Recognition: unknown
Cool-chic 5.0: Faster Encoding and Inter-Feature Entropy Modeling for Overfitted Image Compression
Pith reviewed 2026-05-08 02:14 UTC · model grok-4.3
The pith
Cool-chic 5.0 updates the decoder architecture and optimization to deliver better image compression with one-tenth the encoding iterations of prior overfitted methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cool-chic 5.0 reaches superior rate-distortion performance by combining an updated decoder that incorporates inter-feature entropy modeling with a more efficient optimization schedule, allowing it to surpass all previous overfitted codecs using only one-tenth as many encoding iterations, to reduce bitrate by 11 percent relative to H.266/VVC, and to remain competitive with autoencoders such as MLIC++ at 250 times lower decoding complexity.
What carries the argument
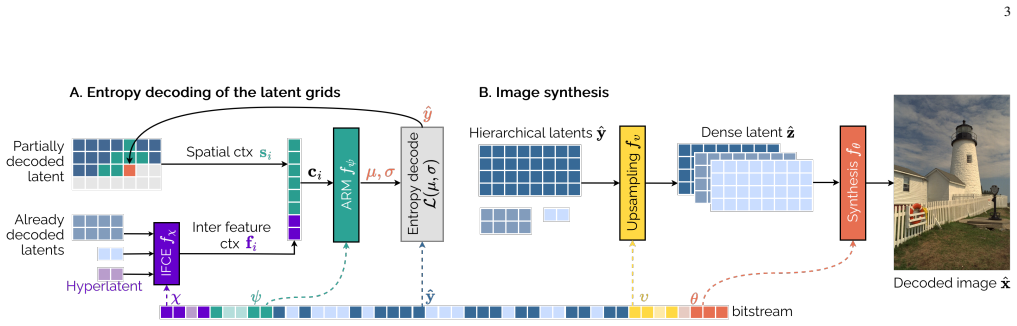
Inter-feature entropy modeling inside the content-tailored decoder, which captures statistical dependencies across feature maps to produce tighter probability estimates for arithmetic coding.
If this is right
- Only one-tenth the encoding iterations are needed to exceed the compression of earlier overfitted codecs.
- Bitrate drops by 11 percent compared with the conventional H.266/VVC standard under the reported test conditions.
- Rate-distortion performance stays competitive with modern autoencoders while decoding complexity falls by a factor of 250.
- The full implementation is released as open source, enabling direct replication and extension.
Where Pith is reading between the lines
- The reduced encoding cost could make content-specific compression practical on devices where compute time is limited but high quality is required.
- The same inter-feature modeling pattern might be applied to other media such as video to obtain similar complexity reductions.
- Public code release allows independent verification and possible integration into existing compression pipelines.
Load-bearing premise
The measured gains come from the stated decoder changes and optimization schedule rather than from any unmentioned differences in training data, test conditions, or implementation details.
What would settle it
Repeating the experiments while restricting Cool-chic 5.0 to the same number of encoding iterations used by the previous best overfitted codec and finding that the rate advantage disappears would falsify the central claim.
Figures







read the original abstract
Overfitted codecs compress an image by learning a decoder tailored to the content during the encoding. As such, they trade increased encoding complexity for strong compression performance and low decoding complexity. This work introduces Cool-chic 5.0, the latest version in the Cool-chic series of overfitted codecs, featuring an updated decoder architecture and an improved optimization process. Cool-chic 5.0 outperforms all overfitted codecs with 10 times less encoding iterations. It offers -11% rate reduction compared to the state-of-the-art conventional codec H.266/VVC. It is also competitive with modern autoencoders such as MLIC++ while featuring a decoding complexity 250 times lower. This work is made open-source at https://github.com/Orange-OpenSource/Cool-Chic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Cool-chic 5.0, an updated overfitted image codec that incorporates a revised decoder architecture, inter-feature entropy modeling, and refined optimization procedures. It claims to surpass prior overfitted codecs in rate-distortion performance while requiring only one-tenth the encoding iterations, to deliver an 11% rate saving relative to H.266/VVC, and to remain competitive with learned autoencoders such as MLIC++ at 250 times lower decoding complexity. The implementation is released as open-source software.
Significance. If the reported gains are reproducible under matched experimental conditions, the work meaningfully improves the practicality of overfitted compression by simultaneously lowering encoding cost and raising compression efficiency. The open-source release and the explicit architectural diagrams plus loss formulations constitute a clear strength, enabling direct verification and extension by the community.
major comments (2)
- [Section 4 (Experimental results) and Section 3.2 (Inter-feature entropy modeling)] The central performance claims rest on the inter-feature entropy model and the updated decoder; however, the manuscript does not provide an ablation that isolates the contribution of each change (e.g., entropy modeling alone versus decoder redesign) to the observed 10× iteration reduction and rate savings. Without this breakdown, it is difficult to attribute the gains precisely to the stated innovations.
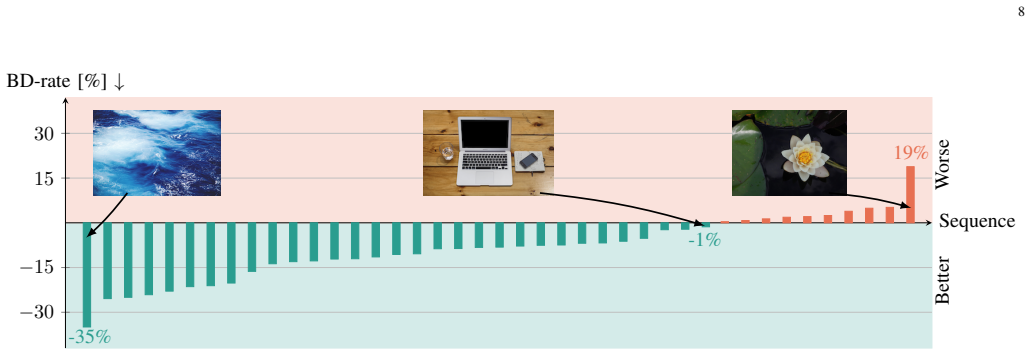
- [Table 2 and Figure 5] Table 2 and the associated RD curves compare against H.266/VVC and MLIC++; the text should explicitly state the VVC encoder configuration (preset, intra-only flag, rate-control mode) and confirm that all methods were evaluated on identical test images and with the same distortion metric (PSNR or MS-SSIM) at the same operating points.
minor comments (3)
- [Abstract and Section 4.1] The abstract states “10 times less encoding iterations” without referencing the exact baseline iteration count used for the comparison; this detail should appear in the main text near the first mention of the result.
- [Section 3.2 and Equation (5)] Notation for the entropy parameters (e.g., the definition of the inter-feature context vector) is introduced in Section 3.2 but is not consistently reused in the loss-function equation; a single consolidated notation table would improve readability.
- [Section 5 (Conclusion)] The open-source repository link is given, but the manuscript should include a brief statement confirming that the released code reproduces the exact numbers reported in Tables 1–3.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The comments highlight important aspects for clarity and attribution, which we address below. We will incorporate the requested details and additions in the revised manuscript.
read point-by-point responses
-
Referee: [Section 4 (Experimental results) and Section 3.2 (Inter-feature entropy modeling)] The central performance claims rest on the inter-feature entropy model and the updated decoder; however, the manuscript does not provide an ablation that isolates the contribution of each change (e.g., entropy modeling alone versus decoder redesign) to the observed 10× iteration reduction and rate savings. Without this breakdown, it is difficult to attribute the gains precisely to the stated innovations.
Authors: We agree that an explicit ablation isolating the inter-feature entropy modeling from the decoder redesign would improve attribution of the gains in rate savings and encoding iterations. The current manuscript presents the combined Cool-chic 5.0 system, but we will add a dedicated ablation subsection (or table) in the revised version. This will report separate results for the entropy model alone, the decoder changes alone, and their combination, using the same test conditions to quantify each component's contribution to the 10× iteration reduction and BD-rate improvements. revision: yes
-
Referee: [Table 2 and Figure 5] Table 2 and the associated RD curves compare against H.266/VVC and MLIC++; the text should explicitly state the VVC encoder configuration (preset, intra-only flag, rate-control mode) and confirm that all methods were evaluated on identical test images and with the same distortion metric (PSNR or MS-SSIM) at the same operating points.
Authors: We appreciate this request for explicit experimental details. In the revised manuscript, we will add a clear statement in Section 4 (and in the captions of Table 2 and Figure 5) specifying the VVC configuration: the 'faster' preset, intra-only mode enabled, and constant quality rate control with QP values matched to the target rates. We confirm that all codecs (including Cool-chic 5.0, prior overfitted methods, and MLIC++) were evaluated on identical test images from the standard datasets using PSNR as the distortion metric at the same operating points. These clarifications will be inserted to ensure full reproducibility. revision: yes
Circularity Check
Empirical engineering paper; no circular derivation
full rationale
The paper introduces Cool-chic 5.0 as an updated overfitted image codec with new decoder architecture, inter-feature entropy modeling, and optimization tweaks. All central claims (10x fewer iterations, -11% rate vs H.266/VVC, competitiveness with MLIC++) are supported by reported RD tables, complexity measurements, and an open-source repository for direct reproduction. No mathematical derivation chain exists that could reduce predictions to fitted inputs or self-citations by construction. Minor series self-reference is present but not load-bearing for any result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cool- chic: Coordinate-based low complexity hierarchical image codec,
T. Ladune, P. Philippe, F. Henry, G. Clare, and T. Leguay, “Cool- chic: Coordinate-based low complexity hierarchical image codec,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 13 515–13 522
2023
-
[2]
Mlic++: Linear complexity multi-reference entropy modeling for learned image compression,
W. Jiang, J. Yang, Y . Zhai, F. Gao, and R. Wang, “Mlic++: Linear complexity multi-reference entropy modeling for learned image compression,”ACM Trans. Multimedia Comput. Commun. Appl., vol. 21, no. 5, May 2025. [Online]. Available: https://doi.org/10.1145/3719011
-
[3]
Learned image compression with hierarchical progressive context modeling,
Y . Li, H. Zhang, L. Li, and D. Liu, “Learned image compression with hierarchical progressive context modeling,”CoRR, vol. abs/2507.19125,
-
[4]
Learned image compression with hierarchical progressive context modeling,
[Online]. Available: https://doi.org/10.48550/arXiv.2507.19125
-
[5]
Improved encoding for overfitted video codecs,
P. Philippe, T. Ladune, G. Clare, F. Henry, T. Blard, and T. Leguay, “Upsampling improvement for overfitted neural coding,” inIEEE International Symposium on Circuits and Systems, ISCAS 2025, London, United Kingdom, May 25-28, 2025. IEEE, 2025, pp. 1–5. [Online]. Available: https://doi.org/10.1109/ISCAS56072.2025.11044014
-
[6]
MoRIC: A modular region-based implicit codec for image compression,
G. Li, H. Wu, and D. Gunduz, “MoRIC: A modular region-based implicit codec for image compression,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=IFjjzfkC65
2025
-
[7]
H. Wu, G. Chen, P. L. Dragotti, and D. G ¨und¨uz, “Lotterycodec: Searching the implicit representation in a random network for low-complexity image compression,” 2025. [Online]. Available: https: //arxiv.org/abs/2507.01204
-
[8]
The Cool-chic image and video codec,
O. Research, “The Cool-chic image and video codec,” https://github.com/Orange-OpenSource/Cool-Chic
-
[9]
C3: High-performance and low-complexity neural compression from a single image or video,
H. Kim, M. Bauer, L. Theis, J. R. Schwarz, and E. Dupont, “C3: High-performance and low-complexity neural compression from a single image or video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 9347– 9358
2024
-
[10]
CLIC Challenge on Learned Image Coding 2020,
CLIC20, “CLIC Challenge on Learned Image Coding 2020,” http://clic.compression.cc/2021/tasks/index.html, 2020
2020
-
[11]
Implicit neural representations with periodic activation functions,
V . Sitzmann, J. N. P. Martel, A. W. Bergman, D. B. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation functions,” inAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. B...
2020
-
[12]
Coin: Compression with implicit neural representations.arXiv preprint arXiv:2103.03123, 2021
E. Dupont, A. Golinski, M. Alizadeh, Y . W. Teh, and A. Doucet, “Coin: Compression with implicit neural representations,”ArXiv, vol. abs/2103.03123, 2021. [Online]. Available: https://api.semanticscholar. org/CorpusID:232110691
-
[13]
COIN++: neural compression across modalities,
E. Dupont, H. Loya, M. Alizadeh, A. Golinski, Y . W. Teh, and A. Doucet, “COIN++: neural compression across modalities,” Trans. Mach. Learn. Res., vol. 2022, 2022. [Online]. Available: https://openreview.net/forum?id=NXB0rEM2Tq
2022
-
[14]
Implicit neural representations for image compression,
Y . Str ¨umpler, J. Postels, R. Yang, L. V . Gool, and F. Tombari, “Implicit neural representations for image compression,” inComputer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXVI, ser. Lecture Notes in Computer Science, S. Avidan, G. J. Brostow, M. Ciss ´e, G. M. Farinella, and T. Hassner, E...
-
[15]
Low-complexity overfitted neural image codec,
T. Leguay, T. Ladune, P. Philippe, G. Clare, F. Henry, and O. D ´eforges, “Low-complexity overfitted neural image codec,” in2023 IEEE 25th International Workshop on Multimedia Signal Processing (MMSP), 2023, pp. 1–6
2023
-
[16]
Multiresolution contexts for implicit neural codecs,
H. B. Dogaroglu, C. E. Wiedemann, and E. Steinbach, “Multiresolution contexts for implicit neural codecs,” in2025 Picture Coding Symposium (PCS 2025), Dec 2025
2025
-
[17]
Hypercool: Reducing encoding cost in overfitted codecs with hypernetworks,
P. B. Tatch ´e, T. Aczel, T. Ladune, and R. Wattenhofer, “Hypercool: Reducing encoding cost in overfitted codecs with hypernetworks,” in AAAI 2026 Workshop on Machine Learning for Wireless Communication and Networks (ML4Wireless), 2026. [Online]. Available: https: //openreview.net/forum?id=nhl96GVc6E
2026
-
[18]
Fitted neural lossless image compres- sion,
Z. Zhang, Z. Chen, and S. Liu, “Fitted neural lossless image compres- sion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 23 249–23 258
2025
-
[19]
Progressive COOL- CHIC: efficient decoding for dual-resolution images,
M. Benjak, Y . Chen, W. Peng, and J. Ostermann, “Progressive COOL- CHIC: efficient decoding for dual-resolution images,” inInternational Conference on Visual Communications and Image Processing, VCIP 2025, Klagenfurt, Austria, December 1-4, 2025. IEEE, 2025, pp. 1–5. [Online]. Available: https://doi.org/10.1109/VCIP67698.2025.11396837
-
[20]
Scalable COOL-CHIC: dual-resolution images from a single bitstream,
——, “Scalable COOL-CHIC: dual-resolution images from a single bitstream,” inPicture Coding Symposium, PCS 2025, Aachen, Germany, December 8-11, 2025. IEEE, 2025, pp. 1–5. [Online]. Available: https://doi.org/10.1109/PCS65673.2025.11417678
-
[21]
Objects disentangled implicit neural representation for image coding,
C. Lin, Y . Wu, Y . Li, J. Li, K. Zhang, and L. Zhang, “Objects disentangled implicit neural representation for image coding,” in Proceedings of the 3rd International Workshop on Multimedia Content Generation and Evaluation: New Methods and Practice, ser. McGE ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 147–155. [Online]. Availa...
-
[22]
Good, cheap, and fast: Overfitted image compression with wasserstein distortion,
J. Ball ´e, L. Versari, E. Dupont, H. Kim, and M. Bauer, “Good, cheap, and fast: Overfitted image compression with wasserstein distortion,” 2025, https://arxiv.org/abs/2412.00505
-
[23]
Perceptually optimised cool-chic for CLIC 2025,
P. Philippe, T. Ladune, G. Clare, and F. E. Henry, “Perceptually optimised cool-chic for CLIC 2025,” in7th Challenge on Learned Image Compression, 2025. [Online]. Available: https://openreview.net/ forum?id=7S19tNWnRO
2025
-
[24]
Nerv: neural representations for videos,
H. Chen, B. He, H. Wang, Y . Ren, S.-N. Lim, and A. Shrivastava, “Nerv: neural representations for videos,” inProceedings of the 35th International Conference on Neural Information Processing Systems, ser. NIPS ’21. Red Hook, NY , USA: Curran Associates Inc., 2024
2024
-
[25]
Hnerv: A hybrid neural representation for videos,
H. Chen, M. Gwilliam, S.-N. Lim, and A. Shrivastava, “Hnerv: A hybrid neural representation for videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[26]
Hinerv: video compression with hierarchical encoding-based neural representation,
H. M. Kwan, G. Gao, F. Zhang, A. Gower, and D. Bull, “Hinerv: video compression with hierarchical encoding-based neural representation,” in Proceedings of the 37th International Conference on Neural Information 11 Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2024
2024
-
[27]
Ffnerv: Flow-guided frame- wise neural representations for videos,
J. C. Lee, D. Rho, J. H. Ko, and E. Park, “Ffnerv: Flow-guided frame- wise neural representations for videos,” inProceedings of the 31st ACM International Conference on Multimedia, ser. MM ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 7859–7870. [Online]. Available: https://doi.org/10.1145/3581783.3612444
-
[28]
Nvrc: Neural video representation compression,
H. M. Kwan, G. Gao, F. Zhang, A. Gower, and D. Bull, “Nvrc: Neural video representation compression,” 2024. [Online]. Available: https://arxiv.org/abs/2409.07414
-
[29]
Cool-chic video: Learned video coding with 800 parameters,
T. Leguay, T. Ladune, P. Philippe, and O. D ´eforges, “Cool-chic video: Learned video coding with 800 parameters,” inData Compression Con- ference, DCC 2024, Snowbird, UT, USA, March 19-22, 2024, A. Bilgin, J. E. Fowler, J. Serra-Sagrist `a, Y . Ye, and J. A. Storer, Eds. IEEE, 2024, pp. 23–32, https://doi.org/10.1109/DCC58796.2024.00010
-
[30]
Improved encoding for overfitted video codecs,
——, “Improved encoding for overfitted video codecs,” inIEEE International Symposium on Circuits and Systems, ISCAS 2025, London, United Kingdom, May 25-28, 2025. IEEE, 2025, pp. 1–5. [Online]. Available: https://doi.org/10.1109/ISCAS56072.2025.11043596
-
[31]
Cnvc: A compact neural video codec with instance-level adaptation,
Y . Li, C. Lin, J. Li, K. Zhang, and L. Zhang, “Cnvc: A compact neural video codec with instance-level adaptation,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 4, pp. 5525– 5537, 2026
2026
-
[32]
SOAP: improving and stabilizing shampoo using adam for language modeling,
N. Vyas, D. Morwani, R. Zhao, I. Shapira, D. Brandfonbrener, L. Janson, and S. M. Kakade, “SOAP: improving and stabilizing shampoo using adam for language modeling,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=IDxZhXrpNf
2025
-
[33]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Y . Bengio and Y . LeCun, Eds., 2015. [Online]. Available: http://arxiv.org/abs/1412.6980
work page internal anchor Pith review arXiv 2015
-
[34]
Universally quantized neural compression,
E. Agustsson and L. Theis, “Universally quantized neural compression,” inAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds.,
2020
-
[35]
Available: https://proceedings.neurips.cc/paper/2020/ hash/92049debbe566ca5782a3045cf300a3c-Abstract.html
[Online]. Available: https://proceedings.neurips.cc/paper/2020/ hash/92049debbe566ca5782a3045cf300a3c-Abstract.html
2020
-
[36]
Joint autoregressive and hierarchical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” in Advances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc., 2018. [Online]. Available: https://proceedings.neurips.cc/p...
2018
-
[37]
Variational image compression with a scale hyperprior,
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” in6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018. [Online]. Available: https://openreview.net/forum?id=rkcQFMZRb
2018
-
[38]
Deep Residual Learning for Image Recognition , isbn =
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV , USA, June 27-30, 2016. IEEE Computer Society, 2016, pp. 770–778. [Online]. Available: https://doi.org/10.1109/CVPR.2016.90
-
[39]
Lossy image compres- sion with compressive autoencoders,
L. Theis, W. Shi, A. Cunningham, and F. Husz ´ar, “Lossy image compres- sion with compressive autoencoders,”ArXiv, vol. abs/1703.00395, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:8394195
-
[40]
Soft then hard: Rethinking the quantization in neural image compression,
Z. Guo, Z. Zhang, R. Feng, and Z. Chen, “Soft then hard: Rethinking the quantization in neural image compression,” in International Conference on Machine Learning, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:233210102
2021
-
[41]
Y . Zhang and F. Zhu, “Leveraging second-order curvature for efficient learned image compression: Theory and empirical evidence,”CoRR, vol. abs/2601.20769, 2026. [Online]. Available: https://doi.org/10. 48550/arXiv.2601.20769
-
[42]
Learned image compression with discretized gaussian mixture likelihoods and attention modules,
Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Learned image compression with discretized gaussian mixture likelihoods and attention modules,”2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7936–7945, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:209862064
2020
-
[43]
Elic: Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding,
D. He, Z. Yang, W. Peng, R. Ma, H. Qin, and Y . Wang, “Elic: Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding,”2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5708–5717, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:247594672
2022
-
[44]
Towards practical real-time neural video compression,
Z. Jia, B. Li, J. Li, W. Xie, L. Qi, H. Li, and Y . Lu, “Towards practical real-time neural video compression,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-25, 2024, 2025
2025
-
[45]
Kodak image dataset,
“Kodak image dataset,”http://r0k.us/graphics/kodak/
-
[46]
Overview of the Versatile Video Coding (VVC) standard and its applications,
B. Bross, Y .-K. Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J.-R. Ohm, “Overview of the Versatile Video Coding (VVC) standard and its applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3736–3764, 2021
2021
-
[47]
Low-rank quantization-aware training for LLMs
Y . Bondarenko, R. D. Chiaro, and M. Nagel, “Low-rank quantization- aware training for llms,”ArXiv, vol. abs/2406.06385, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:270370870
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.