Recognition: unknown
Fast Strategy Solving for the Informed Player in Two-Player Zero-Sum Linear-Quadratic Differential Games with One-Sided Information
Pith reviewed 2026-05-08 02:31 UTC · model grok-4.3
The pith
The informed player's Nash equilibrium strategy in linear-quadratic differential games with one-sided information reduces to a bi-level optimization over signaling and closed-loop controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
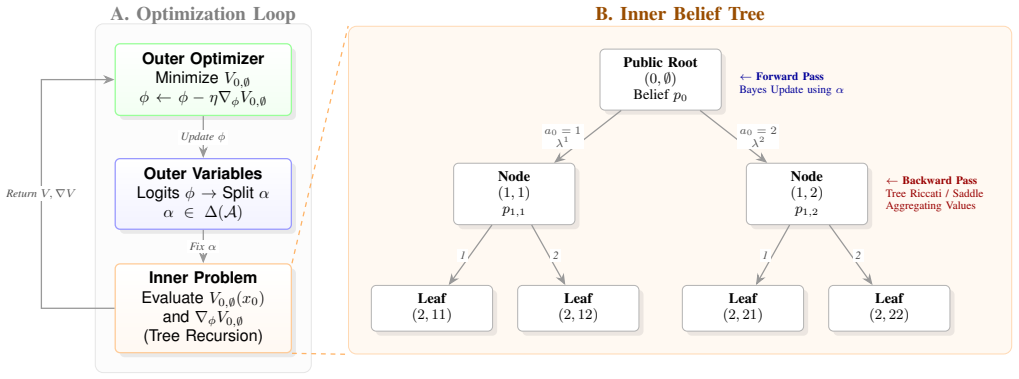
For linear dynamics and quadratic losses the informed player's equilibrium strategy computation can be formulated as a bi-level optimization problem in which the outer level optimizes the signaling strategy (when and how to release type information) and the inner level is a game-tree LQR that yields the optimal closed-loop control; the bi-level problem is solved by an adjoint-enabled backpropagation scheme that alternates a backward LQR pass with a forward gradient descent pass for improving the signaling policy.
What carries the argument
Bi-level optimization whose outer level selects signaling actions that shape the uninformed player's belief updates and whose inner level solves a sequence of linear-quadratic regulators on the resulting information tree, optimized jointly by adjoint-enabled backpropagation.
If this is right
- Sub-game solving reaches approximately 10 Hz for eight-dimensional states, two-dimensional actions, and ten-step horizons, making real-time equilibrium approximation feasible under information asymmetry.
- The method directly incorporates random disturbances into the closed-loop LQR solutions, yielding robust strategies that account for both payoff uncertainty and process noise.
- Signaling policies that mix information revelation with deliberate belief manipulation become computable without enumerating the full belief simplex.
- The same adjoint-backpropagation pipeline can be applied to any linear-quadratic zero-sum game whose payoff is drawn from a finite set known only to one player.
Where Pith is reading between the lines
- Because the inner loop is an exact LQR solver, the approach may extend to cases with continuous payoff uncertainty if the belief can be discretized or represented parametrically.
- The 10 Hz rate on modest hardware suggests that the scheme could be embedded in robotic or autonomous systems that must plan against opponents whose objectives are only partially known.
- Replacing the inner LQR with a learned value function approximator might allow scaling to higher-dimensional or continuous-time settings while preserving the outer signaling optimization.
Load-bearing premise
The atomic structure of the Nash equilibrium previously identified for general nonlinear games continues to hold exactly in the linear-quadratic case, so that the bi-level formulation captures the full equilibrium without additional hidden constraints or discretization artifacts.
What would settle it
On any small instance of the homing game for which an independent numerical solver or exhaustive search returns a strategy whose expected payoff for the informed player exceeds the value obtained by the bi-level optimizer, the completeness of the formulation would be refuted.
Figures


read the original abstract
We study finite-horizon two-player zero-sum differential games with one-sided payoff information ($G$), where the informed player (P1) knows the game payoff, while P2 only has a public belief over a finite set of possible payoffs. In this case, P1's Nash equilibrium (NE) behavioral strategy may control the release of the type information or even resort to manipulate P2's belief. Previous studies revealed an atomic structure of the NE of $G$ with general nonlinear dynamics and payoffs, leading to tractable NE approximation. Implementing such approximation schemes for real-time sub-game solving, however, has not been achieved, yet is desired for applications where sim-to-real gaps exist and robust control is required. This paper improves the computational efficiency of sub-game solving for P1 during $G$ with linear dynamics and quadratic losses. Specifically, we show that P1's NE computation can be formulated as a bi-level optimization problem where the outer level optimizes the "signaling" strategy, i.e., when and how to reveal information through control, and the inner level is a game-tree LQR that solves for the optimal closed-loop control. This bi-level problem is solved via an adjoint-enabled backpropagation scheme: A "backward" LQR pass is followed by a "forward" gradient descent pass for improving the signaling. We apply the proposed algorithm to approximate NEs for variants of a homing problem with a 8D state space, 2D action spaces, and a discrete time horizon of $K=10$. The algorithm achieves $\approx$10Hz sub-game solving, enabling robust game-theoretic planning under information asymmetry and random disturbances.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for finite-horizon two-player zero-sum linear-quadratic differential games with one-sided information, the informed player's (P1) Nash equilibrium behavioral strategy can be exactly recast as a bi-level optimization: the outer level optimizes the signaling strategy (when and how to reveal type information via control), while the inner level solves a game-tree LQR for optimal closed-loop controls. This bi-level problem is solved via an adjoint-enabled backpropagation scheme (backward LQR pass followed by forward gradient descent on signaling parameters). The method is demonstrated on variants of an 8D homing problem with 2D actions and discrete horizon K=10, achieving approximately 10 Hz sub-game solving rates.
Significance. If the bi-level recasting is exact and the computed strategies satisfy the original equilibrium conditions, the work would provide a practical, real-time method for approximating NE strategies under information asymmetry in LQ settings. This is significant for robust control applications with sim-to-real gaps, as the adjoint backpropagation enables efficient sub-game solving without requiring full nonlinear optimization at runtime. The computational speed on 8D problems is a concrete strength.
major comments (3)
- [Main theoretical formulation (bi-level reduction)] The central claim that P1's NE reduces exactly to the stated bi-level optimization (outer signaling + inner game-tree LQR) rests on the atomic NE structure from prior nonlinear studies holding without modification for linear dynamics and quadratic costs. No derivation or appendix is supplied showing that the quadratic value functions and linear dynamics introduce no additional belief-manipulation constraints, hidden saddle conditions, or non-atomic equilibria that the bi-level would miss.
- [Numerical experiments and results] The numerical results report ~10 Hz on 8D homing examples but supply no error bars across runs, baseline comparisons against other approximation methods, convergence guarantees for the gradient descent on signaling, or explicit verification (e.g., saddle-point residual checks or unilateral deviation tests) that the output strategies satisfy the original game equilibrium conditions.
- [Problem setup and discretization] The discretization to K=10 and the specific homing problem setup may mask potential gaps in the bi-level formulation; the manuscript should include a sensitivity analysis or counter-example check confirming that the atomic structure assumption continues to hold exactly under LQ payoffs.
minor comments (2)
- [Abstract] The abstract introduces the game as 'G' without an immediate definition; define the game and one-sided information setting explicitly on first use.
- [Algorithm description] Clarify the exact form of the adjoint backpropagation (e.g., which variables are differentiated through the inner LQR solve) and any assumptions on differentiability of the value functions.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and valuable feedback on our manuscript. We address each of the major comments below and indicate the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [Main theoretical formulation (bi-level reduction)] The central claim that P1's NE reduces exactly to the stated bi-level optimization (outer signaling + inner game-tree LQR) rests on the atomic NE structure from prior nonlinear studies holding without modification for linear dynamics and quadratic costs. No derivation or appendix is supplied showing that the quadratic value functions and linear dynamics introduce no additional belief-manipulation constraints, hidden saddle conditions, or non-atomic equilibria that the bi-level would miss.
Authors: We thank the referee for highlighting this important aspect. The atomic structure is inherited from our prior work on general nonlinear differential games, where it was shown that the informed player's equilibrium strategy decomposes into a signaling phase and a subsequent control phase without loss of optimality. For the linear-quadratic case, the inner game-tree LQR admits exact closed-form solutions via Riccati equations, and the outer signaling optimization remains unchanged because the belief updates and information revelation occur through the same control channels. No additional saddle conditions or constraints are introduced by the LQ structure, as the quadratic costs ensure convexity in controls. To address the lack of explicit derivation, we will add a concise appendix providing the step-by-step reduction for the LQ setting, confirming the equivalence. revision: yes
-
Referee: [Numerical experiments and results] The numerical results report ~10 Hz on 8D homing examples but supply no error bars across runs, baseline comparisons against other approximation methods, convergence guarantees for the gradient descent on signaling, or explicit verification (e.g., saddle-point residual checks or unilateral deviation tests) that the output strategies satisfy the original game equilibrium conditions.
Authors: We agree that the experimental section can be strengthened with additional reporting and validation. In the revision, we will add error bars computed over multiple independent runs with varied random seeds for initialization. We will include baseline comparisons, such as against a non-signaling strategy (where information is not revealed strategically) and a heuristic signaling approach. Regarding convergence, we will report the gradient norms and objective values over iterations to demonstrate empirical convergence, noting that global optimality is not guaranteed due to non-convexity. For verification, we will perform unilateral deviation tests on selected instances by fixing the signaling and optimizing P2's response, checking that the value does not improve for P2. These additions will be included in the revised numerical results section. revision: yes
-
Referee: [Problem setup and discretization] The discretization to K=10 and the specific homing problem setup may mask potential gaps in the bi-level formulation; the manuscript should include a sensitivity analysis or counter-example check confirming that the atomic structure assumption continues to hold exactly under LQ payoffs.
Authors: The K=10 discretization is chosen to balance computational tractability with demonstration of real-time performance in the 8D state space. We acknowledge that this specific setup might not reveal all potential issues. In the revision, we will include a sensitivity analysis by testing the method on smaller horizons (e.g., K=5) and larger ones where feasible, as well as on a simplified 2D or 4D variant of the homing problem to check consistency. We will also verify the atomic structure by examining whether the computed signaling times align with the expected discrete revelation points. If any deviation from the expected structure is observed, it will be discussed; however, our preliminary checks suggest the assumption holds for the LQ case. revision: partial
Circularity Check
Bi-level formulation for LQ NE inherits atomic structure from prior nonlinear studies without LQ-specific re-derivation
specific steps
-
self citation load bearing
[Abstract]
"Previous studies revealed an atomic structure of the NE of G with general nonlinear dynamics and payoffs, leading to tractable NE approximation. [...] we show that P1's NE computation can be formulated as a bi-level optimization problem where the outer level optimizes the signaling strategy, i.e., when and how to reveal information through control, and the inner level is a game-tree LQR that solves for the optimal closed-loop control."
The claim that the NE can be exactly recast as this specific bi-level problem for the linear-quadratic case is presented as following directly from the atomic structure identified in prior work. No separate derivation or proof is given that linear dynamics and quadratic payoffs introduce no additional belief-manipulation constraints or non-atomic equilibria that would invalidate the bi-level reduction; the formulation therefore reduces to the cited prior result rather than being derived from first principles within the LQ setting.
full rationale
The paper's core contribution is recasting P1's NE as an outer signaling optimization plus inner game-tree LQR, solved by adjoint backpropagation. This algorithmic step is self-contained and does not reduce to a fit or self-definition within the present text. However, the load-bearing premise that the NE admits exactly this atomic decomposition (allowing the bi-level to capture the equilibrium without extra saddle constraints) is imported from previous studies on general nonlinear dynamics. No derivation is supplied showing the structure survives unchanged under linear dynamics and quadratic costs, so the correctness of the claimed NE approximation depends on that external assumption rather than being independently established here. This produces moderate circularity but leaves the computational method itself independent.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The atomic structure of Nash equilibria established for general nonlinear differential games with one-sided information continues to hold for the linear-quadratic case.
Reference graph
Works this paper leans on
-
[1]
Design and analysis of state-feedback optimal strategies for the differential game of active defense,
E. Garcia, D. W. Casbeer, and M. Pachter, “Design and analysis of state-feedback optimal strategies for the differential game of active defense,”IEEE Transactions on Automatic Control, vol. 64, no. 2, pp. 553–568, 2018
2018
-
[2]
The complete differential game of active target defense,
E. Garcia, D. W. Casbeer, and M. Pachter, “The complete differential game of active target defense,”Journal of Optimization Theory and Applications, vol. 191, no. 2, pp. 675–699, 2021
2021
-
[3]
A differential game for cooperative target defense,
L. Liang, F. Deng, Z. Peng, X. Li, and W. Zha, “A differential game for cooperative target defense,”Automatica, vol. 102, pp. 58–71, 2019
2019
-
[4]
Optimal strategies for detecting data exfiltration by internal and external attackers,
K. Durkota, V . Lis `y, C. Kiekintveld, K. Hor ´ak, B. Bo ˇsansk`y, and T. Pevn`y, “Optimal strategies for detecting data exfiltration by internal and external attackers,” inInternational Conference on Decision and Game Theory for Security, pp. 171–192, Springer, 2017
2017
-
[5]
Data exfiltration detection and prevention: Virtually distributed pomdps for practically safer networks,
S. M. Mc Carthy, A. Sinha, M. Tambe, and P. Manadhata, “Data exfiltration detection and prevention: Virtually distributed pomdps for practically safer networks,” inInternational Conference on Decision and Game Theory for Security, pp. 39–61, Springer, 2016
2016
-
[6]
A point-based approximate algorithm for one-sided partially observable pursuit-evasion games,
K. Hor ´ak and B. Bo ˇsansk`y, “A point-based approximate algorithm for one-sided partially observable pursuit-evasion games,” inInternational conference on decision and game theory for security, pp. 435–454, Springer, 2016
2016
-
[7]
Flipit: The game of “stealthy takeover
M. Van Dijk, A. Juels, A. Oprea, and R. L. Rivest, “Flipit: The game of “stealthy takeover”,”Journal of Cryptology, vol. 26, no. 4, pp. 655– 713, 2013
2013
-
[8]
Continuous auctions and insider trading,
A. S. Kyle, “Continuous auctions and insider trading,”Econometrica: Journal of the Econometric Society, pp. 1315–1335, 1985
1985
-
[9]
Insider trading in continuous time,
K. Back, “Insider trading in continuous time,”The Review of Financial Studies, vol. 5, no. 3, pp. 387–409, 1992
1992
-
[10]
Market manipulation: An adversarial learning framework for detection and evasion,
X. Wang and M. P. Wellman, “Market manipulation: An adversarial learning framework for detection and evasion,” in29th International Joint Conference on Artificial Intelligence, 2020
2020
-
[11]
Solving football by exploiting equilibrium structure of 2p0s differential games with one- sided information,
M. Ghimire, L. Zhang, Z. Xu, and Y . Ren, “Solving football by exploiting equilibrium structure of 2p0s differential games with one- sided information,” 2025
2025
-
[12]
State-constrained zero- sum differential games with one-sided information,
M. Ghimire, L. Zhang, Z. Xu, and Y . Ren, “State-constrained zero- sum differential games with one-sided information,” inForty-first International Conference on Machine Learning
-
[13]
Games with incomplete information played by “bayesian
J. C. Harsanyi, “Games with incomplete information played by “bayesian” players, i–iii part i. the basic model,”Management science, vol. 14, no. 3, pp. 159–182, 1967
1967
-
[14]
R. J. Aumann, M. Maschler, and R. E. Stearns,Repeated games with incomplete information. MIT press, 1995
1995
-
[15]
Differential games with asymmetric information,
P. Cardaliaguet, “Differential games with asymmetric information,” SIAM journal on Control and Optimization, vol. 46, no. 3, pp. 816– 838, 2007
2007
-
[16]
Numerical approximation and optimal strategies for differential games with lack of information on one side,
P. Cardaliaguet, “Numerical approximation and optimal strategies for differential games with lack of information on one side,”Advances in Dynamic Games and Their Applications: Analytical and Numerical Developments, pp. 1–18, 2009
2009
-
[17]
A differential game of incomplete information,
G. Hexner, “A differential game of incomplete information,”Journal of Optimization Theory and Applications, vol. 28, pp. 213–232, 1979
1979
-
[18]
R. J. Elliott and N. J. Kalton,The existence of value in differential games, vol. 126. American Mathematical Soc., 1972
1972
-
[19]
Differen- tiable mpc for end-to-end planning and control,
B. Amos, I. Jimenez, J. Sacks, B. Boots, and J. Z. Kolter, “Differen- tiable mpc for end-to-end planning and control,”Advances in neural information processing systems, vol. 31, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.