Recognition: unknown
Text-Conditional JEPA for Learning Semantically Rich Visual Representations
Pith reviewed 2026-05-07 17:54 UTC · model grok-4.3
The pith
TC-JEPA conditions masked feature prediction on text captions via sparse cross-attention to produce more semantically rich visual representations and outperforms contrastive methods on fine-grained tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TC-JEPA also offers a new vision-language pretraining paradigm based on feature prediction only, outperforming contrastive methods on diverse tasks, especially those requiring fine-grained visual understanding and reasoning.
Load-bearing premise
That modulating predicted patch features with a text conditioner via sparse cross-attention will reliably reduce visual uncertainty in a way that produces semantically meaningful representations without introducing text-specific biases or requiring perfectly aligned captions.
Figures










read the original abstract
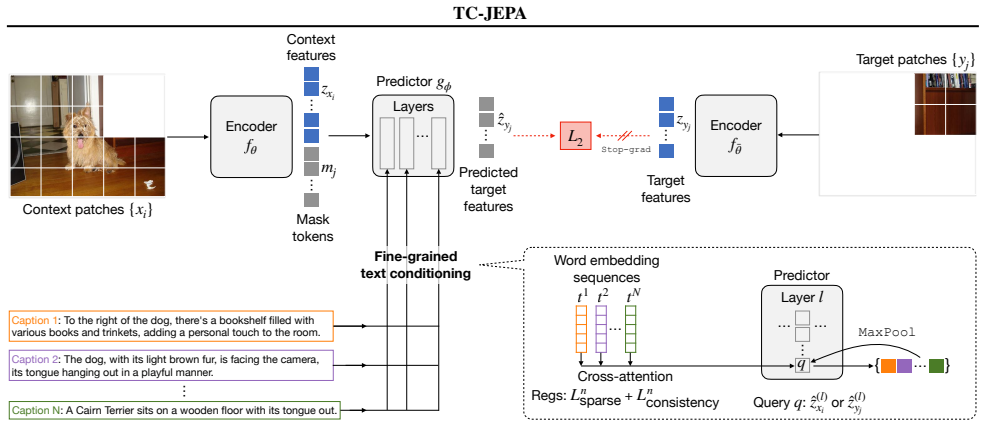
Image-based Joint-Embedding Predictive Architecture (I-JEPA) offers a promising approach to visual self-supervised learning through masked feature prediction. However with the inherent visual uncertainty at masked positions, feature prediction remains challenging and may fail to learn semantic representations. In this work, we propose Text-Conditional JEPA (TC-JEPA) that uses image captions to reduce the prediction uncertainty. Specifically, we modulate the predicted patch features using a fine-grained text conditioner that computes sparse cross-attention over input text tokens. With such conditioning, patch features become predictable as a function of text, thus are more semantically meaningful. We show TC-JEPA improves downstream performance and training stability, with promising scaling properties. TC-JEPA also offers a new vision-language pretraining paradigm based on feature prediction only, outperforming contrastive methods on diverse tasks, especially those requiring fine-grained visual understanding and reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Text-Conditional JEPA (TC-JEPA) as an extension of I-JEPA for visual self-supervised learning. It introduces a fine-grained text conditioner that uses sparse cross-attention over image captions to modulate predicted patch features, with the goal of reducing visual uncertainty at masked positions and yielding more semantically meaningful representations. The authors claim this leads to improved downstream performance, better training stability, favorable scaling, and outperformance over contrastive vision-language methods on diverse tasks, particularly those needing fine-grained visual understanding and reasoning.
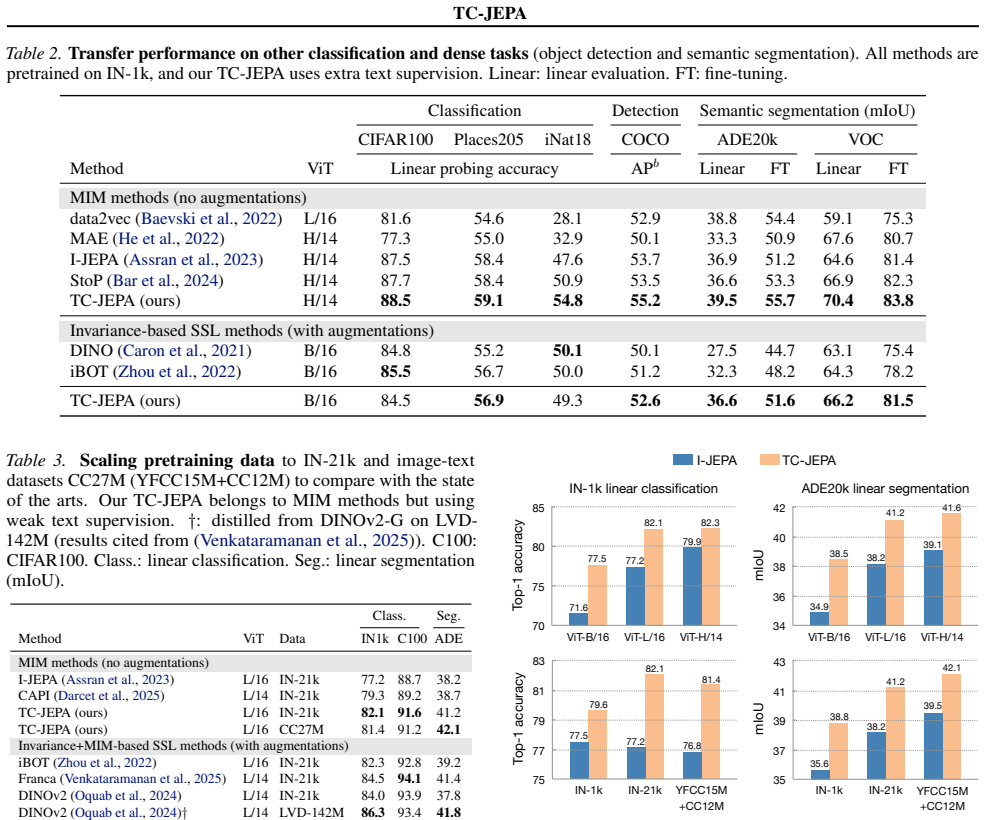
Significance. If the central empirical claims hold after addressing controls for text biases, the work could establish a viable feature-prediction-based alternative to contrastive vision-language pretraining. This would be notable for potentially learning robust visual semantics without relying on negative samples or explicit alignment losses, with possible benefits for reasoning-heavy downstream tasks. The scaling properties, if demonstrated rigorously, would add to the practical appeal.
major comments (3)
- [Abstract] Abstract: The central claim that modulating predicted patch features via the text conditioner produces 'more semantically meaningful' representations (because they become 'predictable as a function of text') is load-bearing for the entire contribution, yet the abstract supplies no quantitative results, ablation studies, or controls. Without these, it is impossible to determine whether gains arise from reduced visual uncertainty or from exploitation of caption statistics and linguistic priors.
- [Method] Method section (text conditioner description): The sparse cross-attention mechanism is presented at a high level without equations or pseudocode showing how sparsity is enforced or how the modulation interacts with the JEPA predictor. This leaves open the possibility that the predictor relies on global text features rather than forcing the visual encoder to resolve fine-grained details, directly undermining the self-supervised interpretation and the claimed superiority on reasoning tasks.
- [Experiments] Experiments section: The assertions of outperformance over contrastive methods and improvements on fine-grained tasks lack reported effect sizes, baseline details, statistical tests, or controls such as mismatched/randomized captions. These omissions make it impossible to assess whether the results support the claim that the approach avoids text-specific biases.
minor comments (2)
- [Abstract] The abstract contains a grammatical error: 'However with the inherent' should read 'However, with the inherent'.
- Notation for the text conditioner and its integration with the JEPA predictor should be introduced with explicit equations or a clear diagram to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications where needed and indicating the revisions incorporated into the manuscript.
read point-by-point responses
-
Referee: [Abstract] The central claim that modulating predicted patch features via the text conditioner produces 'more semantically meaningful' representations (because they become 'predictable as a function of text') is load-bearing for the entire contribution, yet the abstract supplies no quantitative results, ablation studies, or controls. Without these, it is impossible to determine whether gains arise from reduced visual uncertainty or from exploitation of caption statistics and linguistic priors.
Authors: We agree that the abstract should more explicitly support the central claims with quantitative evidence. In the revised manuscript we have updated the abstract to report specific downstream gains (e.g., absolute improvements on fine-grained classification and reasoning benchmarks) and to reference the ablation studies and mismatched-caption controls that appear in the experiments section. These additions make the source of the gains clearer while remaining within length constraints. revision: yes
-
Referee: [Method] The sparse cross-attention mechanism is presented at a high level without equations or pseudocode showing how sparsity is enforced or how the modulation interacts with the JEPA predictor. This leaves open the possibility that the predictor relies on global text features rather than forcing the visual encoder to resolve fine-grained details, directly undermining the self-supervised interpretation and the claimed superiority on reasoning tasks.
Authors: We appreciate the referee highlighting the need for greater technical precision. The original submission described the sparse cross-attention at a conceptual level; we have now added the explicit equations for the top-k sparsity mask and the modulation step, together with a short pseudocode block that shows how the text-conditioned target features are supplied to the JEPA predictor. These additions confirm that the visual encoder must resolve fine-grained patch details to match the conditioned predictions, preserving the self-supervised character of the objective. revision: yes
-
Referee: [Experiments] The assertions of outperformance over contrastive methods and improvements on fine-grained tasks lack reported effect sizes, baseline details, statistical tests, or controls such as mismatched/randomized captions. These omissions make it impossible to assess whether the results support the claim that the approach avoids text-specific biases.
Authors: Baseline details and direct comparisons with contrastive vision-language methods were already present in the experiments section. To address the remaining points we have added (i) effect-size reporting (Cohen’s d) and statistical significance tests across multiple random seeds, and (ii) new control experiments that replace captions with mismatched or randomly sampled text. The mismatched-caption runs show a clear performance drop, indicating that gains are not attributable to linguistic priors alone. These controls are now reported in the revised experiments section and appendix. revision: yes
Axiom & Free-Parameter Ledger
invented entities (1)
-
fine-grained text conditioner
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint-embedding predictive architecture
Assran, M., Duval, Q., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., LeCun, Y ., and Ballas, N. Self-supervised learning from images with a joint-embedding predictive architecture. InCVPR, 2023
2023
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Komeili, M., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., Arnaud, S., Gejji, A., Martin, A., Robert Hogan, F., Dugas, D., Bojanowski, P., Khalidov, V ., Labatut, P., Massa, F., Szafraniec, M., Krishnakumar, K., Li, Y ., Ma, X., Chandar, S., Meier, F., LeCun, Y ., Rab- bat, M., and Bal...
work page internal anchor Pith review arXiv
-
[2]
Back to the features: Dino as a foundation for video world models.arXiv preprint arXiv:2507.19468,
Baldassarre, F., Szafraniec, M., Terver, B., Khalidov, V ., Massa, F., LeCun, Y ., Labatut, P., Seitzer, M., and Bo- janowski, P. Back to the features: Dino as a foundation for video world models.arXiv preprint arXiv:2507.19468,
-
[3]
data2vec: A general framework for self-supervised learning in speech, vision and language
Baevski, A., Hsu, W.-N., Xu, Q., Babu, A., Gu, J., and Auli, M. data2vec: A general framework for self-supervised learning in speech, vision and language. InICML, 2022
2022
-
[3]
Revisiting Feature Prediction for Learning Visual Representations from Video
Bardes, A., Garrido, Q., Ponce, J., Rabbat, M., LeCun, Y ., Assran, M., and Ballas, N. Revisiting feature prediction for learning visual representations from video.arXiv preprint arXiv:2404.08471,
work page internal anchor Pith review arXiv
-
[4]
S., Bugliarello, E., Wang, X., Yu, Q., Chen, L.-C., and Zhai, X
Beyer, L., Wan, B., Madan, G., Pavetic, F., Steiner, A., Kolesnikov, A., Pinto, A. S., Bugliarello, E., Wang, X., Yu, Q., Chen, L.-C., and Zhai, X. A study of autoregres- sive decoders for multi-tasking in computer vision.arXiv preprint arXiv:2303.17376,
-
[5]
BEit: BERT pre- training of image transformers
Bao, H., Dong, L., Piao, S., and Wei, F. BEit: BERT pre- training of image transformers. InICLR, 2022
2022
-
[5]
An empirical study of training self- supervised vision transformers
Chen, X., Xie, S., and He, K. An empirical study of train- ing self-supervised vision transformers.arXiv preprint arXiv:2104.02057,
-
[6]
Stochastic positional embeddings improve masked image modeling
Ballas, N., Darrell, T., Globerson, A., and LeCun, Y . Stochastic positional embeddings improve masked image modeling. InICML, 2024
2024
-
[6]
Darcet, T., Baldassarre, F., Oquab, M., Mairal, J., and Bojanowski, P. Cluster and predict latents patches for improved masked image modeling.arXiv preprint arXiv:2502.08769,
-
[7]
Navigation world models
Bar, A., Zhou, G., Tran, D., Darrell, T., and LeCun, Y . Navigation world models. InCVPR, 2025
2025
-
[7]
Garrido, Q., Assran, M., Ballas, N., Bardes, A., Najman, L., and LeCun, Y . Learning and leveraging world mod- els in visual representation learning.arXiv preprint arXiv:2403.00504,
-
[8]
Liu, H., Li, C., Li, Y ., and Lee, Y . J. Improved base- lines with visual instruction tuning.arXiv preprint arXiv:2310.03744,
work page internal anchor Pith review arXiv
-
[9]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M. F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y ., Mustafa, B., H ´enaff, O., Harmsen, J., Steiner, A., and Zhai, X. SigLIP 2: Multilingual vision- language encoders with improved semantic understand- ing, localization, and dense features.arXiv preprint arXiv:2502.14786,
work page internal anchor Pith review arXiv
-
[10]
A., Minderer, M., Blundell, C., Pascanu, R., and Mitrovic, J
Kaplanis, C., Gritsenko, A. A., Minderer, M., Blundell, C., Pascanu, R., and Mitrovic, J. Improving fine-grained understanding in image-text pre-training. InICML, 2024
2024
-
[10]
Venkataramanan, S., Pariza, V ., Salehi, M., Knobel, L., Gidaris, S., Ramzi, E., Bursuc, A., and Asano, Y . M. Franca: Nested matryoshka clustering for scalable visual representation learning.arXiv preprint arXiv:2507.14137,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Emerging properties in self-supervised vision transformers
Bojanowski, P., and Joulin, A. Emerging properties in self-supervised vision transformers. InICCV, 2021
2021
-
[11]
Text Conditioning on Holistic Caption Embedding In the main paper, we introduce a text conditioning method based on the word embedding sequencet= [t 1,
11 TC-JEPA A. Text Conditioning on Holistic Caption Embedding In the main paper, we introduce a text conditioning method based on the word embedding sequencet= [t 1, . . . , tS]∈R dt×S of a text caption sentence. In the literature, there are alternative conditioning methods that use the holistic caption embedding in various domains,e.g., (Lavoie et al., 2...
2024
-
[12]
Con- ceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Changpinyo, S., Sharma, P., Ding, N., and Soricut, R. Con- ceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InCVPR, 2021
2021
-
[12]
Specifically, we feed ¯t to an AdaLN block to generate scale and shift coefficients that modulate the LayerNorm outputs of each predictor layer
provides an efficient way to text condition the predictor gϕ on aggregated ¯t. Specifically, we feed ¯t to an AdaLN block to generate scale and shift coefficients that modulate the LayerNorm outputs of each predictor layer. {¯tn} of different captions produce different modulation outputs at each layer, which is max-pooled again. The parameters of the AdaL...
2024
-
[13]
Contrastive localized language-image pre-training
Chen, H.-Y ., Lai, J., Zhang, H., Wang, A., Eichner, M., You, K., Cao, M., Zhang, B., Yang, Y ., and Gan, Z. Contrastive localized language-image pre-training. InICML, 2025
2025
-
[13]
Tuning the learning rate and weight-decay schedules does not bring much benefit in our experiments
including the fixed batch size 2048, max learning rate 10−3 with a warmup and then cosine decay schedule, and weight decay linearly increased from 0.04 to 0.4. Tuning the learning rate and weight-decay schedules does not bring much benefit in our experiments. Instead, we found our properly regularized TC-JEPA objective makes JEPA learning robust when cond...
2048
-
[14]
ShareGPT4V: Improving large multi- modal models with better captions
Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., and Lin, D. ShareGPT4V: Improving large multi- modal models with better captions. InECCV, 2024
2024
-
[14]
Semantic segmentation.We consider the two setups in (Zhou et al., 2022; Bao et al.,
is fine-tuned with 1 × schedule for 12 epochs, using the same fine-tuning hyperparameters. Semantic segmentation.We consider the two setups in (Zhou et al., 2022; Bao et al.,
2022
-
[15]
Big self-supervised models are strong semi- supervised learners
Hinton, G. Big self-supervised models are strong semi- supervised learners. InNeurIPS, 2020
2020
-
[15]
Concretely, a single 12-layer autoregressive decoder is trained on the frozen encoder, which learns a multi-task model for captioning and VQA
on top in a multi-task setup. Concretely, a single 12-layer autoregressive decoder is trained on the frozen encoder, which learns a multi-task model for captioning and VQA. We carefully follow the official implementation and similarly use a unified image preprocessing across tasks. To ease multi-task training on different task data (COCO, GQA and VQAv2), ...
2015
-
[16]
These models generate captions of different quality and styles, and their outputs are usually shorter or less descriptive than those from the default ShareGPT4V model
and InstructBLIP (Dai et al., 2023). These models generate captions of different quality and styles, and their outputs are usually shorter or less descriptive than those from the default ShareGPT4V model. Fig. 12 compares their text conditioning effects when pretraining ViT-L/16 encoder on the enriched YFCC15M dataset with varying N, the number of randoml...
2023
-
[17]
InstructBLIP: Towards general- purpose vision-language models with instruction tuning
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P., and Hoi, S. InstructBLIP: Towards general- purpose vision-language models with instruction tuning. InNeurIPS, 2023
2023
-
[19]
MaskCLIP: Masked self-distillation advances contrastive language-image pretraining
Dong, X., Bao, J., Zheng, Y ., Zhang, T., Chen, D., Yang, H., Zeng, M., Zhang, W., Yuan, L., Chen, D., Wen, F., and Yu, N. MaskCLIP: Masked self-distillation advances contrastive language-image pretraining. InCVPR, 2023. 9 TC-JEPA
2023
-
[20]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[21]
The pascal visual object classes challenge: A retrospective.IJCV, 111(1):98–136, 2015
Winn, J., and Zisserman, A. The pascal visual object classes challenge: A retrospective.IJCV, 111(1):98–136, 2015
2015
-
[22]
Scaling language-free visual representation learning
Rabbat, M., Ballas, N., LeCun, Y ., Bar, A., et al. Scaling language-free visual representation learning. InICCV, 2025
2025
-
[24]
VISSL.https:// github.com/facebookresearch/vissl, 2021
Lefaudeux, B., Singh, M., Reis, V ., Caron, M., Bo- janowski, P., Joulin, A., and Misra, I. VISSL.https:// github.com/facebookresearch/vissl, 2021
2021
-
[25]
Making the V in VQA matter: Elevating the role of image understanding in Visual Question An- swering
Parikh, D. Making the V in VQA matter: Elevating the role of image understanding in Visual Question An- swering. InCVPR, 2017
2017
-
[26]
H., Buchatskaya, E., Doersch, C., Pires, B
Grill, J.-B., Strub, F., Altch ´e, F., Tallec, C., Richemond, P. H., Buchatskaya, E., Doersch, C., Pires, B. A., Guo, Z. D., Azar, M. G., Piot, B., Kavukcuoglu, K., Munos, R., and Valko, M. Bootstrap your own latent a new approach to self-supervised learning. InNeurIPS, 2020
2020
-
[27]
Mask R-CNN
He, K., Gkioxari, G., Doll ´ar, P., and Girshick, R. Mask R-CNN. InICCV, pp. 2980–2988, 2017
2017
-
[28]
Masked autoencoders are scalable vision learners
He, K., Chen, X., Xie, S., Li, Y ., Doll´ar, P., and Girshick, R. Masked autoencoders are scalable vision learners. In CVPR, 2022
2022
-
[29]
MAST: Masked augmentation subspace training for generalizable self- supervised priors
Huang, C., Goh, H., Gu, J., and Susskind, J. MAST: Masked augmentation subspace training for generalizable self- supervised priors. InICLR, 2023
2023
-
[30]
Hudson, D. A. and Manning, C. D. GQA: A new dataset for real-world visual reasoning and compositional question answering. InCVPR, 2019
2019
-
[31]
Learning multiple layers of features from tiny images
Krizhevsky, A. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[32]
G., Courville, A., and Ballas, N
Lavoie, S., Kirichenko, P., Ibrahim, M., Assran, M., Wilson, A. G., Courville, A., and Ballas, N. Modeling caption diversity in contrastive vision-language pretraining. In ICML, 2024
2024
-
[33]
R., Gotmare, A
Li, J., Selvaraju, R. R., Gotmare, A. D., Joty, S., Xiong, C., and Hoi, S. Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021
2021
-
[34]
Ramanan, D., Doll ´ar, P., and Zitnick, C. L. Microsoft COCO: common objects in context. InECCV, 2014
2014
-
[35]
Enhancing JEPAs with spatial conditioning: Robust and efficient representation learning
Littwin, E., Thilak, V ., and Gopalakrishnan, A. Enhancing JEPAs with spatial conditioning: Robust and efficient representation learning. InNeurIPS SSL Workshop, 2024
2024
-
[37]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization. InICLR, 2019
2019
-
[38]
F., Xian, Y ., Zhai, X., Hoyer, L., Van Gool, L., and Tombari, F
Naeem, M. F., Xian, Y ., Zhai, X., Hoyer, L., Van Gool, L., and Tombari, F. SILC: Improving vision language pretraining with self-distillation. InECCV, 2024
2024
-
[39]
DINOv2: Learning robust visual features without super- vision.TMLR, 2024
Mairal, J., Labatut, P., Joulin, A., and Bojanowski, P. DINOv2: Learning robust visual features without super- vision.TMLR, 2024. ISSN 2835-8856
2024
-
[40]
Learning transferable visual models from natural language supervision
Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[41]
Matena, M., Zhou, Y ., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer.JMLR, 21(140):1–67, 2020
2020
-
[42]
Imagenet large scale visual recognition challenge.IJCV, 115(3):211–252, 2015
Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A., and Fei-Fei, L. Imagenet large scale visual recognition challenge.IJCV, 115(3):211–252, 2015. 10 TC-JEPA
2015
-
[43]
Saharia, C., Chan, W., Saxena, S., Lit, L., Whang, J., Den- ton, E., Ghasemipour, S. K. S., Ayan, B. K., Mahdavi, S. S., Gontijo-Lopes, R., Salimans, T., Ho, J., Fleet, D. J., and Norouzi, M. Photorealistic text-to-image diffusion models with deep language understanding. InNeurIPS, 2022
2022
-
[44]
A., Friedland, G., Elizalde, B., Ni, K., Poland, D., Borth, D., and Li, L.-J
Thomee, B., Shamma, D. A., Friedland, G., Elizalde, B., Ni, K., Poland, D., Borth, D., and Li, L.-J. YFCC100M: the new data in multimedia research.Commun. ACM, 59(2): 64–73, 2016
2016
-
[46]
The inaturalist species classification and detection dataset
Shepard, A., Adam, H., Perona, P., and Belongie, S. The inaturalist species classification and detection dataset. In CVPR, 2018
2018
-
[47]
L., and Parikh, D
Vedantam, R., Zitnick, C. L., and Parikh, D. CIDEr: Consensus-based image description evaluation. InCVPR, 2015
2015
-
[49]
Towards visual grounding: A survey.TPAMI, pp
Xiao, L., Yang, X., Lan, X., Wang, Y ., and Xu, C. Towards visual grounding: A survey.TPAMI, pp. 1–20, 2025
2025
-
[50]
Unified perceptual parsing for scene understanding
Xiao, T., Liu, Y ., Zhou, B., Jiang, Y ., and Sun, J. Unified perceptual parsing for scene understanding. InECCV, 2018
2018
-
[51]
A., and Darrell, T
Xiao, T., Wang, X., Efros, A. A., and Darrell, T. What should not be contrastive in contrastive learning. InICLR, 2021
2021
-
[52]
Demystifying CLIP data
Xu, H., Xie, S., Tan, X., Huang, P.-Y ., Howes, R., Sharma, V ., Li, S.-W., Ghosh, G., Zettlemoyer, L., and Feichten- hofer, C. Demystifying CLIP data. InICLR, 2024
2024
-
[53]
Under- standing and improving layer normalization
Xu, J., Sun, X., Zhang, Z., Zhao, G., and Lin, J. Under- standing and improving layer normalization. InNeurIPS, 2019
2019
-
[54]
GroupViT: Semantic segmentation emerges from text supervision
Xu, J., De Mello, S., Liu, S., Byeon, W., Breuel, T., Kautz, J., and Wang, X. GroupViT: Semantic segmentation emerges from text supervision. InCVPR, 2022
2022
-
[55]
FILIP: Fine-grained interactive language-image pre-training
Yao, L., Huang, R., Hou, L., Lu, G., Niu, M., Xu, H., Liang, X., Li, Z., Jiang, X., and Xu, C. FILIP: Fine-grained interactive language-image pre-training. InICLR, 2022
2022
-
[56]
CoCa: Contrastive captioners are image- text foundation models.TMLR, 2022
Yu, J., Wang, Z., Vasudevan, V ., Yeung, L., Seyedhosseini, M., and Wu, Y . CoCa: Contrastive captioners are image- text foundation models.TMLR, 2022. ISSN 2835-8856
2022
-
[57]
When and why vision-language models behave like bags-of-words, and what to do about it? InICLR, 2023
Zou, J. When and why vision-language models behave like bags-of-words, and what to do about it? InICLR, 2023
2023
-
[58]
Sig- moid loss for language image pre-training
Zhai, X., Mustafa, B., Kolesnikov, A., and Beyer, L. Sig- moid loss for language image pre-training. InICCV, 2023
2023
-
[59]
DreamLIP: Language-image pre-training with long captions
Chen, W., and Shen, Y . DreamLIP: Language-image pre-training with long captions. InECCV, 2024
2024
-
[60]
Learning deep features for scene recognition using places database
Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., and Oliva, A. Learning deep features for scene recognition using places database. InNeurIPS, 2014
2014
-
[61]
Scene parsing through ADE20K dataset
Torralba, A. Scene parsing through ADE20K dataset. In CVPR, 2017
2017
-
[62]
DINO-WM: World models on pre-trained visual features enable zero- shot planning
Zhou, G., Pan, H., LeCun, Y ., and Pinto, L. DINO-WM: World models on pre-trained visual features enable zero- shot planning. InICML, 2025
2025
-
[63]
iBOT: Image bert pre-training with online tokenizer.ICLR, 2022
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., and Kong, T. iBOT: Image bert pre-training with online tokenizer.ICLR, 2022. 11 TC-JEPA A. Text Conditioning on Holistic Caption Embedding In the main paper, we introduce a text conditioning method based on the word embedding sequencet= [t 1, . . . , tS]∈R dt×S of a text caption sentence. In the ...
2022
-
[64]
Describe the image in short
Specifically, ShareGPT4V is queried with two prompts: 1) “Describe the image in short” that often generates succinct text descriptions in 1 to 2 captions (sentences) for a given image. 2) “Describe the image in detail” that generates a long list of detailed captions, each one often focusing on a different visual aspect. Note the text captions generated fr...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.