Recognition: 2 theorem links
· Lean TheoremUnified Map Prior Encoder for Mapping and Planning
Pith reviewed 2026-05-08 18:11 UTC · model grok-4.3
The pith
A unified encoder aligns and fuses any mix of vector and raster map priors into BEV features to raise mapping accuracy and lower planning errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
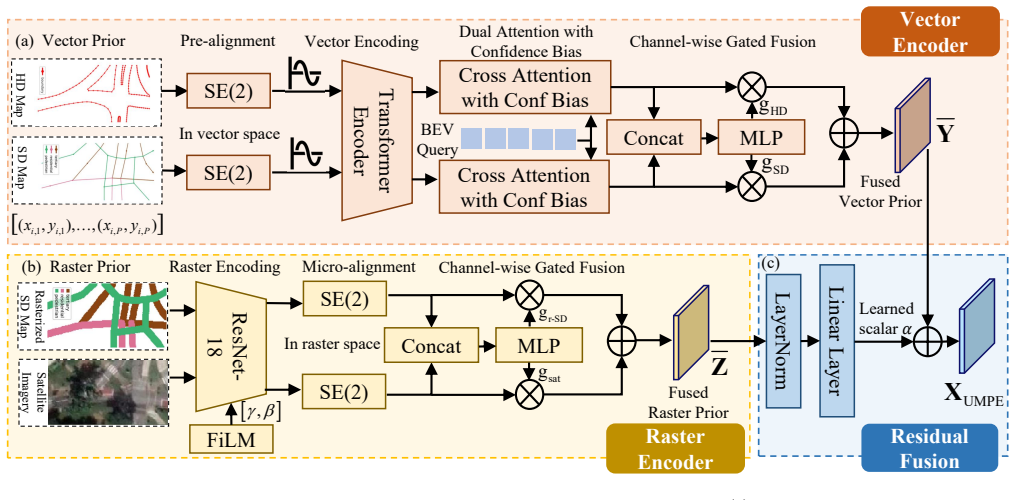
The paper claims that a vector encoder that pre-aligns polylines, encodes points with multi-frequency sinusoids, and emits tokens with per-polyline scores, followed by a raster encoder that applies FiLM-conditioned ResNet stages and SE(2) micro-alignment, then fuses the two streams in vector-first order via cross-attention with bias and normalized channel gating, produces BEV features that improve both mapping and planning over sensor-only baselines.
What carries the argument
The Unified Map Prior Encoder with a vector branch (SE(2) pre-alignment, sinusoidal point encoding, confidence scores) and a raster branch (FiLM-conditioned ResNet-18, zero-initialized residual fusion), merged by cross-attention and gating.
If this is right
- Mapping models reach higher mAP when any combination of priors is supplied at test time.
- End-to-end planners produce trajectories with lower average L2 error and lower collision rates.
- A model trained on the full set of priors still outperforms single-prior baselines when only one prior arrives at inference.
- The same fusion pattern works across different backbone mapping and planning networks.
Where Pith is reading between the lines
- Similar alignment-plus-gating blocks could be added to other multi-sensor fusion pipelines that suffer from inconsistent data availability.
- The method suggests that explicit geometric correction before semantic fusion is more important than simply increasing model capacity.
- Testing the same architecture on datasets with seasonal map changes would reveal whether the confidence scores adapt to outdated priors.
- Extending the raster branch to accept live aerial imagery could further reduce reliance on pre-built HD maps.
Load-bearing premise
The supplied map priors can be brought into the current vehicle frame by simple rigid transformations and their usefulness can be summarized by scalar scores that do not mislead the later fusion steps.
What would settle it
A test set containing large unmodeled pose drift where adding the priors through the encoder lowers mapping mAP or raises collision rate compared with the no-prior baseline would show the alignment and gating steps are not sufficient.
Figures



read the original abstract
Online mapping and end-to-end (E2E) planning in autonomous driving remain largely sensor-centric, leaving rich map priors, including HD/SD vector maps, rasterized SD maps, and satellite imagery, underused because of heterogeneity, pose drift, and inconsistent availability at test time. We present UMPE, a Unified Map Prior Encoder that can ingest any subset of four priors and fuse them with BEV features for both mapping and planning. UMPE has two branches. The vector encoder pre-aligns HD/SD polylines with a frame-wise SE(2) correction, encodes points via multi-frequency sinusoidal features, and produces polyline tokens with confidence scores. BEV queries then apply cross-attention with confidence bias, followed by normalized channel-wise gating to avoid length imbalance and softly down-weight uncertain sources. The raster encoder shares a ResNet-18 backbone conditioned by FiLM with scaling and shift at every stage, performs SE(2) micro-alignment, and injects priors through zero-initialized residual fusion, so the network starts from a do-no-harm baseline and learns to add only useful prior evidence. A vector-then-raster fusion order reflects the inductive bias of geometry first, appearance second. On nuScenes mapping, UMPE lifts MapTRv2 from 61.5 to 67.4 mAP (+5.9) and MapQR from 66.4 to 71.7 mAP (+5.3). On Argoverse2, UMPE adds +4.1 mAP over strong baselines. UMPE is compositional: when trained with all priors, it outperforms single-prior models even when only one prior is available at test time, demonstrating powerset robustness. For E2E planning with the VAD backbone on nuScenes, UMPE reduces trajectory error from 0.72 to 0.42 m L2 on average (-0.30 m) and collision rate from 0.22% to 0.12% (-0.10%), surpassing recent prior-injection methods. These results show that a unified, alignment-aware treatment of heterogeneous map priors yields better mapping and better planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents UMPE, a Unified Map Prior Encoder that ingests heterogeneous map priors (HD/SD vector maps, rasterized maps, satellite imagery) and fuses them with BEV features for online mapping and end-to-end planning. The vector encoder applies frame-wise SE(2) micro-alignment to polylines, uses multi-frequency sinusoidal point encoding, and produces tokens with confidence scores that bias cross-attention and enable normalized gating. The raster encoder employs a FiLM-conditioned ResNet-18 with SE(2) alignment and zero-initialized residual fusion. Vector-then-raster fusion order is used. On nuScenes, UMPE improves MapTRv2 mAP from 61.5 to 67.4 and MapQR from 66.4 to 71.7; with VAD planner it reduces average L2 trajectory error from 0.72 m to 0.42 m and collision rate from 0.22% to 0.12%. Comparable gains (+4.1 mAP) are reported on Argoverse2, with compositional robustness when subsets of priors are available at test time.
Significance. If the empirical gains prove robust, the work is significant for providing a practical, alignment-aware mechanism to exploit underused map priors in autonomous driving despite pose drift and inconsistent availability. The do-no-harm residual design, powerset robustness, and joint mapping-planning improvements represent useful engineering contributions that could be adopted in BEV pipelines.
major comments (2)
- [Vector encoder description (abstract and method)] The reported gains (e.g., +5.9 mAP on MapTRv2, -0.30 m L2 with VAD) rest on the vector encoder's SE(2) micro-alignment and per-polyline confidence scores being sufficiently accurate to modulate cross-attention and gating without amplifying pose errors. No independent diagnostics (alignment error histograms, calibration plots, or drift-robustness tests) are provided to verify this load-bearing assumption under realistic conditions.
- [Experiments and results] Ablation studies isolating the SE(2) correction, confidence gating, raster residual fusion, and vector-first order are absent, as is error analysis on cases where priors are noisy or misaligned. This makes it difficult to attribute the central performance deltas specifically to the proposed components rather than other implementation details.
minor comments (2)
- [Fusion module] The normalized channel-wise gating operation would benefit from an explicit equation to clarify how length imbalance is avoided and uncertain sources are down-weighted.
- [Figures and tables] Figure captions and axis labels in the mapping and planning result tables could be expanded for standalone readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of UMPE's practical contributions. We address each major comment below and will revise the manuscript accordingly to provide the requested diagnostics and ablations.
read point-by-point responses
-
Referee: [Vector encoder description (abstract and method)] The reported gains (e.g., +5.9 mAP on MapTRv2, -0.30 m L2 with VAD) rest on the vector encoder's SE(2) micro-alignment and per-polyline confidence scores being sufficiently accurate to modulate cross-attention and gating without amplifying pose errors. No independent diagnostics (alignment error histograms, calibration plots, or drift-robustness tests) are provided to verify this load-bearing assumption under realistic conditions.
Authors: We acknowledge that the manuscript does not include independent diagnostics such as alignment error histograms, confidence calibration plots, or explicit drift-robustness tests for the SE(2) micro-alignment and per-polyline confidence scores. The reported gains and the powerset robustness results (outperforming single-prior models even with partial priors at test time) provide indirect evidence that the mechanisms do not amplify pose errors under the evaluated conditions. To directly address the concern, we will add these diagnostics in the revision, including histograms of SE(2) correction magnitudes on nuScenes and Argoverse2, calibration curves for confidence scores, and tests with simulated pose drift. revision: yes
-
Referee: [Experiments and results] Ablation studies isolating the SE(2) correction, confidence gating, raster residual fusion, and vector-first order are absent, as is error analysis on cases where priors are noisy or misaligned. This makes it difficult to attribute the central performance deltas specifically to the proposed components rather than other implementation details.
Authors: We agree that the current experiments do not isolate the individual contributions of SE(2) correction, confidence gating, raster residual fusion, and vector-first fusion order, nor do they include dedicated error analysis on noisy or misaligned priors. While the manuscript reports overall gains, subset robustness, and comparisons to prior-injection baselines, these do not fully disentangle the components. We will add targeted ablations for each element and case studies analyzing performance on subsets with injected noise or misalignment in the revised experiments section. revision: yes
Circularity Check
No circularity: empirical architecture with independent experimental validation
full rationale
The paper presents UMPE as an engineering architecture (vector encoder with SE(2) pre-alignment and confidence-gated cross-attention; raster encoder with FiLM-conditioned ResNet and zero-init residual fusion; vector-then-raster order) whose performance claims rest entirely on held-out nuScenes/Argoverse2 metrics. No equation or result is shown to reduce by construction to a fitted parameter, self-citation, or renamed input; the design choices are presented as inductive biases rather than derived predictions. The central results (mAP deltas, L2/collision reductions) are falsifiable experimental outcomes, not tautological re-statements of the method.
Axiom & Free-Parameter Ledger
free parameters (2)
- SE(2) correction parameters
- FiLM scaling and shift parameters
axioms (2)
- domain assumption BEV features can be meaningfully augmented by cross-attention to aligned map tokens
- domain assumption Zero-initialized residual fusion starts from a do-no-harm baseline
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixation force J(x)=½(x+x⁻¹)−1; the paper's benchmark gains have no structural connection to this cost.J_uniquely_calibrated_via_higher_derivative unclearOn nuScenes, UMPE lifts MapTRv2 from 61.5 to 67.4 mAP (+5.9) and MapQR from 66.4 to 71.7 mAP (+5.3).
Reference graph
Works this paper leans on
-
[1]
Augmenting lane perception and topol- ogy understanding with standard definition navigation maps,
K. Z. Luo, X. Weng, Y . Wang, S. Wu, J. Li, K. Q. Weinberger, Y . Wang, and M. Pavone, “Augmenting lane perception and topol- ogy understanding with standard definition navigation maps,”ICRA, pp. 4029–4035, 2023
2023
-
[2]
Enhancing online road network perception and reasoning with standard definition maps,
H. Zhang, D. Paz, Y . Guo, A. Das, X. Huang, K. Haug, H. I. Christensen, and L. Ren, “Enhancing online road network perception and reasoning with standard definition maps,” inIROS, 2024
2024
-
[3]
Sdtagnet: Leveraging text-annotated navigation maps for online hd map construction,
F. Immel, J.-H. Pauls, R. Fehler, F. Bieder, J. Merkert, and C. Stiller, “Sdtagnet: Leveraging text-annotated navigation maps for online hd map construction,”arXiv preprint arXiv:2506.08997, 2025
-
[4]
Comple- menting onboard sensors with satellite maps: a new perspective for hd map construction,
W. Gao, J. Fu, Y . Shen, H. Jing, S. Chen, and N. Zheng, “Comple- menting onboard sensors with satellite maps: a new perspective for hd map construction,” inICRA, pp. 11103–11109, IEEE, 2024
2024
-
[5]
Smart: Advancing scalable map priors for driving topology reasoning,
J. Ye, D. Paz, H. Zhang, Y . Guo, X. Huang, H. I. Christensen, Y . Wang, and L. Ren, “Smart: Advancing scalable map priors for driving topology reasoning,”arXiv preprint arXiv:2502.04329, 2025
-
[6]
Sept: Standard-definition map enhanced scene perception and topology reasoning for autonomous driving,
M. Pei, J. Shan, P. Li, J. Shi, J. Huo, Y . Gao, and S. Shen, “Sept: Standard-definition map enhanced scene perception and topology reasoning for autonomous driving,”RAL, 2025
2025
-
[7]
Leveraging sd map to augment hd map-based trajectory prediction,
Z. Dong, R. Ding, W. Li, P. Zhang, G. Tang, and J. Guo, “Leveraging sd map to augment hd map-based trajectory prediction,” inCVPR, pp. 17219–17228, 2025
2025
-
[8]
arXiv preprint arXiv:2409.05352 , year=
S. Zeng, X. Chang, X. Liu, Z. Pan, and X. Wei, “Driving with prior maps: Unified vector prior encoding for autonomous vehicle mapping,” arXiv preprint arXiv:2409.05352, 2024
-
[9]
Maptrv2: An end-to-end framework for online vectorized hd map construction,
B. Liao, S. Chen, Y . Zhang, B. Jiang, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Maptrv2: An end-to-end framework for online vectorized hd map construction,”IJCV, vol. 133, no. 3, pp. 1352–1374, 2025
2025
-
[10]
Leveraging enhanced queries of point sets for vectorized map construction,
Z. Liu, X. Zhang, G. Liu, J. Zhao, and N. Xu, “Leveraging enhanced queries of point sets for vectorized map construction,” inEuropean Conference on Computer Vision, pp. 461–477, Springer, 2024
2024
-
[11]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inCVPR, 2020
2020
-
[12]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Pontes,et al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,”arXiv preprint arXiv:2301.00493, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inCVPR, pp. 8340–8350, 2023
2023
-
[14]
Hdmapnet: An online hd map construction and evaluation framework,
Q. Li, Y . Wang, Y . Wang, and H. Zhao, “Hdmapnet: An online hd map construction and evaluation framework,” in2022 International Conference on Robotics and Automation (ICRA), IEEE, 2022
2022
-
[15]
Vectormapnet: End-to-end vectorized hd map learning,
Y . Liu, T. Yuan, Y . Wang, Y . Wang, and H. Zhao, “Vectormapnet: End-to-end vectorized hd map learning,” inInternational Conference on Machine Learning, pp. 22352–22369, PMLR, 2023
2023
-
[16]
Maptr: Structured modeling and learning for online vectorized hd map construction,
B. Liao, S. Chen, X. Wang, T. Cheng, Q. Zhang, W. Liu, and C. Huang, “Maptr: Structured modeling and learning for online vectorized hd map construction,”arXiv preprint arXiv:2208.14437, 2022
-
[17]
Streammapnet: Streaming mapping network for vectorized online hd map construc- tion,
T. Yuan, Y . Liu, Y . Wang, Y . Wang, and H. Zhao, “Streammapnet: Streaming mapping network for vectorized online hd map construc- tion,” inCVPR, pp. 7356–7365, 2024
2024
-
[18]
Maptracker: Track- ing with strided memory fusion for consistent vector hd mapping,
J. Chen, Y . Wu, J. Tan, H. Ma, and Y . Furukawa, “Maptracker: Track- ing with strided memory fusion for consistent vector hd mapping,” in ECCV, pp. 90–107, Springer, 2024
2024
-
[19]
Himap: Hybrid representation learning for end-to-end vectorized hd map construction,
Y . Zhou, H. Zhang, J. Yu, Y . Yang, S. Jung, S.-I. Park, and B. Yoo, “Himap: Hybrid representation learning for end-to-end vectorized hd map construction,” inCVPR, pp. 15396–15406, 2024
2024
-
[20]
Chameleon: Fast-slow neuro-symbolic lane topology extraction,
Z. Zhang, X. Li, S. Zou, G. Chi, S. Li, X. Qiu, G. Wang, G. Zheng, L. Wang, H. Zhao,et al., “Chameleon: Fast-slow neuro-symbolic lane topology extraction,” in2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 3752–3758, IEEE, 2025
2025
-
[21]
Reusing attention for one-stage lane topology understanding,
Y . Li, Z. Zhang, X. Qiu, X. Li, Z. Liu, L. Wang, R. Li, Z. Zhu, H.-a. Gao, X. Lin,et al., “Reusing attention for one-stage lane topology understanding,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2025
2025
-
[22]
Openlane-v2: A topology reasoning bench- mark for unified 3d hd mapping,
H. Wang, T. Li, Y . Li, L. Chen, C. Sima, Z. Liu, B. Wang, P. Jia, Y . Wang, S. Jiang,et al., “Openlane-v2: A topology reasoning bench- mark for unified 3d hd mapping,”NeurIPS, pp. 18873–18884, 2023
2023
-
[23]
Graph-based Topology Reasoning for Driving Scenes,
T. Li, L. Chen, H. Wang, Y . Li, J. Yang, X. Geng, S. Jiang, Y . Wang, H. Xu, C. Xu,et al., “Graph-based topology reasoning for driving scenes,”arXiv preprint arXiv:2304.05277, 2023
-
[24]
TopoMLP: A Simple yet Strong Pipeline for Driving Topology Reasoning,
D. Wu, J. Chang, F. Jia, Y . Liu, T. Wang, and J. Shen, “Topomlp: A simple yet strong pipeline for driving topology reasoning,”arXiv preprint arXiv:2310.06753, 2023
-
[25]
LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving,
T. Li, P. Jia, B. Wang, L. Chen, K. Jiang, J. Yan, and H. Li, “Lane- segnet: Map learning with lane segment perception for autonomous driving,”arXiv preprint arXiv:2312.16108, 2023
-
[26]
Mtr++: Multi-agent mo- tion prediction with symmetric scene modeling and guided intention querying,
S. Shi, L. Jiang, D. Dai, and B. Schiele, “Mtr++: Multi-agent mo- tion prediction with symmetric scene modeling and guided intention querying,”TPAMI, vol. 46, no. 5, pp. 3955–3971, 2024
2024
-
[27]
Densetnt: End-to-end trajectory predic- tion from dense goal sets,
J. Gu, C. Sun, and H. Zhao, “Densetnt: End-to-end trajectory predic- tion from dense goal sets,” inCVPR, pp. 15303–15312, 2021
2021
-
[28]
Hivt: Hierarchical vector transformer for multi-agent motion prediction,
Z. Zhou, L. Ye, J. Wang, K. Wu, and K. Lu, “Hivt: Hierarchical vector transformer for multi-agent motion prediction,” inCVPR, 2022
2022
-
[29]
Query-centric trajectory prediction,
Z. Zhou, J. Wang, Y .-H. Li, and Y .-K. Huang, “Query-centric trajectory prediction,” inCVPR, pp. 17863–17873, 2023
2023
-
[30]
Accelerating online mapping and behavior prediction via direct bev feature attention,
X. Gu, G. Song, I. Gilitschenski, M. Pavone, and B. Ivanovic, “Accelerating online mapping and behavior prediction via direct bev feature attention,” inECCV, pp. 412–428, Springer, 2024
2024
-
[31]
Pro- ducing and leveraging online map uncertainty in trajectory prediction,
X. Gu, G. Song, I. Gilitschenski, M. Pavone, and B. Ivanovic, “Pro- ducing and leveraging online map uncertainty in trajectory prediction,” inCVPR, pp. 14521–14530, 2024
2024
-
[32]
Presight: Enhancing autonomous vehicle perception with city-scale nerf priors,
T. Yuan, Y . Mao, J. Yang, Y . Liu, Y . Wang, and H. Zhao, “Presight: Enhancing autonomous vehicle perception with city-scale nerf priors,” inECCV, pp. 323–339, Springer, 2024
2024
-
[33]
Neural map prior for autonomous driving,
X. Xiong, Y . Liu, T. Yuan, Y . Wang, Y . Wang, and H. Zhao, “Neural map prior for autonomous driving,” inCVPR, pp. 17535–17544, 2023
2023
-
[34]
P-mapnet: Far-seeing map generator enhanced by both sdmap and hdmap priors,
Z. Jiang, Z. Zhu, P. Li, H.-a. Gao, T. Yuan, Y . Shi, H. Zhao, and H. Zhao, “P-mapnet: Far-seeing map generator enhanced by both sdmap and hdmap priors,”RAL, 2024
2024
-
[35]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang,et al., “Planning-oriented autonomous driving,” in CVPR, pp. 17853–17862, 2023
2023
-
[36]
Is ego status all you need for open-loop end-to-end autonomous driving?,
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez, “Is ego status all you need for open-loop end-to-end autonomous driving?,” inCVPR, pp. 14864–14873, 2024
2024
-
[37]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu,et al., “Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation,”arXiv:2406.06978, 2024
work page internal anchor Pith review arXiv 2024
-
[38]
Delving into mapping uncertainty for mapless trajectory prediction,
Z. Zhang, X. Qiu, B. Zhang, G. Zheng, X. Gu, G. Chi, H.-a. Gao, L. Wang, Z. Liu, X. Li,et al., “Delving into mapping uncertainty for mapless trajectory prediction,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2025
2025
-
[39]
Uniuncer: Unified dynamic static uncertainty for end to end driving,
Y . Gao, J. Wang, Z. Zhang, A. Jiang, Y . Wang, Y . Heng, S. Wang, H. Sun, Z. Hu, and H. Zhao, “Uniuncer: Unified dynamic static uncertainty for end to end driving,”arXiv preprint arXiv:2603.07686, 2026
work page internal anchor Pith review arXiv 2026
-
[40]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang,et al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,” inCVPR, 2025
2025
-
[41]
Goalflow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving,
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin, “Goalflow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving,” inCVPR, pp. 1602–1611, 2025
2025
-
[42]
Genad: Generative end-to-end autonomous driving,
W. Zheng, R. Song, X. Guo, C. Zhang, and L. Chen, “Genad: Generative end-to-end autonomous driving,” inECCV, Springer, 2024
2024
-
[43]
W. Sun, X. Lin, Y . Shi, C. Zhang, H. Wu, and S. Zheng, “Sparsedrive: End-to-end autonomous driving via sparse scene representation,”arXiv preprint arXiv:2405.19620, 2024
-
[44]
Epona: Autoregressive diffusion world model for autonomous driving
K. Zhang, Z. Tang, X. Hu, X. Pan, X. Guo, Y . Liu, J. Huang, L. Yuan, Q. Zhang, X.-X. Long,et al., “Epona: Autoregressive diffusion world model for autonomous driving,”arXiv:2506.24113, 2025
-
[45]
Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving,
Z. Song, C. Jia, L. Liu, H. Pan, Y . Zhang, J. Wang, X. Zhang, S. Xu, L. Yang, and Y . Luo, “Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving,” inCVPR, 2025
2025
-
[46]
Bridging past and future: End-to-end autonomous driving with historical prediction and planning,
B. Zhang, N. Song, X. Jin, and L. Zhang, “Bridging past and future: End-to-end autonomous driving with historical prediction and planning,” inCVPR, pp. 6854–6863, 2025
2025
-
[47]
H. Fu, D. Zhang, Z. Zhao, J. Cui, D. Liang, C. Zhang, D. Zhang, H. Xie, B. Wang, and X. Bai, “Orion: A holistic end-to-end au- tonomous driving framework by vision-language instructed action generation,”arXiv preprint arXiv:2503.19755, 2025
-
[48]
Gaussianfusion: Gaussian-based multi-sensor fusion for end-to-end autonomous driv- ing,
S. Liu, Q. Liang, Z. Li, B. Li, and K. Huang, “Gaussianfusion: Gaussian-based multi-sensor fusion for end-to-end autonomous driv- ing,”arXiv preprint arXiv:2506.00034, 2025
-
[49]
Openstreetmap: User-generated street maps,
M. Haklay and P. Weber, “Openstreetmap: User-generated street maps,”IEEE Pervasive computing, vol. 7, no. 4, pp. 12–18, 2008
2008
-
[50]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inCVPR, pp. 770–778, 2016
2016
-
[51]
Mind the map! accounting for existing map information when estimating online hdmaps from sensor,
R. Sun, L. Yang, D. Lingrand, and F. Precioso, “Mind the map! accounting for existing map information when estimating online hdmaps from sensor,”arXiv preprint arXiv:2311.10517, 2023
-
[52]
Mgmap: Mask-guided learning for online vectorized hd map construction,
X. Liu, S. Wang, W. Li, R. Yang, J. Chen, and J. Zhu, “Mgmap: Mask-guided learning for online vectorized hd map construction,” in CVPR, pp. 14812–14821, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.