018). Adaptivity of deep relu network for learning in besov and mixed smooth besov spaces: optimal rate and curse of dimensionality
2018
-
[53]
and Ollivier, Y
Tallec, C. and Ollivier, Y. (2018). Can recurrent neural networks warp time? In International Conference on Learning Representations
2018
-
[54]
Tu, Z., He, F., and Tao, D. (2020). Understanding generalization in recurrent neural networks. In International Conference on Learning Representations
2020
-
[55]
N., Kaiser, L
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. u., and Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc
2017
-
[56]
Wang, D., Zheng, Y., Lian, H., and Li, G. (2022). High-dimensional vector autoregressive time series modeling via tensor decomposition. Journal of the American Statistical Association , 117(539):1338--1356
2022
-
[57]
Yuan, M. (2011). On the identifiability of additive index models. Statistica Sinica , 21(4):1901--1911
2011
-
[58]
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., and Zhang, W. (2021). Informer: Beyond efficient transformer for long sequence time-series forecasting. Proceedings of the AAAI Conference on Artificial Intelligence , 35(12):11106--11115
2021
-
[59]
and Bartlett, P
Anthony, M. and Bartlett, P. L. (2009). Neural Network Learning: Theoretical Foundations . Cambridge University Press, USA, 1st edition
2009
-
[60]
L., Harvey, N., Liaw, C., and Mehrabian, A
Bartlett, P. L., Harvey, N., Liaw, C., and Mehrabian, A. (2019). Nearly-tight vc-dimension and pseudodimension bounds for piecewise linear neural networks. Journal of Machine Learning Research , 20(63):1--17
2019
-
[61]
Edelman, A. (1997). The probability that a random real Gaussian matrix has k real eigenvalues, related distributions, and the Circular law . Journal of Multivariate Analysis , 60(2):203--232
1997
-
[62]
Györfi, L., Kohler, M., Krzyzak, A., and Walk, H. (2002). A Distribution-Free Theory of Nonparametric Regression. Springer series in statistics. Springer
2002
-
[63]
Hartfiel, D. J. (1995). Dense sets of diagonalizable matrices. Proceedings of the American Mathematical Society , 123(6):1669--1672
1995
-
[64]
Meyer, C. D. (2023). Matrix Analysis and Applied Linear Algebra, Second Edition . Society for Industrial and Applied Mathematics, Philadelphia, PA
2023
-
[65]
and Sun, J
Stewart, G. and Sun, J. (1990). Matrix Perturbation Theory . Computer Science and Scientific Computing. Elsevier Science
1990
-
[66]
and Vu, V
Tao, T. and Vu, V. (2017). Random matrices have simple spectrum. Comb. , 37(3):539--553
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.