Recognition: 3 theorem links
· Lean TheoremTrust, but Verify: Peeling Low-Bit Transformer Networks for Training Monitoring
Pith reviewed 2026-05-08 19:30 UTC · model grok-4.3
The pith
Layer-wise local optimization produces reference bounds that often match or exceed full transformer performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
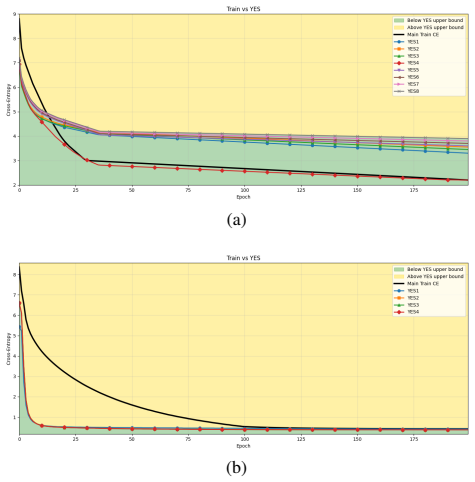
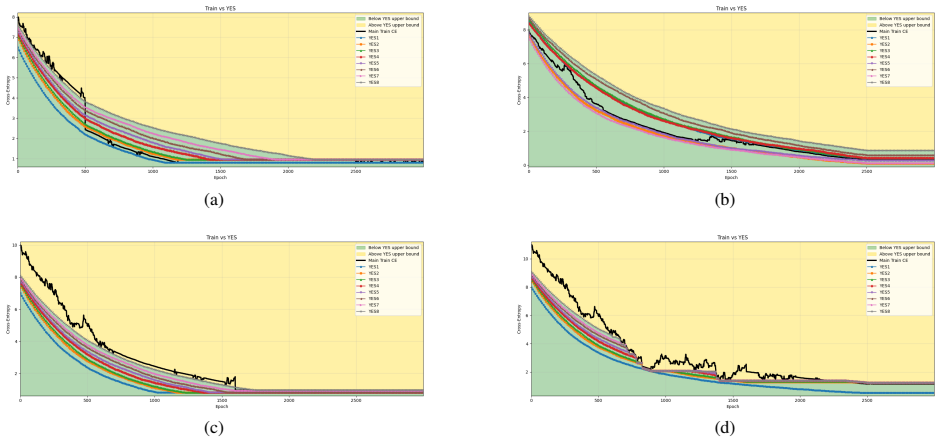
By locally optimizing each transformer layer against the intermediate representations produced by the trained model and projecting via different permutations, the authors obtain layer-specific reference bounds whose performance can equal or exceed that of the full end-to-end trained network at multiple stages of training. These bounds remain effective under binarization and quantization, thereby separating apparent convergence from effective layer-wise optimality in a way that aggregate loss metrics cannot.
What carries the argument
The layer-wise peeling framework, which locally optimizes each transformer layer against the trained model's intermediate representations to construct achievable reference baselines.
If this is right
- Standard training loss curves alone cannot confirm that every layer has reached effective optimality.
- The same layer-wise bounds remain informative for binarized and quantized transformer models where training is especially fragile.
- Inefficiencies can be diagnosed at arbitrary points during training rather than only at the end.
- Reference bounds that surpass the trained model indicate concrete optimization opportunities invisible to aggregate metrics.
Where Pith is reading between the lines
- The bounds could be used to decide when to stop training individual layers rather than the whole network.
- Targeted fine-tuning or replacement of only the under-performing layers might improve efficiency without full retraining.
- The approach might extend to encoder-decoder or non-transformer architectures to identify similar layer-specific gaps.
- In low-bit deployment, the method could flag layers that need higher precision to avoid silent performance degradation.
Load-bearing premise
Locally optimizing each layer to match the trained model's intermediate representations produces valid achievable baselines that diagnose the quality of full end-to-end training.
What would settle it
If the locally optimized layer bounds consistently underperform the full trained model on held-out data at late training stages across multiple decoder-only models and datasets, the claim that they expose hidden inefficiencies would not hold.
Figures


read the original abstract
Understanding whether deep neural networks are effectively optimized remains challenging, as training occurs in highly nonconvex landscapes and standard metrics provide limited visibility into layer-wise learning quality. This challenge is particularly acute for transformer-based language models, where training is expensive, models are often reused in frozen form, and poorly optimized layers can silently degrade performance. We propose a layer-wise peeling framework for monitoring training dynamics, in which each transformer layer is locally optimized against intermediate representations of the trained model. By constructing lightweight, layer-specific reference solutions and projecting layers onto multiple intermediate outputs via different permutations, we obtain achievable baselines that enable fine-grained diagnosis of under-optimized layers. Experiments on decoder-only transformer models show that these layer-wise reference bounds can match or even surpass the trained model at various stages of training, exposing inefficiencies that remain hidden in aggregate loss curves. We further demonstrate that this analysis remains effective under binarization and quantized settings, where training dynamics are particularly fragile. Across all numerical results, the proposed bounds consistently separate apparent convergence from effective optimality, highlighting optimization opportunities that are invisible when relying on training loss alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a layer-wise 'peeling' framework to monitor training dynamics in transformer networks. Each layer is locally optimized against the trained model's intermediate representations to produce lightweight reference bounds; these bounds are claimed to diagnose under-optimized layers by matching or exceeding the trained model's layer outputs at various training stages. Experiments on decoder-only transformers show the bounds can match or surpass the trained model, revealing inefficiencies invisible in aggregate loss curves, with the approach remaining effective under binarization and quantization.
Significance. If the local reference bounds are validated as achievable within the full end-to-end network, the method would offer a practical diagnostic tool for layer-wise optimization quality in large language models, especially low-bit variants where training is fragile. It could help distinguish apparent convergence from true optimality, addressing a gap in current training monitoring practices.
major comments (3)
- [Experiments section] The central experimental claim (abstract and Experiments section) that layer-wise reference bounds 'can match or even surpass the trained model' is load-bearing for the diagnosis of hidden inefficiencies, yet the manuscript provides no results on re-inserting the locally optimized layers back into the original network and measuring global performance. Without this verification, local gains may reflect ignored inter-layer error propagation rather than under-optimization in the original training.
- [§3 (Method)] §3 (Method): The construction of reference bounds via local optimization against fixed intermediate representations assumes these solutions remain realizable in the coupled network. The paper does not report any ablation or forward-pass evaluation confirming that substituting optimized layers preserves downstream compatibility, which directly undermines the claim that the bounds expose training deficiencies rather than optimization artifacts.
- [Quantization experiments] Quantization experiments (abstract): While the abstract asserts effectiveness under binarization and low-bit settings, no controls are described for how quantization interacts with the local optimization objective or whether the reference bounds remain valid when the entire network (including non-peeled layers) is quantized. This is necessary to support the claim that the framework diagnoses fragile training dynamics.
minor comments (2)
- [Abstract and §3] The abstract and method description use 'projecting layers onto multiple intermediate outputs via different permutations' without defining the permutation selection procedure or its coverage of inter-layer dependencies; a brief clarification or pseudocode would improve reproducibility.
- [Figures and Tables] Figure captions and experimental tables (if present) should explicitly state the number of random seeds, statistical significance tests, and exact local optimization hyperparameters to allow readers to assess variability in the reported bound comparisons.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our work. Below, we address each major comment in detail, providing clarifications on the scope and design of our layer-wise peeling framework.
read point-by-point responses
-
Referee: [Experiments section] The central experimental claim (abstract and Experiments section) that layer-wise reference bounds 'can match or even surpass the trained model' is load-bearing for the diagnosis of hidden inefficiencies, yet the manuscript provides no results on re-inserting the locally optimized layers back into the original network and measuring global performance. Without this verification, local gains may reflect ignored inter-layer error propagation rather than under-optimization in the original training.
Authors: We thank the referee for this observation. Our peeling framework is specifically designed to generate layer-specific reference bounds by optimizing each layer locally against the fixed intermediate representations from the trained model. The key finding that these bounds can match or surpass the trained model's layer outputs highlights that the original training did not reach the locally optimal solution for those layers. This local comparison directly exposes under-optimization without needing to account for inter-layer dynamics in the diagnostic phase, as the intermediates are held fixed from the trained network. Re-integrating the optimized layers would necessitate a full retraining cycle, which defeats the purpose of a lightweight monitoring tool. We believe this local verification is sufficient and valid for diagnosing inefficiencies invisible in aggregate metrics. revision: no
-
Referee: [§3 (Method)] §3 (Method): The construction of reference bounds via local optimization against fixed intermediate representations assumes these solutions remain realizable in the coupled network. The paper does not report any ablation or forward-pass evaluation confirming that substituting optimized layers preserves downstream compatibility, which directly undermines the claim that the bounds expose training deficiencies rather than optimization artifacts.
Authors: We clarify that our method does not assume or claim that the locally optimized layers can be directly substituted into the coupled network while preserving all downstream behaviors without adjustment. The reference bounds are computed to provide an achievable performance ceiling for each layer in isolation, using the trained model's intermediates as anchors. This isolates the optimization quality of individual layers. If a local solution surpasses the original, it indicates a deficiency in how that layer was trained, regardless of immediate compatibility. We did not perform substitution ablations because the framework's value lies in its diagnostic capability rather than as a drop-in replacement. This distinction is important for understanding the paper's contributions. revision: no
-
Referee: [Quantization experiments] Quantization experiments (abstract): While the abstract asserts effectiveness under binarization and low-bit settings, no controls are described for how quantization interacts with the local optimization objective or whether the reference bounds remain valid when the entire network (including non-peeled layers) is quantized. This is necessary to support the claim that the framework diagnoses fragile training dynamics.
Authors: Our quantization and binarization experiments apply the full peeling framework to networks that are entirely in low-bit or binary precision. The local optimization is carried out respecting the quantization constraints, and the resulting bounds continue to provide meaningful diagnostics. We focused on fully quantized settings to address the fragility of training in such regimes, without partial quantization controls, as mixing precisions would not reflect the practical low-bit scenarios we target. The consistent results across these experiments support the framework's utility in diagnosing training dynamics under quantization. revision: no
Circularity Check
No significant circularity; method proposes independent local baselines
full rationale
The paper's core contribution is a layer-wise peeling procedure that locally optimizes each transformer layer to match or exceed the trained model's intermediate activations, then uses these as reference bounds for diagnosis. This construction is defined directly from the optimization objective against fixed trained intermediates and does not reduce to a self-referential fit, renamed empirical pattern, or load-bearing self-citation. No equations or steps in the provided description equate a claimed prediction or uniqueness result back to the inputs by definition. The framework remains self-contained against external benchmarks such as the original training loss curves.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Cost.Jcostwashburn_uniqueness_aczel unclearminimize over [W_K]_{i,j} ∈ {−λ, λ} ‖Y − W_K Y*_K‖_F^2 ... cW_K = λ sign(Y Y*†_K)
Reference graph
Works this paper leans on
-
[1]
Deep learning.nature, 521(7553):436–444, 2015
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.nature, 521(7553):436–444, 2015
2015
-
[2]
MIT press Cambridge, 2016
Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio.Deep learning, volume 1. MIT press Cambridge, 2016
2016
-
[3]
Megha Srivastava, Simran Arora, and Dan Boneh. Optimistic verifiable training by controlling hardware nondeterminism.arXiv preprint arXiv:2403.09603, 2024
-
[4]
The loss surfaces of multilayer networks
Anna Choromanska, Mikael Henaff, Michael Mathieu, Gérard Ben Arous, and Yann LeCun. The loss surfaces of multilayer networks. InArtificial intelligence and statistics, pages 192–204. PMLR, 2015
2015
-
[5]
Identifying and attacking the saddle point problem in high-dimensional non-convex optimization.Advances in neural information processing systems, 27, 2014
Yann N Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization.Advances in neural information processing systems, 27, 2014
2014
-
[6]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization (2016).arXiv preprint arXiv:1611.03530, 2017
work page internal anchor Pith review arXiv 2016
-
[7]
Behnam Neyshabur, Ryota Tomioka, Ruslan Salakhutdinov, and Nathan Srebro. Geometry of optimization and implicit regularization in deep learning.arXiv preprint arXiv:1705.03071, 2017. 10
-
[8]
Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer.arXiv preprint arXiv:2102.01293, 2021
-
[9]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review arXiv 2022
-
[10]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[12]
LoRA: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. LoRA: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[13]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
2019
-
[14]
Beyond chinchilla-optimal: Accounting for inference in language model scaling laws
Nikhil Sardana, Jacob Portes, Sasha Doubov, and Jonathan Frankle. Beyond chinchilla-optimal: Accounting for inference in language model scaling laws.arXiv preprint arXiv:2401.00448, 2023
-
[15]
Adam Roberts, Colin Raffel, and Noam Shazeer. How much knowledge can you pack into the parameters of a language model?arXiv preprint arXiv:2002.08910, 2020
-
[16]
Optimization methods for large-scale machine learning.SIAM review, 60(2):223–311, 2018
Léon Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning.SIAM review, 60(2):223–311, 2018
2018
-
[17]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review arXiv 2017
-
[18]
Generalization bounds for stochastic gradient descent via localized covers.Advances in Neural Information Processing Systems, 35:2790–2802, 2022
Sejun Park, Umut Simsekli, and Murat A Erdogdu. Generalization bounds for stochastic gradient descent via localized covers.Advances in Neural Information Processing Systems, 35:2790–2802, 2022
2022
-
[19]
Closing the convergence gap of SGD without replacement
Shashank Rajput, Anant Gupta, and Dimitris Papailiopoulos. Closing the convergence gap of SGD without replacement. InInternational Conference on Machine Learning, pages 7964–7973. PMLR, 2020
2020
-
[20]
On convergence-diagnostic based step sizes for stochastic gradient descent
Scott Pesme, Aymeric Dieuleveut, and Nicolas Flammarion. On convergence-diagnostic based step sizes for stochastic gradient descent. InInternational conference on machine learning, pages 7641–7651. PMLR, 2020
2020
-
[21]
A convergence theory for deep learning via over-parameterization
Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. InInternational conference on machine learning, pages 242–252. PMLR, 2019
2019
-
[22]
Data-aware training quality monitoring and certification for deep learning
Farhang Yeganegi, Arian Eamaz, and Mojtaba Soltanalian. Data-aware training quality monitoring and certification for deep learning. InOPT 2025: Optimization for Machine Learning
2025
-
[23]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
work page Pith review arXiv 2016
-
[24]
Insights on representational similarity in neural networks with canonical correlation.Advances in neural information processing systems, 31, 2018
Ari Morcos, Maithra Raghu, and Samy Bengio. Insights on representational similarity in neural networks with canonical correlation.Advances in neural information processing systems, 31, 2018
2018
-
[25]
Openllama: An open reproduction of llama, May 2023
Xinyang Geng and Hao Liu. Openllama: An open reproduction of llama, May 2023
2023
-
[26]
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit LLMs: All large language models are in 1.58 bits.arXiv preprint arXiv:2402.17764, 2024. 11 A Toy Example: MNIST Dataset Toy experiment: MNISTWe begin with a simple toy experiment on the MNIST dataset to demonstrate ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.