Recognition: 2 theorem links
· Lean TheoremOGPO: Sample Efficient Full-Finetuning of Generative Control Policies
Pith reviewed 2026-05-08 18:41 UTC · model grok-4.3
The pith
OGPO fine-tunes generative control policies to near full task success from poor initializations with no expert data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
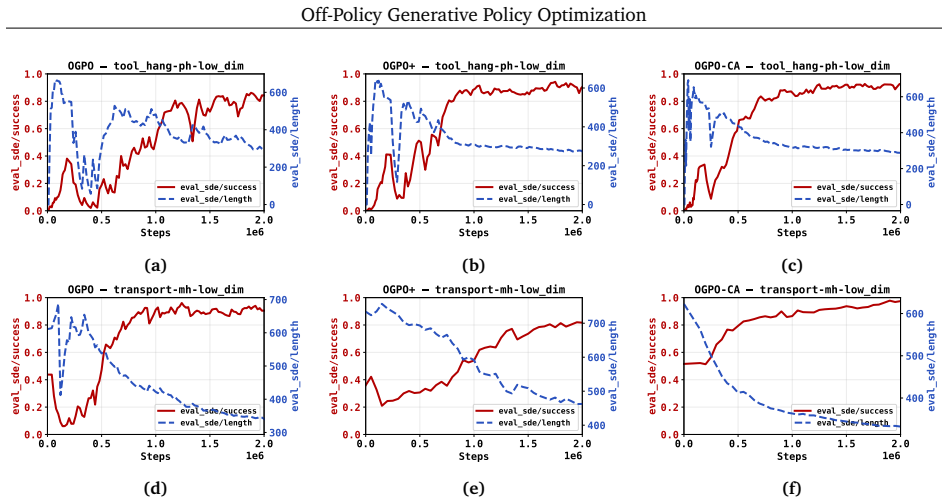
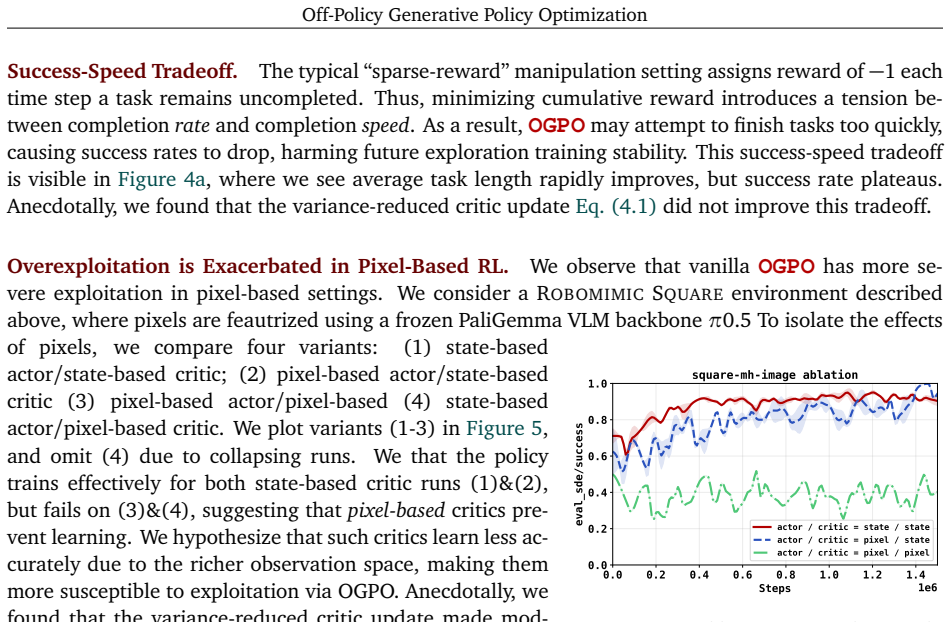
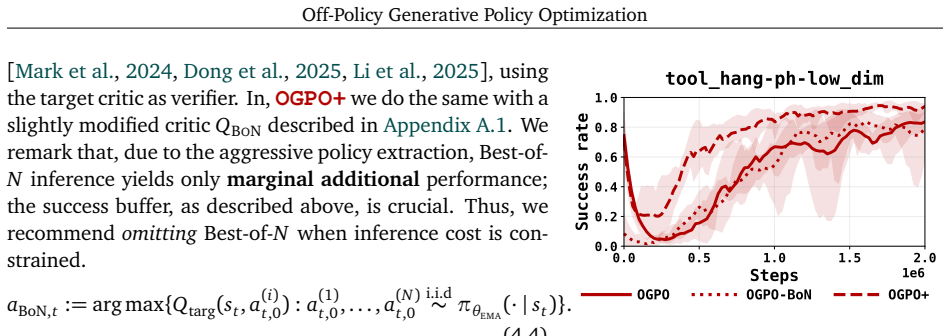
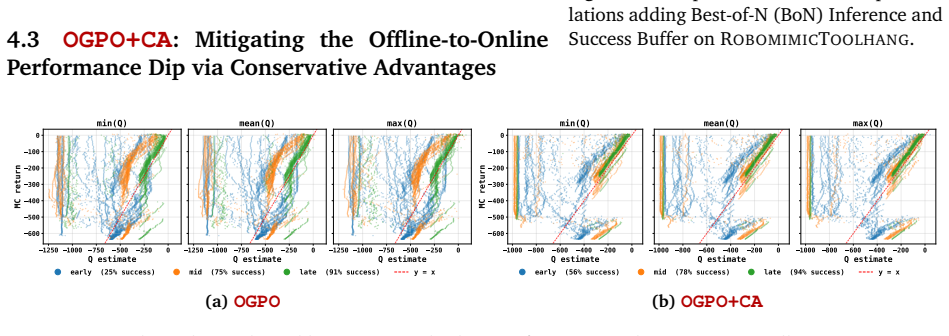
OGPO maintains off-policy critic networks to maximize data reuse and propagates policy gradients through the full generative process of the policy via a modified PPO objective, using critics as the terminal reward. It achieves state-of-the-art performance on manipulation tasks spanning multi-task settings, high-precision insertion, and dexterous control. It is the only method that can fine-tune poorly-initialized behavior cloning policies to near full task-success with no expert data in the online replay buffer, and does so with few task-specific hyperparameter tuning. The work also identifies practical stabilizers including success-buffer regularization, conservative advantages, chi-squared
What carries the argument
The modified PPO objective that uses off-policy critics as terminal rewards to back-propagate gradients through the complete generative sampling steps of the policy while enabling data reuse.
If this is right
- The method outperforms alternatives on policy steering and residual correction tasks.
- It delivers strong results in multi-task, high-precision insertion, and dexterous control without expert data.
- Few task-specific hyperparameter changes are needed across different observation types.
- Stabilizers such as success-buffer regularization and Q-variance reduction prevent critic over-exploitation.
Where Pith is reading between the lines
- The same off-policy critic structure could be tested on fine-tuning other generative models outside robotics.
- Starting from cheap behavior cloning initializations may cut the cost of deploying learned policies in real environments.
- The stabilizers might generalize to larger-scale policies or additional generative architectures.
- Similar gradient propagation through sampling processes could apply to non-manipulation control problems like navigation.
Load-bearing premise
Off-policy critics stay stable and provide useful signals when gradients are sent through the entire generative policy process via the modified PPO objective, without heavy per-task tuning or collapse in state- and pixel-based settings.
What would settle it
Apply OGPO to a dexterous manipulation task starting from a poorly initialized behavior cloning policy and an empty expert data buffer; if the policy does not reach near full task success or exhibits instability, the central claim fails.
Figures





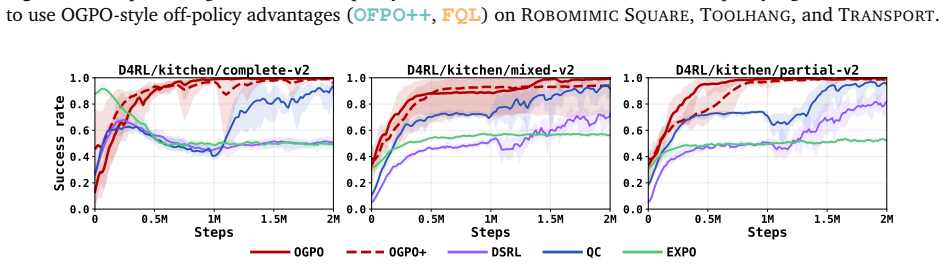
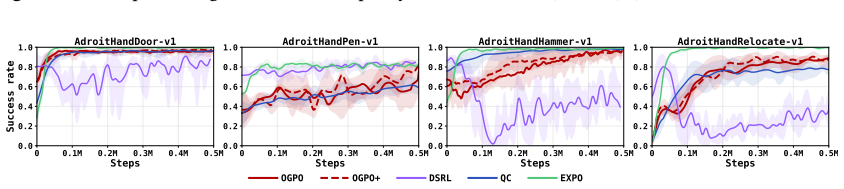


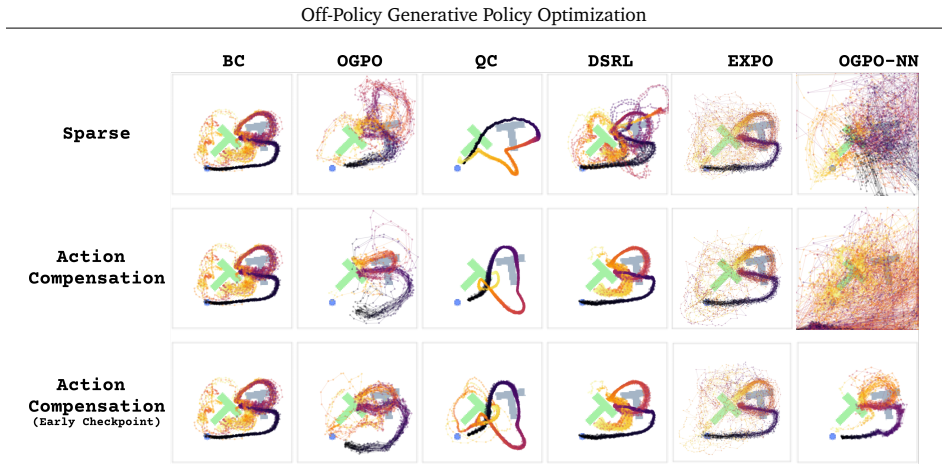

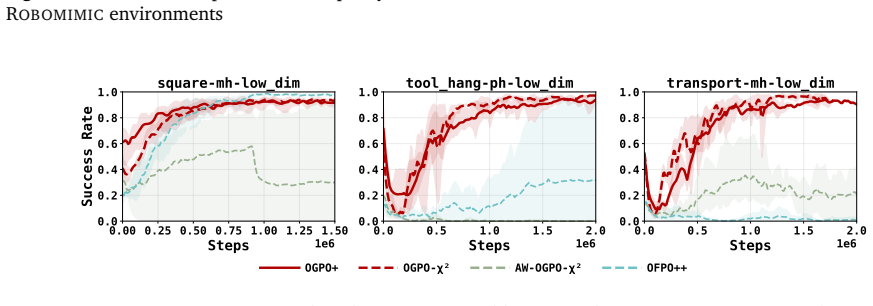










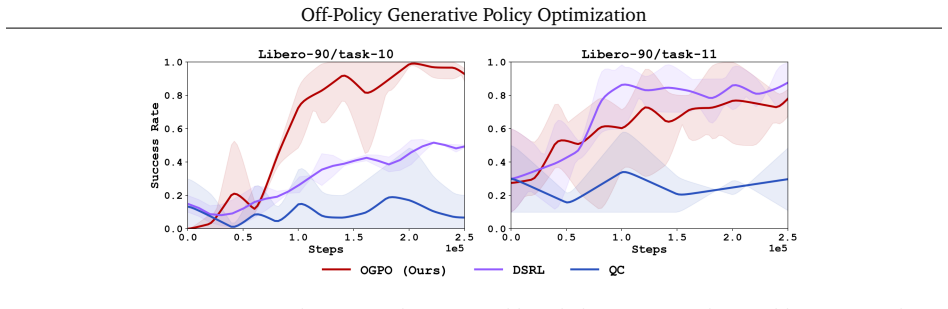
read the original abstract
Generative control policies (GCPs), such as diffusion- and flow-based control policies, have emerged as effective parameterizations for robot learning. This work introduces Off-policy Generative Policy Optimization (OGPO), a sample-efficient algorithm for finetuning GCPs that maintains off-policy critic networks to maximize data reuse and propagate policy gradients through the full generative process of the policy via a modified PPO objective, using critics as the terminal reward. OGPO achieves state-of-the-art performance on manipulation tasks spanning multi-task settings, high-precision insertion, and dexterous control. To our knowledge, it is also the only method that can fine-tune poorly-initialized behavior cloning policies to near full task-success with no expert data in the online replay buffer, and does so with few task-specific hyperparameter tuning. Through extensive empirical investigations, we demonstrate the OGPO drastically outperforms methods alternatives on policy steering and learning residual corrections, and identify the key mechanisms behind its performance. We further introduce practical stabilizers, including success-buffer regularization, conservative advantages, $\chi^2$ regularization, and Q-variance reduction, to mitigate critic over-exploitation across state- and pixel-based settings. Beyond proposing OGPO, we conduct a systematic empirical study of GCP finetuning, identifying the stabilizing mechanisms and failure modes that govern successful off-policy full-policy improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Off-policy Generative Policy Optimization (OGPO), an algorithm for sample-efficient full-finetuning of generative control policies (GCPs) such as diffusion- and flow-based policies. OGPO maintains off-policy critic networks for data reuse and employs a modified PPO objective in which the critics act as terminal rewards, allowing policy gradients to propagate through the entire generative sampling process. It reports state-of-the-art results on robot manipulation tasks spanning multi-task settings, high-precision insertion, and dexterous control. The work claims to be the only method able to fine-tune poorly-initialized behavior-cloning policies to near-full task success with no expert data in the online replay buffer and with minimal task-specific hyperparameter tuning. Four practical stabilizers (success-buffer regularization, conservative advantages, χ² regularization, and Q-variance reduction) are introduced to address critic over-exploitation, and a systematic empirical study of GCP finetuning is presented.
Significance. If the empirical results and stability claims hold under rigorous verification, OGPO would constitute a meaningful advance in sample-efficient robot learning by providing a practical route to optimize expressive generative policies that are otherwise difficult to train. The identification of concrete stabilizing mechanisms and failure modes for off-policy full-policy improvement could inform subsequent work on generative policies in both state- and pixel-based regimes.
major comments (2)
- [Abstract (stabilizers and empirical claims)] The load-bearing claim that off-policy critics remain stable and non-exploitative when used as terminal rewards inside the modified PPO objective (with gradients back-propagated through the full generative chain) is supported only by the introduction of four stabilizers. It is not shown whether these stabilizers generalize without non-trivial per-task tuning precisely in the regime of very poor initial BC policies and zero expert data in the replay buffer—the setting highlighted as novel.
- [Abstract and empirical investigations section] The assertion of state-of-the-art performance and unique capability to reach near-full task success from poorly-initialized BC policies rests on extensive empirical investigations whose full details (baselines, statistical reporting, ablation studies on the stabilizers, and exact experimental protocols) are not verifiable from the provided material. This directly limits assessment of whether the reported gains are robust.
minor comments (2)
- Notation for the modified PPO objective and the precise form of the terminal reward derived from the critic could be clarified with an explicit equation reference to aid reproducibility.
- The abstract states that the method works 'with few task-specific hyperparameter tuning'; a concise table summarizing the hyperparameter ranges actually used across tasks would strengthen this claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review of our manuscript on OGPO. We value the emphasis on rigorous verification of stability claims and empirical robustness, and we address each major comment below with specific plans for revision where appropriate.
read point-by-point responses
-
Referee: [Abstract (stabilizers and empirical claims)] The load-bearing claim that off-policy critics remain stable and non-exploitative when used as terminal rewards inside the modified PPO objective (with gradients back-propagated through the full generative chain) is supported only by the introduction of four stabilizers. It is not shown whether these stabilizers generalize without non-trivial per-task tuning precisely in the regime of very poor initial BC policies and zero expert data in the replay buffer—the setting highlighted as novel.
Authors: We thank the referee for this precise observation on the load-bearing nature of the stability claim. The manuscript evaluates OGPO specifically in the regime of poorly initialized BC policies with no expert data in the replay buffer, demonstrating stable critic behavior and high task success across multi-task, insertion, and dexterous manipulation settings. The four stabilizers are introduced with motivations tied to observed failure modes (critic over-exploitation, advantage bias, distribution shift, and variance), and ablations show their individual contributions. While the paper reports results with limited task-specific tuning, we acknowledge that a more explicit demonstration of fixed-hyperparameter generalization across this exact regime would strengthen the claim. In the revision we will add a dedicated subsection analyzing hyperparameter sensitivity and include new experiments using a single shared hyperparameter configuration for the poor-initialization setting. revision: partial
-
Referee: [Abstract and empirical investigations section] The assertion of state-of-the-art performance and unique capability to reach near-full task success from poorly-initialized BC policies rests on extensive empirical investigations whose full details (baselines, statistical reporting, ablation studies on the stabilizers, and exact experimental protocols) are not verifiable from the provided material. This directly limits assessment of whether the reported gains are robust.
Authors: We apologize that the experimental details were not sufficiently clear or accessible in the material reviewed. The full manuscript includes: (i) explicit baseline descriptions and implementation details for all compared methods, (ii) statistical reporting with means, standard deviations, and multiple random seeds for all main results, (iii) comprehensive ablations isolating each stabilizer, and (iv) exact protocols (network architectures, replay buffer sizes, sampling steps, and environment parameters) in the appendix. To improve verifiability we will revise the main text to include a concise summary table of key experimental settings and ensure every performance claim is cross-referenced to the corresponding figure, table, or appendix section. These changes will make the robustness of the reported gains easier to assess without altering the underlying results. revision: yes
Circularity Check
No significant circularity: empirical algorithmic proposal with independent experimental validation
full rationale
The paper presents OGPO as a practical algorithm extending PPO for generative policies, using off-policy critics as terminal rewards and introducing four stabilizers (success-buffer regularization, conservative advantages, χ² regularization, Q-variance reduction). All central claims concern empirical performance on manipulation tasks, including fine-tuning poorly-initialized BC policies without expert data. No derivation chain, uniqueness theorem, or first-principles prediction is offered that reduces by the paper's own equations to fitted parameters, self-citations, or ansatzes; the work is self-contained as an empirical contribution whose results are externally falsifiable via replication on the reported tasks and baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- PPO and stabilizer hyperparameters
axioms (1)
- domain assumption Off-policy critics can provide reliable terminal rewards for policy gradient updates through generative processes
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Implicit reparameterization gradients , author=. Advances in neural information processing systems , volume=
-
[2]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling llm test-time compute optimally can be more effective than scaling model parameters , author=. arXiv preprint arXiv:2408.03314 , year=
-
[3]
International Conference on Machine Learning , pages=
Do differentiable simulators give better policy gradients? , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[4]
arXiv preprint arXiv:2310.11428 , year=
Butterfly effects of sgd noise: Error amplification in behavior cloning and autoregression , author=. arXiv preprint arXiv:2310.11428 , year=
-
[5]
2004 , publisher=
Optimal control theory: an introduction , author=. 2004 , publisher=
2004
-
[6]
Advances in Neural Information Processing Systems , volume=
TaSIL: Taylor series imitation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Machine Learning , pages=
Information-theoretic considerations in batch reinforcement learning , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[8]
SIAM journal on control and optimization , volume=
A Lyapunov-like characterization of asymptotic controllability , author=. SIAM journal on control and optimization , volume=. 1983 , publisher=
1983
-
[9]
Preference fine-tuning of LLMs should leverage suboptimal, on-policy data,
Preference fine-tuning of llms should leverage suboptimal, on-policy data , author=. arXiv preprint arXiv:2404.14367 , year=
-
[10]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review arXiv
-
[11]
SGDR: Stochastic Gradient Descent with Warm Restarts
SGDR: Stochastic gradient descent with warm restarts , author=. arXiv preprint arXiv:1608.03983 , year=
-
[12]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[13]
arXiv preprint arXiv:2306.06253 , year=
Decision Stacks: Flexible Reinforcement Learning via Modular Generative Models , author=. arXiv preprint arXiv:2306.06253 , year=
- [14]
-
[15]
Planning with Diffusion for Flexible Behavior Synthesis
Planning with diffusion for flexible behavior synthesis , author=. arXiv preprint arXiv:2205.09991 , year=
work page internal anchor Pith review arXiv
-
[16]
Imitating human behaviour with diffusion models.arXiv preprint arXiv:2301.10677, 2023
Imitating human behaviour with diffusion models , author=. arXiv preprint arXiv:2301.10677 , year=
-
[17]
Is Conditional Generative Modeling all you need for Decision-Making? , author=. arXiv preprint arXiv:2211.15657 , year=
-
[20]
Advances in neural information processing systems , volume=
Behavior Transformers: Cloning k modes with one stone , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in neural information processing systems , volume=
Decision transformer: Reinforcement learning via sequence modeling , author=. Advances in neural information processing systems , volume=
-
[22]
Neural computing and applications , volume=
Deep imitation learning for 3D navigation tasks , author=. Neural computing and applications , volume=. 2018 , publisher=
2018
-
[23]
ACM Computing Surveys (CSUR) , volume=
Imitation learning: A survey of learning methods , author=. ACM Computing Surveys (CSUR) , volume=. 2017 , publisher=
2017
-
[24]
End to End Learning for Self-Driving Cars
End to end learning for self-driving cars , author=. arXiv preprint arXiv:1604.07316 , year=
work page internal anchor Pith review arXiv
-
[25]
Conference on robot learning , pages=
One-shot visual imitation learning via meta-learning , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[26]
2018 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Deep imitation learning for complex manipulation tasks from virtual reality teleoperation , author=. 2018 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2018 , organization=
2018
- [27]
-
[28]
Learning for Dynamics and Control Conference , pages=
On the sample complexity of stability constrained imitation learning , author=. Learning for Dynamics and Control Conference , pages=. 2022 , organization=
2022
-
[29]
Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=
A reduction of imitation learning and structured prediction to no-regret online learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
2011
-
[30]
Conference on robot learning , pages=
Dart: Noise injection for robust imitation learning , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[31]
2019 International Conference on Robotics and Automation (ICRA) , pages=
Hg-dagger: Interactive imitation learning with human experts , author=. 2019 International Conference on Robotics and Automation (ICRA) , pages=. 2019 , organization=
2019
-
[32]
MEGA-DAgger: Imitation Learning with Multiple Imperfect Experts, May 2024
MEGA-DAgger: Imitation Learning with Multiple Imperfect Experts , author=. arXiv preprint arXiv:2303.00638 , year=
-
[33]
arXiv preprint arXiv:2106.03207 , year=
Mitigating covariate shift in imitation learning via offline data without great coverage , author=. arXiv preprint arXiv:2106.03207 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Causal confusion in imitation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=
Efficient reductions for imitation learning , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
2010
-
[36]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Is Behavior Cloning All You Need? Understanding Horizon in Imitation Learning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[37]
2003 , publisher=
On the sample complexity of reinforcement learning , author=. 2003 , publisher=
2003
-
[38]
Distributional and L^q norm inequalities for polynomials over convex bodies in
Carbery, Anthony and Wright, James , journal=. Distributional and L^q norm inequalities for polynomials over convex bodies in. 2001 , publisher=
2001
-
[39]
International conference on machine learning , pages=
How to escape saddle points efficiently , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[40]
Mathematics of Computation , volume=
Recovery of Sobolev functions restricted to iid sampling , author=. Mathematics of Computation , volume=
-
[41]
arXiv preprint cs/0408007 , year=
Online convex optimization in the bandit setting: gradient descent without a gradient , author=. arXiv preprint cs/0408007 , year=
work page internal anchor Pith review arXiv
-
[42]
Nonlinear and optimal control theory: lectures given at the CIME summer school held in Cetraro, Italy June 19--29, 2004 , pages=
Input to state stability: Basic concepts and results , author=. Nonlinear and optimal control theory: lectures given at the CIME summer school held in Cetraro, Italy June 19--29, 2004 , pages=. 2008 , publisher=
2004
-
[43]
Statistics & Probability Letters , volume=
Optimal global rates of convergence for interpolation problems with random design , author=. Statistics & Probability Letters , volume=. 2013 , publisher=
2013
-
[44]
High-probability minimax lower bounds,
High-probability minimax lower bounds , author=. arXiv preprint arXiv:2406.13447 , year=
-
[45]
2006 , publisher=
A distribution-free theory of nonparametric regression , author=. 2006 , publisher=
2006
-
[46]
Advances in Neural Information Processing Systems , year=
Provable guarantees for generative behavior cloning: Bridging low-level stability and high-level behavior , author=. Advances in Neural Information Processing Systems , year=
-
[47]
IFAC Proceedings Volumes , volume=
Uncertainty in unstable systems: the gap metric , author=. IFAC Proceedings Volumes , volume=. 1981 , publisher=
1981
-
[48]
2000 , publisher=
Empirical Processes in M-estimation , author=. 2000 , publisher=
2000
-
[49]
2019 , publisher=
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
2019
-
[50]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Minimax Linear Regression under the Quantile Risk , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
2024
-
[51]
Proceedings of The 7th Conference on Robot Learning , pages =
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control , author =. Proceedings of The 7th Conference on Robot Learning , pages =. 2023 , editor =
2023
-
[52]
Advances in Neural Information Processing Systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Offline Reinforcement Learning with Implicit Q-Learning
Offline reinforcement learning with implicit q-learning , author=. arXiv preprint arXiv:2110.06169 , year=
work page internal anchor Pith review arXiv
-
[54]
Advances in neural information processing systems , volume=
Generative adversarial imitation learning , author=. Advances in neural information processing systems , volume=
-
[55]
International Conference on Machine Learning , pages=
Of moments and matching: A game-theoretic framework for closing the imitation gap , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[56]
arXiv preprint arXiv:2410.13855 , year=
Diffusing States and Matching Scores: A New Framework for Imitation Learning , author=. arXiv preprint arXiv:2410.13855 , year=
-
[60]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Idql: Implicit q-learning as an actor-critic method with diffusion policies , author=. arXiv preprint arXiv:2304.10573 , year=
work page internal anchor Pith review arXiv
-
[61]
The Annals of Statistics , volume=
On nonparametric estimation of density level sets , author=. The Annals of Statistics , volume=. 1997 , publisher=
1997
-
[62]
Journal of Multivariate Analysis , volume=
Nonparametric estimation of a function from noiseless observations at random points , author=. Journal of Multivariate Analysis , volume=. 2017 , publisher=
2017
-
[63]
2018 , publisher=
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
2018
-
[64]
IEEE Transactions on Intelligent Vehicles , volume=
Motion planning for autonomous driving: The state of the art and future perspectives , author=. IEEE Transactions on Intelligent Vehicles , volume=. 2023 , publisher=
2023
-
[65]
2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Grasping with chopsticks: Combating covariate shift in model-free imitation learning for fine manipulation , author=. 2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2021 , organization=
2021
-
[66]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Seil: simulation-augmented equivariant imitation learning , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[67]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[68]
Advances in neural information processing systems , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in neural information processing systems , volume=
-
[75]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[78]
Nakamoto, Mitsuhiko and Zhai, Yuexiang and Singh, Anikait and Mark, Max Sobol and Ma, Yi and Finn, Chelsea and Kumar, Aviral and Levine, Sergey , month = jan, year =. Cal-. doi:10.48550/arXiv.2303.05479 , abstract =
-
[80]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[83]
TD-M (PC) \^
Lin, Haotian and Wang, Pengcheng and Schneider, Jeff and Shi, Guanya , journal=. TD-M (PC) \^
-
[87]
International Conference on Machine Learning , pages=
Curriculum reinforcement learning via constrained optimal transport , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[88]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[91]
International conference on machine learning , pages=
Addressing function approximation error in actor-critic methods , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[93]
Advances in Neural Information Processing Systems , volume=
Libero: Benchmarking knowledge transfer for lifelong robot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[94]
arXiv preprint arXiv:2510.21995 , year=
Is Temporal Difference Learning the Gold Standard for Stitching in RL? , author=. arXiv preprint arXiv:2510.21995 , year=
-
[95]
Statistics and computing , volume=
Annealed importance sampling , author=. Statistics and computing , volume=. 2001 , publisher=
2001
-
[96]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[97]
Residual off-policy rl for finetuning behavior cloning policies , author=. arXiv preprint arXiv:2509.19301 , year=
-
[99]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[102]
Consistency models , author=
-
[104]
Conference on Robot Learning (CoRL) , year=
BridgeData V2: A Dataset for Robot Learning at Scale , author=. Conference on Robot Learning (CoRL) , year=
-
[105]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[107]
and Simard, P
Bengio, Y. and Simard, P. and Frasconi, P. , journal=. Learning long-term dependencies with gradient descent is difficult , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.