Recognition: 2 theorem links
An Empirical Study of Agent Skills for Healthcare: Practice, Gaps, and Governance
Pith reviewed 2026-05-08 18:55 UTC · model grok-4.3
The pith
Public healthcare agent skills focus on patient-facing workflows and monitoring rather than diagnostic and treatment tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
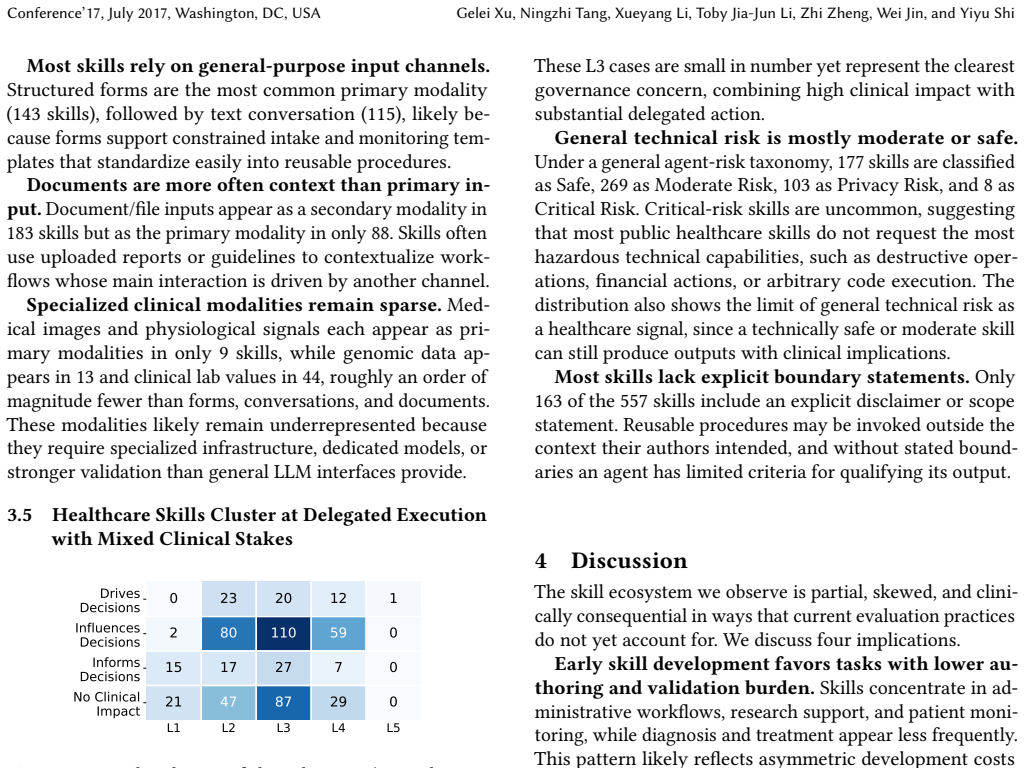
Drawing on 557 healthcare-related skills filtered from public sources and annotated for function, deployment context, autonomy, and safety, the study finds that public healthcare skills emphasize patient-facing workflow automation and monitoring rather than the diagnostic and treatment-oriented tasks foregrounded in research. Coverage of the healthcare lifecycle and specialized clinical inputs remains uneven, and general technical risk does not reliably capture clinical risk. These findings indicate that healthcare skills form a procedural layer not yet addressed by current benchmarks and risk frameworks.
What carries the argument
Annotation of skills along ten dimensions that assess function, deployment context, autonomy, and safety to map real-world capabilities.
Load-bearing premise
The selected 557 skills accurately represent broader healthcare agent practices and the ten dimensions capture all essential aspects of clinical function and risk.
What would settle it
Finding a large set of deployed healthcare agent skills that predominantly support diagnostic and treatment tasks would contradict the observed emphasis on workflow automation.
Figures



read the original abstract
Healthcare automation is shaped by local procedures and organizational constraints, so agent capabilities rarely transfer unchanged across settings. Agent skills, self-contained directories that package reusable procedures for AI agents, are emerging as a procedural layer for adapting healthcare agents across diverse healthcare settings. We present the first empirical analysis of healthcare agent skills, drawing on 557 healthcare-related skills filtered from 58,159 public skills on ClawHub and annotated along ten dimensions covering function, deployment context, autonomy, and safety. We find that public healthcare skills emphasize patient-facing workflow automation and monitoring rather than the diagnostic and treatment-oriented tasks foregrounded in healthcare-agent research; coverage of the healthcare lifecycle and specialized clinical inputs remains uneven; and general technical risk does not reliably capture clinical risk. These findings position healthcare skills as a procedural layer not yet addressed by current benchmarks and risk frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first empirical analysis of healthcare agent skills, filtering 557 healthcare-related skills from 58,159 public skills on ClawHub and annotating them along ten dimensions covering function, deployment context, autonomy, and safety. Key findings are that public skills emphasize patient-facing workflow automation and monitoring over diagnostic/treatment tasks foregrounded in research, that coverage of the healthcare lifecycle and specialized clinical inputs is uneven, and that general technical risk does not reliably capture clinical risk. The work positions healthcare skills as a procedural layer not yet addressed by current benchmarks and risk frameworks.
Significance. If the methodology and sample prove representative, this is a valuable first large-scale empirical mapping of public healthcare agent skills. It provides concrete evidence of mismatches between deployed capabilities and research priorities, plus gaps in lifecycle coverage and risk assessment, which could directly inform the design of future benchmarks, evaluation suites, and governance frameworks for healthcare agents. The use of public ClawHub data and multi-dimensional annotation schema are clear strengths for reproducibility and breadth.
major comments (3)
- [Methods] Methods (filtering step): The reduction from 58,159 to 557 skills is described only at the level of the final count and the label 'healthcare-related.' No explicit keyword list, inclusion/exclusion rules, manual review protocol, or validation against external healthcare skill taxonomies is provided. Because the headline claims about emphasis on patient-facing workflows versus diagnostics rest entirely on this filtered sample, the absence of these details is load-bearing for the representativeness argument.
- [Methods] Methods (annotation process): The ten annotation dimensions are introduced without reporting inter-annotator agreement (e.g., Cohen's kappa or percentage agreement) or a codebook with decision rules for ambiguous cases. This directly affects the reliability of the reported distributions on autonomy, safety, and clinical-input coverage that support the central contrast with healthcare-agent research.
- [Results] Results/Discussion (risk assessment): The claim that 'general technical risk does not reliably capture clinical risk' is asserted on the basis of the annotations, yet the manuscript provides no separate operationalization or coding rubric for clinical risk factors such as regulatory classification, EHR interoperability constraints, or liability exposure. Without this, the conclusion that technical risk frameworks are insufficient cannot be evaluated.
minor comments (2)
- [Abstract] The abstract states the sample size and annotation dimensions but does not preview the filtering criteria or inter-annotator reliability; adding one sentence on these would improve clarity for readers.
- [Results] Table or figure captions for the annotation results should explicitly state the total N=557 and any missing-value handling so that percentages are immediately interpretable.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript. The feedback identifies key areas where additional methodological details and clarifications will improve the paper's transparency and impact. We address each major comment below and will make the corresponding revisions.
read point-by-point responses
-
Referee: [Methods] Methods (filtering step): The reduction from 58,159 to 557 skills is described only at the level of the final count and the label 'healthcare-related.' No explicit keyword list, inclusion/exclusion rules, manual review protocol, or validation against external healthcare skill taxonomies is provided. Because the headline claims about emphasis on patient-facing workflows versus diagnostics rest entirely on this filtered sample, the absence of these details is load-bearing for the representativeness argument.
Authors: We agree that the filtering methodology requires more explicit documentation to substantiate the representativeness of the 557 healthcare-related skills. In the revised manuscript, we will provide the complete keyword list used for filtering, detailed inclusion and exclusion rules, the protocol for any manual review, and any validation performed against external healthcare skill taxonomies. This addition will directly support the claims regarding the emphasis on patient-facing workflows. revision: yes
-
Referee: [Methods] Methods (annotation process): The ten annotation dimensions are introduced without reporting inter-annotator agreement (e.g., Cohen's kappa or percentage agreement) or a codebook with decision rules for ambiguous cases. This directly affects the reliability of the reported distributions on autonomy, safety, and clinical-input coverage that support the central contrast with healthcare-agent research.
Authors: We recognize that reporting inter-annotator agreement and providing a codebook are critical for establishing the reliability of the annotations. The revised manuscript will include a comprehensive description of the annotation process, the full codebook with decision rules for handling ambiguous cases, and inter-annotator agreement metrics (e.g., Cohen's kappa or percentage agreement). These details will bolster confidence in the distributions reported for autonomy, safety, and clinical inputs. revision: yes
-
Referee: [Results] Results/Discussion (risk assessment): The claim that 'general technical risk does not reliably capture clinical risk' is asserted on the basis of the annotations, yet the manuscript provides no separate operationalization or coding rubric for clinical risk factors such as regulatory classification, EHR interoperability constraints, or liability exposure. Without this, the conclusion that technical risk frameworks are insufficient cannot be evaluated.
Authors: We appreciate the referee's observation that a more explicit operationalization of clinical risk would strengthen our analysis. Although the annotations on safety and clinical inputs were designed to illustrate the distinction from general technical risk, we will revise the manuscript to include a dedicated operationalization and coding rubric for clinical risk factors, incorporating elements such as regulatory classification, EHR interoperability, and liability exposure. This will make the basis for our conclusions clearer and more evaluable. revision: yes
Circularity Check
No circularity: purely empirical analysis of external public data
full rationale
The paper performs a descriptive empirical study: it filters 557 healthcare-related skills from the external ClawHub repository (58,159 total) and annotates them along ten dimensions covering function, context, autonomy, and safety. No equations, derivations, fitted parameters, predictions, or self-citation chains appear in the provided text. All claims (emphasis on patient-facing workflow, uneven lifecycle coverage, mismatch between technical and clinical risk) are observational reports drawn from the sampled external data rather than reductions to the paper's own inputs or prior self-work. The study is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 557 skills filtered from ClawHub constitute a representative sample of healthcare agent capabilities.
- domain assumption The ten annotation dimensions adequately capture function, deployment context, autonomy, and safety for clinical relevance.
Reference graph
Works this paper leans on
-
[1]
2025 , howpublished =
Anthropic , title =. 2025 , howpublished =
2025
-
[2]
Agent skills: A data-driven analysis of claude skills for extending large language model functionality , author=. arXiv preprint arXiv:2602.08004 , year=
-
[3]
Journal of Biomedical Informatics , pages=
A comprehensive survey of AI Agents in Healthcare , author=. Journal of Biomedical Informatics , pages=. 2026 , publisher=
2026
-
[4]
Authorea Preprints , year=
Agent Skills from the Perspective of Procedural Memory: A Survey , author=. Authorea Preprints , year=
-
[5]
arXiv preprint arXiv:2508.19322 , year=
At-cxr: Uncertainty-aware agentic triage for chest x-rays , author=. arXiv preprint arXiv:2508.19322 , year=
-
[6]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Reflectool: Towards reflection-aware tool-augmented clinical agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
Communications Medicine , year=
Simulated patient systems powered by large language model-based AI agents offer potential for transforming medical education , author=. Communications Medicine , year=
-
[8]
Programming by Chat: A Large-Scale Behavioral Analysis of 11,579 Real-World AI-Assisted IDE Sessions , author=. arXiv preprint arXiv:2604.00436 , year=
-
[9]
Advances in Therapy , volume=
A narrative review of the patient journey through the lens of non-communicable diseases in low-and middle-income countries , author=. Advances in Therapy , volume=. 2020 , publisher=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.