Recognition: unknown
Decoupled Guidance Diffusion for Adaptive Offline Safe Reinforcement Learning
Pith reviewed 2026-05-09 15:41 UTC · model grok-4.3
The pith
Safe Decoupled Guidance Diffusion conditions cost limits separately from reward gradients to handle varying safety budgets at deployment in offline RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Safe Decoupled Guidance Diffusion (SDGD) conditions classifier-free guidance on the cost limit to bias sampling toward trajectories satisfying the specified limit, while using reward-gradient guidance to refine trajectories for higher return; Feasible Trajectory Relabeling reshapes reward targets to discourage directions that increase cumulative cost, and first-order sampling-time analysis shows this suppresses reward-induced cost drift under a prefix-restorative alignment condition.
What carries the argument
Safe Decoupled Guidance Diffusion (SDGD) with Feasible Trajectory Relabeling (FTR), which decouples safety enforcement via cost-conditioned classifier-free guidance from reward optimization and relabels targets to keep cost from rising.
Load-bearing premise
The prefix-restorative alignment condition holds so reward guidance does not produce lasting cost drift during sampling.
What would settle it
A controlled test that violates the prefix-restorative alignment condition and shows SDGD samples violate the cost limit more often than baselines while still increasing reward.
Figures





read the original abstract
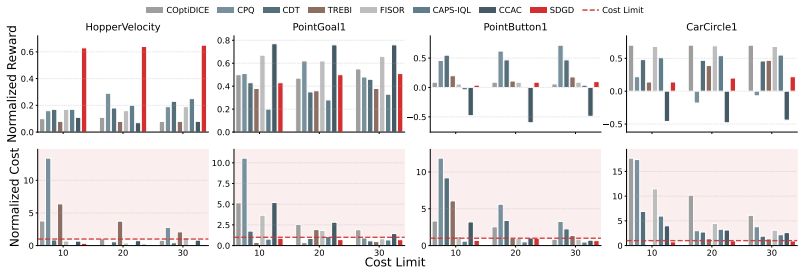
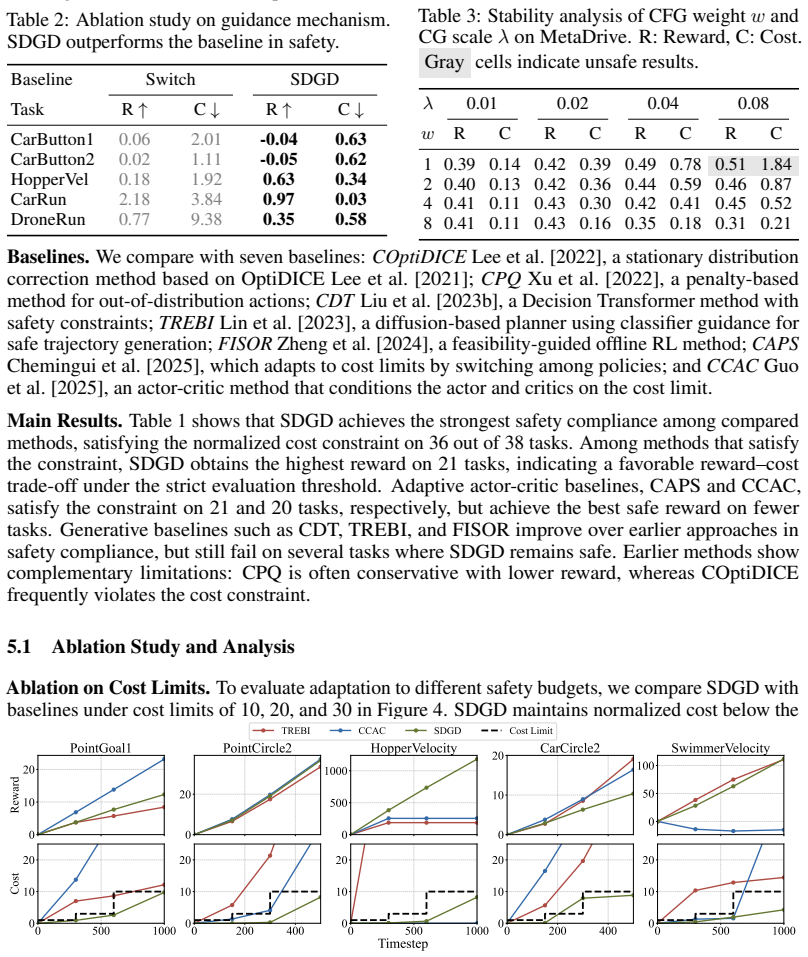
Offline safe reinforcement learning often requires policies to adapt at deployment time to safety budgets that vary across episodes or change within a single episode. While diffusion-based planners enable flexible trajectory generation, existing guidance schemes often treat reward improvement and constraint satisfaction as competing gradient objectives, which can lead to unreliable safety compliance under cost limits. We reinterpret adaptive safe trajectory generation as sampling from a constrained trajectory distribution, where the budget restricts the trajectory region, and reward shapes preferences within that region. This perspective motivates Safe Decoupled Guidance Diffusion (SDGD), which conditions classifier-free guidance on the cost limit to bias sampling toward trajectories satisfying the specified limit, while using reward-gradient guidance to refine trajectories for higher return. Because direct reward guidance can increase return while also steering samples toward trajectories with higher cumulative cost, we introduce Feasible Trajectory Relabeling (FTR) to reshape reward targets and discourage such directions. We further provide a first-order sampling-time analysis showing that FTR suppresses reward-induced cost drift under a prefix-restorative alignment condition. Extensive evaluations on the DSRL benchmark show that SDGD achieves the strongest safety compliance among baselines, satisfying the constraint on 94.7% of tasks (36/38), while obtaining the highest reward among safe methods on 21 tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Safe Decoupled Guidance Diffusion (SDGD) for adaptive offline safe reinforcement learning. It reinterprets trajectory generation as sampling from a cost-constrained distribution, using classifier-free guidance conditioned on the cost limit to enforce safety while applying separate reward-gradient guidance for return improvement. Feasible Trajectory Relabeling (FTR) is introduced to reshape reward targets and reduce cost drift, supported by a first-order sampling-time analysis under a prefix-restorative alignment condition. On the DSRL benchmark, SDGD is reported to satisfy safety constraints on 94.7% of tasks (36/38) while achieving the highest reward among safe methods on 21 tasks.
Significance. If the empirical results and the safety analysis hold, the work provides a principled decoupling of safety and reward objectives in diffusion planners for offline safe RL, which could enable more reliable adaptation to varying or intra-episode cost budgets. The benchmark results demonstrate practical promise, and credit is due for the extensive DSRL evaluations and the attempt to derive a sampling-time drift bound. The significance would increase with reproducible code or explicit verification of the alignment condition.
major comments (2)
- [first-order sampling-time analysis] The first-order sampling-time analysis claims that FTR suppresses reward-induced cost drift under the prefix-restorative alignment condition, but no empirical verification of this condition (e.g., via alignment metric on sampled prefixes from the learned score functions) is reported on the DSRL tasks, and the diffusion training does not explicitly enforce it. This condition is load-bearing for moving beyond pure empirical safety claims.
- [Experiments / DSRL benchmark results] The reported 94.7% compliance (36/38 tasks) and superiority on 21 tasks lack accompanying details on number of random seeds, error bars, or ablations isolating the contribution of cost-conditioned guidance versus FTR; without these, it is unclear whether post-hoc hyperparameter choices affect the safety-reward tradeoff.
minor comments (2)
- [Abstract] The abstract states 'strongest safety compliance among baselines' without naming the baselines or providing a summary table of all methods' compliance rates and returns.
- [Method overview] Notation for the constrained trajectory distribution and how the cost limit enters the classifier-free guidance should be introduced earlier with an explicit equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the corresponding revisions.
read point-by-point responses
-
Referee: The first-order sampling-time analysis claims that FTR suppresses reward-induced cost drift under the prefix-restorative alignment condition, but no empirical verification of this condition (e.g., via alignment metric on sampled prefixes from the learned score functions) is reported on the DSRL tasks, and the diffusion training does not explicitly enforce it. This condition is load-bearing for moving beyond pure empirical safety claims.
Authors: We agree that the manuscript presents the first-order bound under the prefix-restorative alignment condition without reporting a direct empirical check of that condition on the DSRL tasks. The analysis is intended to explain the mechanism by which FTR limits cost drift during sampling; the training procedure itself does not enforce the condition. To strengthen the connection between the theory and the empirical results, the revised manuscript will include a post-hoc evaluation of an alignment metric computed on prefixes sampled from the trained score functions across representative DSRL tasks. revision: yes
-
Referee: The reported 94.7% compliance (36/38 tasks) and superiority on 21 tasks lack accompanying details on number of random seeds, error bars, or ablations isolating the contribution of cost-conditioned guidance versus FTR; without these, it is unclear whether post-hoc hyperparameter choices affect the safety-reward tradeoff.
Authors: The referee correctly notes that the current manuscript reports aggregate success rates without stating the number of random seeds, without error bars, and without ablations that separate the contributions of cost-conditioned guidance and FTR. In the revision we will add these elements: results will be reported with the number of seeds and standard-error bars, and we will include ablations that disable cost-conditioned guidance and FTR individually to quantify their separate effects on safety compliance and reward. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces SDGD, FTR, and a first-order sampling-time analysis under the prefix-restorative alignment condition, with empirical results on the DSRL benchmark. No equations or steps reduce claimed predictions or safety guarantees to inputs by construction. No self-citations are load-bearing, no fitted parameters are renamed as predictions, and no ansatz or uniqueness is smuggled via prior work. The conditional analysis is presented as such without self-referential definitions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Janaka Chathuranga Brahmanage and Akshat Kumar. Beyond hard constraints: Budget-conditioned reachability for safe offline reinforcement learning.arXiv preprint arXiv:2603.22292,
-
[2]
Hao Ma, Sabrina Bodmer, Andrea Carron, Melanie Zeilinger, and Michael Muehlebach. Constraint- aware diffusion guidance for robotics: Real-time obstacle avoidance for autonomous racing.arXiv preprint arXiv:2505.13131,
-
[3]
Kwanyoung Park, Seohong Park, Youngwoon Lee, and Sergey Levine
URL https: //openreview.net/forum?id=vFLrQgI6MW. Kwanyoung Park, Seohong Park, Youngwoon Lee, and Sergey Levine. Scalable offline model-based rl with action chunks.arXiv preprint arXiv:2512.08108,
-
[4]
Dongxiu Liu, Haoyi Niu, Zhihao Wang, Jinliang Zheng, Yinan Zheng, Zhonghong Ou, Jianming Hu, Jianxiong Li, and Xianyuan Zhan. Efficient robotic policy learning via latent space backward planning.arXiv preprint arXiv:2505.06861,
-
[5]
Jichen Zhang, Liqun Zhao, Antonis Papachristodoulou, and Jack Umenberger. Constrained diffusers for safe planning and control.arXiv preprint arXiv:2506.12544,
-
[6]
Datasets and benchmarks for offline safe reinforcement learning
Zuxin Liu, Zijian Guo, Haohong Lin, Yihang Yao, Jiacheng Zhu, Zhepeng Cen, Hanjiang Hu, Wenhao Yu, Tingnan Zhang, Jie Tan, et al. Datasets and benchmarks for offline safe reinforcement learning. arXiv preprint arXiv:2306.09303, 2023a. Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforcement learning by pid lagrangian methods. InIn...
-
[7]
Jongmin Lee, Cosmin Paduraru, Daniel J Mankowitz, Nicolas Heess, Doina Precup, Kee-Eung Kim, and Arthur Guez. Coptidice: Offline constrained reinforcement learning via stationary distribution correction estimation.arXiv preprint arXiv:2204.08957,
-
[8]
Yinan Zheng, Jianxiong Li, Dongjie Yu, Yujie Yang, Shengbo Eben Li, Xianyuan Zhan, and Jingjing Liu. Safe offline reinforcement learning with feasibility-guided diffusion model.arXiv preprint arXiv:2401.10700,
-
[9]
arXiv preprint arXiv:2011.04021 , year=
Jessica B Hamrick, Abram L Friesen, Feryal Behbahani, Arthur Guez, Fabio Viola, Sims Witherspoon, Thomas Anthony, Lars Buesing, Petar Veliˇckovi´c, and Théophane Weber. On the role of planning in model-based deep reinforcement learning.arXiv preprint arXiv:2011.04021,
-
[10]
Kirsch, L., Harrison, J., Freeman, C., Sohl-Dickstein, J., and Schmidhuber, J
Sili Huang, Jifeng Hu, Hechang Chen, Lichao Sun, and Bo Yang. In-context decision transformer: Reinforcement learning via hierarchical chain-of-thought.arXiv preprint arXiv:2405.20692,
-
[11]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991,
work page internal anchor Pith review arXiv
-
[12]
Is Conditional Generative Modeling all you need for Decision-Making?
Anurag Ajay, Yilun Du, Abhi Gupta, Joshua Tenenbaum, Tommi Jaakkola, and Pulkit Agrawal. Is con- ditional generative modeling all you need for decision-making?arXiv preprint arXiv:2211.15657,
work page internal anchor Pith review arXiv
-
[13]
Sixu Yan, Zeyu Zhang, Muzhi Han, Zaijin Wang, Qi Xie, Zhitian Li, Zhehan Li, Hangxin Liu, Xinggang Wang, and Song-Chun Zhu. M2diffuser: Diffusion-based trajectory optimization for mobile manipulation in 3d scenes.arXiv preprint arXiv:2410.11402,
-
[14]
Reasoning with latent diffusion in offline reinforcement learning.arXiv preprint arXiv:2309.06599,
Siddarth Venkatraman, Shivesh Khaitan, Ravi Tej Akella, John Dolan, Jeff Schneider, and Glen Berseth. Reasoning with latent diffusion in offline reinforcement learning.arXiv preprint arXiv:2309.06599,
-
[15]
Efficient planning with latent diffusion.arXiv preprint arXiv:2310.00311,
Wenhao Li. Efficient planning with latent diffusion.arXiv preprint arXiv:2310.00311,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.