Recognition: unknown
Causal Small Area Estimation with Survey-only Covariates
Pith reviewed 2026-05-07 13:17 UTC · model grok-4.3
The pith
Survey data combined with population covariates identifies area-specific treatment effects without observing treatment for the full population.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that area-specific average treatment effects are identifiable from a data structure in which treatment and outcome appear only in the survey sample while auxiliary covariates are available for the entire population. The identification combines the survey-only covariates with the population-level information to construct a doubly robust estimator that is consistent whenever either the outcome regression model or the treatment and area assignment models are correctly specified. The estimator is further shown to attain the semiparametric efficiency bound for the target parameter under regularity conditions.
What carries the argument
The doubly robust estimator that remains consistent if at least one of the outcome regression model or the treatment and area assignment models is correctly specified, using the combination of survey covariates and population auxiliary data to estimate area-specific effects.
If this is right
- The estimator stays consistent for the area-specific effects even when one of the two sets of models is misspecified.
- It reaches the semiparametric efficiency bound, meaning it has the smallest possible asymptotic variance among regular estimators.
- Finite-sample performance remains favorable when the number of observations per area is small.
- The method applies directly to evaluating treatment effects in small domains using standard survey sampling designs.
Where Pith is reading between the lines
- The same data-combination idea could be tested in settings where only a subset of covariates is observed at the population level rather than the full auxiliary vector.
- Applying the estimator to administrative records linked to surveys would provide a direct check on whether the efficiency bound is attained in practice.
- The framework suggests that survey designers could add a modest number of extra covariates to enable causal small-area analysis without expanding the sample size.
Load-bearing premise
That the survey-only covariates together with the population auxiliary information are sufficient to satisfy the conditions needed to identify the area-specific effects without bias.
What would settle it
A simulation in which the proposed estimator fails to recover the known true area-specific effect even when both the outcome regression model and the treatment and area models are correctly specified would show the consistency claim does not hold.
Figures
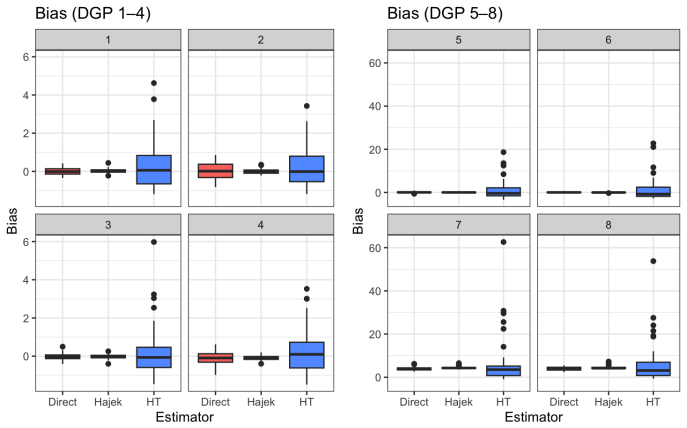




read the original abstract
Area-specific causal inference is important in many policy and survey applications, where the goal is to evaluate treatment effects for small geographic or demographic domains. Existing causal small area estimation methods, however, typically rely on a strong data requirement that treatment status is observed for all units in the population. This assumption is often unrealistic in practical survey settings, where both treatment and outcome variables are observed only for sampled units, while auxiliary covariates are available for the full population. To address this limitation, we develop a new identification strategy for area-specific treatment effects under this more realistic data structure by combining survey-only covariates with population-level auxiliary information. Based on this result, we propose a doubly robust estimator that remains consistent when either the outcome regression model or the treatment and area assignment models are correctly specified. We further derive the semiparametric efficiency bound for the target parameter and show that the proposed estimator attains this bound under regularity conditions. Simulation studies demonstrate favorable finite-sample performance, particularly in settings with small sample sizes within areas, and an empirical application illustrates the practical relevance of the proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a new identification strategy for area-specific treatment effects in settings where both treatment and outcome are observed only in a survey sample (with survey-only covariates), while auxiliary covariates are available for the full population. It proposes a doubly robust estimator that is consistent if either the outcome regression model or the treatment and area assignment models are correctly specified, derives the semiparametric efficiency bound for the target parameter, and shows that the estimator attains this bound under regularity conditions. The claims are supported by simulation studies demonstrating favorable finite-sample performance (especially for small within-area samples) and an empirical application.
Significance. If the identification, consistency, and efficiency results hold, this is a meaningful extension of causal small area estimation to more realistic survey data structures that do not require population-level treatment observations. The doubly robust property and attainment of the semiparametric efficiency bound are clear strengths, providing robustness to model misspecification and theoretical optimality. The simulation results for small sample sizes within areas and the empirical illustration add practical value for policy applications in small domains.
major comments (2)
- [§2] §2 (Identification): The central identification result for area-specific effects combines survey-only covariates with population auxiliaries, but the manuscript should explicitly list and justify the required causal assumptions (e.g., conditional ignorability given the observed covariates, positivity, and consistency) in this data structure, as these are load-bearing for the claimed new strategy and are only alluded to in the abstract.
- [§4] §4 (Efficiency bound): The derivation that the proposed estimator attains the semiparametric efficiency bound relies on regularity conditions; the paper should verify whether these conditions are standard or require additional restrictions due to the small-area marginalization and survey sampling weights, as this directly supports the efficiency claim.
minor comments (3)
- [Abstract, §3] Abstract and §3: The term 'treatment and area assignment models' is used without a clear definition of the area assignment component; a brief clarification or reference to the relevant equation would improve readability.
- [Simulation studies] Simulation section: The data-generating processes and specific parameter values used in the Monte Carlo studies should be reported in more detail (e.g., in a table or appendix) to allow full replication of the reported finite-sample results.
- Notation: The distinction between survey-only covariates and population-level auxiliaries is central but occasionally blurred in the text; consistent use of subscripts or superscripts would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. The comments identify opportunities to improve clarity on identification assumptions and the efficiency result, which we address point by point below.
read point-by-point responses
-
Referee: [§2] §2 (Identification): The central identification result for area-specific effects combines survey-only covariates with population auxiliaries, but the manuscript should explicitly list and justify the required causal assumptions (e.g., conditional ignorability given the observed covariates, positivity, and consistency) in this data structure, as these are load-bearing for the claimed new strategy and are only alluded to in the abstract.
Authors: We agree that an explicit statement of the causal assumptions will strengthen the presentation. In the revised manuscript we will insert a dedicated subsection in §2 that lists and justifies the three core assumptions in the context of the survey-plus-population data structure: (i) conditional ignorability of treatment and area assignment given the observed covariates (both survey-only and auxiliary), (ii) positivity (treatment and area probabilities bounded away from zero), and (iii) consistency. We will explain why these assumptions, together with the availability of population-level auxiliaries, suffice for the new identification result. revision: yes
-
Referee: [§4] §4 (Efficiency bound): The derivation that the proposed estimator attains the semiparametric efficiency bound relies on regularity conditions; the paper should verify whether these conditions are standard or require additional restrictions due to the small-area marginalization and survey sampling weights, as this directly supports the efficiency claim.
Authors: The regularity conditions invoked for the efficiency bound are the standard semiparametric conditions (asymptotic linearity, Donsker-class nuisance estimators, finite moments). We acknowledge that small-area marginalization and survey weights may introduce additional considerations. In the revision we will expand the discussion in §4 to verify that these standard conditions continue to hold under the survey design and marginalization, or to state any supplementary restrictions that are required, with appropriate references to the survey-sampling literature. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper formalizes a data structure with survey-only covariates and population-level auxiliaries, then derives an identification strategy for area-specific treatment effects, a doubly robust estimator consistent under correct specification of either the outcome or treatment/area models, and the semiparametric efficiency bound attained by the estimator. These steps apply standard semiparametric causal inference results to the new data structure without reducing any claimed result to a fitted input, self-definition, or load-bearing self-citation by construction. No equations or steps in the provided abstract and description exhibit the enumerated circular patterns; the central claims retain independent content from the data formalization and regularity conditions.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters in outcome regression and treatment/area assignment models
axioms (2)
- domain assumption Conditional ignorability of treatment given covariates
- domain assumption Correct specification of at least one of the two working models for double robustness
Reference graph
Works this paper leans on
-
[1]
Bickel and Chris A
Peter J. Bickel and Chris A. J. Klaassen and Ya'acov Ritov and Jon A. Wellner , title =
-
[2]
Biometrika , volume=
M-quantile models for small area estimation , author=. Biometrika , volume=. 2006 , publisher=
2006
-
[3]
Manski , title =
Charles F. Manski , title =
-
[4]
Nelder , title =
Peter McCullagh and John A. Nelder , title =
-
[5]
Sampling from a Finite Population , publisher =
Jaroslav H. Sampling from a Finite Population , publisher =
-
[6]
Imbens and Donald B
Guido W. Imbens and Donald B. Rubin , title =
-
[7]
Roderick J. A. Little and Donald B. Rubin , title =
-
[8]
2015 , publisher=
Small Area Estimation , author=. 2015 , publisher=
2015
-
[9]
Model Assisted Survey Sampling , author=
-
[10]
Journal of the American Statistical Association , pages=
Bias control for M-quantile-based small area estimators , author=. Journal of the American Statistical Association , pages=. 2026 , publisher=
2026
-
[11]
Japanese Journal of Statistics and Data Science , volume=
Small area estimation with mixed models: a review , author=. Japanese Journal of Statistics and Data Science , volume=. 2020 , publisher=
2020
-
[12]
Tsiatis , title =
Anastasios A. Tsiatis , title =
-
[13]
van der Vaart , title =
Aad W. van der Vaart , title =
-
[14]
Binder , title =
David A. Binder , title =. International Statistical Review , year =
-
[15]
Battese and Rachel M
George E. Battese and Rachel M. Harter and Wayne A. Fuller , title =. Journal of the American Statistical Association , year =
-
[16]
Robins , title=
Heejung Bang and James M. Robins , title=. Biometrics , volume=
-
[17]
The Econometrics Journal , year =
Victor Chernozhukov and Denis Chetverikov and Mert Demirer and Esther Duflo and Christian Hansen and Whitney Newey and James Robins , title =. The Econometrics Journal , year =
-
[18]
Dahabreh and Miguel A
Issa J. Dahabreh and Miguel A. Hern. Extending Inferences from a Randomized Trial to a Target Population , journal =. 2019 , volume =
2019
-
[19]
Calibration Estimators in Survey Sampling , journal =
Deville, Jean-Claude and S. Calibration Estimators in Survey Sampling , journal =. 1992 , volume =
1992
-
[20]
Econometrica , volume=
Micro-Level Estimation of Poverty and Inequality , author=. Econometrica , volume=
-
[21]
Journal of the American Statistical Association , volume=
Estimates of Income for Small Places: An Application of James--Stein Procedures to Census Data , author=. Journal of the American Statistical Association , volume=
-
[22]
Little , title =
Andrew Gelman and Thomas C. Little , title =. Survey Methodology , year =
-
[23]
Malay Ghosh and J. N. K. Rao , title =. Statistical Science , year =
-
[24]
Econometrica , year =
Jinyong Hahn , title =. Econometrica , year =
-
[25]
Imbens and Geert Ridder , title =
Keisuke Hirano and Guido W. Imbens and Geert Ridder , title =. Econometrica , year =
-
[26]
Journal of the American Statistical Association , volume=
A Generalization of Sampling Without Replacement From a Finite Universe , author=. Journal of the American Statistical Association , volume=
-
[27]
and Broockman, David E
Kalla, Joshua L. and Broockman, David E. , title =. American Political Science Review , year =
-
[28]
Newey , title =
Whitney K. Newey , title =. Econometrica , volume=
-
[29]
Statistical Science , year =
Danny Pfeffermann , title =. Statistical Science , year =
-
[30]
Sankhya Series B , year =
Danny Pfeffermann and Michael Sverchkov , title =. Sankhya Series B , year =
-
[31]
Computational Statistics and Data Analysis , year =
Setareh Ranjbara and Nicola Salvatib and Barbara Pacini , title =. Computational Statistics and Data Analysis , year =
-
[32]
Journal of the American Statistical Association , year =
Katarzyna Reluga and Dehan Kong and Setareh Ranjbar and Nicola Salvati and Mark van der Laan , title =. Journal of the American Statistical Association , year =
-
[33]
Rubin , title =
Donald B. Rubin , title =. Journal of Educational Psychology , year =
-
[34]
Rosenbaum and Donald B
Paul R. Rosenbaum and Donald B. Rubin , title =. Biometrika , year =
-
[35]
Journal of the American Statistical Association , volume=
Estimation of Regression Coefficients When Some Regressors Are Not Always Observed , author=. Journal of the American Statistical Association , volume=
-
[36]
Pedro H. C. Sant'Anna and Jun Zhao , title =. Journal of Econometrics , year =
-
[37]
Biometrika , year =
Zhiqiang Tan , title =. Biometrika , year =
-
[38]
and Yamauchi, S
Kuriwaki, S. and Yamauchi, S. , title =. 2021 , month =
2021
-
[39]
American Community Survey (ACS) , year =
-
[40]
American National Election Studies 2024 Time Series Study , year =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.