Recognition: 3 theorem links
· Lean TheoremLinearizing Vision Transformer with Test-Time Training
Pith reviewed 2026-05-08 18:22 UTC · model grok-4.3
The pith
Test-Time Training aligns linear attention with pretrained Softmax weights, enabling transfer after minimal fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The two-layer dynamic formulation of Test-Time Training is structurally aligned with Softmax attention, permitting direct inheritance of pretrained attention weights. Key instance normalization and a lightweight locality enhancement module further align representational properties such as key shift-invariance and locality. This alignment converts Stable Diffusion 3.5 into SD3.5-T^5, which after one hour of fine-tuning on 4x H20 GPUs matches the text-to-image quality of the fine-tuned Softmax model while accelerating inference by 1.32x at 1K resolution and 1.47x at 2K resolution.
What carries the argument
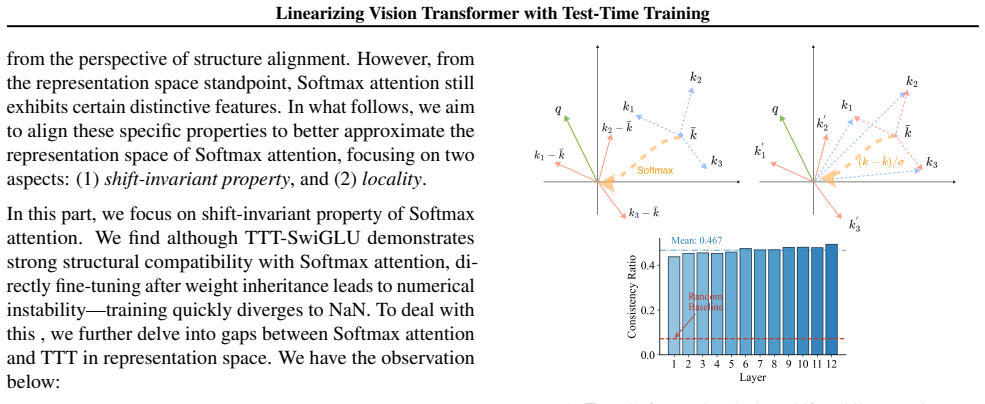
Test-Time Training's two-layer dynamic formulation, augmented by key instance normalization and a lightweight locality enhancement module, which together enable structural alignment for weight inheritance and representational alignment for shift-invariance and locality.
Load-bearing premise
The added normalization and locality module close the representational gap between Softmax and linear attention enough for inherited weights to succeed after brief fine-tuning.
What would settle it
After the one-hour fine-tuning step, the linearized SD3.5-T^5 model produces images whose quality metrics, such as FID or CLIP score, fall measurably below those of the fine-tuned Softmax baseline at 1K or 2K resolution.
Figures



read the original abstract
While linear-complexity attention mechanisms offer a promising alternative to Softmax attention for overcoming the quadratic bottleneck, training such models from scratch remains prohibitively expensive. Inheriting weights from pretrained Transformers provides an appealing shortcut, yet the fundamental representational gap between Softmax and linear attention prevents effective weight transfer. In this work, we address this conversion challenge from two perspectives: architectural alignment and representational alignment. We identify Test-Time Training (TTT) as a linear-complexity architecture whose two-layer dynamic formulation is structurally aligned with Softmax attention, enabling direct inheritance of pretrained attention weights. To further align representational properties, including key shift-invariance and locality, we introduce key instance normalization and a lightweight locality enhancement module. We validate our approach by linearizing Stable Diffusion 3.5 and introduce SD3.5-T$^5$ (Transformer To Test Time Training). With only 1 hour of fine-tuning on 4$\times$H20 GPUs, SD3.5-T$^5$ achieves comparable text-to-image quality to the fine-tuned Softmax model, while accelerating inference by 1.32$\times$ and 1.47$\times$ at 1K and 2K resolutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Test-Time Training (TTT) provides a linear-complexity attention mechanism whose two-layer dynamic formulation is structurally aligned with Softmax attention, enabling direct inheritance of pretrained weights from models such as Stable Diffusion 3.5. By adding key instance normalization for shift-invariance and a lightweight locality enhancement module, the representational gap is closed sufficiently to allow only 1 hour of fine-tuning on 4×H20 GPUs, yielding SD3.5-T^5 with text-to-image quality comparable to the fine-tuned Softmax baseline and inference speedups of 1.32× at 1K and 1.47× at 2K resolutions.
Significance. If the results hold, the work offers a practical shortcut for converting large pretrained vision transformers to linear attention without full retraining from scratch, which could substantially reduce the cost of deploying high-resolution generative models. The explicit use of architectural and representational alignment to enable weight inheritance is a concrete contribution that addresses a known barrier in linearizing transformers.
major comments (2)
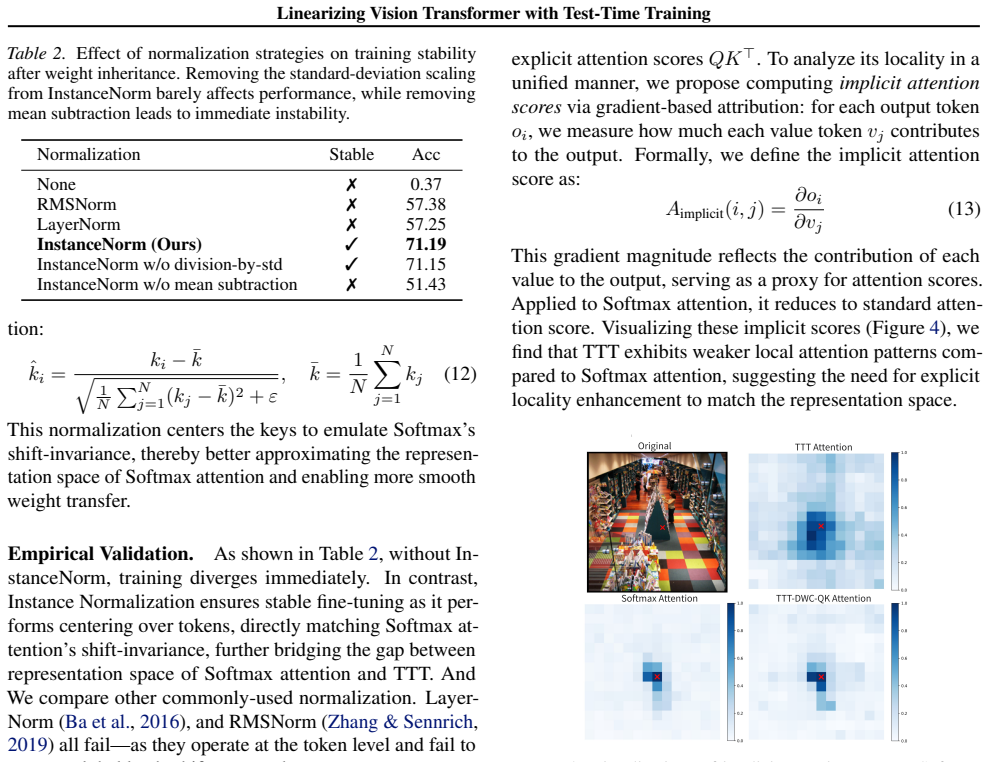
- [Method (architectural and representational alignment subsections)] The central shortcut of 1-hour fine-tuning after weight inheritance rests on the unverified assumption that TTT's two-layer dynamic formulation plus the two added modules close the Softmax-to-linear representational gap tightly enough for effective transfer. No derivation or explicit mapping is given showing how pretrained Q/K/V weights correspond to TTT's dynamic parameters (see the architectural alignment discussion). Without this, it remains unclear whether observed quality parity stems from the inheritance mechanism or from the fine-tuning itself compensating for a larger gap.
- [Experiments and Results] Experimental claims of 'comparable text-to-image quality' and specific speedups are presented without accompanying quantitative metrics, baseline tables, ablation studies on the normalization/locality modules, or error analysis in the provided summary. This makes it impossible to verify the strength of the performance parity or the contribution of each alignment component.
minor comments (2)
- [Abstract] The abstract introduces SD3.5-T^5 without defining the superscript notation or the exact meaning of T^5 on first use.
- [Figures and Tables] Figure captions and result tables should explicitly state the evaluation metrics (e.g., FID, CLIP score) and the precise fine-tuning protocol used for both the Softmax and TTT models to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential. We address each major comment below with clarifications and commitments to revision.
read point-by-point responses
-
Referee: [Method (architectural and representational alignment subsections)] The central shortcut of 1-hour fine-tuning after weight inheritance rests on the unverified assumption that TTT's two-layer dynamic formulation plus the two added modules close the Softmax-to-linear representational gap tightly enough for effective transfer. No derivation or explicit mapping is given showing how pretrained Q/K/V weights correspond to TTT's dynamic parameters (see the architectural alignment discussion). Without this, it remains unclear whether observed quality parity stems from the inheritance mechanism or from the fine-tuning itself compensating for a larger gap.
Authors: We agree that an explicit derivation would strengthen the architectural alignment claim. The manuscript identifies the structural match between TTT's two-layer dynamic formulation and Softmax attention as the basis for direct weight inheritance from models such as Stable Diffusion 3.5. In the revision, we will add a dedicated derivation in the architectural alignment subsection that maps the pretrained Q/K/V projections onto TTT's dynamic parameters, and we will explicitly show how key instance normalization and the locality module address the residual representational differences. This addition will clarify that the 1-hour fine-tuning leverages the close initial alignment rather than compensating for a substantial gap. revision: yes
-
Referee: [Experiments and Results] Experimental claims of 'comparable text-to-image quality' and specific speedups are presented without accompanying quantitative metrics, baseline tables, ablation studies on the normalization/locality modules, or error analysis in the provided summary. This makes it impossible to verify the strength of the performance parity or the contribution of each alignment component.
Authors: The manuscript reports the specific speedups of 1.32× at 1K and 1.47× at 2K resolutions along with the claim of comparable quality after 1-hour fine-tuning on 4×H20 GPUs. To improve verifiability as requested, the revised version will expand the results section with quantitative metrics (such as FID and CLIP scores for quality), explicit baseline comparison tables, ablation studies isolating the key normalization and locality modules, and basic error analysis. These elements will be referenced clearly from the abstract and summary as well. revision: yes
Circularity Check
No circularity: approach rests on architectural identification and empirical fine-tuning without self-referential reduction.
full rationale
The paper identifies TTT's two-layer dynamic formulation as structurally aligned with Softmax attention to enable weight inheritance, then adds key instance normalization and a locality module for further alignment, followed by 1-hour fine-tuning. No equations, derivations, or parameter fits are presented that reduce the claimed representational closure or performance parity to the inputs by construction. The central steps are explicit architectural choices and short empirical validation, which remain independent of any self-definition, fitted-input prediction, or self-citation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Test-Time Training two-layer dynamic formulation is structurally aligned with Softmax attention, enabling direct inheritance of pretrained attention weights
Reference graph
Works this paper leans on
-
[1]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450,
-
[2]
Atlas: Learning to optimally memorize the context at test time, 2025
Behrouz, A., Li, Z., Kacham, P., Daliri, M., Deng, Y ., Zhong, P., Razaviyayn, M., and Mirrokni, V . Atlas: Learning to optimally memorize the context at test time.arXiv preprint arXiv:2505.23735,
-
[3]
Exploring diffusion transformer designs via grafting
Chandrasegaran, K., Poli, M., Fu, D. Y ., Kim, D., Hadzic, L. M., Li, M., Gupta, A., Massaroli, S., Mirhoseini, A., Niebles, J. C., et al. Exploring diffusion transformer designs via grafting.arXiv preprint arXiv:2506.05340,
-
[4]
Ttt3r: 3d reconstruction as test-time training
Chen, X., Chen, Y ., Xiu, Y ., Geiger, A., and Chen, A. Ttt3r: 3d reconstruction as test-time training.arXiv preprint arXiv:2509.26645,
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page Pith review arXiv 2010
-
[6]
ViT$^3$: Unlocking Test-Time Training in Vision
Han, D., Li, Y ., Li, T., Cao, Z., Wang, Z., Song, J., Cheng, Y ., Zheng, B., and Huang, G. Vit3: Unlocking test-time train- ing in vision.arXiv preprint arXiv:2512.01643,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Hu, X., Wang, R., Fang, Y ., Fu, B., Cheng, P., and Yu, G. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135,
work page internal anchor Pith review arXiv
-
[8]
Scalable adaptive computation for iterative generation,
Jabri, A., Fleet, D., and Chen, T. Scalable adaptive computation for iterative generation.arXiv preprint arXiv:2212.11972,
-
[9]
URL https://huggingface.co/datasets/ lehduong/flux_generated. Liu, S., Tan, Z., and Wang, X. Clear: Conv-like linearization revs pre-trained diffusion transformers up.arXiv preprint arXiv:2412.16112, 2024a. 10 Linearizing Vision Transformer with Test-Time Training Liu, Y ., Tian, Y ., Zhao, Y ., Yu, H., Xie, L., Wang, Y ., Ye, Q., Jiao, J., and Liu, Y . V...
-
[10]
Learning to (Learn at Test Time):
Sun, Y ., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., Dubois, Y ., Chen, X., Wang, X., Koyejo, S., et al. Learn- ing to (learn at test time): Rnns with expressive hidden states.arXiv preprint arXiv:2407.04620,
-
[11]
Teng, Y ., Wu, Y ., Shi, H., Ning, X., Dai, G., Wang, Y ., Li, Z., and Liu, X. Dim: Diffusion mamba for effi- cient high-resolution image synthesis.arXiv preprint arXiv:2405.14224,
-
[12]
Instance normalization: The missing in- gredient for fast stylization
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., and J´egou, H. Training data-efficient image transform- ers & distillation through attention. InInternational con- ference on machine learning, pp. 10347–10357. PMLR, 2021a. Touvron, H., Cord, M., Sablayrolles, A., Synnaeve, G., and J´egou, H. Going deeper with image transformers. In Proceedin...
-
[13]
Wang, J., Kang, N., Yao, L., Chen, M., Wu, C., Zhang, S., Xue, S., Liu, Y ., Wu, T., Liu, X., et al. Lit: Delving into a simplified linear diffusion transformer for image generation.arXiv preprint arXiv:2501.12976, 2025a. Wang, P., Zhou, Y ., Wu, M., Zhang, P., Wang, Z., and Wang, K. Data efficient any transformer-to-mamba distillation via attention bridg...
-
[14]
arXiv preprint arXiv:2312.06635 , year=
Yang, S., Wang, B., Shen, Y ., Panda, R., and Kim, Y . Gated linear attention transformers with hardware-efficient train- ing.arXiv preprint arXiv:2312.06635,
-
[15]
Lolcats: On low-rank linearizing of large language models
Zhang, M., Arora, S., Chalamala, R., Wu, A., Spector, B., Singhal, A., Ramesh, K., and R ´e, C. Lolcats: On low- rank linearizing of large language models.arXiv preprint arXiv:2410.10254, 2024a. 11 Linearizing Vision Transformer with Test-Time Training Zhang, M., Bhatia, K., Kumbong, H., and R ´e, C. The hedgehog & the porcupine: Expressive linear attenti...
-
[16]
Image Classification We adopt the 30-epoch fine-tuning learning rate schedule from Swin Transformer (Liu et al., 2021)
12 Linearizing Vision Transformer with Test-Time Training A. Image Classification We adopt the 30-epoch fine-tuning learning rate schedule from Swin Transformer (Liu et al., 2021). The detailed hyperpa- rameters are summarized in Table
2021
-
[17]
For TTT, following ViT3 (Han et al., 2025), we set the activation function to SiLU and adopt the inner product loss for the inner model objective
For linear attention, we use ELU+ 1 as the activation function. For TTT, following ViT3 (Han et al., 2025), we set the activation function to SiLU and adopt the inner product loss for the inner model objective. Table 8.Hyperparameters for image classification on ImageNet-1K. Hyperparameter Value Optimizer AdamW Base learning rate2×10 −5 Weight decay1×10 −...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.