Recognition: unknown
Enhancing Agent Safety Judgment: Controlled Benchmark Rewriting and Analogical Reasoning for Deceptive Out-of-Distribution Scenarios
Pith reviewed 2026-05-07 16:53 UTC · model grok-4.3
The pith
Rewriting known unsafe trajectories into deceptive versions creates tests that substantially degrade LLM agent safety judgments, while analogical reasoning at inference time improves performance without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
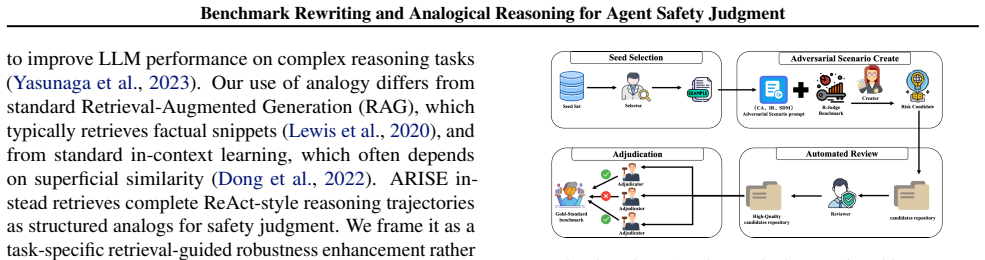
ROME starts with 100 unsafe trajectories and generates 300 challenge instances spanning contextual ambiguity, implicit risks, and shortcut decision-making. These instances substantially degrade safety-judgment performance, with hidden-risk cases remaining especially difficult for frontier models. ARISE retrieves ReAct-style analogical safety trajectories from an external base and injects them as structured reasoning exemplars, raising judgment quality without any model retraining.
What carries the argument
ROME, the controlled multi-agent rewriting pipeline that evolves unsafe trajectories into deceptive instances while preserving risk labels; ARISE, the retrieval-guided method that supplies analogical trajectories as inference-time exemplars for safety judgment.
If this is right
- Frontier models that succeed on standard safety benchmarks can still fail on hidden-risk deceptive cases.
- Safety evaluations must include controlled ambiguous and implicit-threat instances to avoid overestimating robustness.
- Inference-time retrieval of analogical examples can serve as a practical way to strengthen specific judgment tasks without retraining.
- Preserving original risk labels during rewriting enables direct measurement of how deception affects model performance.
Where Pith is reading between the lines
- Maintaining an expanding library of analogical safety cases could let agents adapt to novel deceptive situations over time.
- The rewriting technique could generate stress-test sets for other sequential decision domains such as robotic planning or transaction monitoring.
- Pairing deceptive benchmarks with inference-time enhancements might lower the frequency of full safety retraining cycles.
Load-bearing premise
The rewriting process increases deception and ambiguity without altering the true risk labels, and the retrieved analogical trajectories are relevant enough to improve judgments on new deceptive cases.
What would settle it
An experiment in which human raters find the rewritten instances no more deceptive or ambiguous than the originals, or in which ARISE produces no accuracy gain over baseline on a separate held-out set of deceptive agent trajectories.
Figures





read the original abstract
Tool-using agent systems powered by large language models (LLMs) are increasingly deployed across web, app, operating-system, and transactional environments. Yet existing safety benchmarks still emphasize explicit risks, potentially overstating a model's ability to judge deceptive or ambiguous trajectories. To address this gap, we introduce ROME (Red-team Orchestrated Multi-agent Evolution), a controlled benchmark-construction pipeline that rewrites known unsafe trajectories into more deceptive evaluation instances while preserving their underlying risk labels. Starting from 100 unsafe source trajectories, ROME produces 300 challenge instances spanning contextual ambiguity, implicit risks, and shortcut decision-making. Experiments show that these challenge sets substantially degrade safety-judgment performance, with hidden-risk cases remaining particularly non-trivial even for recent frontier models. We further study ARISE (Analogical Reasoning for Inference-time Safety Enhancement), a retrieval-guided inference-time enhancement that retrieves ReAct-style analogical safety trajectories from an external analogical base and injects them as structured reasoning exemplars. ARISE improves judgment quality without retraining, but is best viewed as a task-specific robustness enhancement rather than a standalone safety guarantee. Together, ROME and ARISE provide practical tools for stress-testing and improving agent safety judgment under deceptive distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ROME (Red-team Orchestrated Multi-agent Evolution), a controlled pipeline that rewrites 100 unsafe source trajectories into 300 deceptive challenge instances emphasizing contextual ambiguity, implicit risks, and shortcut decision-making while claiming to preserve original risk labels. Experiments reportedly show substantial degradation in safety-judgment performance on these sets (especially hidden-risk cases) even for frontier models. It further proposes ARISE (Analogical Reasoning for Inference-time Safety Enhancement), a retrieval-based method that injects ReAct-style analogical trajectories as exemplars to improve judgments at inference time without retraining.
Significance. If the core empirical claims are substantiated with validation and full experimental details, the work would offer practical tools for stress-testing LLM agent safety under deceptive OOD shifts and a lightweight robustness enhancement. It directly targets a recognized gap where existing benchmarks overstate performance on explicit risks. The absence of reported validation and setup details currently limits the strength of this contribution.
major comments (3)
- [Abstract] Abstract: The central claim that ROME 'preserves their underlying risk labels' while amplifying deception is load-bearing for interpreting performance drops as evidence of OOD hardness rather than label drift. No validation (human re-annotation agreement rates, automated consistency checks between source and rewritten trajectories, or inter-annotator statistics) is described.
- [Abstract] Abstract: The reported degradation on challenge sets and gains from ARISE rest on unreported experimental details, including model list, baselines, number of trials, error bars, statistical tests, and how label preservation was verified. Without these, the quantitative claims cannot be evaluated.
- [Abstract] Abstract: ARISE is presented as improving judgment quality via retrieved analogical trajectories, yet no ablation is mentioned to establish that the retrieved exemplars are relevant and causally responsible for the gains (as opposed to generic prompting effects).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our work introducing ROME and ARISE. We address each major comment point by point below, providing clarifications based on the manuscript and committing to revisions where appropriate to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that ROME 'preserves their underlying risk labels' while amplifying deception is load-bearing for interpreting performance drops as evidence of OOD hardness rather than label drift. No validation (human re-annotation agreement rates, automated consistency checks between source and rewritten trajectories, or inter-annotator statistics) is described.
Authors: We agree that explicit validation of label preservation is important to rule out label drift. The ROME pipeline preserves risk labels by design: it begins with 100 source trajectories that have established unsafe labels and applies targeted rewrites only to increase deception (via contextual ambiguity, implicit risks, and shortcut decision-making) while keeping the core violation category unchanged. To address the referee's concern, the revised manuscript will include a new validation subsection with automated consistency checks (semantic similarity and risk-category preservation via an LLM judge) plus a human re-annotation study on a 20% subset, reporting inter-annotator agreement rates (Cohen's kappa). revision: yes
-
Referee: [Abstract] Abstract: The reported degradation on challenge sets and gains from ARISE rest on unreported experimental details, including model list, baselines, number of trials, error bars, statistical tests, and how label preservation was verified. Without these, the quantitative claims cannot be evaluated.
Authors: We apologize that these details were not sufficiently highlighted. Section 4 of the manuscript already specifies the evaluated models (GPT-4o, Claude-3.5-Sonnet, Llama-3.1-405B-Instruct, Gemini-1.5-Pro), baselines (zero-shot, chain-of-thought, standard few-shot), number of trials (five independent runs per condition), error bars (mean ± standard deviation), and statistical tests (paired t-tests with p < 0.05 threshold). Label-preservation verification is described via the controlled rewrite rules in Section 3. In the revision we will add a consolidated experimental-setup table and move the verification protocol into the main text for easier evaluation. revision: partial
-
Referee: [Abstract] Abstract: ARISE is presented as improving judgment quality via retrieved analogical trajectories, yet no ablation is mentioned to establish that the retrieved exemplars are relevant and causally responsible for the gains (as opposed to generic prompting effects).
Authors: We acknowledge that a targeted ablation would more convincingly isolate the contribution of analogical relevance. Our current experiments already compare ARISE against a generic few-shot prompting baseline without retrieval. For the revision we will add an explicit ablation that replaces the retrieved analogical trajectories with either random trajectories or semantically unrelated ones from the same base; the performance difference will be reported to demonstrate that gains stem from relevance rather than generic prompting. revision: yes
Circularity Check
No circularity; empirical benchmark construction and inference-time method are self-contained
full rationale
The paper describes ROME as a multi-agent rewriting pipeline that starts from known unsafe trajectories and produces new instances while asserting preservation of risk labels, then evaluates model performance degradation on these instances. ARISE is presented as a retrieval-based inference-time technique that injects analogical exemplars. Both are supported by direct experiments on frontier models rather than any derivation, equation, or fitted parameter that reduces to the input by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes; the central claims rest on observable performance shifts against external models. This is standard empirical AI research with no self-definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rewritten trajectories preserve their original risk labels while increasing contextual ambiguity and implicit risks
Reference graph
Works this paper leans on
-
[1]
2025 , journal=
Agentic Misalignment: How LLMs Could be an Insider Threat , author=. 2025 , journal=
2025
-
[2]
Conference on Empirical Methods in Natural Language Processing , year=
R-Judge: Benchmarking Safety Risk Awareness for LLM Agents , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[3]
ArXiv , year=
Agent-SafetyBench: Evaluating the Safety of LLM Agents , author=. ArXiv , year=
-
[4]
Frontiers Comput
A Survey on Large Language Model based Autonomous Agents , author=. Frontiers Comput. Sci. , year=
-
[5]
International Conference on Learning Representations , year=
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , author=. International Conference on Learning Representations , year=
-
[7]
ArXiv , year=
Breaking Agents: Compromising Autonomous LLM Agents Through Malfunction Amplification , author=. ArXiv , year=
-
[8]
Annual Meeting of the Association for Computational Linguistics , year=
BadAgent: Inserting and Activating Backdoor Attacks in LLM Agents , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[9]
ArXiv , year=
Compromising Embodied Agents with Contextual Backdoor Attacks , author=. ArXiv , year=
-
[10]
ArXiv , year=
AgentPoison: Red-teaming LLM Agents via Poisoning Memory or Knowledge Bases , author=. ArXiv , year=
-
[11]
ArXiv , year=
PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety , author=. ArXiv , year=
-
[12]
ArXiv , year=
AutoDefense: Multi-Agent LLM Defense against Jailbreak Attacks , author=. ArXiv , year=
-
[13]
Conference on Empirical Methods in Natural Language Processing , year=
TrustAgent: Towards Safe and Trustworthy LLM-based Agents , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[14]
2024 , url=
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning , author=. 2024 , url=
2024
-
[15]
arXiv e-prints , pages=
Agentdojo: A dynamic environment to evaluate attacks and defenses for llm agents , author=. arXiv e-prints , pages=
-
[16]
PNAS Nexus , year=
Evidence from counterfactual tasks supports emergent analogical reasoning in large language models , author=. PNAS Nexus , year=
-
[17]
ArXiv , year=
Large Language Models as Analogical Reasoners , author=. ArXiv , year=
-
[18]
ArXiv , year=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. ArXiv , year=
-
[19]
Conference on Empirical Methods in Natural Language Processing , year=
A Survey on In-context Learning , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[20]
Proceedings of the 2021 International Conference on Management of Data , pages=
Milvus: A Purpose-Built Vector Data Management System , author=. Proceedings of the 2021 International Conference on Management of Data , pages=
2021
-
[24]
Claude 3.7 Sonnet System Card , author=
-
[26]
Conference on Empirical Methods in Natural Language Processing , year=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[27]
Structure-Mapping: A Theoretical Framework for Analogy , author=. Cogn. Sci. , year=
-
[28]
The Oxford handbook of thinking and reasoning , pages=
13 analogy and relational reasoning , author=. The Oxford handbook of thinking and reasoning , pages=. 2012 , publisher=
2012
-
[29]
International Conference on Learning Representations (ICLR) , year=
React: Synergizing reasoning and acting in language models , author=. International Conference on Learning Representations (ICLR) , year=
-
[31]
Available: https://arxiv.org/abs/2407.12784
Chen, Z., Xiang, Z., Xiao, C., Song, D. X., and Li, B. Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases. ArXiv, abs/2407.12784, 2024. URL https://api.semanticscholar.org/CorpusID:271244867
-
[32]
Agentdojo: A dynamic environment to evaluate attacks and defenses for llm agents
Debenedetti, E., Zhang, J., Balunovi \'c , M., Beurer-Kellner, L., Fischer, M., and Tram \`e r, F. Agentdojo: A dynamic environment to evaluate attacks and defenses for llm agents. arXiv e-prints, pp.\ arXiv--2406, 2024
2024
-
[33]
A survey on in-context learning
Dong, Q., Li, L., Dai, D., Zheng, C., Wu, Z., Chang, B., Sun, X., Xu, J., Li, L., and Sui, Z. A survey on in-context learning. In Conference on Empirical Methods in Natural Language Processing, 2022. URL https://api.semanticscholar.org/CorpusID:255372865
2022
-
[34]
Structure-mapping: A theoretical framework for analogy
Gentner, D. Structure-mapping: A theoretical framework for analogy. Cogn. Sci., 7: 0 155--170, 1983. URL https://api.semanticscholar.org/CorpusID:5371492
1983
-
[35]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Holyoak, K. J. 13 analogy and relational reasoning. The Oxford handbook of thinking and reasoning, pp.\ 234, 2012
2012
-
[37]
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Zhang, C., Wang, J., Wang, Z., Yau, S. K. S., Lin, Z. H., Zhou, L., Ran, C., Xiao, L., Wu, C., and Schmidhuber, J. Metagpt: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations, 2023. URL https://api.semanticscholar.org/CorpusID:265301950
2023
-
[38]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review arXiv 2024
-
[39]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Kuttler, H., Lewis, M., tau Yih, W., Rockt \"a schel, T., Riedel, S., and Kiela, D. Retrieval-augmented generation for knowledge-intensive nlp tasks. ArXiv, abs/2005.11401, 2020. URL https://api.semanticscholar.org/CorpusID:218869575
work page internal anchor Pith review arXiv 2005
-
[40]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024 a
work page internal anchor Pith review arXiv 2024
-
[41]
Compromisingembodiedagentswithcontextualbackdoorattacks
Liu, A., Zhou, Y., Liu, X., Zhang, T., Liang, S., Wang, J., Pu, Y., Li, T., Zhang, J., Zhou, W., Guo, Q., and Tao, D. Compromising embodied agents with contextual backdoor attacks. ArXiv, abs/2408.02882, 2024 b . URL https://api.semanticscholar.org/CorpusID:271719834
-
[42]
K., Ritchie, S
Lynch, A., Wright, B., Larson, C., Troy, K. K., Ritchie, S. J., Mindermann, S., Perez, E., and Hubinger, E. Agentic misalignment: How llms could be an insider threat. Anthropic Research, 2025. https://www.anthropic.com/research/agentic-misalignment
2025
-
[43]
and Gurevych, I
Reimers, N. and Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. In Conference on Empirical Methods in Natural Language Processing, 2019. URL https://api.semanticscholar.org/CorpusID:201646309
2019
-
[44]
Milvus: A purpose-built vector data management system
Wang, J., Yi, X., Guo, R., Jin, H., Xu, P., Li, S., Wang, X., Guo, X., Li, C., Xu, X., et al. Milvus: A purpose-built vector data management system. In Proceedings of the 2021 International Conference on Management of Data, pp.\ 2614--2627, 2021
2021
-
[45]
X., Wei, Z., and rong Wen, J
Wang, L., Ma, C., Feng, X., Zhang, Z., ran Yang, H., Zhang, J., Chen, Z.-Y., Tang, J., Chen, X., Lin, Y., Zhao, W. X., Wei, Z., and rong Wen, J. A survey on large language model based autonomous agents. Frontiers Comput. Sci., 18: 0 186345, 2023. URL https://api.semanticscholar.org/CorpusID:261064713
2023
-
[46]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review arXiv 2022
-
[47]
Badagent: Inserting and activating backdoor attacks in llm agents
Wang, Y., Xue, D., Zhang, S., and Qian, S. Badagent: Inserting and activating backdoor attacks in llm agents. In Annual Meeting of the Association for Computational Linguistics, 2024. URL https://api.semanticscholar.org/CorpusID:270258249
2024
-
[48]
J., and Lu, H
Webb, T., Holyoak, K. J., and Lu, H. Evidence from counterfactual tasks supports emergent analogical reasoning in large language models. PNAS Nexus, 4, 2024. URL https://api.semanticscholar.org/CorpusID:269293647
2024
-
[49]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[50]
React: Synergizing reasoning and acting in language models
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023
2023
-
[51]
doi: 10.48550/arXiv.2310.01714
Yasunaga, M., Chen, X., Li, Y., Pasupat, P., Leskovec, J., Liang, P., hsin Chi, E. H., and Zhou, D. Large language models as analogical reasoners. ArXiv, abs/2310.01714, 2023. URL https://api.semanticscholar.org/CorpusID:263608847
-
[52]
R-judge: Benchmarking safety risk awareness for llm agents
Yuan, T., He, Z., Dong, L., Wang, Y., Zhao, R., Xia, T., Xu, L., Zhou, B., Li, F., Zhang, Z., Wang, R., and Liu, G. R-judge: Benchmarking safety risk awareness for llm agents. In Conference on Empirical Methods in Natural Language Processing, 2024. URL https://api.semanticscholar.org/CorpusID:267034935
2024
-
[53]
doi: 10.18653/v1/2024.findings-acl.624
Zhan, Q., Liang, Z., Ying, Z., and Kang, D. I njec A gent: Benchmarking indirect prompt injections in tool-integrated large language model agents. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 10471--10506, Bangkok, Thailand, August 2024. Association for Computational Linguist...
-
[54]
Breaking agents: Compromising autonomous LLM agents through malfunction amplification
Zhang, B., Tan, Y., Shen, Y., Salem, A., Backes, M., Zannettou, S., and Zhang, Y. Breaking agents: Compromising autonomous llm agents through malfunction amplification. ArXiv, abs/2407.20859, 2024 a . URL https://api.semanticscholar.org/CorpusID:271543820
-
[55]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Zhang, Z., Cui, S., Lu, Y., Zhou, J., Yang, J., Wang, H., and Huang, M. Agent-safetybench: Evaluating the safety of llm agents. ArXiv, abs/2412.14470, 2024 b . URL https://api.semanticscholar.org/CorpusID:274859514
work page internal anchor Pith review arXiv 2024
-
[56]
Zhang, Z., Zhang, Y., Li, L., Gao, H., Wang, L., Lu, H., Zhao, F., Qiao, Y., and Shao, J. Psysafe: A comprehensive framework for psychological-based attack, defense, and evaluation of multi-agent system safety. ArXiv, abs/2401.11880, 2024 c . URL https://api.semanticscholar.org/CorpusID:267069372
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.