Recognition: 3 theorem links
· Lean TheoremInformation in Many-body Eigenstates: A Question of Learnability
Pith reviewed 2026-05-08 19:01 UTC · model grok-4.3
The pith
Eigenstates near the spectral edges of many-body Hamiltonians allow more accurate reconstruction of the Hamiltonian than mid-spectrum eigenstates when using an encoder-decoder neural network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For a fixed encoder-decoder architecture and physics-inspired loss, spectral-edge eigenstates permit markedly higher accuracy in Hamiltonian prediction and need fewer training examples than mid-spectrum eigenstates, quantifying the greater informational content of the former.
What carries the argument
Learnability, measured by the accuracy of Hamiltonian reconstruction from eigenstate input via an encoder-decoder neural network trained with a physics-inspired loss function.
If this is right
- Spectral position determines the practical utility of eigenstates for Hamiltonian inference.
- Fewer edge eigenstates suffice to learn the Hamiltonian compared with bulk eigenstates.
- Machine learning supplies a quantitative probe of eigenstate information content distinct from entanglement entropy.
- The distinction between edge and mid-spectrum eigenstates is manifested directly in their differential learnability.
Where Pith is reading between the lines
- Experimental protocols that preferentially access low-energy eigenstates could reduce the resources needed for Hamiltonian learning in quantum simulators.
- The same learnability test could be applied to disordered or driven systems to check whether localization alters the edge-bulk information gap.
- Integrable versus chaotic models could be compared to test whether the learnability difference survives changes in level statistics.
Load-bearing premise
The encoder-decoder architecture and chosen loss function measure the intrinsic information content of the eigenstates rather than artifacts of the network or training procedure.
What would settle it
Achieving comparable Hamiltonian reconstruction accuracy from an equal number of mid-spectrum eigenstates as from edge eigenstates would falsify the claimed difference in learnability.
Figures







read the original abstract
To what extent do individual eigenstates encode information of their underlying Hamiltonian, and how does this depend on their spectral position? For many-body quantum systems, this issue is widely understood in terms of the differing nature of the eigenstates near the spectral edges (low-entanglement, highly-structured eigenstates) and those far from the spectral edges (high-entanglement, near-random eigenstates). Utilizing the availability of machine learning tools, we introduce a new way to quantify the information contained in eigenstates: for a particular learning architecture, how precisely can the Hamiltonian be reconstructed from a single eigenstate? We refer to this property as learnability; it serves as a new, alternative measure of the information content of eigenstates, made possible by machine learning. Using an encoder-decoder neural network and a physics-inspired loss function, we demonstrate how the distinction between two types of eigenstates is manifested as a difference in learnability. For spectral-edge eigenstates, the prediction accuracy is much better, and fewer eigenstates are required to learn the Hamiltonian, compared to mid-spectrum eigenstates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces 'learnability' as a machine-learning-based measure of the information about the underlying Hamiltonian encoded in individual many-body eigenstates. Using an encoder-decoder neural network trained with a physics-inspired loss, the authors report that eigenstates near the spectral edges permit substantially higher Hamiltonian reconstruction accuracy and require fewer samples for successful learning than mid-spectrum eigenstates, attributing the distinction to the lower entanglement and greater structure of edge states.
Significance. If the central distinction survives broader validation, the work supplies a new operational, data-driven proxy for eigenstate information content that complements entanglement-based diagnostics. It could inform studies of the eigenstate thermalization hypothesis, many-body localization, and practical Hamiltonian learning protocols from limited quantum data.
major comments (1)
- The interpretation that the reported learnability gap is intrinsic to eigenstate structure (rather than an artifact of the chosen encoder-decoder architecture and loss) is load-bearing for the claim that learnability constitutes a general new measure of information content. No ablations with alternative architectures (linear models, graph networks, or different inductive biases) or loss terms are presented to test whether the edge-versus-mid-spectrum distinction persists; because edge states are low-entanglement while mid-spectrum states obey volume-law entanglement, any architecture favoring local correlations could preferentially succeed on the former. This concern is not addressed by the single-architecture results.
minor comments (2)
- Quantitative details required for assessing soundness—dataset sizes, number of eigenstates per training set, error bars on reconstruction accuracy, and statistical significance tests—are absent from the abstract and not referenced in the provided description of the results.
- The manuscript does not discuss controls for network capacity, hyperparameter sensitivity, or training convergence that could affect the measured sample efficiency and accuracy differences.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. The concern regarding potential architecture dependence is well-taken, and we address it directly below while clarifying the scope of our claims.
read point-by-point responses
-
Referee: The interpretation that the reported learnability gap is intrinsic to eigenstate structure (rather than an artifact of the chosen encoder-decoder architecture and loss) is load-bearing for the claim that learnability constitutes a general new measure of information content. No ablations with alternative architectures (linear models, graph networks, or different inductive biases) or loss terms are presented to test whether the edge-versus-mid-spectrum distinction persists; because edge states are low-entanglement while mid-spectrum states obey volume-law entanglement, any architecture favoring local correlations could preferentially succeed on the former. This concern is not addressed by the single-architecture results.
Authors: We agree that the absence of architecture ablations leaves open the possibility that the observed learnability gap could be influenced by the specific inductive biases of the encoder-decoder network and physics-inspired loss. The manuscript explicitly qualifies learnability as a property 'for a particular learning architecture' (see abstract), and we attribute the gap to the intrinsic structural differences between edge and mid-spectrum eigenstates, particularly their entanglement scaling. To strengthen the interpretation, the revised manuscript will include a new subsection with results from a linear regression baseline and a minimal feedforward network, testing whether the edge-versus-mid-spectrum distinction in reconstruction accuracy persists. We will also expand the discussion to note the current limitation and the need for broader validation in future work. This addresses the core of the concern without claiming full generality at present. revision: partial
Circularity Check
No circularity: learnability is an empirical definition with observed outcomes
full rationale
The paper defines learnability directly as the reconstruction accuracy achieved by training an encoder-decoder network on eigenstates to recover the Hamiltonian parameters, using a physics-inspired loss. The central observation—that spectral-edge eigenstates yield higher accuracy and require fewer samples than mid-spectrum states—is reported as the empirical result of this training procedure rather than a quantity derived from prior fitted parameters or self-referential equations. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to force the distinction; the result remains an independent measurement of the chosen architecture's performance on the two classes of states.
Axiom & Free-Parameter Ledger
free parameters (1)
- Encoder-decoder architecture and training hyperparameters
axioms (1)
- domain assumption A physics-inspired loss function can serve as a faithful proxy for Hamiltonian reconstruction fidelity
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_Rayleigh = (1/N M(M-1)) sum_{i!=j} |(H_res)_{ij}|^2 + gamma (1/NM) sum_i |(H_res)_{ii} - E_i|^2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2(a)], see Eq
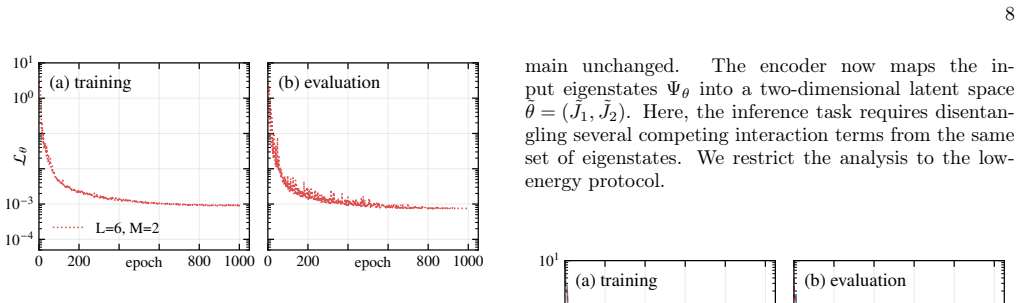
The encoder The procedure begins by performing exact diagonal- ization (ED) of a one-dimensional spin-1/2J 1J2 chain [Fig. 2(a)], see Eq. (1), for preselected parametersθ. Their choice is discussed later in Sec. IV. The encoder takes as input a matrix of many-body eigenstates,Ψθ ∈ RD×M, whereMdenotes the number of eigenstates in- cluded in a single realiz...
-
[2]
Spectral protocol We consider three selection protocols. In Sec. IVB, we use (i) low-energy states (blue),i.e., the first MHamiltonian eigenstates,m i ∈ {1, . . . , M}, and (ii) middle-spectrum states (red),i.e., a set ofM consecutive eigenstates centered around the eigen- state with indexm av, whose energy is closest to the mean energy,E θ mav ≈E av ≡Tr ...
-
[3]
Dependence of the loss on the selected eigenstate in- dexm i according to single state selection protocol
The decoder The decoder maps latent variables˜θto a Hamiltonian ˆH˜θ = ˜F( ˜θ), whose eigenstatesΨ ˜θ are required to match 4 10□4 102Lrayleigh (a) /u1D441sam = 1000 /u1D464/u1D43B= 4 /u1D464/u1D43B= 64 /u1D464/u1D43B= 128 (b) /u1D441sam = 20000 0 10 20 30/u1D45A/u1D456 10□3 100L /u1D703 (c) /u1D441sam = 1000 0 10 20 30/u1D45A/u1D456 (d) /u1D441sam = 2000...
2024
-
[4]
G. Carleo and M. Troyer, Science355, 602 (2017), https://www.science.org/doi/pdf/10.1126/science.aag2302
-
[5]
Lange, A
H. Lange, A. Van de Walle, A. Abedinnia, and A. Bohrdt, From Architectures to Applications: A Re- view of Neural Quantum States (2024)
2024
-
[6]
Neural- network quantum states for many-body physics,
M. Medvidović and J. R. Moreno, The European Phys- ical Journal Plus139, 631 (2024), arXiv:2402.11014 [cond-mat]
-
[7]
S. Dash, L. Gravina, F. Vicentini, M. Ferrero, and A. Georges, Communications Physics8, 10.1038/s42005-025-02005-4 (2025)
-
[8]
Paul, Physical Review Letters136, 120403 (2026)
N. Paul, Physical Review Letters136, 120403 (2026)
2026
-
[9]
Torlai, G
G. Torlai, G. Mazzola, J. Carrasquilla, M. Troyer, R.Melko,andG.Carleo,NaturePhysics14,447(2018)
2018
-
[10]
Koutný, L
D. Koutný, L. Motka, Z. c. v. Hradil, J. Řeháček, and L. L. Sánchez-Soto, Phys. Rev. A106, 012409 (2022)
2022
-
[11]
Baláž, M
P. Baláž, M. Krawczyk, J. Pawłowski, and K. Roszak, Phys. Rev. A112, 022431 (2025)
2025
-
[12]
M. Krawczyk, P. Baláž, K. Roszak, and J. Pawłowski, Learning quantum tomography from incomplete mea- surements (2026), arXiv:2506.19428 [quant-ph]
-
[13]
Broecker, J
P. Broecker, J. Carrasquilla, R. G. Melko, and S. Trebst, Scientific Reports7, 8823 (2017)
2017
-
[14]
Carrasquilla and R
J. Carrasquilla and R. G. Melko, Nature Physics13, 431 (2017)
2017
-
[15]
X.-Y. Dong, F. Pollmann, and X.-F. Zhang, Physical Review B99, 121104 (2019)
2019
-
[16]
B. S. Rem, N. Käming, M. Tarnowski, L. Asteria, N. Fläschner, C. Becker, K. Sengstock, and C. Weit- enberg, Nature Physics15, 917 (2019)
2019
-
[17]
Canabarro, F
A. Canabarro, F. F. Fanchini, A. L. Malvezzi, R. Pereira, and R. Chaves, Physical Review B100, 045129 (2019)
2019
-
[18]
Shiina, H
K. Shiina, H. Mori, Y. Okabe, and H. K. Lee, Scientific Reports10, 2177 (2020)
2020
-
[19]
Yu, L.-W
Y. Yu, L.-W. Yu, W. Zhang, H. Zhang, X. Ouyang, Y. Liu, D.-L. Deng, and L. M. Duan, Experimental unsupervised learning of non-Hermitian knotted phases with solid-state spins (2021)
2021
-
[20]
Mahlow, F
F. Mahlow, F. S. Luiz, A. L. Malvezzi, and F. F. Fan- chini, Scientific Reports13, 14411 (2023)
2023
-
[21]
G. S. Franco, F. Mahlow, P. M. Prado, G. E. L. Pexe, L. A. M. Rattighieri, and F. F. Fanchini, Quantum Phases Classification Using Quantum Machine Learn- 9 ing with SHAP-Driven Feature Selection (2025)
2025
-
[22]
Behler and M
J. Behler and M. Parrinello, Physical Review Letters 98, 146401 (2007)
2007
-
[23]
Behler, The Journal of Chemical Physics145, 170901 (2016)
J. Behler, The Journal of Chemical Physics145, 170901 (2016)
2016
-
[24]
F. A. Faber, A. Lindmaa, O. A. Von Lilienfeld, and R. Armiento, Physical Review Letters117, 135502 (2016)
2016
-
[25]
Artrith, A
N. Artrith, A. Urban, and G. Ceder, Physical Review B 96, 014112 (2017)
2017
-
[26]
A. Seko, H. Hayashi, K. Nakayama, A. Takahashi, and I. Tanaka, Physical Review B95, 144110 (2017)
2017
-
[27]
Akinpelu, M
A. Akinpelu, M. Bhullar, and Y. Yao, Journal of Physics: Condensed Matter36, 453001 (2024)
2024
-
[28]
Nematov and M
D. Nematov and M. Hojamberdiev, Computational Condensed Matter45, e01139 (2025)
2025
-
[29]
Yoon, J.-H
H. Yoon, J.-H. Sim, and M. J. Han, Physical Review B 98, 245101 (2018)
2018
-
[30]
Zhang, M
R. Zhang, M. E. Merkel, S. Beck, and C. Ederer, Phys- ical Review Research4, 043082 (2022)
2022
-
[31]
Kliczkowski, L
M. Kliczkowski, L. Keyes, S. Roy, T. Paiva, M. Rande- ria, N. Trivedi, and M. M. Maśka, Physical Review B 110, 115119 (2024)
2024
-
[32]
Vidal, J
G. Vidal, J. I. Latorre, E. Rico, and A. Kitaev, Phys. Rev. Lett.90, 227902 (2003)
2003
-
[33]
Calabrese and J
P. Calabrese and J. Cardy, Journal of statistical me- chanics: theory and experiment2004, P06002 (2004)
2004
-
[34]
Kitaev and J
A. Kitaev and J. Preskill, Phys. Rev. Lett.96, 110404 (2006)
2006
-
[35]
Levin and X.-G
M. Levin and X.-G. Wen, Phys. Rev. Lett.96, 110405 (2006)
2006
-
[36]
Eisert, M
J. Eisert, M. Cramer, and M. B. Plenio, Reviews of Modern Physics82, 277 (2010)
2010
-
[37]
Laflorencie, Physics Reports646, 1 (2016)
N. Laflorencie, Physics Reports646, 1 (2016)
2016
-
[38]
Bianchi, L
E. Bianchi, L. Hackl, M. Kieburg, M. Rigol, and L. Vid- mar, PRX Quantum3, 030201 (2022)
2022
-
[39]
D. J. Luitz, N. Laflorencie, and F. Alet, Journal of Statistical Mechanics: Theory and Experiment2014, P08007 (2014)
2014
-
[40]
Vermersch, M
B. Vermersch, M. Ljubotina, J. I. Cirac, P. Zoller, M. Serbyn, and L. Piroli, Physical Review X14, 031035 (2024)
2024
-
[41]
E. H. Lieb and D. W. Robinson, Communications in Mathematical Physics28, 251 (1972)
1972
-
[42]
M. B. Hastings, Journal of Statistical Mechanics: The- ory and Experiment2007, P08024 (2007)
2007
-
[43]
Srednicki, Phys
M. Srednicki, Phys. Rev. E50, 888 (1994)
1994
-
[44]
J. M. Deutsch, Phys. Rev. A43, 2046 (1991)
2046
-
[45]
Rigol, V
M. Rigol, V. Dunjko, and M. Olshanii, Nature (London) 452, 854 (2008)
2008
-
[46]
D’Alessio, Y
L. D’Alessio, Y. Kafri, A. Polkovnikov, and M. Rigol, Adv. Phys.65, 239 (2016)
2016
-
[47]
J. R. Garrison and T. Grover, Physical Review X8, 021026 (2018)
2018
-
[48]
M.Haque, P.A.McClarty,andI.M.Khaymovich,Phys- ical Review E105, 014109 (2022)
2022
-
[49]
Huang, IEEE Journal on Selected Areas in Informa- tion Theory5, 694 (2024)
Y. Huang, IEEE Journal on Selected Areas in Informa- tion Theory5, 694 (2024)
2024
-
[50]
Kliczkowski, R
M. Kliczkowski, R. Świętek, L. Vidmar, and M. Rigol, Physical Review E107, 064119 (2023)
2023
-
[51]
C. M. Langlett and J. F. Rodriguez-Nieva, Physical Re- view Letters134, 230402 (2025)
2025
-
[52]
Patil, L
R. Patil, L. Hackl, G. R. Fagan, and M. Rigol, Physical Review B108, 245101 (2023)
2023
-
[53]
J.F.Rodriguez-Nieva, C.Jonay,andV.Khemani,Phys- ical Review X14, 031014 (2024)
2024
-
[54]
Świ¸ etek, M
R. Świ¸ etek, M. Kliczkowski, L. Vidmar, and M. Rigol, Physical Review E109, 024117 (2024)
2024
-
[55]
Y. Yauk, R. Patil, Y. Zhang, M. Rigol, and L. Hackl, Physical Review B110, 235154 (2024)
2024
-
[56]
Qi and D
X.-L. Qi and D. Ranard, Quantum3, 159 (2019)
2019
-
[57]
D. Bank, N. Koenigstein, and R. Giryes, Autoencoders (2020)
2020
-
[58]
A. N. Gorban, V. A. Makarov, and I. Y. Tyukin, En- tropy22, 82 (2020)
2020
-
[59]
Pugliese, S
R. Pugliese, S. Regondi, and R. Marini, Data Science and Management4, 19 (2021)
2021
-
[60]
Cybenko, Mathematics of Control, Signals, and Sys- tems2, 303 (1989)
G. Cybenko, Mathematics of Control, Signals, and Sys- tems2, 303 (1989)
1989
-
[61]
Gallant, IEEE Transactions on Neural Networks1, 179 (1990)
S. Gallant, IEEE Transactions on Neural Networks1, 179 (1990)
1990
-
[62]
Hornik, M
K. Hornik, M. Stinchcombe, and H. White, Neural Net- works2, 359 (1989)
1989
-
[63]
440– 449
H.T.SiegelmannandE.D.Sontag,inProceedings of the fifth annual workshop on Computational learning theory (ACM, Pittsburgh Pennsylvania USA, 1992) pp. 440– 449
1992
-
[64]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, Attention Is All You Need (2017)
2017
-
[65]
Barron, IEEE Transactions on Information Theory 39, 930 (1993)
A. Barron, IEEE Transactions on Information Theory 39, 930 (1993)
1993
-
[66]
X. Yuan, S. Endo, Q. Zhao, Y. Li, and S. C. Benjamin, Quantum3, 191 (2019)
2019
-
[67]
Cerezo, A
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, Nature Reviews Physics3, 625 (2021)
2021
-
[68]
Raissi, P
M. Raissi, P. Perdikaris, and G. Karniadakis, Journal of Computational Physics378, 686 (2019)
2019
-
[69]
Wang, and L
G.E.Karniadakis, I.G.Kevrekidis, L.Lu, P.Perdikaris, S. Wang, and L. Yang, Nature Reviews Physics3, 422 (2021)
2021
-
[71]
D.-L. Deng, X. Li, and S. Das Sarma, Physical Review X7, 021021 (2017)
2017
-
[72]
Y. Chen, Y. Pan, G. Zhang, and S. Cheng, Quantum Science and Technology7, 015005 (2021)
2021
-
[73]
Koutný, L
D. Koutný, L. Ginés, M. Moczała-Dusanowska, S. Höfling, C. Schneider, A. Predojević, and M. Ježek, Science Advances9, eadd7131 (2023)
2023
-
[74]
Pawłowski and M
J. Pawłowski and M. Krawczyk, Phys. Rev. Appl.22, 014068 (2024)
2024
-
[75]
Feng and L
C. Feng and L. Chen, Communications in Theoretical Physics76, 075104 (2024)
2024
-
[76]
Huang, L
Y. Huang, L. Che, C. Wei, F. Xu, X. Nie, J. Li, D. Lu, and T. Xin, npj Quantum Information11, 29 (2025)
2025
-
[77]
Krawczyk, J
M. Krawczyk, J. Pawłowski, M. M. Maśka, and K. Roszak, Phys. Rev. A109, 022405 (2024)
2024
-
[78]
Zhang, P
Y. Zhang, P. Ginsparg, and E.-A. Kim, Physical Review Research2, 023283 (2020)
2020
-
[79]
Valenti, G
A. Valenti, G. Jin, J. Léonard, S. D. Huber, and E. Gre- plova, Physical Review A105, 023302 (2022)
2022
-
[80]
S. J. Wetzel, S. Ha, R. Iten, M. Klopotek, and Z. Liu, Interpretable Machine Learning in Physics: A Review (2025)
2025
-
[81]
E. P. L. Van Nieuwenburg, Y.-H. Liu, and S. D. Huber, 10 Nature Physics13, 435 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.