Recognition: 2 theorem links
NucEval: A Robust Evaluation Framework for Nuclear Instance Segmentation
Pith reviewed 2026-05-08 18:30 UTC · model grok-4.3
The pith
NucEval integrates four fixes to produce more reliable scores for nuclear instance segmentation in pathology images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
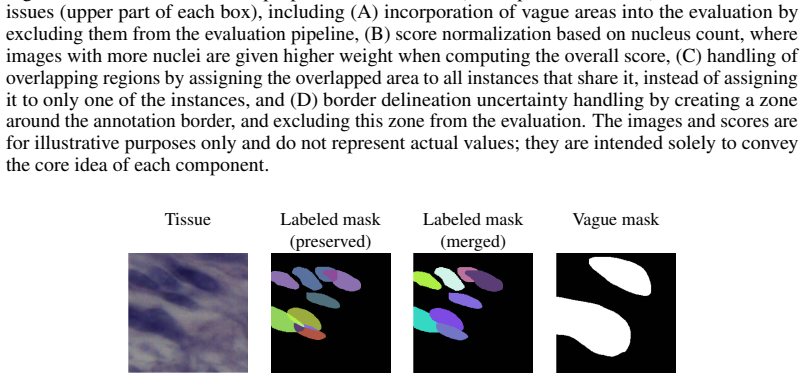
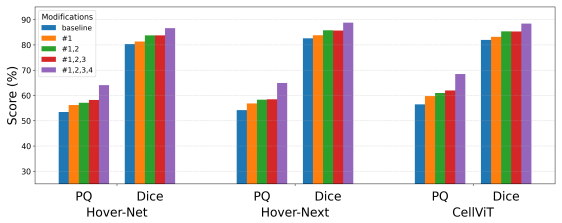
The central claim is that handling vague regions, applying score normalization, accounting for overlapping instances, and addressing border uncertainty within a single framework enables robust evaluation of nuclear instance segmentation. The authors integrate these into NucEval and demonstrate its effects on metrics using multiple datasets and models.
What carries the argument
NucEval, the unified framework that incorporates modifications for vague regions, score normalization, overlapping instances, and border uncertainty to improve evaluation robustness.
If this is right
- Metrics from existing methods may change significantly when these issues are addressed.
- Relative performance of CNN and ViT models can shift under the new evaluation.
- The framework provides a standardized way to assess segmentation on datasets with inherent ambiguities.
- Code release allows researchers to apply consistent evaluation across studies.
Where Pith is reading between the lines
- This evaluation approach could become a default standard for pathology segmentation benchmarks.
- It highlights the need for segmentation models to explicitly manage image ambiguities rather than relying on post-hoc fixes.
- Similar modifications might apply to evaluating instance segmentation in other medical imaging contexts like tumor detection.
Load-bearing premise
The four issues identified are the main sources of inconsistency in current evaluation methods, and fixing them does not introduce new biases.
What would settle it
Direct comparison of model rankings using standard metrics versus NucEval on a held-out dataset where human experts rate the quality of segmentations in ambiguous areas.
Figures




read the original abstract
In computational pathology, nuclear instance segmentation is a fundamental task with many downstream clinical applications. With the advent of deep learning, many approaches, including convolutional neural networks (CNNs) and vision transformers (ViTs), have been proposed for this task, along with both machine learning-based and non-machine learning-based pre- and post-processing techniques to further boost performance. However, one fundamental aspect that has received less attention is the evaluation pipeline. In this study, we identify four key issues associated with nuclear instance segmentation evaluation and propose corresponding solutions. Our proposed modifications, namely handling vague regions, score normalization, overlapping instances, and border uncertainty, are integrated into a unified framework called NucEval, which enables robust evaluation of nuclear instance segmentation. We evaluate this pipeline using the NuInsSeg dataset, which provides unique characteristics that make it particularly suitable for this study, as well as two additional external datasets, with three CNN- and ViT-based nuclear instance segmentation models, to demonstrate the impact of these modifications on instance segmentation metrics. The code, along with complete guidelines and illustrative examples, is publicly available at: https://github.com/masih4/nuc_eval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NucEval, a unified evaluation framework for nuclear instance segmentation that extends standard metrics to address four domain-specific issues: handling vague regions, score normalization, overlapping instances, and border uncertainty. The authors define explicit implementation rules for each modification, apply the framework to the NuInsSeg dataset (chosen for its unique characteristics) plus two external datasets, and report resulting shifts in instance segmentation metrics across three CNN- and ViT-based models. Public code, guidelines, and examples are provided at the linked GitHub repository.
Significance. If the modifications produce demonstrably more robust evaluations without new inconsistencies, the work could improve the reliability of model comparisons in computational pathology, where nuclear segmentation supports downstream clinical tasks. The public release of code and illustrative examples is a clear strength that supports reproducibility and adoption.
major comments (2)
- [results/experiments] The central claim that the four modifications yield a more robust pipeline rests on reported metric shifts, but the manuscript does not include statistical significance testing or variance estimates across multiple runs or cross-validation folds; this weakens the ability to conclude that observed differences reflect genuine robustness gains rather than dataset-specific noise (results section).
- [evaluation framework] While ablations are mentioned, the paper does not quantify whether the combined framework introduces any systematic bias relative to expert-annotated ground truth on the adjusted cases (e.g., vague regions or border uncertainty); a direct comparison table against unmodified metrics on a held-out expert subset would strengthen the no-new-bias claim.
minor comments (3)
- [abstract] The abstract lists the four issues but does not briefly define each; adding one-sentence definitions would improve accessibility for readers outside computational pathology.
- [methods] Notation for the modified metrics (e.g., how score normalization is applied to IoU or F1) should be introduced with explicit equations in the methods section to avoid ambiguity when readers implement the public code.
- [figures] Figure captions describing qualitative examples of the four modifications could be expanded to explicitly link visual changes to the quantitative metric shifts reported in the tables.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment below, indicating the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [results/experiments] The central claim that the four modifications yield a more robust pipeline rests on reported metric shifts, but the manuscript does not include statistical significance testing or variance estimates across multiple runs or cross-validation folds; this weakens the ability to conclude that observed differences reflect genuine robustness gains rather than dataset-specific noise (results section).
Authors: We agree that statistical significance testing and variance estimates would strengthen the evidence that the observed metric shifts reflect genuine robustness improvements. In the revised manuscript, we will add paired statistical tests (e.g., Wilcoxon signed-rank tests) comparing original and NucEval metrics across the three models and datasets, along with reported p-values. We will also include variance estimates by computing standard deviations across the multiple datasets and models, and note consistency of shifts to mitigate concerns about dataset-specific noise. Additional runs with varied seeds will be performed where computationally feasible to provide further error estimates. revision: yes
-
Referee: [evaluation framework] While ablations are mentioned, the paper does not quantify whether the combined framework introduces any systematic bias relative to expert-annotated ground truth on the adjusted cases (e.g., vague regions or border uncertainty); a direct comparison table against unmodified metrics on a held-out expert subset would strengthen the no-new-bias claim.
Authors: We thank the referee for highlighting the need to explicitly verify absence of systematic bias. The NuInsSeg dataset was chosen for its annotations that explicitly mark vague regions and border uncertainty, which our framework directly incorporates. In the revision, we will add a comparison table contrasting modified versus unmodified metrics specifically on the subsets involving these adjustments, using the provided expert ground truth to demonstrate that changes correct for the identified issues without introducing new bias. A fully independent held-out expert subset with re-annotations is not available in the current datasets, but the existing annotations permit this targeted validation on the relevant cases. revision: partial
Circularity Check
No significant circularity in the NucEval derivation or evaluation pipeline
full rationale
The paper identifies four evaluation issues (vague regions, score normalization, overlapping instances, border uncertainty), defines explicit handling rules for each, integrates them into the NucEval framework, and demonstrates effects via direct application to NuInsSeg plus two external datasets using three models. No load-bearing step reduces a claimed result to a fitted parameter, self-citation chain, or input by construction; the modifications are presented as rule-based adjustments rather than learned predictions, and the reported metric shifts are empirical observations from the defined pipeline. The derivation chain is therefore self-contained against the provided datasets and code.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard instance segmentation metrics require pathology-specific adjustments for vague regions, overlaps, and borders.
Reference graph
Works this paper leans on
-
[1]
Samya A. Omoush, Jihad A. M. Alzyoud, Nidhal Kamel Taha El-Omari, and Ahmad J. A. Alzyoud. The role of whole slide imaging in ai-based digital pathology: Current challenges and future directions—an updated literature review.Journal of Molecular Pathology, 7(1), 2026. doi: https://doi.org/10.3390/jmp7010002
-
[2]
Clarke, Charlotte Jennings, Gillian Matthews, Caroline Cartlidge, Henschel Freduah-Agyemang, Deborah D
Clare McGenity, Emily L. Clarke, Charlotte Jennings, Gillian Matthews, Caroline Cartlidge, Henschel Freduah-Agyemang, Deborah D. Stocken, and Darren Treanor. Artificial intelli- gence in digital pathology: a systematic review and meta-analysis of diagnostic test accu- racy.npj Digital Medicine, 7(1):114, 2024. ISSN 2398-6352. doi: https://doi.org/10.1038/...
2024
-
[3]
A systematic review on cell nucleus instance segmentation.IET Image Processing, 19(1):e70129, 2025
Yulin Chen, Qian Huang, Meng Geng, Zhijian Wang, and Yi Han. A systematic review on cell nucleus instance segmentation.IET Image Processing, 19(1):e70129, 2025. doi: https://doi.org/10.1049/ipr2.70129
-
[4]
Neeraj Kumar, Ruchika Verma, Deepak Anand, Yanning Zhou, Omer Fahri Onder, Efstratios Tsougenis, Hao Chen, Pheng-Ann Heng, Jiahui Li, Zhiqiang Hu, Yunzhi Wang, Navid Alemi Koohbanani, Mostafa Jahanifar, Neda Zamani Tajeddin, Ali Gooya, Nasir Rajpoot, Xuhua Ren, Sihang Zhou, Qian Wang, Dinggang Shen, Cheng-Kun Yang, Chi-Hung Weng, Wei-Hsiang Yu, Chao-Yuan ...
-
[5]
Le Hou, Rajarsi Gupta, John S Van Arnam, Yuwei Zhang, Kaustubh Sivalenka, Dimitris Samaras, Tahsin M Kurc, and Joel H Saltz. Dataset of segmented nuclei in hematoxylin and eosin stained histopathology images of ten cancer types.Scientific data, 7(1):1–12, 2020. doi: https://doi.org/10.1038/s41597-020-0528-1
-
[6]
Simon Graham, Quoc Dang Vu, Shan E Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, and Nasir Rajpoot. Hover-Net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images.Medical Image Analysis, 58:101563, 2019. ISSN 1361-8415. doi: https://doi.org/10.1016/j.media.2019.101563
-
[7]
Nagtegaal, Maria Rodriguez Martinez, and Inti Zlobec
Elias Baumann, Bastian Dislich, Josef Lorenz Rumberger, Iris D. Nagtegaal, Maria Rodriguez Martinez, and Inti Zlobec. Hover-next: A fast nuclei segmentation and classification pipeline for next generation histopathology. In Ninon Burgos, Caroline Petitjean, Maria Vakalopoulou, Stergios Christodoulidis, Pierrick Coupe, Hervé Delingette, Carole Lartizien, a...
2024
-
[8]
Fabian Hörst, Moritz Rempe, Lukas Heine, Constantin Seibold, Julius Keyl, Giulia Baldini, Selma Ugurel, Jens Siveke, Barbara Grünwald, Jan Egger, and Jens Kleesiek. Cellvit: Vision 10 transformers for precise cell segmentation and classification.Medical Image Analysis, 94: 103143, 2024. ISSN 1361-8415. doi: https://doi.org/10.1016/j.media.2024.103143
-
[9]
Insmix: Towards realistic generative data augmentation for nuclei instance segmentation
Yi Lin, Zeyu Wang, Kwang-Ting Cheng, and Hao Chen. Insmix: Towards realistic generative data augmentation for nuclei instance segmentation. In Linwei Wang, Qi Dou, P. Thomas Fletcher, Stefanie Speidel, and Shuo Li, editors,Medical Image Computing and Computer As- sisted Intervention – MICCAI 2022, pages 140–149, Cham, 2022. Springer Nature Switzerland. IS...
-
[10]
Amirreza Mahbod, Georg Dorffner, Isabella Ellinger, Ramona Woitek, and Sepideh Hatamikia. Improving generalization capability of deep learning-based nuclei instance segmentation by non-deterministic train time and deterministic test time stain normalization.Computational and Structural Biotechnology Journal, 23:669–678, 2024. ISSN 2001-0370. doi: https: /...
-
[11]
Jiaqi Lv, Esha Sadia Nasir, Kesi Xu, Mostafa Jahanifar, Brinder Singh Chohan, Behnaz El- haminia, and Shan E Ahmed Raza. Kongnet: A multi-headed deep learning model for detection and classification of nuclei in histopathology images.arXiv preprint arXiv:2510.23559, 2025. doi: https://doi.org/10.48550/arXiv.2510.23559
work page internal anchor Pith review doi:10.48550/arxiv.2510.23559 2025
-
[12]
Dominik Müller, Iñaki Soto-Rey, and Frank Kramer. Towards a guideline for evaluation metrics in medical image segmentation.BMC Research Notes, 15(1):210, Jun 2022. doi: https://doi.org/10.1186/s13104-022-06096-y
-
[13]
Tizabi, Michael Baumgartner, Matthias Eisenmann, Doreen Heckmann- Nötzel, A
Annika Reinke, Minu D. Tizabi, Michael Baumgartner, Matthias Eisenmann, Doreen Heckmann- Nötzel, A. Emre Kavur, Tim Rädsch, Carole H. Sudre, Laura Acion, Michela Antonelli, Tal Arbel, Spyridon Bakas, Arriel Benis, Florian Buettner, M. Jorge Cardoso, Veronika Cheplygina, Jianxu Chen, Evangelia Christodoulou, Beth A. Cimini, Keyvan Farahani, Luciana Ferrer,...
-
[14]
Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Dollár. Panoptic segmentation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019. doi: https://doi.org/10.1109/CVPR.2019.00963
-
[15]
Lee R. Dice. Measures of the amount of ecologic association between species.Ecology, 26(3): 297–302, 1945. ISSN 00129658, 19399170. doi: https://doi.org/10.2307/1932409
-
[16]
MoNuSAC2020: A multi-organ nuclei segmentation and classification challenge
Adrien Foucart, Olivier Debeir, and Christine Decaestecker. Comments on “MoNuSAC2020: A multi-organ nuclei segmentation and classification challenge”.IEEE Transactions on Medical Imaging, 41(4):997–999, 2022. doi: https://doi.org/10.1109/TMI.2022.3156023
-
[17]
MoNuSAC2020: A multi-organ nuclei segmentation and classification challenge
Ruchika Verma, Neeraj Kumar, Abhijeet Patil, Nikhil Cherian Kurian, Swapnil Rane, and Amit Sethi. Author’s reply to “MoNuSAC2020: A multi-organ nuclei segmentation and classification challenge”.IEEE Transactions on Medical Imaging, 41(4):1000–1003, 2022. doi: https://doi.org/10.1109/TMI.2022.3157048
-
[18]
Common limitations of image processing metrics: A picture story.arXiv preprint arXiv:2104.05642,
Annika Reinke, Minu D Tizabi, Carole H Sudre, Matthias Eisenmann, Tim Rädsch, Michael Baumgartner, Laura Acion, Michela Antonelli, Tal Arbel, Spyridon Bakas, et al. Common limitations of image processing metrics: A picture story.arXiv preprint arXiv:2104.05642,
-
[19]
doi: https://doi.org/10.48550/arXiv.2104.05642. 11
-
[20]
Adrien Foucart, Olivier Debeir, and Christine Decaestecker. Panoptic quality should be avoided as a metric for assessing cell nuclei segmentation and classification in digital pathology.Scientific Reports, 13(1):8614, May 2023. doi: https://doi.org/10.1038/s41598-023-35605-7
-
[21]
Backpropagation through time and the brain.Current Opinion in Neurobiology, 55:82–89, 2019
Adrien Foucart, Olivier Debeir, and Christine Decaestecker. Shortcomings and areas for improvement in digital pathology image segmentation challenges.Computerized Medical Imaging and Graphics, 103:102155, 2023. ISSN 0895-6111. doi: https://doi.org/10.1016/j. compmedimag.2022.102155
work page doi:10.1016/j 2023
-
[22]
Bradley, Aaron Carass, Carolin Feldmann, Alejandro F
Lena Maier-Hein, Matthias Eisenmann, Annika Reinke, Sinan Onogur, Marko Stankovic, Patrick Scholz, Tal Arbel, Hrvoje Bogunovic, Andrew P. Bradley, Aaron Carass, Carolin Feldmann, Alejandro F. Frangi, Peter M. Full, Bram van Ginneken, Allan Hanbury, Katrin Honauer, Michal Kozubek, Bennett A. Landman, Keno März, Oskar Maier, Klaus Maier-Hein, Bjoern H. Menz...
-
[23]
Full, Hrvoje Bogunovic, Bennett A
Annika Reinke, Matthias Eisenmann, Sinan Onogur, Marko Stankovic, Patrick Scholz, Peter M. Full, Hrvoje Bogunovic, Bennett A. Landman, Oskar Maier, Bjoern Menze, Gregory C. Sharp, Korsuk Sirinukunwattana, Stefanie Speidel, Fons van der Sommen, Guoyan Zheng, Henning Müller, Michal Kozubek, Tal Arbel, Andrew P. Bradley, Pierre Jannin, Annette Kopp-Schneider...
-
[24]
Amirreza Mahbod, Christine Polak, Katharina Feldmann, Rumsha Khan, Katharina Gelles, Georg Dorffner, Ramona Woitek, Sepideh Hatamikia, and Isabella Ellinger. Nuinsseg: A fully annotated dataset for nuclei instance segmentation in h&e-stained histological images.Scientific Data, 11(1):295, 2024. ISSN 2052-4463. doi: https://doi.org/10.1038/s41597-024-03117-2
-
[25]
Amirreza Mahbod, Gerald Schaefer, Benjamin Bancher, Christine Löw, Georg Dorffner, Rupert Ecker, and Isabella Ellinger. CryoNuSeg: A dataset for nuclei instance segmentation of cryosectioned H&E-stained histological images.Computers in Biology and Medicine, 132: 104349, 2021. doi: https://doi.org/10.1016/j.compbiomed.2021.104349
-
[26]
Nima Torbati, Anastasia Meshcheryakova, Ramona Woitek, Sepideh Hatamikia, Diana Mechtcheriakova, and Amirreza Mahbod. Nucfuserank: Dataset fusion and performance ranking for nuclei instance segmentation.arXiv preprint arXiv:2601.20104, 2026. doi: https://doi.org/10.48550/arXiv.2601.20104
-
[27]
Ruchika Verma, Neeraj Kumar, Abhijeet Patil, Nikhil Cherian Kurian, Swapnil Rane, Simon Graham, Quoc Dang Vu, Mieke Zwager, Shan E Ahmed Raza, Nasir Rajpoot, Xiyi Wu, Huai Chen, Yijie Huang, Lisheng Wang, Hyun Jung, G Thomas Brown, Yanling Liu, Shuolin Liu, Seyed Alireza Fatemi Jahromi, Ali Asghar Khani, Ehsan Montahaei, Mahdieh Soleymani Baghshah, Hamid ...
-
[28]
Mark Schuiveling, Hong Liu, Daniel Eek, Gerben E Breimer, Karijn PM Suijkerbuijk, Willeke AM Blokx, and Mitko Veta. A novel dataset for nuclei and tissue segmentation in 12 melanoma with baseline nuclei segmentation and tissue segmentation benchmarks.GigaScience, 14:giaf011, 2025. doi: https://doi.org/10.1093/gigascience/giaf011
-
[29]
Mark Schuiveling, Hong Liu, Daniel Eek, Martina Hanusová, Isabella A.J. van Duin, Laurens S. ter Maat, Janneke C. van der Weerd, Franchette van den Berkmortel, Christian U. Blank, Gerben E. Breimer, Femke H. Burgers, Marye Boers-Sonderen, Alfons J.M. van den Eertwegh, Jan Willem B. de Groot, John B.A.G. Haanen, Geke A.P. Hospers, Ellen Kapiteijn, Djura Pi...
-
[30]
Peter Naylor, Marick Laé, Fabien Reyal, and Thomas Walter. Segmentation of nuclei in histopathology images by deep regression of the distance map.IEEE Transactions on Medical Imaging, 38(2):448–459, 2019. doi: https://doi.org/10.1109/TMI.2018.2865709
-
[31]
Evaluating participating methods in image analysis challenges: Lessons from monusac 2020.Pattern Recognition, 141:109600,
Adrien Foucart, Olivier Debeir, and Christine Decaestecker. Evaluating participating methods in image analysis challenges: Lessons from monusac 2020.Pattern Recognition, 141:109600,
2020
-
[32]
doi: https://doi.org/10.1016/j.patcog.2023.109600
ISSN 0031-3203. doi: https://doi.org/10.1016/j.patcog.2023.109600
-
[33]
Alexander
Le Zhang, Ryutaro Tanno, Mou-Cheng Xu, Chen Jin, Joseph Jacob, Olga Ciccarelli, Frederik Barkhof, and Daniel C. Alexander. Disentangling human error from the ground truth in segmentation of medical images. InProceedings of the 34th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 9781...
2020
-
[34]
Sepideh Hatamikia, Geevarghese George, Florian Schwarzhans, Amirreza Mahbod, and Ramona Woitek. Breast mri radiomics and machine learning-based predictions of response to neoadjuvant chemotherapy – how are they affected by variations in tumor delineation?Computational and Structural Biotechnology Journal, 23:52–63, 2024. ISSN 2001-0370. doi: https://doi.o...
2024
-
[35]
Douglas Joseph Hartman, Jeroen A.W.M. Van Der Laak, Metin N. Gurcan, and Liron Pantanowitz. Value of public challenges for the development of pathology deep learn- ing algorithms.Journal of Pathology Informatics, 11(1):7, 2020. ISSN 2153-3539. doi: https://doi.org/10.4103/jpi.jpi_64_19
-
[36]
Distribution de la flore alpine dans le bassin des dranses et dans quelques régions voisines.Bull Soc Vaudoise Sci Nat, 37:241–272, 1901
Paul Jaccard. Distribution de la flore alpine dans le bassin des dranses et dans quelques régions voisines.Bull Soc Vaudoise Sci Nat, 37:241–272, 1901
1901
-
[37]
Abishek Sankaranarayanan, Georgii Khachaturov, Kimberly S. Smythe, and Shachi Mittal. Quantitative benchmarking of nuclear segmentation algorithms in multiplexed immunofluo- rescence imaging for translational studies.Communications Biology, 8(1):836, 2025. ISSN 2399-3642. doi: https://doi.org/10.1038/s42003-025-08184-8
-
[38]
Simon Graham, Quoc Dang Vu, Mostafa Jahanifar, Martin Weigert, Uwe Schmidt, Wenhua Zhang, Jun Zhang, Sen Yang, Jinxi Xiang, Xiyue Wang, Josef Lorenz Rumberger, Elias Baumann, Peter Hirsch, Lihao Liu, Chenyang Hong, Angelica I. Aviles-Rivero, Ayushi Jain, Heeyoung Ahn, Yiyu Hong, Hussam Azzuni, Min Xu, Mohammad Yaqub, Marie-Claire Blache, Benoît Piégu, Ber...
-
[39]
Adrien Foucart, Arthur Elskens, and Christine Decaestecker. Ranking the scores of algorithms with confidence. InEuropean Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, pages 431–436, 2025. doi: https://doi.org/10.14428/esann/ 2025.ES2025-39. 13 A Technical appendices and supplementary material A.1 Literature revi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.