Recognition: unknown
Conformalized Percentile Interval: Finite Sample Validity and Improved Conditional Performance
Pith reviewed 2026-05-08 17:05 UTC · model grok-4.3
The pith
A calibration step applied to probability integral transforms of a neural network's conditional CDF estimate produces predictive intervals with exact finite-sample marginal coverage and improved conditional performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The conformalized percentile interval is formed by applying percentile calibration to the PIT values obtained from a neural-network estimate of the conditional CDF. This yields intervals whose length is the smallest value satisfying the empirical quantile in PIT space, delivering exact finite-sample marginal coverage for any underlying distribution and asymptotic conditional coverage whenever the CDF estimator satisfies mild consistency conditions.
What carries the argument
Probability integral transform applied to the neural-network conditional CDF estimate, followed by empirical percentile calibration on the resulting PIT values to determine interval endpoints.
If this is right
- Predictive intervals retain exact marginal coverage even if the neural network CDF model is misspecified.
- Under consistency of the CDF estimator, the intervals achieve conditional coverage without requiring perfect knowledge of the true distribution.
- Interval lengths adapt to the empirical PIT distribution, producing shorter intervals than methods that ignore the estimated conditional shape.
- Feature-dependent miscoverage is reduced because calibration occurs after the PIT step removes most feature dependence.
Where Pith is reading between the lines
- The same PIT-calibration idea could be paired with other consistent conditional distribution estimators such as quantile forests or normalizing flows.
- In sequential or non-stationary settings the method may need an additional forgetting mechanism to maintain the asymptotic conditional property.
- Practical gains would be largest in applications where baseline conformal intervals are overly wide due to strong heteroskedasticity.
Load-bearing premise
The neural network conditional CDF estimate must be accurate enough for the PIT values to become asymptotically independent of the input features.
What would settle it
Apply the method to a dataset with deliberately inaccurate conditional CDF estimates and measure whether marginal coverage still equals the nominal level while conditional coverage deviates from the asymptotic claim.
Figures
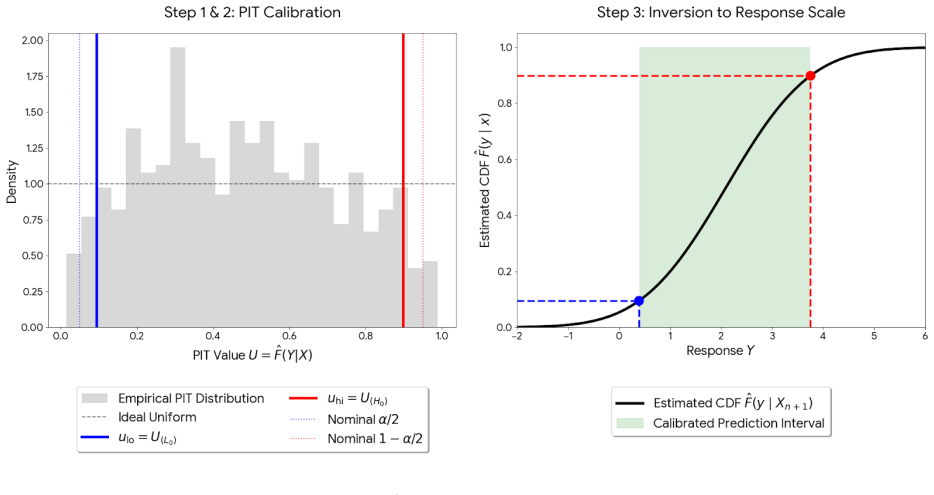

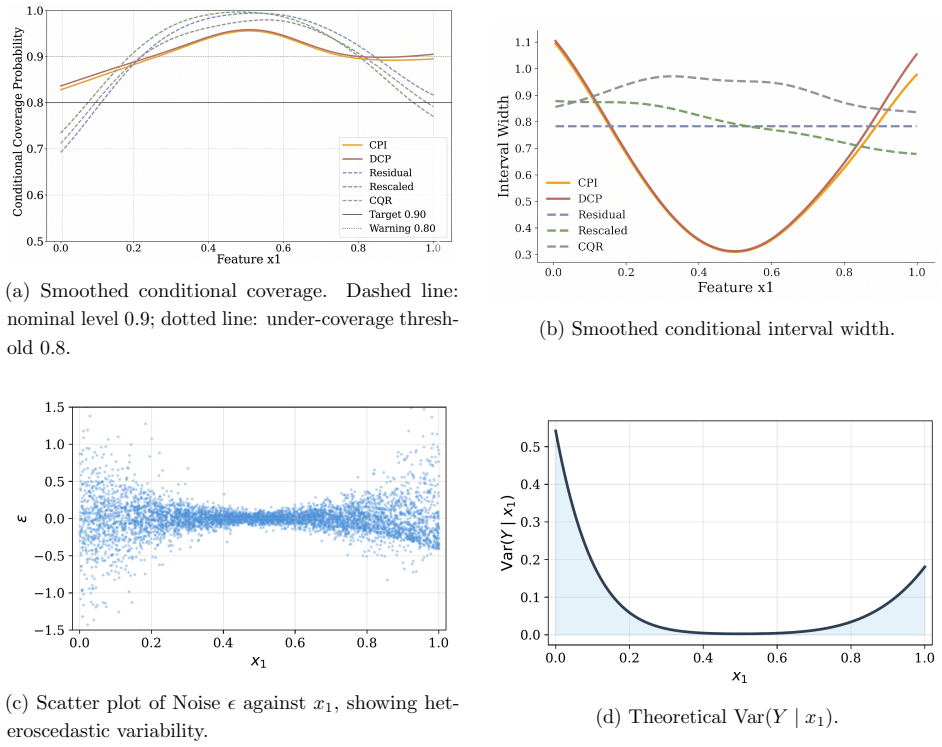
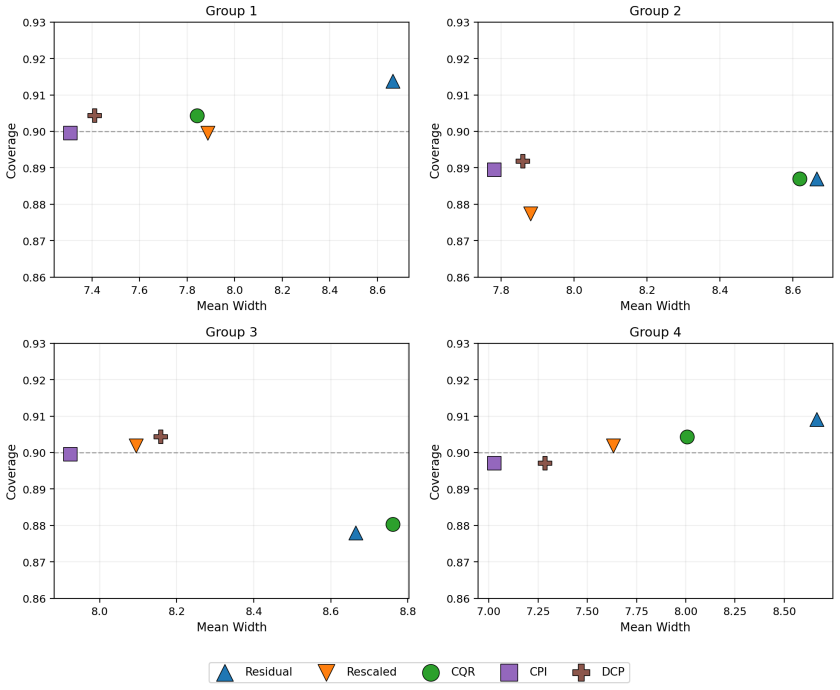

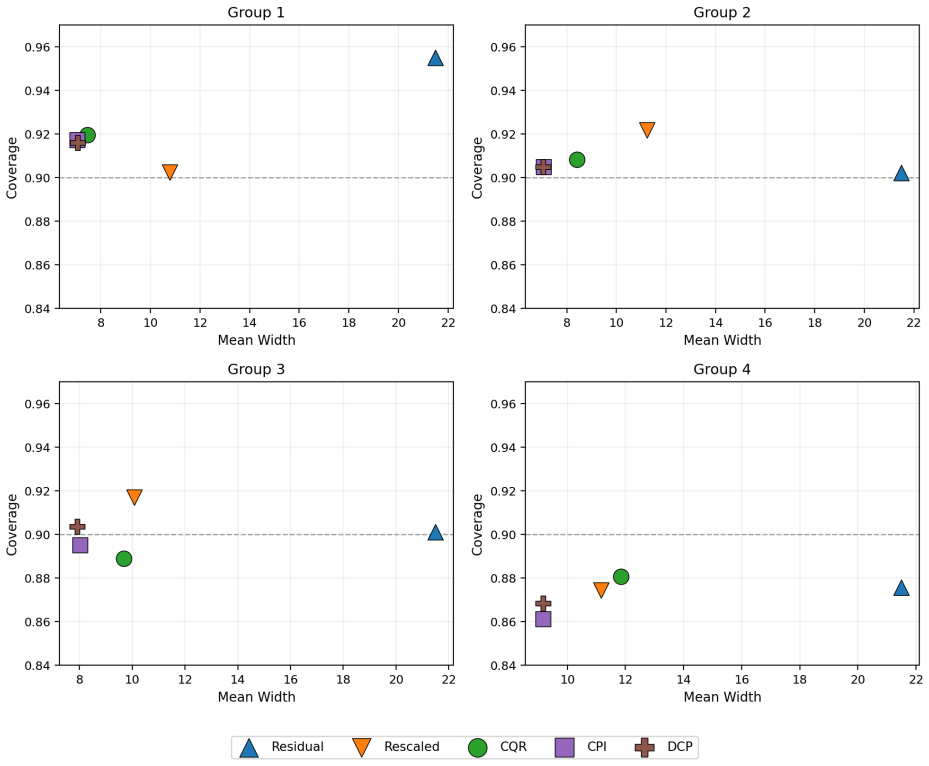


read the original abstract
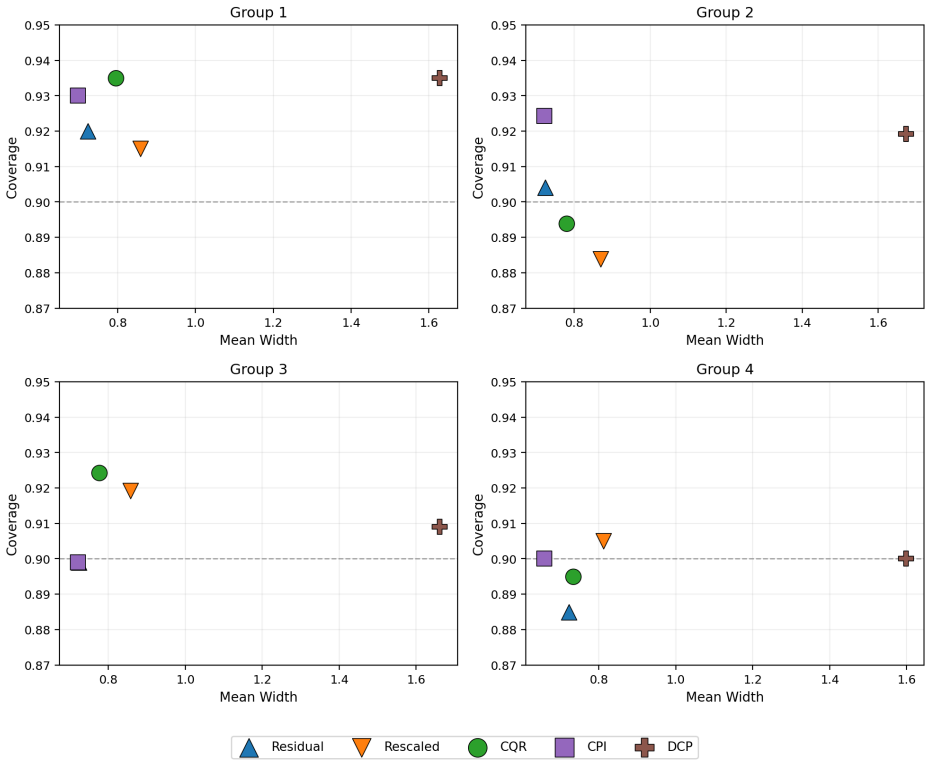
Conformal prediction provides distribution-free predictive intervals with finite-sample marginal coverage. However, achieving conditional validity and interval efficiency (in terms of short interval length) remains challenging, particularly in complex settings with heteroskedasticity, skewed responses, or estimation errors. We propose a conformal-style calibration method for responses obtained by the probability integral transform (PIT) of the conditional cumulative distribution function (CDF) estimated via neural networks to construct a finite-sample-adjusted percentile interval with the shortest length determined by the estimated conditional CDF. Calibrating in PIT space is effective because PIT values are asymptotically feature-independent when the CDF estimator is accurate, which mitigates feature-dependent miscoverage and improves conditional calibration. On the other hand, our percentile calibration adapts to the empirical PIT distribution, which is robust against a possibly imperfect estimation of the conditional CDF. We prove the finite-sample marginal coverage property of the proposed method and show its asymptotic conditional coverage under mild consistency conditions. Experiments on diverse synthetic and real-world benchmarks demonstrate better conditional calibration and substantially shorter intervals than existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Conformalized Percentile Interval (CPI), which applies a conformal-style calibration step to the probability integral transform (PIT) values obtained from a neural-network estimate of the conditional CDF. This yields predictive intervals whose length is determined by the estimated conditional CDF, with a claim of finite-sample marginal coverage (via exchangeability of the calibrated PIT scores) and asymptotic conditional coverage under mild consistency conditions on the CDF estimator. Experiments on synthetic and real-world data are reported to show improved conditional calibration and shorter intervals relative to existing conformal methods.
Significance. If the finite-sample marginal guarantee and the asymptotic conditional coverage both hold, the approach would provide a useful practical tool for obtaining shorter, better-calibrated intervals in settings with heteroskedasticity or skewness, while preserving the distribution-free marginal property. The idea of calibrating in PIT space to exploit asymptotic feature-independence is conceptually appealing and could complement existing conformal techniques.
major comments (2)
- [§4] §4 (Theoretical Analysis), statement of asymptotic conditional coverage: The 'mild consistency conditions' invoked for the neural-network conditional CDF estimator are not stated with sufficient precision (e.g., no explicit rate or uniformity requirement over x). Without uniform or sup-norm consistency, the PIT scores may retain residual dependence on x, so that the subsequent global percentile calibration on the empirical PIT distribution cannot guarantee the claimed asymptotic conditional coverage; this is load-bearing for the paper's central claim of improved conditional performance.
- [§5] §5 (Experiments), Tables 1–3 and Figures 2–4: The reported gains in conditional coverage and interval length are presented without ablation on the quality of the base NN CDF estimator (e.g., no comparison when the NN is deliberately underfit or when the data exhibit strong heteroskedasticity). It is therefore unclear whether the observed improvements are driven by the CPI calibration step itself or by the particular NN architecture and training regime chosen.
minor comments (2)
- [§3] Notation in §3: The precise definition of the calibration quantile applied to the PIT scores (and how ties or discrete PIT values are handled) should be written explicitly, as it directly affects the finite-sample coverage argument.
- [§1, §5] The abstract and §1 claim 'substantially shorter intervals'; the experimental tables would benefit from reporting the ratio of average lengths together with standard errors across replications.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below and will revise the paper accordingly to strengthen the presentation of the theoretical results and experimental evidence.
read point-by-point responses
-
Referee: [§4] §4 (Theoretical Analysis), statement of asymptotic conditional coverage: The 'mild consistency conditions' invoked for the neural-network conditional CDF estimator are not stated with sufficient precision (e.g., no explicit rate or uniformity requirement over x). Without uniform or sup-norm consistency, the PIT scores may retain residual dependence on x, so that the subsequent global percentile calibration on the empirical PIT distribution cannot guarantee the claimed asymptotic conditional coverage; this is load-bearing for the paper's central claim of improved conditional performance.
Authors: We agree that the asymptotic conditional coverage result requires a more precise statement of the consistency assumptions on the neural-network CDF estimator. In the revised manuscript, we will update the theorem in §4 to explicitly require uniform (sup-norm) consistency of the CDF estimator at a rate that vanishes asymptotically, ensuring that the PIT scores become independent of the features x. This will clarify how the global percentile calibration on the empirical PIT distribution yields the claimed asymptotic conditional coverage and will make the load-bearing assumption transparent. revision: yes
-
Referee: [§5] §5 (Experiments), Tables 1–3 and Figures 2–4: The reported gains in conditional coverage and interval length are presented without ablation on the quality of the base NN CDF estimator (e.g., no comparison when the NN is deliberately underfit or when the data exhibit strong heteroskedasticity). It is therefore unclear whether the observed improvements are driven by the CPI calibration step itself or by the particular NN architecture and training regime chosen.
Authors: We acknowledge that the current experiments do not include explicit ablations on the base estimator quality. While the reported results use a standard NN trained to convergence on benchmarks that already incorporate heteroskedasticity and skewness, we agree that additional controls are needed to isolate the contribution of the CPI step. In the revised version, we will add ablation experiments: (i) deliberately underfit NNs (reduced capacity or early stopping) and (ii) synthetic data with controlled levels of heteroskedasticity, comparing CPI against baselines under these regimes. This will demonstrate that the observed gains in conditional calibration and interval length are attributable to the PIT-space calibration. revision: yes
Circularity Check
No circularity: finite-sample coverage follows from exchangeability independent of NN fit; asymptotic result uses external consistency assumptions
full rationale
The derivation separates the finite-sample marginal coverage (obtained via standard conformal exchangeability applied to the PIT scores after training the NN CDF estimator on a held-out set) from the estimator quality itself. The percentile calibration step adapts directly to the empirical distribution of the transformed scores without feeding any fitted parameter back into the coverage guarantee. The asymptotic conditional coverage is explicitly conditioned on mild consistency of the NN estimator (an external assumption, not derived from the method's own outputs), with no self-citation load-bearing the central claim and no renaming or self-definitional reduction of predictions to inputs. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild consistency conditions on the conditional CDF estimator
Reference graph
Works this paper leans on
- [1]
-
[2]
arXiv preprint arXiv:2411.11824 , year=
Angelopoulos, A. N., Barber, R. F., and Bates, S. Theoretical foundations of conformal prediction.arXiv preprint arXiv:2411.11824, 2024
-
[3]
F., Pope, D
Brooks, T. F., Pope, D. S., and Marcolini, M. A. Airfoil self-noise and prediction. NASA Reference Publication 1218, National Aeronautics and Space Administration, 1989
1989
-
[4]
and Vovk, V
Burnaev, E. and Vovk, V. Efficiency of conformalized ridge regression. InConference on Learning Theory, pp. 605–622. PMLR, 2014
2014
-
[5]
Distributional conformal prediction.Proceedings of the National Academy of Sciences, 118(48):e2107794118, 2021
Chernozhukov, V., W¨ uthrich, K., and Zhu, Y. Distributional conformal prediction.Proceedings of the National Academy of Sciences, 118(48):e2107794118, 2021
2021
-
[6]
Ein-Dor, P. and Feldmesser, J. Attributes of the performance of central processing units: A relative performance prediction model.Communications of the ACM, 30(4):308–317, 1987. doi: 10.1145/32232.32234
-
[7]
J., Ramdas, A., and Tibshirani, R
Foygel Barber, R., Candes, E. J., Ramdas, A., and Tibshirani, R. J. The limits of distribution- free conditional predictive inference.Information and Inference: A Journal of the IMA, 10(2): 455–482, 2021
2021
-
[8]
J., and Cand` es, E
Gibbs, I., Cherian, J. J., and Cand` es, E. J. Conformal prediction with conditional guarantees. Journal of the Royal Statistical Society Series B: Statistical Methodology, pp. qkaf008, 2025
2025
-
[9]
Localized conformal prediction: A generalized inference framework for conformal prediction.Biometrika, 110(1):33–50, 2023
Guan, L. Localized conformal prediction: A generalized inference framework for conformal prediction.Biometrika, 110(1):33–50, 2023
2023
-
[10]
Hore, R. and Barber, R. F. Conformal prediction with local weights: randomization enables local guarantees.arXiv preprint arXiv:2310.07850, 2023. 20
-
[11]
and Nan, B
Hu, B. and Nan, B. Conditional distribution function estimation using neural networks for censored and uncensored data.Journal of Machine Learning Research, 24(223):1–26, 2023
2023
-
[12]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations, 2015
2015
-
[13]
and Hallock, K
Koenker, R. and Hallock, K. F. Quantile regression.Journal of Economic Perspectives, 15(4): 143–156, 2001
2001
-
[14]
J., and Wasserman, L
Lei, J., G’Sell, M., Rinaldo, A., Tibshirani, R. J., and Wasserman, L. Distribution-free predictive inference for regression.Journal of the American Statistical Association, 113(523):1094–1111, 2018
2018
-
[15]
Liang, R., Zhu, W., and Barber, R. F. Conformal prediction after efficiency-oriented model selection.arXiv preprint arXiv:2408.07066, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
J., Sellers, T
Nash, W. J., Sellers, T. L., Talbot, S. R., Cawthorn, A. J., and Ford, W. B. The population biology of abalone (Haliotisspecies) in Tasmania. I. Blacklip abalone (H. rubra) from the north coast and islands of Bass Strait. Technical Report 48, Sea Fisheries Division, Department of Primary Industry and Fisheries, Tasmania, 1994
1994
-
[17]
B., Panov, M., and Moulines, E
Plassier, V., Fishkov, A., Dheur, V., Guizani, M., Taieb, S. B., Panov, M., and Moulines, E. Rectifying conformity scores for better conditional coverage. InInternational Conference on Machine Learning, 2025
2025
-
[18]
Probabilistic conformal prediction with approximate conditional validity
Plassier, V., Fishkov, A., Guizani, M., Panov, M., and Moulines, E. Probabilistic conformal prediction with approximate conditional validity. InInternational Conference on Learning Representations, 2025
2025
-
[19]
Quinlan, J. R. Combining instance-based and model-based learning. InProceedings of the 10th International Conference on Machine Learning, pp. 236–243. Morgan Kaufmann, 1993
1993
-
[20]
and Baveja, A
Redmond, M. and Baveja, A. A data-driven software tool for enabling cooperative information sharing among police departments.European Journal of Operational Research, 141(3):660–678,
-
[21]
doi: 10.1016/S0377-2217(01)00264-8
-
[22]
Conformalized quantile regression.Advances in Neural Information Processing Systems, 32, 2019
Romano, Y., Patterson, E., and Candes, E. Conformalized quantile regression.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[23]
P., and Carroll, R
Ruppert, D., Wand, M. P., and Carroll, R. J.Semiparametric regression. Number 12 in Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2003. 21
2003
-
[24]
and Romano, Y
Sesia, M. and Romano, Y. Conformal prediction using conditional histograms.Advances in Neural Information Processing Systems, 34:6304–6315, 2021
2021
-
[25]
T., Doucet, A., et al
Stutz, D., Cemgil, A. T., Doucet, A., et al. Learning optimal conformal classifiers. In International Conference on Learning Representations, 2022
2022
-
[26]
J., Foygel Barber, R., Candes, E., and Ramdas, A
Tibshirani, R. J., Foygel Barber, R., Candes, E., and Ramdas, A. Conformal prediction under covariate shift.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[27]
Springer, 2005
Vovk, V., Gammerman, A., and Shafer, G.Algorithmic learning in a random world. Springer, 2005
2005
-
[28]
Boosted conformal prediction intervals.Advances in Neural Information Processing Systems, 37:71868–71899, 2024
Xie, R., Barber, R., and Candes, E. Boosted conformal prediction intervals.Advances in Neural Information Processing Systems, 37:71868–71899, 2024
2024
-
[29]
and Kuchibhotla, A
Yang, Y. and Kuchibhotla, A. K. Selection and aggregation of conformal prediction sets. Journal of the American Statistical Association, 120(549):435–447, 2025
2025
-
[30]
Modeling of strength of high-performance concrete using artificial neural networks
Yeh, I.-C. Modeling of strength of high-performance concrete using artificial neural networks. Cement and Concrete Research, 28(12):1797–1808, 1998. doi: 10.1016/S0008-8846(98)00165-3
-
[31]
Stability.Bernoulli, 19(4):1484–1500, 2013
Yu, B. Stability.Bernoulli, 19(4):1484–1500, 2013. Appendix A Implementation Details We provide the full implementation details for reproducibility. NN-CDE (Hazard Network).The conditional density estimator is a two-hidden-layer MLP with 64 hidden units per layer and ReLU activations. All features are standardized to zero mean and unit variance. Training ...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.