Recognition: unknown
The Right Answer, the Wrong Direction: Why Transformers Fail at Counting and How to Fix It
Pith reviewed 2026-05-07 17:48 UTC · model grok-4.3
The pith
Transformers represent counts accurately inside but store them in directions nearly orthogonal to the digit rows of the output head.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
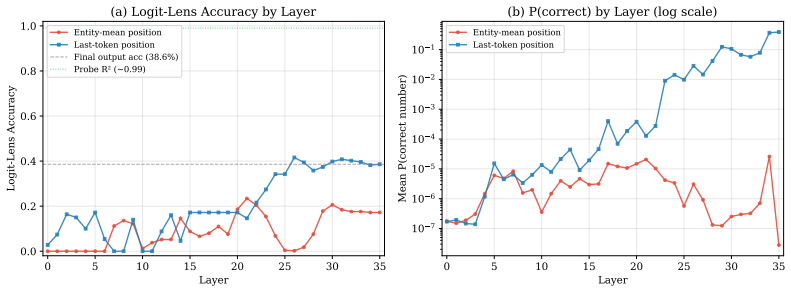
Across Pythia, Qwen3, and Mistral models, linear probes extract the correct count from hidden states with R² > 0.99, yet the count directions show cosine similarity at most 0.032 with the output-head rows for digit tokens. The information is therefore present but geometrically inaccessible to the token logits. Updating only the digit rows of the output head (36k parameters) raises constrained digit prediction to 100 percent, while a 7.7M-parameter LoRA on attention Q and V weights lifts true autoregressive generation to 83 percent and drops the correct digit's logit rank from roughly 56,000 to 1.
What carries the argument
Geometric readout bottleneck formed by the near-orthogonality between count-encoding directions in intermediate layers and the output-head rows for digit tokens.
If this is right
- Updating the 36,864 digit rows of the output head alone lifts constrained next-token digit prediction from 60.7 percent to 100 percent across four tasks.
- A 7.67M-parameter LoRA on attention Q/V weights raises greedy autoregressive counting to 83.1 percent while leaving broader reasoning benchmarks intact.
- The same misalignment appears in character counting, addition, and list-length tasks but is absent from MMLU, GSM8K, and DROP.
- Logit-lens measurements show the correct digit's vocabulary rank improving by a factor of 50,000 after the interventions.
Where Pith is reading between the lines
- Many apparent reasoning failures may trace to similar readout misalignments rather than missing internal representations.
- Training regimes could add explicit alignment losses between hidden-state directions and output-head rows for specific token classes.
- The pattern may generalize to other low-cardinality output vocabularies such as months or basic arithmetic operators.
Load-bearing premise
High probe accuracy plus low cosine similarity indicates a causal misalignment that the output-head or LoRA interventions can correct without harming other capabilities.
What would settle it
An experiment in which updating the digit rows of the output head or applying the LoRA leaves constrained and autoregressive counting accuracy unchanged or lower.
Figures


read the original abstract
Large language models often fail at simple counting tasks, even when the items to count are explicitly present in the prompt. We investigate whether this failure occurs because transformers do not represent counts internally, or because they cannot convert those representations into the correct output tokens. Across three model families, Pythia, Qwen3, and Mistral, ranging from 0.4B to 14B parameters, we find strong evidence for the second explanation. Linear probes recover the correct count from intermediate layers with near-perfect accuracy ($R^2>0.99$), showing that the information is present. However, the internal directions that encode counts are nearly orthogonal to the output-head rows for digit tokens ($|\cos|\leq0.032$). In other words, the model stores the count in a form that the digit logits do not naturally read out. We localize this failure with two interventions. Updating only the digit rows of the output head (36,864 parameters) substantially improves constrained next-token digit prediction (60.7 to 100.0% across four tasks), but it does not fix autoregressive generation. By contrast, a small LoRA intervention on attention Q/V weights (7.67M parameters) improves upstream routing and achieves 83.1% +/- 7.2% in true greedy autoregressive generation. Logit-lens measurements confirm the mechanism: the correct digit's vocabulary rank drops from 55,980 to 1, a 50,000x improvement. Additional norm, logit-lens, and cross-task analyses show that the bottleneck generalizes across character counting, addition, and list length, while remaining absent from broader multi-step reasoning benchmarks, including MMLU, GSM8K, and DROP. These results identify counting failure as a geometric readout bottleneck rather than a failure of internal representation: the model knows the count but the output pathway is geometrically misaligned with the tokens needed to express it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that transformer LLMs fail at counting tasks not because they lack internal representations of counts, but because those representations are geometrically misaligned with the output head. Linear probes recover counts from intermediate layers with R² > 0.99 across Pythia, Qwen3, and Mistral models (0.4B–14B), yet the count directions are nearly orthogonal to digit-token rows in the unembedding matrix (|cos| ≤ 0.032). Targeted interventions—updating only the 36,864 digit rows of the output head or applying a small LoRA to attention Q/V weights—improve constrained next-token prediction and autoregressive generation, respectively, with logit-lens confirming the mechanism via large rank improvements. The effect is shown to be selective to counting-like tasks and absent from broader reasoning benchmarks.
Significance. If the geometric-readout-bottleneck account holds, the work supplies a concrete, falsifiable explanation for a well-known LLM failure mode together with minimal, parameter-efficient fixes. Strengths include the convergence of three independent measurements (probes, cosine geometry, logit lens), cross-model and cross-task controls, and explicit distinction between constrained next-token prediction and full autoregressive generation. The results suggest that many apparent reasoning deficits may be addressable by aligning internal directions with the output vocabulary rather than by scaling or additional pre-training.
major comments (2)
- [Methods] Methods (probe training and intervention details): The manuscript reports R² > 0.99 for linear probes and large logit-rank gains after LoRA, but provides insufficient information on probe regularization, train/test splits, number of examples per count value, and whether the interventions were ablated against non-counting tasks to confirm specificity. Without these controls, it remains possible that the reported improvements reflect general capacity changes rather than correction of the claimed misalignment.
- [§4] §4 (intervention results): The output-head update achieves 100 % on constrained next-token prediction but leaves autoregressive generation broken, while the LoRA fix reaches only 83.1 % ± 7.2 % on greedy generation. The paper does not quantify side effects on non-counting capabilities (e.g., MMLU or GSM8K scores before/after), which is load-bearing for the claim that the bottleneck is isolated and fixable without broader degradation.
minor comments (2)
- [Abstract] The abstract and main text use “digit tokens” without clarifying whether this includes multi-digit numbers or only single digits 0–9; this affects interpretation of the 36,864-parameter count.
- [Figures] Figure captions and logit-lens plots should report the exact vocabulary size and rank statistics (mean, median, and top-1 accuracy) rather than only the single example of rank dropping from 55,980 to 1.
Simulated Author's Rebuttal
Thank you for the detailed review and positive recommendation for minor revision. We address each major comment below and will update the manuscript to include the requested details and analyses.
read point-by-point responses
-
Referee: [Methods] Methods (probe training and intervention details): The manuscript reports R² > 0.99 for linear probes and large logit-rank gains after LoRA, but provides insufficient information on probe regularization, train/test splits, number of examples per count value, and whether the interventions were ablated against non-counting tasks to confirm specificity. Without these controls, it remains possible that the reported improvements reflect general capacity changes rather than correction of the claimed misalignment.
Authors: We will revise the Methods section to provide full details on probe training, including regularization parameters, train/test splits, and the number of examples per count value. Additionally, we will include ablation studies demonstrating that the interventions do not improve performance on non-counting tasks, confirming the specificity of the effect to the geometric misalignment. revision: yes
-
Referee: [§4] §4 (intervention results): The output-head update achieves 100 % on constrained next-token prediction but leaves autoregressive generation broken, while the LoRA fix reaches only 83.1 % ± 7.2 % on greedy generation. The paper does not quantify side effects on non-counting capabilities (e.g., MMLU or GSM8K scores before/after), which is load-bearing for the claim that the bottleneck is isolated and fixable without broader degradation.
Authors: The current manuscript includes cross-task analyses showing that the misalignment is selective to counting-like tasks and absent from benchmarks such as MMLU, GSM8K, and DROP. To further quantify side effects, we will add before-and-after performance scores on these benchmarks following each intervention in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on direct empirical measurements: linear probes achieving R²>0.99 for count recovery from intermediate layers, cosine similarities |cos|≤0.032 between probe-derived directions and output-head rows, and performance gains from minimal interventions (output-head row updates and attention Q/V LoRA) corroborated by logit-lens rank improvements. These are observational results from probes, geometric calculations, and controlled experiments across model families, not derivations that reduce by construction to fitted inputs or self-citations. No equations, uniqueness theorems, or ansatzes are presented that would create self-definitional or load-bearing circularity; the analysis is self-contained against external benchmarks like MMLU and GSM8K.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Linear probes recover linearly encoded information about counts from hidden states when such information is present.
- domain assumption Low cosine similarity between count directions and output-head rows indicates a geometric readout bottleneck.
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. InICLR 2017 Workshop,
2017
-
[2]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112,
work page internal anchor Pith review arXiv
-
[3]
arXiv preprint arXiv:2303.09435 , year=
19 Alexander Yom Din, Taelin Karidi, Leshem Choshen, and Michal Shlain. Jump to conclusions: Short-cutting transformers with linear transformations.arXiv preprint arXiv:2303.09435,
-
[4]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy
Available athttps://transformer-circuits.pub/2022/ toy_model/index.html. Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495,
2022
-
[5]
Designing and interpreting probes with control tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 2733–2743,
2019
-
[6]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review arXiv
-
[7]
Neel Nanda, Andrew Lawrence, Trenton Chan, Tom Price, and Tom Henighan. Progress measures for grokking via mechanistic interpretability.arXiv preprint arXiv:2301.05217,
-
[8]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Available at https://transformer-circuits. pub/2022/in-context-learning-and-induction-heads/. Chang Park et al. The linear representation hypothesis and the geometry of large language models. arXiv preprint arXiv:2311.03658,
work page internal anchor Pith review arXiv 2022
-
[9]
Logan, Matt Gardner, and Sameer Singh
Yasaman Razeghi, Robert L Logan IV , Matt Gardner, and Sameer Singh. Impact of pretraining term frequencies on few-shot numerical reasoning.arXiv preprint arXiv:2202.07206,
-
[10]
Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis.arXiv preprint arXiv:2305.15054,
-
[11]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Lukas Berglund. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review arXiv
-
[12]
Do NLP models know numbers? probing numeracy in embeddings
Eric Wallace, Yizhong Wang, Sujian Li, Sameer Singh, and Matt Gardner. Do NLP models know numbers? probing numeracy in embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 5307–5315,
2019
-
[13]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.