Recognition: 3 theorem links
· Lean TheoremTwo-scale Neural Networks for Singularly Perturbed Dynamical Systems with Multiple Parameters
Pith reviewed 2026-05-08 18:41 UTC · model grok-4.3
The pith
Two-scale neural networks capture sharp transitions in singularly perturbed dynamical systems with multiple parameters by using the geometric mean of the parameters as a single scale input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that augmenting the input of a two-scale neural network with a scale-aware feature based on the geometric mean of multiple small parameters allows the network to intrinsically capture sharp solution transitions in singularly perturbed dynamical systems, with numerical experiments confirming satisfactory accuracy for coupled systems having high-contrast parameters.
What carries the argument
The single effective scale parameter, computed as the geometric mean of all small parameters and used to augment the neural network input as a scale-aware feature.
If this is right
- The proposed framework handles coupled systems with multiple and high-contrast small parameters.
- It obtains satisfactory accuracy in capturing solution features induced by small parameters.
- The method extends successfully from scalar problems with one parameter to dynamical systems with several parameters.
- Numerical experiments across a range of systems support the approach.
Where Pith is reading between the lines
- This reduction to a single scale via geometric mean may simplify application to other multi-parameter problems without changing the network architecture.
- The method could be tested on systems with three or more small parameters to check if the geometric mean remains effective.
- It may provide an alternative to traditional methods for stiff systems that require fine resolution or asymptotic analysis.
- Potential connections exist to other machine-learning techniques for differential equations with varying stiffness levels.
Load-bearing premise
That defining a single effective scale as the geometric mean of all small parameters is sufficient for the neural network to capture the sharp transitions induced by each individual parameter and their interactions.
What would settle it
A dynamical system example where using the geometric mean scale leads to poor approximation of at least one transition layer caused by a specific small parameter, while reference solutions show distinct features not aligned with the mean.
Figures












read the original abstract
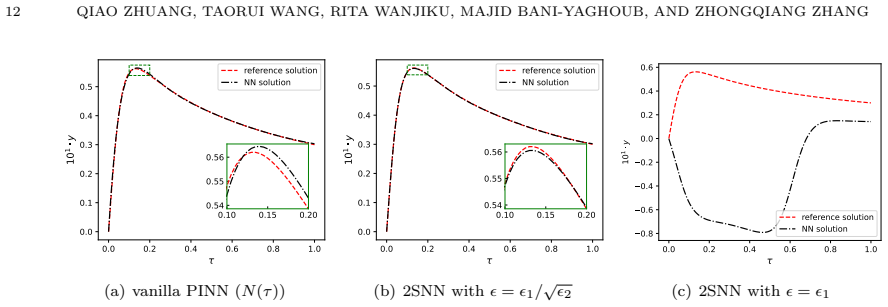
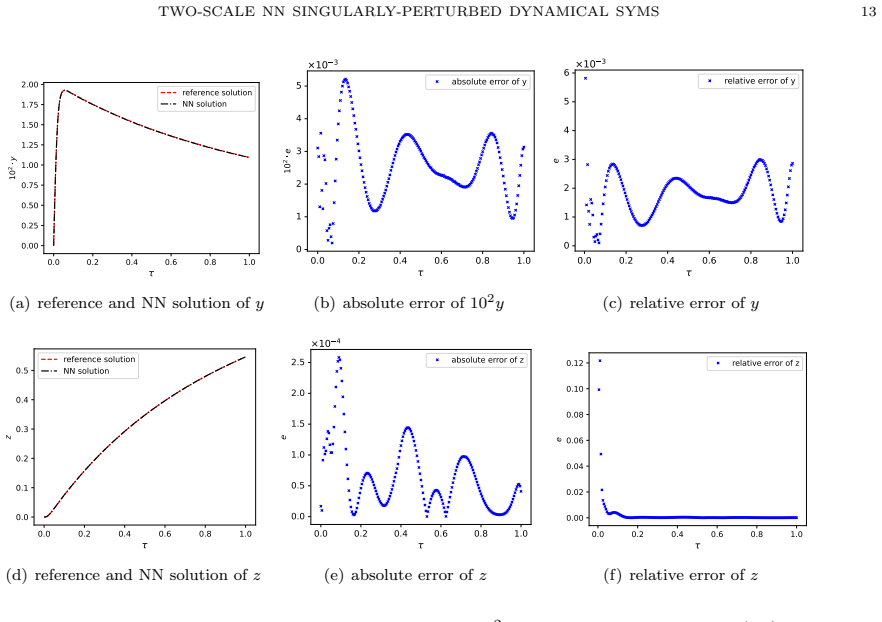
We extend our two-scale neural-network method for scalar singularly perturbed problems with one small parameter to dynamical systems with multiple small parameters. To accommodate multiple small parameters, we use a single effective scale parameter defined as the geometric mean of all parameters. We thus augment the network input with a scale-aware feature, enabling it to capture sharp solution transitions intrinsically. Numerical experiments across a range of dynamical systems demonstrate that the proposed framework can handle coupled systems with multiple and high-contrast small parameters and obtain satisfactory accuracy in capturing solution features induced by small parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends a prior two-scale neural-network method for scalar singularly perturbed problems to dynamical systems with multiple small parameters. It augments the network input with a single effective scale defined as the geometric mean of all small parameters, allowing the network to capture sharp transitions intrinsically. Numerical experiments on a range of dynamical systems, including coupled systems with high-contrast parameters, are used to claim satisfactory accuracy in resolving solution features induced by the small parameters.
Significance. If the single-scale augmentation reliably resolves distinct transition layers and their interactions, the method would offer a simple, architecture-light alternative to multi-scale or layer-adapted discretizations for multi-parameter singularly perturbed systems, which are common in applications such as chemical kinetics and fluid mechanics.
major comments (2)
- [Abstract and numerical experiments] Abstract and numerical-experiments description: the claim of 'satisfactory accuracy' for high-contrast cases is unsupported by any quantitative error metrics, baseline comparisons against multi-scale networks or classical methods, reported contrast ratios, or convergence rates, preventing assessment of whether the geometric-mean input suffices.
- [Method] Method section (definition of effective scale): the geometric mean is introduced without accompanying analysis or numerical tests showing that a single scale aligns with individual layer thicknesses when parameters differ by several orders of magnitude; this directly bears on the central claim that the network 'intrinsically captures' each parameter's transitions and their interactions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and numerical experiments] Abstract and numerical-experiments description: the claim of 'satisfactory accuracy' for high-contrast cases is unsupported by any quantitative error metrics, baseline comparisons against multi-scale networks or classical methods, reported contrast ratios, or convergence rates, preventing assessment of whether the geometric-mean input suffices.
Authors: We agree that the current abstract and experiments section would benefit from more explicit quantitative support. In the revised manuscript we will report the specific contrast ratios employed (e.g., parameters differing by three or more orders of magnitude), include L² and maximum-norm error tables for the high-contrast test cases, and add brief comparisons against a standard multi-scale network and a layer-adapted finite-difference scheme. These additions will allow readers to evaluate the geometric-mean augmentation directly. revision: yes
-
Referee: [Method] Method section (definition of effective scale): the geometric mean is introduced without accompanying analysis or numerical tests showing that a single scale aligns with individual layer thicknesses when parameters differ by several orders of magnitude; this directly bears on the central claim that the network 'intrinsically captures' each parameter's transitions and their interactions.
Authors: The geometric mean is adopted as a practical single-scale surrogate that reflects the combined stiffness of the system. While a full asymptotic analysis of layer-thickness alignment lies outside the scope of this work, the numerical experiments already contain high-contrast examples in which the individual transition layers are visibly resolved. In the revision we will expand the method section with a short paragraph motivating the geometric-mean choice and explicitly cross-reference the high-contrast experiments that demonstrate capture of distinct layers and their interactions. revision: partial
Circularity Check
Explicit geometric-mean scale definition is non-circular methodological extension
full rationale
The paper extends its prior two-scale NN framework by explicitly defining a single effective scale as the geometric mean of multiple small parameters and augmenting the network input with this defined feature. No equations or claims reduce a prediction or derived quantity to the inputs by construction, nor do any fitted parameters get relabeled as predictions. Validation rests on numerical experiments rather than self-referential derivations. The single self-citation to the authors' earlier two-scale work is minor and not load-bearing for the central multi-parameter claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single effective scale defined as the geometric mean of all small parameters suffices to represent their combined influence on solution transitions.
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.BranchSelectionwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we use a single effective scale parameter defined as the geometric mean of all parameters... ϵ = ⁿ√(ϵ_1 ϵ_2 ··· ϵ_n)
-
Foundation.AlphaCoordinateFixationalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we take γ=−1/2... β ∈ {1/2, 1}, we take γ = −1/2. This milder stretching avoids excessive localization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abeysuriya, Jonathan Hadida, Stamatios N
Romesh G. Abeysuriya, Jonathan Hadida, Stamatios N. Sotiropoulos, Saad Jbabdi, Robert Becker, Benjamin A. E. Hunt, Matthew J. Brookes, and Mark W. Woolrich. A biophysical model of dynamic balancing of excitation and inhibition in fast oscillatory large-scale networks.PLOS Computational Biology, 14:1–27, 02 2018
2018
-
[2]
Multi-level neural networks for accurate solutions of boundary-value problems.Comput
Ziad Aldirany, R´ egis Cottereau, Marc Laforest, and Serge Prudhomme. Multi-level neural networks for accurate solutions of boundary-value problems.Comput. Methods Appl. Mech. Engrg., 419:116666, 2024
2024
-
[3]
Lightweight Geometric Adaptation for Training Physics-Informed Neural Networks
Kang An, Chenhao Si, Shiqian Ma, and Ming Yan. Lightweight geometric adaptation for training physics-informed neural networks.arXiv:2604.15392, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Anagnostopoulos, Juan Diego Toscano, Nikolaos Stergiopulos, and George Em Karniadakis
Sokratis J. Anagnostopoulos, Juan Diego Toscano, Nikolaos Stergiopulos, and George Em Karniadakis. Residual-based attention and connection to information bottleneck theory in PINNs.Comput. Methods Appl. Mech. Engrg., 421:116805, 2024
2024
-
[5]
Pandit, and Sharif S
Arash Arjmand, Majid Bani-Yaghoub, Kiel Corkran, Pranav S. Pandit, and Sharif S. Aly. Assessing the impact of biose- curity compliance on farmworker and livestock health within a one health modeling framework.One Health, 20:101023, 2025
2025
-
[6]
Cassel, and Roshan M
Amirhossein Arzani, Kevin W. Cassel, and Roshan M. D’Souza. Theory-guided physics-informed neural networks for boundary layer problems with singular perturbation.Journal of Computational Physics, 473:111768, 2023
2023
-
[7]
A multiparameter singular perturbation analysis of the robertson model.Studies in Applied Mathematics, 154(2):e70020, 2025
Lukas Baumgartner and Peter Szmolyan. A multiparameter singular perturbation analysis of the robertson model.Studies in Applied Mathematics, 154(2):e70020, 2025
2025
-
[8]
Curriculum learning
Yoshua Bengio, J´ erˆ ome Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th annual international conference on machine learning, pages 41–48, 2009
2009
-
[9]
Asymptotic-preserving neural networks for multiscale hyperbolic models of epidemic spread.Math
Giulia Bertaglia, Chuan Lu, Lorenzo Pareschi, and Xueyu Zhu. Asymptotic-preserving neural networks for multiscale hyperbolic models of epidemic spread.Math. Models Methods Appl. Sci., 32(10):1949–1985, 2022
1949
-
[10]
Pradanya Boro, Aayushman Raina, and Srinivasan Natesan. A parameter-driven physics-informed neural network frame- work for solving two-parameter singular perturbation problems involving boundary layers.Advances in Computational Science and Engineering, 5:72–102, 2025
2025
-
[11]
On stabilized finite element methods for linear systems of convection-diffusion-reaction equations.Com- puter Methods in Applied Mechanics and Engineering, 188(1):61–82, 2000
Ramon Codina. On stabilized finite element methods for linear systems of convection-diffusion-reaction equations.Com- puter Methods in Applied Mechanics and Engineering, 188(1):61–82, 2000
2000
-
[12]
Adaptive multi-scale gradient-enhanced sampling physics-informed neural network for incompressible flow.Physics of Fluids, 38(2):027106, 02 2026
Shuaibing Ding, Juanmin Lei, Liang Xu, Boqian Zhang, Guoyou Sun, Jian Guo, and Yinggang Zhang. Adaptive multi-scale gradient-enhanced sampling physics-informed neural network for incompressible flow.Physics of Fluids, 38(2):027106, 02 2026. 20 QIAO ZHUANG, TAORUI W ANG, RITA W ANJIKU, MAJID BANI-YAGHOUB, AND ZHONGQIANG ZHANG
2026
-
[13]
Zhiwei Fang, Sifan Wang, and Paris Perdikaris. Ensemble learning for physics informed neural networks: a gradient boosting approach.arXiv:2302.13143, 2023
-
[14]
Gung-Min Gie, Youngjoon Hong, Chang-Yeol Jung, and Dongseok Lee. Singular layer physics-informed neural network method for convection-dominated boundary layer problems in two dimensions.Journal of Computational and Applied Mathematics, 474:116918, 2026
2026
-
[15]
Hierarchical class-based curriculum loss
Palash Goyal, Divya Choudhary, and Shalini Ghosh. Hierarchical class-based curriculum loss. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 2448–2454, 2021
2021
-
[16]
John K. Hunter. Chapter 4. InAsymptotic Analysis and Singular Perturbation Theory. University of California, Davis, 2004
2004
-
[17]
Asymptotic-preserving neural networks for multiscale time-dependent linear transport equations.J
Shi Jin, Zheng Ma, and Keke Wu. Asymptotic-preserving neural networks for multiscale time-dependent linear transport equations.J. Sci. Comput., 94(3):Paper No. 57, 21, 2023
2023
-
[18]
Curvature-Aware Optimization for High-Accuracy Physics-Informed Neural Networks
Anas Jnini, Elham Kiyani, Khemraj Shukla, Jorge F Urban, Nazanin Ahmadi Daryakenari, Johannes Muller, Marius Zeinhofer, and George Em Karniadakis. Curvature-aware optimization for high-accuracy physics-informed neural networks. arXiv:2604.05230, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Singular layer pinn methods for steep reaction-diffusion equations in a smooth convex domain.Engineering Analysis with Boundary Elements, 175:106178, 2025
Chang-Yeol Jung, Junghwa Kim, and Eaint Phoo Ngon. Singular layer pinn methods for steep reaction-diffusion equations in a smooth convex domain.Engineering Analysis with Boundary Elements, 175:106178, 2025
2025
-
[20]
Karthikeyan
Muthusamy Lakshmanan and Rajagopal R. Karthikeyan. A singular perturbation theory for the fitzhugh-nagumo nerve conduction equation.Physics Letters A, 82(5):266–270, 1981
1981
-
[21]
A multi-scale DNN algorithm for nonlinear elliptic equations with multiple scales.Commun
Xi-An Li, Zhi-Qin John Xu, and Lei Zhang. A multi-scale DNN algorithm for nonlinear elliptic equations with multiple scales.Commun. Comput. Phys., 28(5):1886–1906, 2020
1906
-
[22]
Subspace decomposition based DNN algorithm for elliptic type multi-scale PDEs.J
Xi-An Li, Zhi-Qin John Xu, and Lei Zhang. Subspace decomposition based DNN algorithm for elliptic type multi-scale PDEs.J. Comput. Phys., 488:Paper No. 112242, 17, 2023
2023
-
[23]
Springer, Berlin, Heidelberg, 1 edition, 2010
Torsten Linß.Layer-Adapted Meshes for Reaction-Convection-Diffusion Problems, volume 1985 ofLecture Notes in Math- ematics. Springer, Berlin, Heidelberg, 1 edition, 2010
1985
-
[24]
Discontinuity computing using physics-informed neural networks.Journal of Scientific Computing, 98(1):22, 2023
Li Liu, Shengping Liu, Hui Xie, Fansheng Xiong, Tengchao Yu, Mengjuan Xiao, Lufeng Liu, and Heng Yong. Discontinuity computing using physics-informed neural networks.Journal of Scientific Computing, 98(1):22, 2023
2023
-
[25]
Multi-scale deep neural network (MscaleDNN) for solving Poisson-Boltzmann equation in complex domains.Commun
Ziqi Liu, Wei Cai, and Zhi-Qin John Xu. Multi-scale deep neural network (MscaleDNN) for solving Poisson-Boltzmann equation in complex domains.Commun. Comput. Phys., 28(5):1970–2001, 2020
1970
-
[26]
Solving multiscale steady radiative transfer equation using neural networks with uniform stability.Res
Yulong Lu, Li Wang, and Wuzhe Xu. Solving multiscale steady radiative transfer equation using neural networks with uniform stability.Res. Math. Sci., 9(3):45, 2022
2022
-
[27]
Bera, Dibakar Ghosh, and Matjaˇ z Perc
Soumen Majhi, Bidesh K. Bera, Dibakar Ghosh, and Matjaˇ z Perc. Chimera states in neuronal networks: A review.Physics of Life Reviews, 28:100–121, 2019
2019
-
[28]
Die kinetik der invertinwirkung.Biochemische Zeitschrift, 49:333 – 369, 1913
Leonor Michaelis and Maud Leonora Menten. Die kinetik der invertinwirkung.Biochemische Zeitschrift, 49:333 – 369, 1913
1913
-
[29]
PAS-Net: Physics-informed adaptive scale deep operator network.arXiv:2511.14925, 2025
Changhong Mou, Yeyu Zhang, Xuewen Zhu, and Qiao Zhuang. PAS-Net: Physics-informed adaptive scale deep operator network.arXiv:2511.14925, 2025
-
[30]
Marcus M¨ unzer and Chris Bard. A curriculum-training-based strategy for distributing collocation points during physics- informed neural network training.arXiv:2211.11396, 2022
-
[31]
O’Malley.Singular Perturbation Methods for Ordinary Differential Equations, volume 89 ofApplied Mathemat- ical Sciences
Robert E. O’Malley.Singular Perturbation Methods for Ordinary Differential Equations, volume 89 ofApplied Mathemat- ical Sciences. Springer, New York, NY, 1 edition, 1991
1991
-
[32]
Slow invariant manifolds of singularly perturbed systems via physics-informed machine learning.SIAM Journal on Scientific Computing, 46(4):C297–C322, 2024
Dimitrios Patsatzis, Gianluca Fabiani, Lucia Russo, and Constantinos Siettos. Slow invariant manifolds of singularly perturbed systems via physics-informed machine learning.SIAM Journal on Scientific Computing, 46(4):C297–C322, 2024
2024
-
[33]
Patsatzis, Lucia Russo, and Constantinos Siettos
Dimitrios G. Patsatzis, Lucia Russo, and Constantinos Siettos. Slow invariant manifolds of fast-slow systems of odes with physics-informed neural networks.SIAM Journal on Applied Dynamical Systems, 23(4):3077–3122, 2024
2024
-
[34]
Sbalzarini, and Philippe Poncet
Sarah Perez, Suryanarayana Maddu, Ivo F. Sbalzarini, and Philippe Poncet. Adaptive weighting of bayesian physics informed neural networks for multitask and multiscale forward and inverse problems.Journal of Computational Physics, 491:112342, 2023
2023
-
[35]
Ransom and Dean R
Ben J. Ransom and Dean R. Wheeler. Rapid computation of effective conductivity of 2d composites by equivalent circuit and spectral methods.Mathematics in Engineering, 4(3):1–24, 2022
2022
-
[36]
H. H. Robertson. The solution of a set of reaction rate equations. InNumerical Analysis: An Introduction, pages 178–182. Academic Press, London, 1966
1966
-
[37]
Serino, Allen Alvarez Loya, J.W
Daniel A. Serino, Allen Alvarez Loya, J.W. Burby, Ioannis G. Kevrekidis, and Qi Tang. Fast-slow neural networks for learning singularly perturbed dynamical systems.Journal of Computational Physics, 537:114090, 2025
2025
-
[38]
Ping Sheng and R. V. Kohn. Geometric effects in continuous-media percolation.Phys. Rev. B, 26:1331–1335, Aug 1982
1982
-
[39]
Curriculum learning: A survey.International Journal of Computer Vision, 130(6):1526–1565, 2022
Petru Soviany, Radu Tudor Ionescu, Paolo Rota, and Nicu Sebe. Curriculum learning: A survey.International Journal of Computer Vision, 130(6):1526–1565, 2022
2022
-
[40]
Urb´ an, Petros Stefanou, and Jos´ e A
Jorge F. Urb´ an, Petros Stefanou, and Jos´ e A. Pons. Unveiling the optimization process of physics informed neural networks: How accurate and competitive can pinns be?Journal of Computational Physics, 523:113656, 2025
2025
-
[41]
Adaptive sampling points based multi-scale residual network for solving partial differential equations.Computers & Mathematics with Applications, 169:223–236, 2024
Jie Wang, Xinlong Feng, and Hui Xu. Adaptive sampling points based multi-scale residual network for solving partial differential equations.Computers & Mathematics with Applications, 169:223–236, 2024
2024
-
[42]
On the eigenvector bias of Fourier feature networks: from regression to solving multi-scale PDEs with physics-informed neural networks.Comput
Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of Fourier feature networks: from regression to solving multi-scale PDEs with physics-informed neural networks.Comput. Methods Appl. Mech. Engrg., 384:Paper No. 113938, 28, 2021. TWO-SCALE NN SINGULARLY-PERTURBED DYNAMICAL SYMS 21
2021
-
[43]
Multi-stage neural networks: Function approximator of machine precision.Journal of Computational Physics, 504:112865, 2024
Yongji Wang and Ching-Yao Lai. Multi-stage neural networks: Function approximator of machine precision.Journal of Computational Physics, 504:112865, 2024
2024
-
[44]
Two-scale neural networks for partial differential equations with small parameters.Communications in Computational Physics, 38(3):603–629, 2025
Qiao Zhuang, Chris Ziyi Yao, Zhongqiang Zhang, and George Em Karniadakis. Two-scale neural networks for partial differential equations with small parameters.Communications in Computational Physics, 38(3):603–629, 2025. (Qiao Zhuang)School of Science and Engineering, University of Missouri-Kansas City, Kansas City, MO 64110, USA Email address:qzhuang@umkc....
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.