Recognition: 2 theorem links
FlexSQL: Flexible Exploration and Execution Make Better Text-to-SQL Agents
Pith reviewed 2026-05-08 18:34 UTC · model grok-4.3
The pith
A text-to-SQL agent that explores schemas, inspects data, and repairs plans at any stage reaches 65.4% on Spider2-Snow while using a smaller model than stronger baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
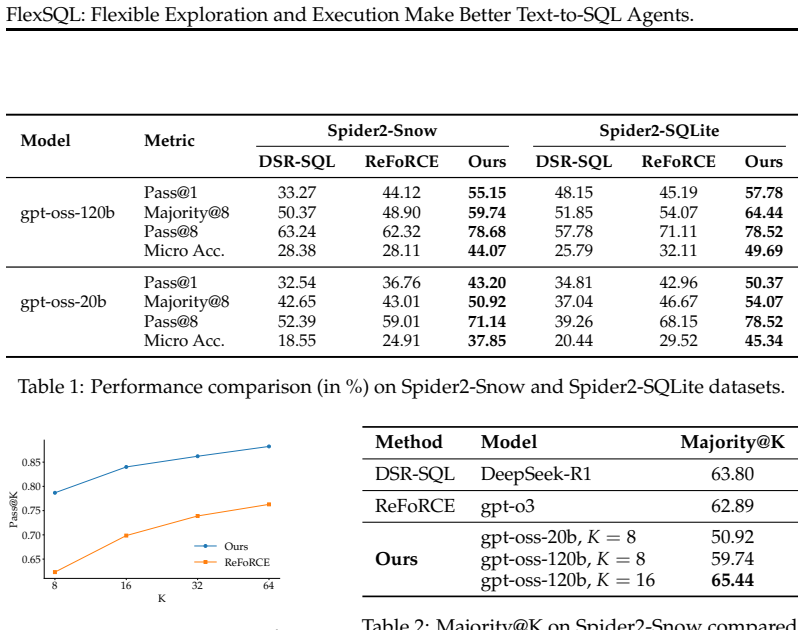
FlexSQL demonstrates that flexible database interaction enables an agent to explore schema structure, inspect data values, and execute verification queries at any point in its reasoning process. The system generates diverse execution plans covering multiple query interpretations, realizes each plan in either SQL or Python, and applies a two-tiered repair mechanism that backtracks from code errors to plan revisions. On the Spider2-Snow benchmark with gpt-oss-120b this yields 65.4% accuracy, surpassing strong open-source baselines that employ larger models such as gpt-o3 and DeepSeek-R1, and produces over 10% relative improvement when integrated into a general-purpose coding agent.
What carries the argument
Flexible database interaction that permits schema exploration, data inspection, and verification queries at arbitrary reasoning steps, combined with diverse plan generation and two-tiered repair for plan-level backtracking.
If this is right
- Early errors in schema interpretation can be corrected without restarting the entire generation process.
- Agents can switch between SQL and Python implementations depending on which better suits the current subtask.
- Diverse plan generation reduces the chance that an ambiguous query is answered under only one interpretation.
- Two-tiered repair allows recovery from both syntax errors and deeper logical mismatches.
- The same flexibility principle can be added as modular skills to existing coding agents.
Where Pith is reading between the lines
- Similar flexible interaction loops could improve agent performance on other schema-heavy or data-grounded tasks such as data wrangling or knowledge-base querying.
- Benchmarks that reward recovery from early mistakes will likely show larger gaps between flexible and rigid agents than benchmarks that penalize only final output.
- Future work could test whether the same two-tiered repair structure transfers to non-SQL domains such as API calling or code generation over large codebases.
Load-bearing premise
The accuracy gains arise primarily from the flexible exploration and execution design rather than from unstated differences in prompting, model version, or benchmark tuning.
What would settle it
A head-to-head comparison on Spider2-Snow in which an otherwise identical agent uses a fixed pipeline with the same model, prompt templates, and repair budget but no mid-reasoning database access.
Figures


read the original abstract
Text-to-SQL over large analytical databases requires navigating complex schemas, resolving ambiguous queries, and grounding decisions in actual data. Most current systems follow a fixed pipeline where schema elements are retrieved once upfront and the database is only revisited for post-hoc repair, limiting recovery from early mistakes. We present FlexSQL, a text-to-SQL agent whose core design principle is flexible database interaction: the agent can explore schema structure, inspect data values, and run verification queries at any point during reasoning. FlexSQL generates diverse execution plans to cover multiple query interpretations, implements each plan in either SQL or Python depending on the task, and uses a two-tiered repair mechanism that can backtrack from code-level errors to plan-level revisions. On Spider2-Snow, using gpt-oss-120b, FlexSQL achieves a 65.4\% score, outperforming strong open-source baselines that use stronger, larger models such as gpt-o3 and DeepSeek-R1. When integrated into a general-purpose coding agent (as skills in Claude Code), our approach yields over 10\% relative improvement on Spider2-Snow. Further analysis shows that flexible exploration and flexible execution jointly contribute to the effectiveness of our approach, highlighting flexibility as a key design principle. Our code is available at: https://github.com/StringNLPLAB/FlexSQL
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlexSQL, a text-to-SQL agent that prioritizes flexible database interaction by allowing schema exploration, data inspection, and verification queries at any reasoning step. It generates diverse execution plans, selects between SQL or Python implementations, and applies a two-tiered repair mechanism for backtracking from errors. On the Spider2-Snow benchmark using gpt-oss-120b, FlexSQL reports 65.4% accuracy, outperforming open-source baselines that employ stronger models such as gpt-o3 and DeepSeek-R1. The authors further claim that flexible exploration and execution jointly drive the gains, demonstrate integration as skills in a general coding agent (Claude Code) yielding >10% relative improvement, and release code at https://github.com/StringNLPLAB/FlexSQL.
Significance. If the performance gains can be rigorously attributed to the flexibility mechanisms rather than confounding factors, this work would strengthen the case for non-fixed pipelines in Text-to-SQL agents, particularly for complex analytical schemas. The open code release and the demonstration of composability with general-purpose coding agents are concrete strengths that support reproducibility and broader applicability.
major comments (3)
- [§4, Table 1] §4 (Experiments) and Table 1: The headline 65.4% result on Spider2-Snow is presented without error bars, multiple runs, or statistical tests, and the paper does not explicitly state whether baseline reproductions (gpt-o3, DeepSeek-R1) used identical prompt templates, temperature, or the same two-tiered repair loop; this directly undermines the claim that gains are due to flexible exploration and execution.
- [§5] §5 (Analysis): The ablation claiming that 'flexible exploration and flexible execution jointly contribute' does not confirm that ablated variants held all other components (model, prompt structure, plan diversity generation, and repair tiers) fixed; without this, the attribution to the core design principle cannot be isolated.
- [§3.3] §3.3 (Two-tiered repair): The mechanism for backtracking from code-level errors to plan-level revisions is described at a high level but lacks pseudocode, exact decision criteria, or implementation details sufficient for reproduction, which is load-bearing for the claimed recovery from early mistakes.
minor comments (2)
- [Abstract, §4] The abstract and §4 refer to 'gpt-oss-120b' without clarifying its exact open-source status or parameter count relative to the cited stronger baselines.
- [§5, Figures] Figure captions and axis labels in the analysis plots could be expanded to explicitly name the ablated conditions and metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the experimental reporting, ablation controls, and reproducibility of the two-tiered repair mechanism.
read point-by-point responses
-
Referee: [§4, Table 1] §4 (Experiments) and Table 1: The headline 65.4% result on Spider2-Snow is presented without error bars, multiple runs, or statistical tests, and the paper does not explicitly state whether baseline reproductions (gpt-o3, DeepSeek-R1) used identical prompt templates, temperature, or the same two-tiered repair loop; this directly undermines the claim that gains are due to flexible exploration and execution.
Authors: We acknowledge the importance of rigorous statistical reporting for establishing the reliability of the 65.4% result. In the revised manuscript, we will report results from multiple independent runs (with standard deviations) and include statistical significance tests comparing FlexSQL against the baselines. We will also explicitly document the prompt templates, temperature settings, and repair configurations used for all baseline reproductions to ensure fair comparison. These additions will better support attribution of gains to the flexible exploration and execution components. revision: yes
-
Referee: [§5] §5 (Analysis): The ablation claiming that 'flexible exploration and flexible execution jointly contribute' does not confirm that ablated variants held all other components (model, prompt structure, plan diversity generation, and repair tiers) fixed; without this, the attribution to the core design principle cannot be isolated.
Authors: We agree that the ablation study must more rigorously isolate the contributions of flexible exploration and execution. In the revised manuscript, we will expand Section 5 with an explicit statement and supplementary table confirming that the model, prompt structure, plan diversity generation, and repair tiers were held fixed across all ablated variants. This will provide clearer evidence that the observed joint benefits stem from the flexibility mechanisms. revision: yes
-
Referee: [§3.3] §3.3 (Two-tiered repair): The mechanism for backtracking from code-level errors to plan-level revisions is described at a high level but lacks pseudocode, exact decision criteria, or implementation details sufficient for reproduction, which is load-bearing for the claimed recovery from early mistakes.
Authors: We recognize that additional implementation details are needed for full reproducibility of the two-tiered repair. In the revised manuscript, we will include pseudocode (as a new algorithm box in Section 3.3) that specifies the exact decision criteria for detecting code-level errors, the conditions for backtracking to plan-level revisions, and how state is maintained during the process. This will make the backtracking mechanism fully transparent and reproducible. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivation chain
full rationale
The paper describes an empirical text-to-SQL agent system (FlexSQL) whose core claims rest on benchmark results (65.4% on Spider2-Snow) and ablation studies rather than any mathematical derivation, equations, or theoretical reduction. No step claims that a prediction or result is derived from first principles that loop back to the same fitted quantities, self-citations, or ansatzes; comparisons to baselines are presented as experimental outcomes, not forced by construction. The work is self-contained as standard ML experimentation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark accuracy on Spider2-Snow reflects practical text-to-SQL capability
invented entities (1)
-
FlexSQL agent design
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc Le and Ed Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , booktitle=
-
[2]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[3]
Minghang Deng and Ashwin Ramachandran and Canwen Xu and Lanxiang Hu and Zhewei Yao and Anupam Datta and Hao Zhang , booktitle=. ReFo. 2025 , url=
2025
-
[4]
Transactions on Machine Learning Research , year =
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author =. Transactions on Machine Learning Research , year =
-
[5]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[6]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[7]
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-
Fangyu Lei and Jixuan Chen and Yuxiao Ye and Ruisheng Cao and Dongchan Shin and Hongjin SU and ZHAOQING SUO and Hongcheng Gao and Wenjing Hu and Pengcheng Yin and Victor Zhong and Caiming Xiong and Ruoxi Sun and Qian Liu and Sida Wang and Tao Yu , booktitle=. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-
-
[8]
Proceedings of the 2018 conference on empirical methods in natural language processing , year=
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , year=
2018
-
[9]
Can LLM already serve as A database interface , author=. A big bench for large-scale database grounded text-to-sqls. CoRR, abs/2305.03111 , year=
-
[10]
SpotIt: Evaluating Text-to-
Rocky Klopfenstein and Yang He and Andrew Tremante and Yuepeng Wang and Nina Narodytska and Haoze Wu , booktitle=. SpotIt: Evaluating Text-to-
-
[11]
2025 , publisher =
Yang, Yicun and Wang, Zhaoguo and Xia, Yu and Wei, Zhuoran and Ding, Haoran and Piskac, Ruzica and Chen, Haibo and Li, Jinyang , title =. 2025 , publisher =
2025
-
[12]
Understanding the Effects of Noise in Text-to- SQL : An Examination of the BIRD -Bench Benchmark
Wretblad, Niklas and Riseby, Fredrik and Biswas, Rahul and Ahmadi, Amin and Holmstr. Understanding the Effects of Noise in Text-to- SQL : An Examination of the BIRD -Bench Benchmark. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2024
2024
-
[13]
Nan Huo and Xiaohan Xu and Jinyang Li and Per Jacobsson and Shipei Lin and Bowen Qin and Binyuan Hui and Xiaolong Li and Ge Qu and Shuzheng Si and Linheng Han and Edward Alexander and Xintong Zhu and Rui Qin and Ruihan Yu and Yiyao Jin and Feige Zhou and Weihao Zhong and Yun Chen and Hongyu Liu and Chenhao Ma and Fatma Ozcan and Yannis Papakonstantinou an...
-
[14]
Mohammadreza Pourreza and Hailong Li and Ruoxi Sun and Yeounoh Chung and Shayan Talaei and Gaurav Tarlok Kakkar and Yu Gan and Amin Saberi and Fatma Ozcan and Sercan O Arik , booktitle=
-
[15]
Pi- SQL : Enhancing Text-to- SQL with Fine-Grained Guidance from Pivot Programming Languages
Chi, Yongdong and Wang, Hanqing and Chen, Yun and Yang, Yan and Yang, Jian and Yang, Zonghan and Yan, Xiao and Chen, Guanhua. Pi- SQL : Enhancing Text-to- SQL with Fine-Grained Guidance from Pivot Programming Languages. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025
2025
-
[16]
CoRR , volume =
Dawei Gao and Haibin Wang and Yaliang Li and Xiuyu Sun and Yichen Qian and Bolin Ding and Jingren Zhou , title =. CoRR , volume =
-
[17]
Din-sql: Decomposed in-context learning of text-to-sql with self-correction
DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction , author=. arXiv preprint arXiv:2304.11015 , year=
-
[18]
2025 , journal =
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale , author =. 2025 , journal =
2025
-
[19]
Verbalized sampling: How to mitigate mode collapse and unlock llm diversity , author=. arXiv preprint arXiv:2510.01171 , year=
-
[20]
arXiv preprint arXiv:2511.21402 , year=
Text-to-SQL as Dual-State Reasoning: Integrating Adaptive Context and Progressive Generation , author=. arXiv preprint arXiv:2511.21402 , year=
-
[21]
Evaluating Cross-Domain Text-to- SQL Models and Benchmarks
Pourreza, Mohammadreza and Rafiei, Davood. Evaluating Cross-Domain Text-to- SQL Models and Benchmarks. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[22]
Tang, Lappoon R. and Mooney, Raymond J. Automated Construction of Database Interfaces: Intergrating Statistical and Relational Learning for Semantic Parsing. 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora. 2000. doi:10.3115/1117794.1117811
-
[23]
IEEE Transactions on Knowledge and Data Engineering , year=
Xiyan-sql: A novel multi-generator framework for text-to-sql , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[24]
and Mooney, Raymond J
Zelle, John M. and Mooney, Raymond J. , title =. Proceedings of the Thirteenth National Conference on Artificial Intelligence - Volume 2 , pages =. 1996 , isbn =
1996
-
[25]
DeepEye-SQL: A Software-Engineering-Inspired Text-to-SQL Framework
DeepEye-SQL: A software-engineering-inspired text-to-sql framework , author=. arXiv preprint arXiv:2510.17586 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
CSC - SQL : Corrective Self-Consistency in Text-to- SQL via Reinforcement Learning
Sheng, Lei and Shuai, Xu Shuai. CSC - SQL : Corrective Self-Consistency in Text-to- SQL via Reinforcement Learning. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 2025. doi:10.18653/v1/2025.findings-ijcnlp.91
-
[27]
Li, Haoyang and Zhang, Jing and Liu, Hanbing and Fan, Ju and Zhang, Xiaokang and Zhu, Jun and Wei, Renjie and Pan, Hongyan and Li, Cuiping and Chen, Hong , title =. Proc. ACM Manag. Data , month = may, articleno =. 2024 , issue_date =. doi:10.1145/3654930 , abstract =
-
[28]
Advances in Neural Information Processing Systems , volume=
Capturing failures of large language models via human cognitive biases , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review arXiv
-
[30]
IEEE Transactions on Knowledge and Data Engineering , year=
A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going? , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[31]
Next-Generation Database Interfaces: A Survey of LLM-Based Text-to-SQL , year=
Hong, Zijin and Yuan, Zheng and Zhang, Qinggang and Chen, Hao and Dong, Junnan and Huang, Feiran and Huang, Xiao , journal=. Next-Generation Database Interfaces: A Survey of LLM-Based Text-to-SQL , year=
-
[32]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[33]
Os-copilot: Towards generalist computer agents with self-improvement
Os-copilot: Towards generalist computer agents with self-improvement , author=. arXiv preprint arXiv:2402.07456 , year=
-
[34]
Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[35]
2024 , url=
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=. 2024 , url=
2024
-
[36]
Transactions on Machine Learning Research , issn=
Cognitive Architectures for Language Agents , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[37]
Using Planning to Improve Semantic Parsing of Instructional Texts
Cohen, Vanya and Mooney, Raymond. Using Planning to Improve Semantic Parsing of Instructional Texts. Proceedings of the 1st Workshop on Natural Language Reasoning and Structured Explanations (NLRSE). 2023. doi:10.18653/v1/2023.nlrse-1.5
-
[38]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Wang, Lei and Xu, Wanyu and Lan, Yihuai and Hu, Zhiqiang and Lan, Yunshi and Lee, Roy Ka-Wei and Lim, Ee-Peng. Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.147
-
[39]
MAC - SQL : A Multi-Agent Collaborative Framework for Text-to- SQL
Wang, Bing and Ren, Changyu and Yang, Jian and Liang, Xinnian and Bai, Jiaqi and Chai, LinZheng and Yan, Zhao and Zhang, Qian-Wen and Yin, Di and Sun, Xing and Li, Zhoujun. MAC - SQL : A Multi-Agent Collaborative Framework for Text-to- SQL. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[40]
Boyan Li and Jiayi Zhang and Ju Fan and Yanwei Xu and Chong Chen and Nan Tang and Yuyu Luo , booktitle=. Alpha-. 2025 , url=
2025
-
[41]
Chess: Contextual harnessing for efficient sql synthesis,
Chess: Contextual harnessing for efficient sql synthesis , author=. arXiv preprint arXiv:2405.16755 , year=
-
[42]
MCS - SQL : Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to- SQL Generation
Lee, Dongjun and Park, Choongwon and Kim, Jaehyuk and Park, Heesoo. MCS - SQL : Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to- SQL Generation. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[43]
Towards Complex Text-to- SQL in Cross-Domain Database with Intermediate Representation
Guo, Jiaqi and Zhan, Zecheng and Gao, Yan and Xiao, Yan and Lou, Jian-Guang and Liu, Ting and Zhang, Dongmei. Towards Complex Text-to- SQL in Cross-Domain Database with Intermediate Representation. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1444
-
[44]
Text-to- SQL Error Correction with Language Models of Code
Chen, Ziru and Chen, Shijie and White, Michael and Mooney, Raymond and Payani, Ali and Srinivasa, Jayanth and Su, Yu and Sun, Huan. Text-to- SQL Error Correction with Language Models of Code. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.117
-
[45]
LETI : Learning to Generate from Textual Interactions
Wang, Xingyao and Peng, Hao and Jabbarvand, Reyhaneh and Ji, Heng. LETI : Learning to Generate from Textual Interactions. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.16
-
[46]
and Drake, John and Zhang, Qiaofu
Gan, Yujian and Chen, Xinyun and Xie, Jinxia and Purver, Matthew and Woodward, John R. and Drake, John and Zhang, Qiaofu. Natural SQL : Making SQL Easier to Infer from Natural Language Specifications. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.174
-
[47]
and Cheung, Alvin , title =
Bhatia, Sahil and Qiu, Jie and Hasabnis, Niranjan and Seshia, Sanjit A. and Cheung, Alvin , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[48]
and Adams, Bram , title =
Macedo, Marcos and Tian, Yuan and Nie, Pengyu and Cogo, Filipe R. and Adams, Bram , title =. Proceedings of the IEEE/ACM 47th International Conference on Software Engineering , pages =. 2025 , isbn =
2025
-
[49]
IRC oder: Intermediate representations make language models robust multilingual code generators
Paul, Indraneil and Glava s , Goran and Gurevych, Iryna. IRC oder: Intermediate Representations Make Language Models Robust Multilingual Code Generators. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.802
-
[50]
The Eleventh International Conference on Learning Representations , year=
Code Translation with Compiler Representations , author=. The Eleventh International Conference on Learning Representations , year=
-
[51]
2004 , isbn =
Lattner, Chris and Adve, Vikram , title =. 2004 , isbn =
2004
-
[52]
Li, Fei and Jagadish, H. V. , title =. Proc. VLDB Endow. , month = sep, pages =. 2014 , issue_date =. doi:10.14778/2735461.2735468 , abstract =
-
[53]
RAT-SQL : Relation-Aware Schema Encoding and Linking for Text-to- SQL Parsers
Wang, Bailin and Shin, Richard and Liu, Xiaodong and Polozov, Oleksandr and Richardson, Matthew. RAT-SQL : Relation-Aware Schema Encoding and Linking for Text-to- SQL Parsers. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.677
-
[54]
Wang, Chenglong and Cheung, Alvin and Bodik, Rastislav , title =. Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation , pages =. 2017 , isbn =. doi:10.1145/3062341.3062365 , abstract =
-
[55]
Wang, Chenglong and Cheung, Alvin and Bodik, Rastislav , title =. SIGPLAN Not. , month = jun, pages =. 2017 , issue_date =. doi:10.1145/3140587.3062365 , abstract =
-
[56]
Yaghmazadeh, Navid and Wang, Yuepeng and Dillig, Isil and Dillig, Thomas , title =. Proc. ACM Program. Lang. , month = oct, articleno =. 2017 , issue_date =. doi:10.1145/3133887 , abstract =
-
[57]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[58]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Inner Monologue: Embodied Reasoning through Planning with Language Models , author=. arXiv preprint arXiv:2207.05608 , year=
work page internal anchor Pith review arXiv
-
[59]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[60]
Experiential reinforcement learning.arXiv preprint arXiv:2602.13949, 2026
Experiential reinforcement learning , author=. arXiv preprint arXiv:2602.13949 , year=
-
[61]
Expanding the Capabilities of Reinforcement Learning via Text Feedback , author=. arXiv preprint arXiv:2602.02482 , year=
-
[62]
Arik, Hootan Nakhost, Hanjun Dai, Rajarishi Sinha, Pengcheng Yin, and Tomas Pfister
Sql-palm: Improved large language model adaptation for text-to-sql (extended) , author=. arXiv preprint arXiv:2306.00739 , year=
-
[63]
2024 , journal =
Qwen2.5 Technical Report , author =. 2024 , journal =
2024
-
[64]
International conference on computers and games , pages=
Efficient selectivity and backup operators in Monte-Carlo tree search , author=. International conference on computers and games , pages=. 2006 , organization=
2006
-
[65]
A Study of LLMs' Preferences for Libraries and Programming Languages
A Study of LLMs' Preferences for Libraries and Programming Languages , author=. arXiv preprint arXiv:2503.17181 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
2026 , url =
Claude Code , version =. 2026 , url =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.