Recognition: 2 theorem links
· Lean TheoremIn-Sample Evaluation of Subgroups Identified by Generic Machine Learning
Pith reviewed 2026-05-08 17:44 UTC · model grok-4.3
The pith
Conditional adaptive perturbation removes selection bias for valid in-sample evaluation of machine learning-identified subgroups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a conditional adaptive perturbation approach to remove selection bias in in-sample subgroup evaluation and deliver valid inference on subgroups identified from the whole dataset by generic machine learning, regardless of whether regularity is satisfied. The proposed method is easy-to-compute, allows model-free and even black-box subgroup identification, and achieves full efficiency across broad scenarios of subgroup analysis through a novel theoretical framework of triple robustness linking rates of subgroup identification and nuisance estimation.
What carries the argument
The conditional adaptive perturbation approach, which adjusts the evaluation statistic by perturbing data conditionally on the identified subgroup to cancel out selection bias from potentially nonsmooth, data-dependent boundaries.
If this is right
- Valid confidence intervals and hypothesis tests for subgroup-specific effects become available using the entire sample.
- Subgroup identification can proceed with arbitrary machine learning procedures, without smoothness or regularity assumptions on boundaries.
- Full statistical efficiency is attained whenever the convergence rates of identification and nuisance estimation satisfy the triple robustness conditions.
- Re-analyses of existing datasets become feasible for data-driven subgroups without requiring sample splitting or new data collection.
Where Pith is reading between the lines
- The perturbation idea could extend to other post-selection settings, such as evaluating clusters or rules discovered by machine learning algorithms.
- In applied domains like clinical trials, the method supports more powerful detection of heterogeneous treatment effects within data-identified patient groups.
- Practical checks could include verifying robustness when subgroup identification and outcome models are estimated jointly from high-dimensional covariates.
Load-bearing premise
The triple robustness framework linking rates of subgroup identification and nuisance estimation holds across broad scenarios, including when subgroup identification uses black-box methods with potentially nonsmooth boundaries.
What would settle it
A simulation study with known nonsmooth subgroup boundaries where the proposed method's confidence intervals fail to achieve nominal coverage or exhibit bias in effect estimates would falsify the claim of valid inference.
Figures

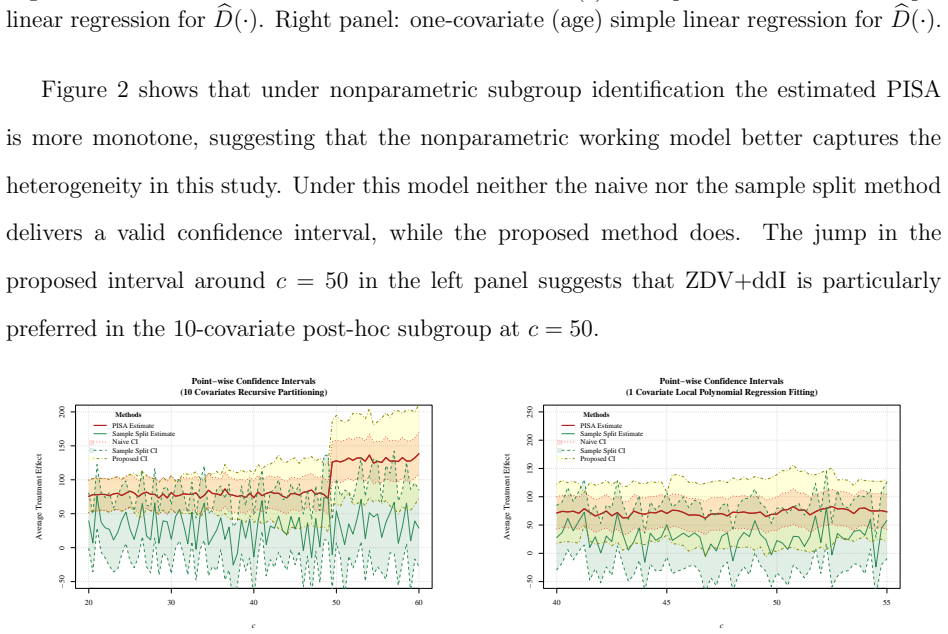
read the original abstract
When a subgroup is identified from the data, it must be evaluated in a replicable way. The usual in-sample approach, which evaluates the post-hoc identified subgroup as predefined, might suffer from selection bias. This issue of in-sample evaluation of data-dependent objects is well recognized but particularly challenging here. Unlike discrete or finite-dimensional data-dependent objects addressed before, the selection bias here is induced by post-hoc identified subgroups, data-dependent sets potentially defined by infinite-dimensional functionals with nonsmooth boundaries known as nonregularity. The out-of-sample approach, which splits data for subgroup identification and evaluation, can help address selection bias but might suffer from efficiency loss and instability. In this paper, we propose a conditional adaptive perturbation approach to remove selection bias in in-sample subgroup evaluation and deliver valid inference on subgroups identified from the whole dataset by generic machine learning, regardless of whether regularity is satisfied. The proposed method is easy-to-compute, allows model-free and even black-box subgroup identification, and achieves full efficiency across broad scenarios of subgroup analysis through a novel theoretical framework of triple robustness linking rates of subgroup identification and nuisance estimation. The merits of the proposed method are demonstrated by a re-analysis of the ACTG 175 trial.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a conditional adaptive perturbation approach for in-sample evaluation of subgroups identified from the full dataset by generic (including black-box) machine learning methods. It claims to remove selection bias induced by post-hoc subgroup identification—particularly in nonregular settings with nonsmooth boundaries—while delivering valid inference and full efficiency. The key innovation is a triple-robustness framework that links the convergence rates of the subgroup identification step and nuisance estimators. The method is illustrated via re-analysis of the ACTG 175 trial.
Significance. If the triple-robustness construction holds under the stated conditions, this would represent a meaningful advance in post-selection inference for subgroup analysis. It would allow full-sample use for both identification and evaluation without the efficiency and stability penalties of data splitting, while accommodating arbitrary ML procedures. This has clear relevance for clinical trials and personalized medicine applications where subgroup discovery is routine. The empirical re-analysis provides useful practical validation.
major comments (2)
- [Abstract] Abstract: The central claim that the method works 'regardless of whether regularity is satisfied' for 'generic machine learning' (including black-box methods with potentially nonsmooth boundaries) is load-bearing but requires explicit rate conditions. The triple-robustness expansion for bias removal implicitly depends on the subgroup identification error converging at a rate compatible with the nuisance estimators; arbitrary ML procedures may violate this (e.g., via inconsistency or arbitrarily slow rates), so the 'regardless' phrasing is not yet secured. Please state the precise rate requirements in the main theorem and discuss their checkability for black-box identifiers.
- [Theoretical framework] Theoretical framework (main results section): The conditional adaptive perturbation's construction and the order at which the selection bias term vanishes need to be verified against the nonregularity case. Without an explicit asymptotic expansion or lemma showing how the perturbation adapts to the identification error rate, it is difficult to confirm that full efficiency is retained when regularity fails. This directly affects the claimed generality.
minor comments (2)
- [Abstract] The abstract would benefit from a one-sentence statement of the minimal rate conditions needed for the triple-robustness property to hold.
- [Methods] Notation for the adaptive perturbation parameter and the subgroup indicator should be introduced with a clear definition table or equation reference early in the methods.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the presentation of the rate conditions and theoretical framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the method works 'regardless of whether regularity is satisfied' for 'generic machine learning' (including black-box methods with potentially nonsmooth boundaries) is load-bearing but requires explicit rate conditions. The triple-robustness expansion for bias removal implicitly depends on the subgroup identification error converging at a rate compatible with the nuisance estimators; arbitrary ML procedures may violate this (e.g., via inconsistency or arbitrarily slow rates), so the 'regardless' phrasing is not yet secured. Please state the precise rate requirements in the main theorem and discuss their checkability for black-box identifiers.
Authors: We agree that the abstract phrasing 'regardless of whether regularity is satisfied' for generic ML could be misinterpreted without reference to the rate conditions. Theorem 1 in the main text already states the precise requirements: the subgroup identification error rate r_n must satisfy r_n = o_p(n^{-1/4}) (or more generally be compatible with the nuisance estimator rates s_n such that r_n s_n = o_p(n^{-1/2})) for the triple-robustness property to hold and remove the selection bias. These rates are checkable for black-box identifiers via known convergence results in the ML literature (e.g., for random forests or neural nets under suitable assumptions) or via data-driven validation. We will revise the abstract to explicitly reference these rate conditions from the main theorem. revision: yes
-
Referee: [Theoretical framework] Theoretical framework (main results section): The conditional adaptive perturbation's construction and the order at which the selection bias term vanishes need to be verified against the nonregularity case. Without an explicit asymptotic expansion or lemma showing how the perturbation adapts to the identification error rate, it is difficult to confirm that full efficiency is retained when regularity fails. This directly affects the claimed generality.
Authors: The conditional adaptive perturbation is constructed in Section 2.2 to condition on the estimated subgroup boundary, with the perturbation size chosen adaptively to match the identification error scale. In the nonregular case, the selection bias term vanishes at rate o_p(n^{-1/2}) under the triple-robustness condition linking the identification and nuisance rates, as shown via the asymptotic expansion in the proof of Theorem 1 (detailed in the supplementary material). We will add a short remark and reference to the key expansion steps in the main results section to make the adaptation to nonregularity more explicit without altering the existing framework. revision: yes
Circularity Check
No circularity: derivation self-contained via novel triple-robustness framework
full rationale
The paper introduces a conditional adaptive perturbation method justified by a new triple-robustness construction that explicitly links rates of subgroup identification (including black-box ML) to nuisance estimation rates, delivering valid in-sample inference without requiring regularity. No equations or steps in the provided abstract reduce a claimed prediction or result to a fitted parameter, self-citation, or definitional tautology; the central claim is presented as following from the proposed framework rather than from re-labeling inputs or prior self-referential results. The derivation therefore stands as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Subgroup identification and nuisance estimators satisfy rate conditions that enable the triple robustness property.
Reference graph
Works this paper leans on
-
[1]
C. K. Chow and C. N. Liu , title =. IEEE Transactions on Information Theory , year =
-
[2]
1988 , address =
Judea Pearl , title =. 1988 , address =
1988
-
[3]
Biometrika , volume=
Network cross-validation by edge sampling , author=. Biometrika , volume=. 2020 , publisher=
2020
-
[4]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
AdaPT: an interactive procedure for multiple testing with side information , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2018 , publisher=
2018
-
[5]
Berrendero, J. R. and Cuevas, A. and Torrecilla, J L. , title =
-
[6]
2025 , note =
R: A Language and Environment for Statistical Computing , author =. 2025 , note =
2025
-
[7]
D. R. Cox , Journal =
-
[8]
and Holmes, Christopher C
Heard, Nicholas A. and Holmes, Christopher C. and Stephens, David A. , Journal =. A Quantitative Study of Gene Regulation Involved in the Immune Response of
-
[9]
2024 , publisher=
A first course in causal inference , author=. 2024 , publisher=
2024
-
[10]
Journal of Machine Learning Research , volume=
Selective inference with distributed data , author=. Journal of Machine Learning Research , volume=
-
[11]
arXiv preprint arXiv:2503.24311 , year=
Selective inference in graphical models via maximum likelihood , author=. arXiv preprint arXiv:2503.24311 , year=
-
[12]
arXiv preprint arXiv:2305.04852 , year=
Isotonic subgroup selection , author=. arXiv preprint arXiv:2305.04852 , year=
-
[13]
Optimal inference after model selection.arXiv preprint arXiv:1410.2597, 2014
Optimal inference after model selection , author=. arXiv preprint arXiv:1410.2597 , year=
-
[14]
The Annals of Statistics , volume=
Exact post-selection inference, with application to the lasso , author=. The Annals of Statistics , volume=
-
[15]
A Historical View of Subgroup Performance Differences on the
Kobrin, Jennifer L and Sathy, Viji and Shaw, Emily J , journal=. A Historical View of Subgroup Performance Differences on the. 2007 , publisher=
2007
-
[16]
Journal of the American Statistical Association , volume=
Efficient estimation of the Cox model with auxiliary subgroup survival information , author=. Journal of the American Statistical Association , volume=. 2016 , publisher=
2016
-
[17]
Nursing Research , volume=
Detecting and explicating interactions in categorical data , author=. Nursing Research , volume=. 2000 , publisher=
2000
-
[18]
2000 , publisher=
Asymptotic statistics , author=. 2000 , publisher=
2000
-
[19]
arXiv preprint arXiv:2102.11338 , year=
Sharp inference on selected subgroups in observational studies , author=. arXiv preprint arXiv:2102.11338 , year=
-
[20]
The Annals of Statistics , volume=
Optimal subgroup selection , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
-
[21]
Econometrica , volume=
On the failure of the bootstrap for matching estimators , author=. Econometrica , volume=. 2008 , publisher=
2008
-
[22]
Biometrika , pages=
On the failure of the bootstrap for Chatterjee's rank correlation , author=. Biometrika , pages=. 2024 , publisher=
2024
-
[23]
Kubota, K and Ichinose, Y and Scagliotti, G and Spigel, D and Kim, JH and Shinkai, T and Takeda, K and Kim, S-W and Hsia, T-C and Li, RK and others , journal=. Phase. 2014 , publisher=
2014
-
[24]
Kubota, Kaoru and Yoshioka, Hiroshige and Oshita, Fumihiro and Hida, Toyoaki and Yoh, Kiyotaka and Hayashi, Hidetoshi and Kato, Terufumi and Kaneda, Hiroyasu and Yamada, Kazuhiko and Tanaka, Hiroshi and others , journal=. Phase. 2017 , publisher=
2017
-
[25]
Generic machine learning inference on heterogeneous treatment effects in randomized experiments, with an application to immunization in
Chernozhukov, Victor and Demirer, Mert and Duflo, Esther and Fernandez-Val, Ivan , year=. Generic machine learning inference on heterogeneous treatment effects in randomized experiments, with an application to immunization in
-
[26]
Statistics in medicine , volume=
Subgroup identification based on differential effect search---a recursive partitioning method for establishing response to treatment in patient subpopulations , author=. Statistics in medicine , volume=. 2011 , publisher=
2011
-
[27]
Computational Statistics & Data Analysis , volume=
Subgroup analysis for heterogeneous additive partially linear models and its application to car sales data , author=. Computational Statistics & Data Analysis , volume=. 2019 , publisher=
2019
-
[28]
Proceedings of the conference on fairness, accountability, and transparency , pages=
An empirical study of rich subgroup fairness for machine learning , author=. Proceedings of the conference on fairness, accountability, and transparency , pages=
-
[29]
arXiv preprint arXiv:2306.17464 , year=
Minimax optimal subgroup identification , author=. arXiv preprint arXiv:2306.17464 , year=
-
[30]
New England Journal of Medicine , volume=
Maraviroc for previously treated patients with R5 HIV-1 infection , author=. New England Journal of Medicine , volume=. 2008 , publisher=
2008
-
[31]
2010 , publisher=
Bayesian adaptive methods for clinical trials , author=. 2010 , publisher=
2010
-
[32]
Journal of the royal statistical society: Series b (statistical methodology) , volume=
Bayesian measures of model complexity and fit , author=. Journal of the royal statistical society: Series b (statistical methodology) , volume=. 2002 , publisher=
2002
-
[33]
AMIA Summits on Translational Science Proceedings , volume=
Predicting clinical outcomes with patient stratification via deep mixture neural networks , author=. AMIA Summits on Translational Science Proceedings , volume=. 2020 , publisher=
2020
-
[34]
Electronics , volume=
A state-of-the-art survey on deep learning theory and architectures , author=. Electronics , volume=. 2019 , publisher=
2019
-
[35]
Bmj , volume=
Credibility of claims of subgroup effects in randomised controlled trials: systematic review , author=. Bmj , volume=. 2012 , publisher=
2012
-
[36]
Bernoulli , volume=
Stability , author=. Bernoulli , volume=
-
[37]
Econometrica: Journal of the Econometric Society , pages=
The asymptotic variance of semiparametric estimators , author=. Econometrica: Journal of the Econometric Society , pages=. 1994 , publisher=
1994
-
[38]
Central limit theorems and bootstrap in high dimensions , author=
-
[39]
Econometrics and Statistics , year=
A Robust Quantitative Risk Screening for Subgroup Pursuit in Clinical Trials , author=. Econometrics and Statistics , year=
-
[40]
Selection bias at the heterosexual
Carlson, Jonathan M and Schaefer, Malinda and Monaco, Daniela C and Batorsky, Rebecca and Claiborne, Daniel T and Prince, Jessica and Deymier, Martin J and Ende, Zachary S and Klatt, Nichole R and DeZiel, Charles E and others , journal=. Selection bias at the heterosexual. 2014 , publisher=
2014
-
[41]
Lancet HIV , volume=
Preconception ART and preterm birth: real effect or selection bias , author=. Lancet HIV , volume=
-
[42]
Epidemiology , volume=
Timing of initiation of antiretroviral therapy and risk of preterm birth in studies of HIV-infected pregnant women: the role of selection bias , author=. Epidemiology , volume=. 2018 , publisher=
2018
-
[43]
arXiv preprint arXiv:1801.09138 , year=
Cross-fitting and fast remainder rates for semiparametric estimation , author=. arXiv preprint arXiv:1801.09138 , year=
-
[44]
Annals of the Institute of Statistical Mathematics , volume=
Local polynomial regression: optimal kernels and asymptotic minimax efficiency , author=. Annals of the Institute of Statistical Mathematics , volume=. 1997 , publisher=
1997
-
[45]
1990 , publisher=
Spline models for observational data , author=. 1990 , publisher=
1990
-
[46]
Machine learning , volume=
Random forests , author=. Machine learning , volume=. 2001 , publisher=
2001
-
[47]
2006 , publisher=
A distribution-free theory of nonparametric regression , author=. 2006 , publisher=
2006
-
[48]
Statistics in Medicine , volume=
Inference on tree-structured subgroups with subgroup size and subgroup effect relationship in clinical trials , author=. Statistics in Medicine , volume=. 2023 , publisher=
2023
-
[49]
The annals of Statistics , volume=
Analyzing bagging , author=. The annals of Statistics , volume=. 2002 , publisher=
2002
-
[50]
Assessing the most vulnerable subgroup to type
Guo, Xinzhou and Wei, Waverly and Liu, Molei and Cai, Tianxi and Wu, Chong and Wang, Jingshen , journal=. Assessing the most vulnerable subgroup to type. 2023 , publisher=
2023
-
[51]
arXiv preprint arXiv:2007.02852 , year=
Cross-fitting and averaging for machine learning estimation of heterogeneous treatment effects , author=. arXiv preprint arXiv:2007.02852 , year=
-
[52]
Wiley interdisciplinary reviews: data mining and knowledge discovery , volume=
Classification and regression trees , author=. Wiley interdisciplinary reviews: data mining and knowledge discovery , volume=. 2011 , publisher=
2011
-
[53]
Journal of Computational and Graphical Statistics , volume=
Model-based recursive partitioning , author=. Journal of Computational and Graphical Statistics , volume=. 2008 , publisher=
2008
-
[54]
Proceedings of the National Academy of Sciences , volume=
Recursive partitioning for heterogeneous causal effects , author=. Proceedings of the National Academy of Sciences , volume=. 2016 , publisher=
2016
-
[55]
The lancet HIV , volume=
Use of electronic health record data and machine learning to identify candidates for HIV pre-exposure prophylaxis: a modelling study , author=. The lancet HIV , volume=. 2019 , publisher=
2019
-
[56]
Bmj , volume=
Is a subgroup effect believable? Updating criteria to evaluate the credibility of subgroup analyses , author=. Bmj , volume=. 2010 , publisher=
2010
-
[57]
Statistical models in S , pages=
Local regression models , author=. Statistical models in S , pages=. 2017 , publisher=
2017
-
[58]
1990 , organization=
Empirical processes: theory and applications , author=. 1990 , organization=
1990
-
[59]
New England Journal of Medicine , volume=
Statistics in medicine---reporting of subgroup analyses in clinical trials , author=. New England Journal of Medicine , volume=. 2007 , publisher=
2007
-
[60]
Pharmaceutical statistics , volume=
Model averaging for treatment effect estimation in subgroups , author=. Pharmaceutical statistics , volume=. 2017 , publisher=
2017
-
[61]
Biometrika , volume=
Optimal post-selection inference for sparse signals: a nonparametric empirical Bayes approach , author=. Biometrika , volume=. 2022 , publisher=
2022
-
[62]
Can one estimate the conditional distribution of post-model-selection estimators? , author=
-
[63]
Econometrica , volume=
Impossibility results for nondifferentiable functionals , author=. Econometrica , volume=. 2012 , publisher=
2012
-
[64]
Journal of the Royal statistical society: series B (Methodological) , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal statistical society: series B (Methodological) , volume=. 1995 , publisher=
1995
-
[65]
Annals of statistics , pages=
The control of the false discovery rate in multiple testing under dependency , author=. Annals of statistics , pages=. 2001 , publisher=
2001
-
[66]
The annals of statistics , pages=
Optimal global rates of convergence for nonparametric regression , author=. The annals of statistics , pages=. 1982 , publisher=
1982
-
[67]
Biometrika , volume=
Doubly robust learning for estimating individualized treatment with censored data , author=. Biometrika , volume=. 2015 , publisher=
2015
-
[68]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Non-parametric methods for doubly robust estimation of continuous treatment effects , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2017 , publisher=
2017
-
[69]
Statistics in medicine , volume=
Qualitative interaction trees: a tool to identify qualitative treatment--subgroup interactions , author=. Statistics in medicine , volume=. 2014 , publisher=
2014
-
[70]
BMC bioinformatics , volume=
Bias in random forest variable importance measures: Illustrations, sources and a solution , author=. BMC bioinformatics , volume=. 2007 , publisher=
2007
-
[71]
Biometrics , volume=
Doubly robust estimation in missing data and causal inference models , author=. Biometrics , volume=. 2005 , publisher=
2005
-
[72]
The Lancet , volume=
Can overall results of clinical trials be applied to all patients? , author=. The Lancet , volume=. 1995 , publisher=
1995
-
[73]
Journal of the American Medical Informatics Association , volume=
Deep significance clustering: a novel approach for identifying risk-stratified and predictive patient subgroups , author=. Journal of the American Medical Informatics Association , volume=. 2021 , publisher=
2021
-
[74]
Biometrics , volume=
A general statistical framework for subgroup identification and comparative treatment scoring , author=. Biometrics , volume=. 2017 , publisher=
2017
-
[75]
The Annals of Probability , volume=
Conditional distributions as derivatives , author=. The Annals of Probability , volume=. 1979 , publisher=
1979
-
[76]
The Annals of Probability , pages=
Convergence in distribution of conditional expectations , author=. The Annals of Probability , pages=. 1994 , publisher=
1994
-
[77]
Journal of Clinical and Translational Science , volume=
318 Discovering Subgroups with Supervised Machine Learning Models for Heterogeneity of Treatment Effect Analysis , author=. Journal of Clinical and Translational Science , volume=. 2024 , publisher=
2024
-
[78]
arXiv preprint arXiv:2207.07781 , year=
Subgroup discovery in unstructured data , author=. arXiv preprint arXiv:2207.07781 , year=
-
[79]
Trials , volume=
No improvement in the reporting of clinical trial subgroup effects in high-impact general medical journals , author=. Trials , volume=. 2016 , publisher=
2016
-
[80]
The Annals of Statistics , volume=
Selective inference with a randomized response , author=. The Annals of Statistics , volume=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.