Recognition: 3 theorem links
· Lean TheoremLatent Bridge: Feature Delta Prediction for Efficient Dual-System Vision-Language-Action Model Inference
Pith reviewed 2026-05-08 17:45 UTC · model grok-4.3
The pith
A lightweight predictor of VLM output deltas lets dual-system VLA models call their vision backbone only every few steps while keeping 95-100 percent task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
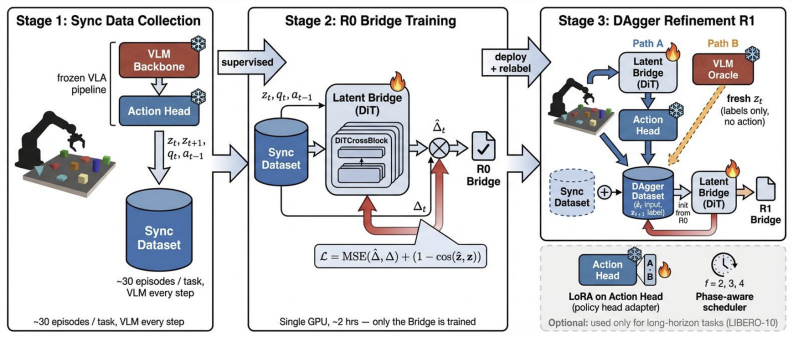
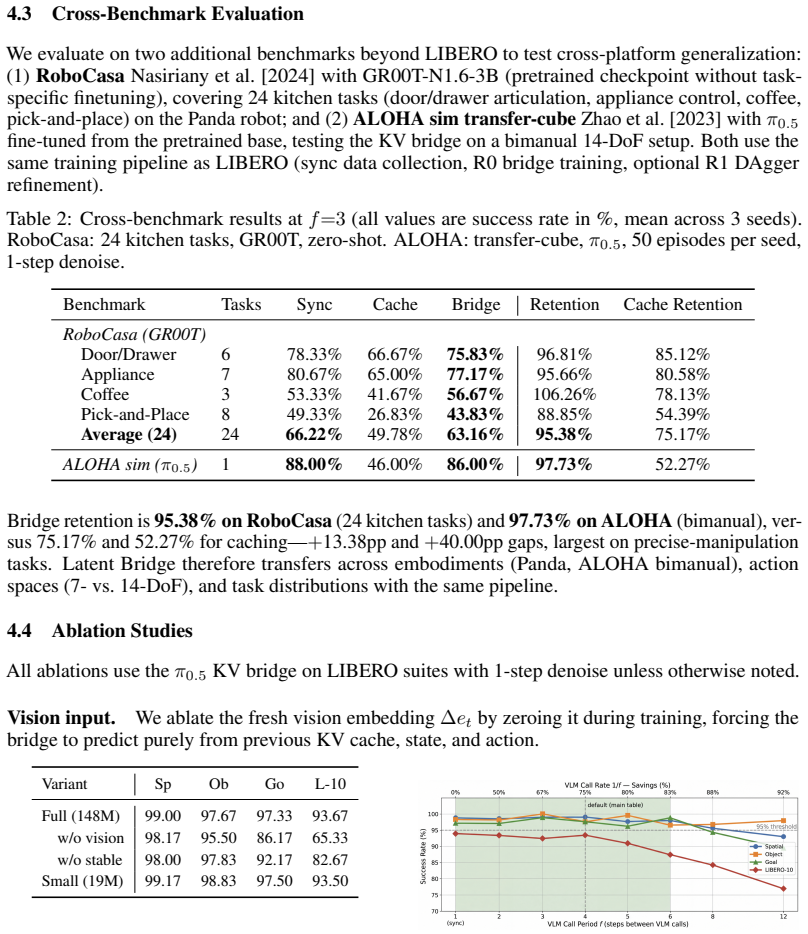
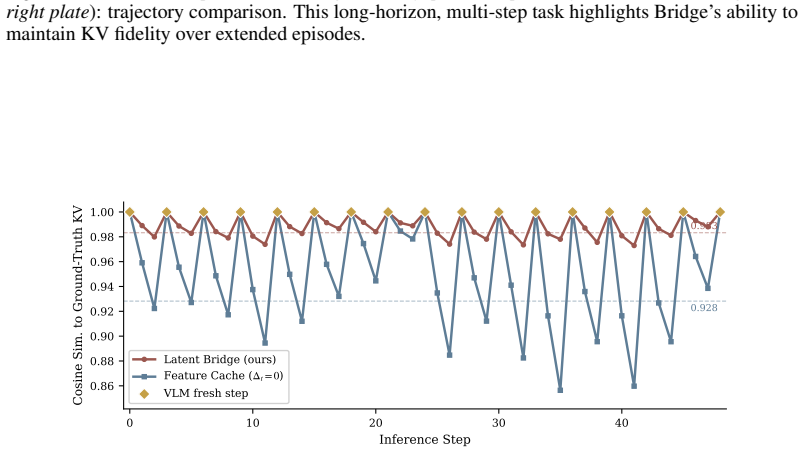
Latent Bridge is a lightweight model that predicts VLM output deltas between timesteps, allowing the action head to operate on predicted features while the VLM backbone executes only at selected intervals. Instantiated as a feature-space bridge on GR00T-N1.6 and a KV-cache bridge on π0.5, it generalizes across architectures. A task-agnostic DAgger pipeline transfers without modification, yielding 95-100 percent performance retention, 50-75 percent fewer VLM calls, and 1.65-1.73x net speedup on LIBERO suites, 24 RoboCasa tasks, and ALOHA transfer-cube.
What carries the argument
Latent Bridge, the lightweight delta-prediction model trained via DAgger to forecast VLM output changes between timesteps, implemented either in feature space or through KV-cache bridging.
If this is right
- VLM calls drop by 50-75 percent while task success stays at 95-100 percent of baseline.
- Net per-episode speedup reaches 1.65-1.73x on the evaluated suites.
- The method applies to both GR00T-N1.6 and π0.5 without architecture-specific redesign.
- Task-agnostic DAgger training transfers directly across LIBERO, RoboCasa, and ALOHA.
- Periodic VLM execution preserves action quality across four LIBERO suites and 24 RoboCasa kitchen tasks.
Where Pith is reading between the lines
- If prediction accuracy holds over longer horizons, VLM call frequency could drop further for extended manipulation sequences.
- Delta-prediction bridges could accelerate other dual-system setups that pair heavy perception with lighter control heads.
- Lower average compute per action might let advanced VLA policies run on more modest robot hardware.
- The same periodic-update pattern might reduce cost in related embodied models that recompute large features every step.
Load-bearing premise
VLM output deltas between timesteps are predictable enough by a lightweight model that errors stay small and do not accumulate to degrade performance when the backbone is skipped for several steps.
What would settle it
Run the system on held-out LIBERO or RoboCasa tasks with VLM calls reduced to every fourth step and measure whether success rates fall below 90 percent of the full-call baseline.
Figures








read the original abstract
Dual-system Vision-Language-Action (VLA) models achieve state-of-the-art robotic manipulation but are bottlenecked by the VLM backbone, which must execute at every control step while producing temporally redundant features. We propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps, enabling the action head to operate on predicted outputs while the expensive VLM backbone is called only periodically. We instantiate Latent Bridge on two architecturally distinct VLAs: GR00T-N1.6 (feature-space bridge) and {\pi}0.5 (KV-cache bridge), demonstrating that the approach generalizes across VLA designs. Our task-agnostic DAgger training pipeline transfers across benchmarks without modification. Across four LIBERO suites, 24 RoboCasa kitchen tasks, and the ALOHA sim transfer-cube task, Latent Bridge achieves 95-100% performance retention while reducing VLM calls by 50-75%, yielding 1.65-1.73x net per-episode speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a lightweight Latent Bridge model can predict deltas in VLM outputs (feature space for GR00T-N1.6 or KV-cache for π0.5) between timesteps, allowing the action head to use predicted features while calling the expensive VLM backbone only periodically. Using task-agnostic DAgger training that transfers without modification, the approach is shown to retain 95-100% performance on four LIBERO suites, 24 RoboCasa tasks, and the ALOHA transfer-cube task while cutting VLM calls by 50-75% for 1.65-1.73x net speedup, and to generalize across two architecturally distinct dual-system VLAs.
Significance. If the empirical retention numbers hold, the work addresses a practical bottleneck in deploying high-performing VLA models for robotics by reducing VLM inference cost without task-specific retraining. The cross-architecture instantiation and benchmark breadth are strengths that could influence efficiency techniques for temporally redundant vision-language models.
major comments (2)
- [§4 (Experiments and Results)] The central claim of 95-100% performance retention with 50-75% VLM call reduction rests on the delta predictor avoiding significant error accumulation over skipped steps. The manuscript reports aggregate success rates but provides no per-step prediction error metrics, growth bounds, or ablations that isolate skip interval (e.g., 2-step vs. 4-step), leaving the generalization claim vulnerable to the possibility that retention holds only for short horizons or particular task dynamics.
- [§3 (Method)] The task-agnostic DAgger pipeline is asserted to transfer across benchmarks and VLA designs without modification, yet the paper does not report the distribution of training trajectories, the relative parameter count or FLOPs of the bridge versus the VLM, or whether the reported net speedup subtracts bridge overhead at inference time. These details are load-bearing for the efficiency claims.
minor comments (2)
- [Abstract] The abstract states ranges (95-100% retention, 50-75% reduction) without per-suite or per-task tables or variance; adding a results table with mean and std over seeds would improve clarity.
- [§3 (Method)] Notation for the two bridge variants (feature-space vs. KV-cache) should be introduced with explicit symbols in the method section to avoid ambiguity when comparing the GR00T-N1.6 and π0.5 instantiations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the empirical support and reporting of efficiency details.
read point-by-point responses
-
Referee: [§4 (Experiments and Results)] The central claim of 95-100% performance retention with 50-75% VLM call reduction rests on the delta predictor avoiding significant error accumulation over skipped steps. The manuscript reports aggregate success rates but provides no per-step prediction error metrics, growth bounds, or ablations that isolate skip interval (e.g., 2-step vs. 4-step), leaving the generalization claim vulnerable to the possibility that retention holds only for short horizons or particular task dynamics.
Authors: We agree that per-step prediction error metrics, explicit bounds on error growth, and ablations isolating the skip interval would provide stronger evidence against potential error accumulation issues. Although the consistent 95-100% retention across benchmarks with varying horizons and dynamics offers supporting evidence for generalization, we will add these analyses—including per-step error plots, growth bounds, and success rates for different skip intervals (e.g., 2-step vs. 4-step)—to the revised manuscript. revision: yes
-
Referee: [§3 (Method)] The task-agnostic DAgger pipeline is asserted to transfer across benchmarks and VLA designs without modification, yet the paper does not report the distribution of training trajectories, the relative parameter count or FLOPs of the bridge versus the VLM, or whether the reported net speedup subtracts bridge overhead at inference time. These details are load-bearing for the efficiency claims.
Authors: We acknowledge that these specifics are important for fully substantiating the efficiency claims and reproducibility. We will add details on the distribution of training trajectories (including counts and characteristics per benchmark), the relative parameter counts and FLOPs of the bridge model versus the VLM backbone, and explicit confirmation that the reported net speedups (1.65-1.73x) incorporate the bridge's inference overhead in end-to-end measurements. These will be included in the revised manuscript, likely in an expanded methods section and appendix. revision: yes
Circularity Check
No circularity; empirical validation on external benchmarks
full rationale
The paper proposes Latent Bridge as a lightweight delta predictor trained via task-agnostic DAgger and reports measured performance retention (95-100%) and speedup on LIBERO, RoboCasa, and ALOHA tasks. No equations, derivations, or self-citations are presented that reduce the central claim to fitted inputs or prior author results by construction. The argument is self-contained as an engineering method whose validity is assessed through direct experimental measurement rather than tautological prediction or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Latent Bridge
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclearWe propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps... ẑ_{t+1} = ẑ_t + B(ẑ_t, s_t, q_t, a_{t-1})
Reference graph
Works this paper leans on
-
[1]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes et al. Revisiting feature prediction for learning visual representations from video. arXiv:2404.08471,
work page internal anchor Pith review arXiv
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck et al. GR00T N1: An open foundation model for generalist humanoid robots. arXiv:2503.14734,
work page internal anchor Pith review arXiv
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black et al. π0: A vision-language-action flow model for general robot control. arXiv:2410.24164,
work page internal anchor Pith review arXiv
-
[4]
SQAP-VLA: Synergistic quantization-aware pruning for VLAs
Hengyu Fang et al. SQAP-VLA: Synergistic quantization-aware pruning for VLAs. arXiv:2509.09090,
-
[5]
Juntao Gao et al. Compressor-VLA: Instruction-guided visual token compression for efficient robotic manipulation.arXiv:2511.18950,
-
[6]
Qixiu Li et al. CogACT: A foundational vision-language-action model for synergizing cognition and action.arXiv:2411.19650, 2024a. Yuhong Li et al. SnapKV: LLM knows what you are looking for before generation. InNeurIPS, 2024b. Ji Lin et al. AWQ: Activation-aware weight quantization for LLM compression and acceleration. In MLSys,
-
[7]
Ziyan Liu et al. VLA-Pruner: Temporal-aware dual-level visual token pruning for efficient VLA inference.arXiv:2511.16449,
-
[8]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, et al. π0.5: a vision-language-action model with open-world generalization.arXiv:2504.16054,
work page internal anchor Pith review arXiv
-
[9]
Hanzhen Wang et al. SpecPrune-VLA: Accelerating VLAs via action-aware self-speculative pruning. arXiv:2509.05614,
-
[10]
Lirui Wang et al. Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers. arXiv:2409.20537,
-
[11]
Siyu Xu et al. VLA-Cache: Efficient vision-language-action manipulation via adaptive token caching. arXiv:2502.02175,
-
[12]
DyQ-VLA: Temporal-dynamic-aware quantization for embodied VLAs
Zihao Zheng et al. DyQ-VLA: Temporal-dynamic-aware quantization for embodied VLAs. arXiv:2603.07904,
-
[13]
max-autotune
11 A Implementation Details Bridge architecture hyperparameters.Both VLA variants use the same DiT backbone with AdaLN conditioning. Table 5 lists the key hyperparameters. Table 5: Bridge model hyperparameters. The small variant achieves comparable SR; we use the full variant in all main experiments. GR00T feature bridge π0.5 KV bridge Full Small Full Sma...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.