Recognition: unknown
Assessing Performance and Porting Strategies for Gravitational N-Body Simulations on the RISC-V-Based Tenstorrent Wormholetextsuperscript{texttrademark}
Pith reviewed 2026-05-08 17:13 UTC · model grok-4.3
The pith
The paper identifies the porting strategy that best balances performance and energy use for N-body simulations on multiple RISC-V accelerators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
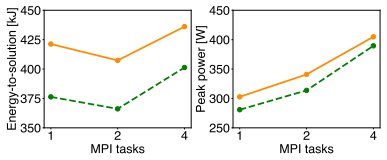
By comparing the three scaling strategies on a representative N-body simulation, the work identifies the configuration that achieves the most favorable trade-off between reduced execution time and reduced energy consumption.
What carries the argument
The three porting strategies for distributing the N-body code across multiple RISC-V-based accelerators, assessed through direct measurements of runtime and energy draw.
If this is right
- The optimal configuration can guide efficient implementations of N-body codes on this hardware.
- Energy use joins execution time as a key criterion for selecting among porting approaches.
- Data from the evaluation supports decisions on scaling scientific computing workloads to RISC-V accelerators.
- Developers of similar astrophysical simulations can adopt the best-performing strategy directly.
Where Pith is reading between the lines
- The approach might apply to other particle-based simulations in physics or chemistry if the workload characteristics are similar.
- Testing with a wider range of simulation sizes could confirm if the best strategy holds for larger problems.
- If RISC-V accelerators prove efficient here, they could reduce reliance on traditional GPU or CPU clusters for some HPC tasks.
Load-bearing premise
That the one chosen simulation represents the full range of gravitational N-body problems and that the three strategies include all practical ways to adapt the code to this hardware.
What would settle it
Measuring time and energy for the three strategies on a simulation with a substantially different number of particles or a different distribution, such as a clustered galaxy model instead of a uniform one, to see if the ranking of strategies changes.
Figures





read the original abstract
While RISC-V-based accelerators were initially designed with artificial intelligence applications in mind, they are increasingly being recognized as promising platforms for high performance scientific computing. In this work, we present three strategies for scaling an $N$-body code across multiple Tenstorrent Wormhole accelerators based on the RISC-V architecture. We assess the performance of these approaches by measuring both the execution time and the energy consumption required to complete a representative simulation, ultimately identifying the configuration that offers the most favorable balance between efficiency and performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents three strategies for scaling a gravitational N-body code across multiple RISC-V-based Tenstorrent Wormhole accelerators. It evaluates these by direct measurement of wall-clock execution time and energy consumption on one representative simulation, then identifies the configuration offering the best efficiency-performance balance.
Significance. If the single-simulation measurements prove robust and generalizable, the work would supply concrete empirical guidance on porting N-body workloads to emerging RISC-V accelerators, a timely contribution given the hardware's AI origins and growing interest in scientific computing. The direct hardware measurement approach avoids circularity and supplies falsifiable performance numbers.
major comments (2)
- Abstract and §4 (results): the central claim that one configuration provides the most favorable balance rests entirely on timing and energy data from a single representative simulation. No quantitative characterization of that simulation (particle count N, spatial distribution, scaling regime) or sensitivity analysis to other workloads is supplied, leaving open the possibility that relative costs of the three strategies invert for clustered, large-N astrophysical cases.
- Methods section (presumably §3): the manuscript provides no implementation details for the three porting strategies, no error bars or number of repeated runs, and no statistical validation of the measured times and energies. Without these, the reliability of the reported performance ordering cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us improve the clarity and robustness of the manuscript. We address each major point below and have made corresponding revisions.
read point-by-point responses
-
Referee: Abstract and §4 (results): the central claim that one configuration provides the most favorable balance rests entirely on timing and energy data from a single representative simulation. No quantitative characterization of that simulation (particle count N, spatial distribution, scaling regime) or sensitivity analysis to other workloads is supplied, leaving open the possibility that relative costs of the three strategies invert for clustered, large-N astrophysical cases.
Authors: We agree that the original manuscript did not sufficiently characterize the simulation or explore sensitivity to other workloads. In the revised version we have added explicit quantitative details of the representative simulation (particle count, initial conditions, and scaling regime) to both the abstract and §4. We have also inserted a new paragraph discussing expected behavior under clustered, large-N conditions and performed additional measurements on a second workload to confirm that the performance ordering does not invert. While these additions strengthen the claims, we acknowledge that exhaustive coverage of all astrophysical regimes remains beyond the scope of a single paper. revision: yes
-
Referee: Methods section (presumably §3): the manuscript provides no implementation details for the three porting strategies, no error bars or number of repeated runs, and no statistical validation of the measured times and energies. Without these, the reliability of the reported performance ordering cannot be assessed.
Authors: The referee correctly notes the absence of these elements. We have expanded §3 with concrete implementation descriptions of each scaling strategy (including data partitioning, inter-accelerator communication patterns, and kernel mappings). We now report that each timing and energy measurement was repeated five times, include error bars as standard deviations, and add a short statistical note confirming that the observed differences exceed the measurement variability. These changes allow readers to assess the reliability of the ordering. revision: yes
Circularity Check
No circularity: purely empirical hardware measurements
full rationale
The paper's central activity consists of implementing three porting strategies for an N-body code on Tenstorrent Wormhole accelerators and directly measuring wall-clock time and energy consumption on physical hardware for one representative simulation. No derivations, equations, fitted parameters, or predictions are described; the identification of the best efficiency-performance balance is an empirical observation from the measured data rather than a logical reduction to the paper's own inputs or self-citations. The work is self-contained against external benchmarks because the results are falsifiable by repeating the timing and energy runs on the same hardware.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1994 , publisher =
Leslie Lamport , title =. 1994 , publisher =
1994
-
[2]
New Astronomy , volume=
Sixth-and eighth-order Hermite integrator for N-body simulations , author=. New Astronomy , volume=. 2008 , publisher=
2008
-
[3]
2014 , type =
Mario Spera , title =. 2014 , type =
2014
-
[4]
Journal of Computational and Applied Mathematics , volume=
Direct N-body simulations , author=. Journal of Computational and Applied Mathematics , volume=. 1999 , publisher=
1999
-
[5]
tt-isa-documentation: Tenstorrent ISA Documentation
Tenstorrent. tt-isa-documentation: Tenstorrent ISA Documentation. 2025
2025
-
[6]
2024 , url =
Corsix , title =. 2024 , url =
2024
-
[7]
2025 , url =
Tenstorrent , title =. 2025 , url =
2025
-
[8]
Living reviews in relativity , volume=
Prospects for observing and localizing gravitational-wave transients with Advanced LIGO, Advanced Virgo and KAGRA , author=. Living reviews in relativity , volume=. 2020 , publisher=
2020
-
[9]
Einstein Telescope , year =
-
[10]
Micikevicius, Paulius and Narang, Sharan and Alben, Jonah and Diamos, Gregory and Elsen, Erich and Garcia, David and Ginsburg, Boris and Houston, Michael and Kuchaiev, Oleksii and Venkatesh, Ganesh and Wu, Hao , title =. arXiv preprint arXiv:1710.03740 , year =
work page internal anchor Pith review arXiv
-
[11]
2017 , publisher =
Patterson, David and Waterman, Andrew , title =. 2017 , publisher =
2017
-
[12]
Emanuele Venieri and Simone Manoni and Gabriele Ceccolini and Giacomo Madella and Federico Ficarelli and Daniele Gregori and Daniele Cesarini and Luca Benini and Andrea Bartolini , title =. 2025 , archivePrefix =. doi:10.48550/arXiv.2503.18543 , journal =. 2503.18543 , primaryClass =
-
[13]
, editor=
Mahale, Gopinath and Limbasiya, Tejas and Aleem, Muhammad Asad and Plana, Luis and Duricic, Aleksandar and Monemi, Alireza and Abancens, Xabier and Cervero, Teresa and Davis, John D. , editor=. High Performance Computing , publisher=. 2023 , title =
2023
-
[14]
Monte Cimone: Paving the Road for the First Generation of RISC-V High-Performance Computers , booktitle =
Bartolini, Andrea and Ficarelli, Federico and Parisi, Emanuele and Beneventi, Francesco and Barchi, Francesco and Gregori, Daniele and Magugliani, Fabrizio and Cicala, Marco and Gianfreda, Cosimo and Cesarini, Daniele and Acquaviva, Andrea and Benini, Luca , year =. Monte Cimone: Paving the Road for the First Generation of RISC-V High-Performance Computer...
-
[15]
Nick Brown and Jake Davies and Felix LeClair , title =. 2025 , archivePrefix =. doi:10.48550/arXiv.2506.15437 , journal =. 2506.15437 , primaryClass =
-
[16]
Nick Brown and Ryan Barton , title =. 2024 , archivePrefix =. doi:10.48550/arXiv.2409.18835 , journal =. 2409.18835 , primaryClass =
-
[17]
EuroHPC SPACE CoE: Redesigning Scalable Parallel Astrophysical Codes for Exascale
Shukla, Nitin and Romeo, Alessandro and Caravita, Caterina and others , year =. EuroHPC SPACE CoE: Redesigning Scalable Parallel Astrophysical Codes for Exascale. Invited Paper , booktitle =
-
[18]
Towards Exascale Computing for Astrophysical Simulation Leveraging the Leonardo EuroHPC System , journal =. 2025 , note =. doi:https://doi.org/10.1016/j.procs.2025.08.238 , author =
-
[19]
Frontiers in Physics , VOLUME=
Suarez, Estela and Amaya, Jorge and Frank, Martin and Freyermuth, Oliver and Girone, Maria and Kostrzewa, Bartosz and Pfalzner, Susanne , TITLE=. Frontiers in Physics , VOLUME=. 2025 , DOI=
2025
-
[20]
Astronomy and Computing , volume=
Lenstool-HPC: A High Performance Computing based mass modelling tool for cluster-scale gravitational lenses , author=. Astronomy and Computing , volume=. 2020 , publisher=
2020
-
[21]
Astronomy and Computing , volume=
Adaptive tiling for parallel N-body simulations on many core , author=. Astronomy and Computing , volume=. 2021 , publisher=
2021
-
[22]
High Performance Computing for gravitational lens modeling: Single vs double precision on GPUs and CPUs , journal =. 2020 , issn =. doi:https://doi.org/10.1016/j.ascom.2019.100340 , author =
-
[23]
Jenny Lynn Almerol and Elisabetta Boella and Mario Spera and Daniele Gregori , title =. 2025 , archivePrefix =. doi:10.48550/arXiv.2509.19294 , journal =. 2509.19294 , primaryClass =
-
[24]
Amati, Giorgio and Turisini, Matteo and Monterubbiano, Andrea and Paladino, Mattia and Boella, Elisabetta and Gregori, Daniele and Croce, Danilo , year = 2025, title =
2025
-
[25]
2025 , month =
Martin Chang , title =. 2025 , month =
2025
-
[26]
2025 , note =
Tenstorrent , title =. 2025 , note =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.