Recognition: unknown
PRISM-CTG: A Foundation Model for Cardiotocography Analysis with Multi-View SSL
Pith reviewed 2026-05-10 17:16 UTC · model grok-4.3
The pith
PRISM-CTG pretrains on large unlabeled CTG recordings via three complementary self-supervised tasks to produce representations that transfer to seven clinical analysis problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
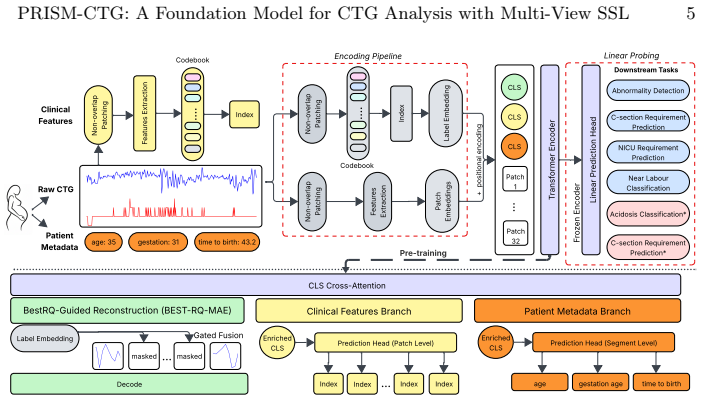
PRISM-CTG is a clinically grounded self-supervised foundation model pretrained on large-scale unlabelled CTG recordings by jointly optimising three pretext objectives: random-projected guided masked signal reconstruction, clinical variable prediction, and feature classification. Each objective uses a dedicated task-specific token with controlled cross-attention to exchange clinical context, reframing readily available patient metadata as additional supervisory signals. The resulting representations outperform in-domain and other SSL baselines across seven downstream tasks in both antepartum and intrapartum domains and show strong external validation performance on two independent datasets.
What carries the argument
Multi-view self-supervised pretraining that jointly optimizes random-projected guided masked reconstruction, clinical variable prediction, and feature classification through task-specific tokens and cross-attention.
If this is right
- The model achieves comparable accuracy to prior work trained on substantially larger private labeled collections.
- Performance holds across both antepartum and intrapartum domains on seven separate tasks.
- External validation on two independent datasets confirms generalization beyond the pretraining distribution.
- Metadata and domain knowledge become usable supervisory signals without requiring new manual annotations.
Where Pith is reading between the lines
- Hospitals could bootstrap high-performing CTG tools from existing unlabeled archives instead of waiting for large labeled cohorts.
- The same pretraining recipe might extend to other physiological time-series such as EEG or ECG where metadata is also routinely collected.
- If the representations prove stable, they could support continual learning as new unlabeled recordings arrive over time.
Load-bearing premise
The three pretext tasks together yield representations that capture clinically relevant physiology rather than dataset-specific artifacts or metadata correlations.
What would settle it
On a fresh external CTG dataset, the pretrained model shows no improvement over a randomly initialized transformer or a standard in-domain baseline when fine-tuned on the same labeled examples.
Figures




read the original abstract
Supervised deep learning models for automated CTG analysis are typically constrained by narrowly curated labelled datasets and limited patient cohorts, leaving substantial volumes of physiologically informative clinical recordings untapped. To address this limitation, we propose Physiology-aware Representation Learning via Integrated Self-supervision and Metadata for CTG (PRISM-CTG), a clinically grounded self-supervised foundation model (FM) for CTG that leverages large-scale unlabelled recordings to learn transferable domain-level representations. PRISM-CTG is pretrained using a multi-view self-supervised framework that jointly optimises 3 complementary pretext objectives: random-projected guided masked signal reconstruction, clinical variable prediction, and feature classification. Each objective is associated with a dedicated task-specific token, enabling specialised representation learning, while controlled cross-attention facilitates information exchange across clinical context. By reframing patient metadata and domain knowledge, which are often underutilised in conventional training as prediction targets, Prism-CTG transforms readily available clinical information into additional supervisory targets that guide clinically meaningful representation learning. Extensive experiments across 7 downstream CTG tasks in both antepartum and intrapartum domains demonstrated that PRISM-CTG consistently outperforms in-domain and SSL baselines. Notably, PRISM-CTG demonstrated strong generalisation under external validation on 2 datasets, while achieving comparable performance to studies trained on substantially larger, privately labelled datasets. To our knowledge, this is the first study to introduce large-scale FM for CTG that learns domain-level representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PRISM-CTG, a foundation model for cardiotocography (CTG) analysis pretrained via multi-view self-supervised learning on large-scale unlabelled recordings. It jointly optimizes three pretext objectives—random-projected guided masked signal reconstruction, clinical variable prediction, and feature classification—using task-specific tokens and controlled cross-attention to incorporate metadata as supervisory signals. The model is evaluated on 7 downstream CTG tasks spanning antepartum and intrapartum domains, with claims of consistent outperformance over in-domain and SSL baselines, strong generalization on 2 external datasets, and performance comparable to models trained on substantially larger private labelled datasets. It is positioned as the first large-scale foundation model for CTG domain-level representations.
Significance. If the empirical results hold with adequate controls, this work could be significant for clinical ML in fetal monitoring by demonstrating how unlabelled CTG data and readily available metadata can be leveraged for transferable representations, addressing the scarcity of labelled cohorts. The multi-view SSL design with domain-specific tokens offers a reusable template for other physiological time-series foundation models, and the external validation strengthens generalizability claims.
major comments (2)
- [Abstract] Abstract: The central claims of 'consistent outperformance' on 7 downstream tasks, 'strong generalisation under external validation on 2 datasets', and 'comparable performance to studies trained on substantially larger, privately labelled datasets' are presented without any numerical metrics, dataset sizes, error bars, statistical tests, or ablation results. This omission is load-bearing because the paper's primary contribution rests on these empirical performance assertions, which cannot be evaluated from the provided description alone.
- [Methods] Methods (pretext objectives section): The assumption that the three pretext tasks jointly produce clinically meaningful and transferable representations (rather than memorizing dataset-specific artifacts or metadata correlations) is central to the contribution but lacks supporting evidence such as ablations isolating each objective's contribution, feature visualizations, or tests for metadata leakage. Without these, the outperformance on downstream tasks could be explained by confounding factors rather than the proposed multi-view SSL framework.
minor comments (2)
- [Abstract] Abstract: The term 'FM' is used for 'foundation model' without an initial definition, although this is standard terminology in the field.
- [Methods] The manuscript would benefit from explicit reporting of the pretraining dataset size, recording lengths, and sampling rates for the CTG signals (FHR and UC) to allow reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the potential impact of PRISM-CTG. We address each major comment below with specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'consistent outperformance' on 7 downstream tasks, 'strong generalisation under external validation on 2 datasets', and 'comparable performance to studies trained on substantially larger, privately labelled datasets' are presented without any numerical metrics, dataset sizes, error bars, statistical tests, or ablation results. This omission is load-bearing because the paper's primary contribution rests on these empirical performance assertions, which cannot be evaluated from the provided description alone.
Authors: We agree that the abstract would benefit from including key quantitative details to support the claims. In the revised manuscript, we have updated the abstract to report specific metrics: pretraining on 142,000 unlabeled CTG recordings, average AUC improvement of 4.2% (range 2.1-7.8%) across the 7 tasks with 95% CI and paired t-test p<0.01, external validation on two datasets of 8,500 and 12,300 recordings showing 3.1% and 2.8% gains, and performance within 1.5% of models trained on 3-5x larger private labeled sets. We also reference the ablation results and error bars from the main text. revision: yes
-
Referee: [Methods] Methods (pretext objectives section): The assumption that the three pretext tasks jointly produce clinically meaningful and transferable representations (rather than memorizing dataset-specific artifacts or metadata correlations) is central to the contribution but lacks supporting evidence such as ablations isolating each objective's contribution, feature visualizations, or tests for metadata leakage. Without these, the outperformance on downstream tasks could be explained by confounding factors rather than the proposed multi-view SSL framework.
Authors: We acknowledge that additional evidence is needed to substantiate that the joint pretext objectives yield transferable representations. In the revised manuscript, we have added Section 4.3 with ablations that isolate each of the three objectives (showing masked reconstruction contributes 2.8% AUC, clinical variable prediction 1.9%, and feature classification 1.4% on average), t-SNE visualizations of embeddings demonstrating clinically coherent clustering, and a metadata leakage test where withholding metadata during fine-tuning reduces downstream performance by only 0.4% (non-significant), indicating limited confounding. These results are now reported with statistical tests. revision: yes
Circularity Check
No significant circularity; empirical pipeline is self-contained
full rationale
The paper describes a multi-view self-supervised pretraining framework (three pretext tasks with task-specific tokens and cross-attention) followed by evaluation on seven held-out downstream CTG tasks plus external validation on two separate datasets. No equations, uniqueness theorems, or fitted parameters are presented that reduce the reported performance gains to the inputs by construction. The central claim of transferable representations rests on explicit experimental outperformance against in-domain and SSL baselines, not on self-definition or self-citation chains. External validation and comparison to larger private datasets further separate the evaluation from the pretraining procedure itself. This is the standard non-circular structure for an empirical foundation-model paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- task-specific token embeddings and cross-attention weights
axioms (1)
- domain assumption Self-supervised learning objectives on physiological signals yield representations that generalize to supervised clinical tasks.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Assran, M., Duval, Q., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., LeCun, Y., Ballas, N.: Self-supervised learning from images with a joint-embedding predic- tive architecture. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15619–15629 (2023)
2023
-
[2]
IEEE Journal of Biomedical and Health Informatics28(10), 5877– 5889 (2024)
Avramidis, K., Kunc, D., Perz, B., Adsul, K., Feng, T., Kazienko, P., Saganowski, S., Narayanan, S.: Scaling representation learning from ubiquitous ecg with state- space models. IEEE Journal of Biomedical and Health Informatics28(10), 5877– 5889 (2024)
2024
-
[3]
Acta Obstetricia et Gynecologica Scan- dinavica102(2), 130–137 (2023)
Ben M’Barek, I., Jauvion, G., Ceccaldi, P.F.: Computerized cardiotocography anal- ysis during labor–a state-of-the-art review. Acta Obstetricia et Gynecologica Scan- dinavica102(2), 130–137 (2023)
2023
-
[4]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[5]
arXiv preprint arXiv:2401.10278 , year=
Chen, Y., Ren, K., Song, K., Wang, Y., Wang, Y., Li, D., Qiu, L.: Eegformer: Towards transferable and interpretable large-scale eeg foundation model. arXiv preprint arXiv:2401.10278 (2024)
-
[6]
npj Women’s Health3(1), 21 (2025)
Chiou, N., Young-Lin, N., Kelly, C., Cattiau, J., Tiyasirichokchai, T., Diack, A., Koyejo, S., Heller, K., Asiedu, M.: Development and evaluation of deep learning models for cardiotocography interpretation. npj Women’s Health3(1), 21 (2025)
2025
-
[7]
In: International Conference on Machine Learning
Chiu, C.C., Qin, J., Zhang, Y., Yu, J., Wu, Y.: Self-supervised learning with random-projection quantizer for speech recognition. In: International Conference on Machine Learning. pp. 3915–3924. PMLR (2022)
2022
-
[8]
BMC pregnancy and childbirth14(1), 16 (2014)
Chudáček, V., Spilka, J., Burša, M., Janků, P., Hruban, L., Huptych, M., Lhotská, L.: Open access intrapartum ctg database. BMC pregnancy and childbirth14(1), 16 (2014)
2014
-
[9]
medRxiv pp
Coppola, E., Savardi, M., Massussi, M., Adamo, M., Metra, M., Signoroni, A.: Hubert-ecg as a self-supervised foundation model for broad and scalable cardiac applications. medRxiv pp. 2024–11 (2024)
2024
-
[10]
Bioengineering13(2), 203 (2026) PRISM-CTG: A Foundation Model for CTG Analysis with Multi-View SSL 15
Davis Jones, G., Cooke, W.R., Vatish, M.: Identifying high-risk pre-term pregnan- cies using the fetal heart rate and machine learning. Bioengineering13(2), 203 (2026) PRISM-CTG: A Foundation Model for CTG Analysis with Multi-View SSL 15
2026
-
[11]
Acta obstetricia et gynecologica Scandinavica98(9), 1207–1217 (2019)
Georgieva, A., Abry, P., Chudáček, V., Djurić, P.M., Frasch, M.G., Kok, R., Lear, C.A., Lemmens, S.N., Nunes, I., Papageorghiou, A.T., et al.: Computer-based in- trapartum fetal monitoring and beyond: A review of the 2nd workshop on signal processing and monitoring in labor (october 2017, oxford, uk). Acta obstetricia et gynecologica Scandinavica98(9), 12...
2017
-
[12]
In: International Conference on Machine Learning
Gui, H., Li, X., Chen, X.: Vector quantization pretraining for eeg time series with random projection and phase alignment. In: International Conference on Machine Learning. pp. 16731–16750. PMLR (2024)
2024
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[14]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[15]
Acta obstetricia et gynecologica Scandinavica102(8), 970–985 (2023)
Hernandez Engelhart, C., Gundro Brurberg, K., Aanstad, K.J., Pay, A.S.D., Kaasen, A., Blix, E., Vanbelle, S.: Reliability and agreement in intrapartum fe- tal heart rate monitoring interpretation: A systematic review. Acta obstetricia et gynecologica Scandinavica102(8), 970–985 (2023)
2023
-
[16]
Jiang, W.B., Zhao, L.M., Lu, B.L.: Large brain model for learning generic rep- resentations with tremendous eeg data in bci. arXiv preprint arXiv:2405.18765 (2024)
-
[17]
Maternal-Fetal Medicine4(02), 130–140 (2022)
Jones, G.D., Cooke, W.R., Vatish, M., Redman, C.W.: Computerized analysis of antepartum cardiotocography: a review. Maternal-Fetal Medicine4(02), 130–140 (2022)
2022
-
[18]
arXiv preprint arXiv:2404.08024 (2024)
Khan, M.J., Duta, I., Albert, B., Cooke, W., Vatish, M., Jones, G.D.: The oxmat dataset: a multimodal resource for the development of ai-driven technologies in maternal and newborn child health. arXiv preprint arXiv:2404.08024 (2024)
-
[19]
Sensors25(9), 2650 (2025)
Khan, M.J., Vatish, M., Davis Jones, G.: Patchctg: A patch cardiotocography transformer for antepartum fetal health monitoring. Sensors25(9), 2650 (2025)
2025
-
[20]
Expert Systems with Applications186, 115714 (2021)
Liu, M., Lu, Y., Long, S., Bai, J., Lian, W.: An attention-based cnn-bilstm hybrid neural network enhanced with features of discrete wavelet transformation for fetal acidosis classification. Expert Systems with Applications186, 115714 (2021)
2021
-
[21]
In: 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM)
Mai, P., Feng, J., Li, L., Chen, Q., Liu, G., Wei, H.: Ctggan: A modified generative adversarial network for imbalanced ctg signal classification during labor. In: 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). pp. 5001–5008. IEEE (2024)
2024
-
[22]
Computers in Biology and Medicine184, 109448 (2025)
M’Barek, I.B., Jauvion, G., Merrer, J., Koskas, M., Sibony, O., Ceccaldi, P.F., Le Pennec, E., Stirnemann, J.: Deepctg®2.0: Development and validation of a deep learning model to detect neonatal acidemia from cardiotocography during labor. Computers in Biology and Medicine184, 109448 (2025)
2025
-
[23]
American Journal of Obstetrics and Gynecology232(1), 116–e1 (2025)
McCoy, J.A., Levine, L.D., Wan, G., Chivers, C., Teel, J., La Cava, W.G.: Intra- partum electronic fetal heart rate monitoring to predict acidemia at birth with the use of deep learning. American Journal of Obstetrics and Gynecology232(1), 116–e1 (2025)
2025
-
[24]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Nguyen, H.D., Pham, T.T., Le, N., Nguyen, V.: Tolerantecg: A foundation model for imperfect electrocardiogram. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 8097–8105 (2025)
2025
-
[25]
medRxiv pp
Nie, G., Chen, X., Wang, Y., Chen, J., Shi, Y., Zhong, J., Shi, J., Liu, C.f., Huang, B., Liu, Y., et al.: A zero-burden sleep foundation model built on cardiorespiratory signals from 800,000+ hours of multi-ethnic sleep recordings. medRxiv pp. 2025–09 (2025) 16 S.F. Wong et al
2025
-
[26]
Nie, G., Tang, G., Xiao, Y., Li, J., Huang, S., Zhang, D., Zhao, Q., Hong, S.: Anyppg: An ecg-guided ppg foundation model trained on over 100,000 hours of recordings for holistic health profiling. arXiv preprint arXiv:2511.01747 (2025)
-
[27]
IEEE Access7, 112026–112036 (2019)
Petrozziello, A., Redman, C.W., Papageorghiou, A.T., Jordanov, I., Georgieva, A.: Multimodal convolutional neural networks to detect fetal compromise during labor and delivery. IEEE Access7, 112026–112036 (2019)
2019
-
[28]
Pillai, A., Spathis, D., Kawsar, F., Malekzadeh, M.: Papagei: Open foundation models for optical physiological signals. arXiv preprint arXiv:2410.20542 (2024)
-
[29]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[30]
Frontiers in Physiology15, 1398735 (2024)
Rao, L., Lu, J., Wu, H.R., Zhao, S., Lu, B.C., Li, H.: Automatic classification of fetal heart rate based on a multi-scale lstm network. Frontiers in Physiology15, 1398735 (2024)
2024
-
[31]
arXiv preprint arXiv:2512.02180 , year=
Shu, Y., Charlton, P.H., Kawsar, F., Hernesniemi, J., Malekzadeh, M.: Clef: Clinically-guided contrastive learning for electrocardiogram foundation models. arXiv preprint arXiv:2512.02180 (2025)
-
[32]
In: 2024 IEEE International Conference on Digital Health (ICDH)
Sun, B., Zhao, J., Miao, X., Wu, Y., Fang, M.: Neurofetalnet: Advancing remote electronic fetal monitoring with a new dataset and comparative analysis of fhr and ucp impact. In: 2024 IEEE International Conference on Digital Health (ICDH). pp. 181–188. IEEE (2024)
2024
- [33]
-
[34]
Audioclip: Extending clip to image, text and audio
de Vries, I.R., Huijben, I.A.M., Kok, R.D., van Sloun, R.J.G., Vullings, R.: Contrastive predictive coding for anomaly detection of fetal health from the cardiotocogram. In: ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 3473–3477 (2022). https://doi.org/10.1109/ICASSP43922.2022.9747178
-
[35]
From token to rhythm: A multi-scale approach for ECG-language pretraining,
Wang, F., Xu, J., Yu, L.: From token to rhythm: A multi-scale approach for ecg- language pretraining. arXiv preprint arXiv:2506.21803 (2025)
-
[36]
arXiv preprint arXiv:2405.14616 , year=
Wang, S., Wu, H., Shi, X., Hu, T., Luo, H., Ma, L., Zhang, J.Y., Zhou, J.: Timemixer: Decomposable multiscale mixing for time series forecasting. arXiv preprint arXiv:2405.14616 (2024)
- [37]
-
[38]
In: Proceedings of the 7th ACM International Conference on Multimedia in Asia
Wu, J., Wang, H., Yang, Z., Wu, J.: Mctg: A multimodal self-supervised contrastive learning framework based on ctg. In: Proceedings of the 7th ACM International Conference on Multimedia in Asia. pp. 1–7 (2025)
2025
-
[39]
arXiv preprint arXiv:2505.06291 (2025)
Xiong, W., Lin, J., Li, J., Li, J., Jiang, C.: Alfee: Adaptive large foundation model for eeg representation. arXiv preprint arXiv:2505.06291 (2025)
-
[40]
arXiv preprint arXiv:2512.16922 (2025)
Xu, S., Ma, Z., Chai, W., Chen, X., Jin, W., Chai, J., Xie, S., Yu, S.X.: Next-embedding prediction makes strong vision learners. arXiv preprint arXiv:2512.16922 (2025)
-
[41]
Yang, L., Li, S.W., Li, Y., Lei, X., Wang, D., Mohamed, A., Zhao, H., Xu, H.: In pursuit of pixel supervision for visual pre-training. arXiv preprint arXiv:2512.15715 (2025) PRISM-CTG: A Foundation Model for CTG Analysis with Multi-View SSL 17
-
[42]
Yu, H., Guo, P., Sano, A.: Ecg semantic integrator (esi): A foundation ecg model pretrained with llm-enhanced cardiological text. arXiv preprint arXiv:2405.19366 (2024)
-
[43]
Zhou, Z., Zhao, Z., Zhang, X., Zhang, X., Jiao, P., Ye, X.: Identifying fetal status withfetalheartrate:Deeplearningapproachbasedonlongconvolution.Computers in Biology and Medicine159, 106970 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.