Recognition: unknown
Neural Control: Adjoint Learning Through Equilibrium Constraints
Pith reviewed 2026-05-07 15:56 UTC · model grok-4.3
The pith
Adjoint differentiation through equilibrium constraints yields memory-efficient proxy gradients for controlling multi-stable physical systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Neural Control is a boundary-control framework that computes trajectory-dependent, memory-efficient proxy gradients by differentiating equilibrium conditions via an adjoint formulation, avoiding unrolling of solver iterations. To improve robustness over long horizons, these sensitivities are integrated into a receding-horizon MPC scheme that repeatedly re-anchors optimization to realized equilibria and mitigates basin-switching in multi-stable regimes. The method is evaluated in simulation and on physical robots manipulating DLOs, showing improved performance over gradient-free baselines.
What carries the argument
The adjoint formulation for differentiating equilibrium conditions, which derives proxy gradients directly from the equilibrium equations without storing intermediate solver states.
If this is right
- Enables gradient-based optimization for multi-stable regimes by mitigating basin-switching through repeated re-anchoring in the MPC loop.
- Reduces memory cost relative to unrolled backpropagation, making longer-horizon control tractable.
- Outperforms gradient-free methods such as SPSA and CEM on both simulated and physical DLO manipulation tasks.
- Supports direct use on hardware robots without requiring full trajectory unrolling during policy updates.
Where Pith is reading between the lines
- The same adjoint construction could be applied to other energy-minimizing systems such as soft-robot manipulators or assemblies of rigid bodies whose equilibria are found iteratively.
- Frequent re-anchoring may offer a general tactic for stabilizing gradient descent on loss landscapes that contain multiple attractors, beyond the specific DLO setting.
- Because the gradients avoid storing solver history, the approach may scale to reinforcement-learning loops on resource-constrained physical hardware where memory limits currently preclude implicit-model methods.
Load-bearing premise
The adjoint-derived proxy gradients remain sufficiently accurate to guide optimization even when the equilibrium solver uses numerical approximations.
What would settle it
A DLO bending task in which Neural Control converges to an invalid or unstable trajectory while a gradient-free baseline such as CEM reaches the target shape, indicating that the proxy gradients led optimization into the wrong basin.
Figures


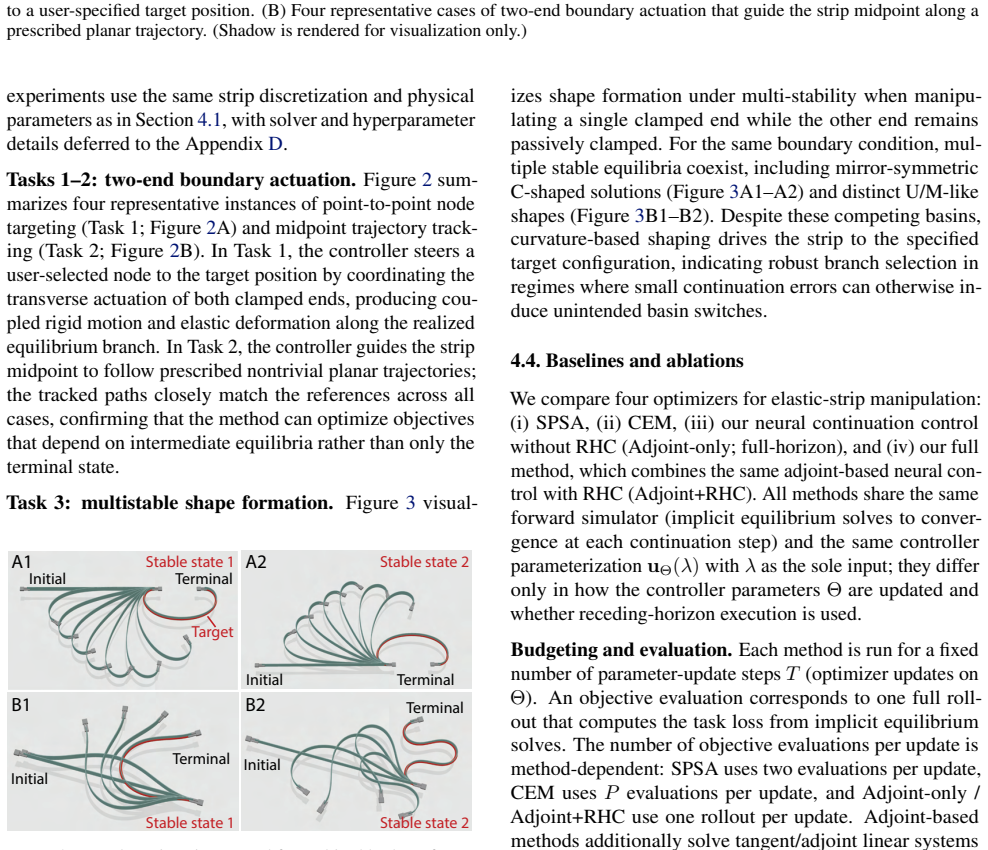
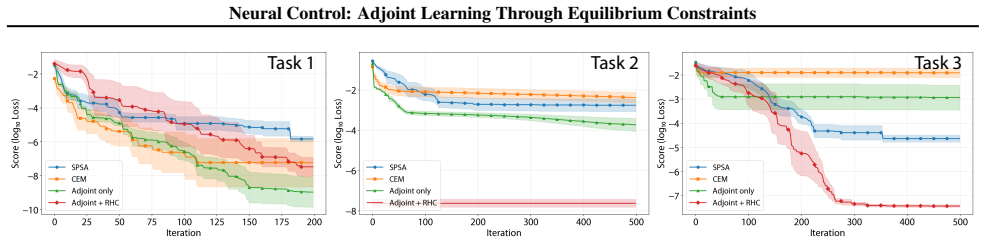


read the original abstract
Many physical AI tasks are governed by implicit equilibrium: an agent actuates a subset of degrees of freedom (boundary DoFs), while the remaining free DoFs settle by minimizing a total potential energy. Even seemingly basic tasks such as bending a deformable linear object (DLO) to a target shape can exhibit strongly nonlinear behavior due to multi-stability: the same boundary conditions may yield multiple equilibrium shapes depending on the actuation trajectory. However, learning and control in such systems is brittle because the actuation-to-configuration map is defined only implicitly, and naive backpropagation through iterative equilibrium solvers is memory- and compute-intensive. We propose Neural Control, a boundary-control framework that computes trajectory-dependent, memory-efficient proxy gradients by differentiating equilibrium conditions via an adjoint formulation, avoiding unrolling of solver iterations. To improve robustness over long horizons, we integrate these sensitivities into a receding-horizon MPC scheme that repeatedly re-anchors optimization to realized equilibria and mitigates basin-switching in multi-stable regimes. We evaluate Neural Control in simulation and on physical robots manipulating DLOs, and show improved performance over gradient-free baselines such as SPSA and CEM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Neural Control, a boundary-control framework for physical AI tasks governed by implicit equilibria (e.g., deformable linear object manipulation). It derives trajectory-dependent proxy gradients via adjoint differentiation of equilibrium conditions to avoid unrolling iterative solvers, then embeds these sensitivities in a receding-horizon MPC scheme that repeatedly re-anchors to realized equilibria in order to mitigate basin-switching in multi-stable regimes. The approach is evaluated in simulation and on physical robots, with claims of improved performance relative to gradient-free baselines such as SPSA and CEM.
Significance. If the central claims hold, the work would be significant for control of implicit, multi-stable physical systems in robotics. The adjoint formulation provides a memory-efficient route to trajectory-dependent sensitivities that standard unrolling cannot scale to long horizons, while the MPC re-anchoring strategy directly targets the basin-switching problem that arises when the same boundary conditions admit multiple equilibria. The paper correctly identifies the standard adjoint method as the technical foundation and demonstrates its integration with receding-horizon optimization, which are genuine strengths.
major comments (2)
- Abstract: the claim that the receding-horizon MPC scheme 'mitigates basin-switching' is load-bearing for the robustness argument, yet the manuscript provides no analysis of how solver approximations (early stopping or loose tolerances) propagate into error in the adjoint-derived proxy gradients. In multi-stable regimes even small residual drift can flip sensitivity signs; without error bounds or tolerance-propagation results the sufficiency of re-anchoring remains unproven for the evaluated horizons.
- Abstract: the statement of 'improved performance over gradient-free baselines such as SPSA and CEM' is central to the empirical contribution, but the abstract supplies no quantitative metrics, error bars, ablation studies on re-anchoring frequency, or implementation details. This absence prevents verification that the data actually support the claims of gradient accuracy and basin-switching mitigation.
minor comments (1)
- The abstract would benefit from a concise statement of the specific tasks, horizon lengths, and solver tolerances used in the simulation and hardware experiments to contextualize the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the significance of the adjoint formulation and receding-horizon re-anchoring strategy. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: Abstract: the claim that the receding-horizon MPC scheme 'mitigates basin-switching' is load-bearing for the robustness argument, yet the manuscript provides no analysis of how solver approximations (early stopping or loose tolerances) propagate into error in the adjoint-derived proxy gradients. In multi-stable regimes even small residual drift can flip sensitivity signs; without error bounds or tolerance-propagation results the sufficiency of re-anchoring remains unproven for the evaluated horizons.
Authors: We agree that a formal analysis of how solver approximations affect the adjoint-derived proxy gradients would strengthen the robustness argument, particularly given the risk of sign flips in multi-stable regimes. The manuscript currently supports the mitigation claim through extensive empirical results in simulation and hardware that demonstrate consistent task success when re-anchoring is applied. In the revised manuscript we will add a new subsection providing both theoretical considerations on residual error propagation and additional experiments that vary solver tolerances and early-stopping criteria across the evaluated horizons. revision: yes
-
Referee: Abstract: the statement of 'improved performance over gradient-free baselines such as SPSA and CEM' is central to the empirical contribution, but the abstract supplies no quantitative metrics, error bars, ablation studies on re-anchoring frequency, or implementation details. This absence prevents verification that the data actually support the claims of gradient accuracy and basin-switching mitigation.
Authors: We acknowledge that the abstract's brevity precludes inclusion of detailed metrics. The full manuscript reports quantitative results with error bars from repeated trials, includes ablation studies on re-anchoring frequency, and provides implementation details in the appendix together with the public code release. To address the concern we will revise the abstract to incorporate representative quantitative indicators of performance improvement while preserving its concise character; the main text and supplementary material will continue to supply the full metrics, ablations, and implementation information. revision: partial
Circularity Check
No significant circularity: adjoint differentiation applies standard implicit-function techniques to equilibrium constraints without reducing to fitted inputs or self-referential definitions.
full rationale
The paper's central derivation applies the adjoint method to differentiate the equilibrium conditions that define the implicit actuation-to-configuration map. This is a direct application of the implicit function theorem and adjoint sensitivity analysis, which are external mathematical tools independent of the paper's fitted values or target results. The receding-horizon MPC integration uses these sensitivities for re-anchoring but does not redefine or fit the gradients to the outcomes being optimized. No load-bearing step quotes a self-citation as a uniqueness theorem, renames a known empirical pattern, or presents a fitted parameter as a prediction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Physical AI tasks are governed by implicit equilibrium where free DoFs settle by minimizing total potential energy.
- domain assumption Differentiating the equilibrium conditions via adjoint formulation yields valid proxy gradients for control optimization.
Reference graph
Works this paper leans on
-
[1]
Nature communications , volume=
Embodied intelligence via learning and evolution , author=. Nature communications , volume=. 2021 , publisher=
2021
-
[2]
2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0 , author=. 2024 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2024 , organization=
2024
-
[3]
International Conference on Machine Learning , pages=
Pods: Policy optimization via differentiable simulation , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[4]
arXiv preprint arXiv:2304.03223 , year=
Dexdeform: Dexterous deformable object manipulation with human demonstrations and differentiable physics , author=. arXiv preprint arXiv:2304.03223 , year=
-
[5]
The International Journal of Robotics Research , volume=
Sim2real neural controllers for physics-based robotic deployment of deformable linear objects , author=. The International Journal of Robotics Research , volume=. 2024 , publisher=
2024
-
[6]
International Conference on Machine Learning , pages=
Efficient differentiable simulation of articulated bodies , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Sapien: A simulated part-based interactive environment , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[8]
arXiv preprint arXiv:2007.02168 , year=
Scalable differentiable physics for learning and control , author=. arXiv preprint arXiv:2007.02168 , year=
-
[9]
Advances in neural information processing systems , volume=
Differentiable cloth simulation for inverse problems , author=. Advances in neural information processing systems , volume=
-
[10]
Applied Mechanics Reviews , pages=
A tutorial on simulating nonlinear behaviors of flexible structures with the discrete differential geometry (DDG) method , author=. Applied Mechanics Reviews , pages=
-
[11]
The International Journal of Robotics Research , volume=
Quasi-static manipulation of a Kirchhoff elastic rod based on a geometric analysis of equilibrium configurations , author=. The International Journal of Robotics Research , volume=. 2014 , publisher=
2014
-
[12]
IEEE Robotics and Automation Letters , volume=
Automated stability testing of elastic rods with helical centerlines using a robotic system , author=. IEEE Robotics and Automation Letters , volume=. 2021 , publisher=
2021
-
[13]
Science Robotics , volume=
Modeling, learning, perception, and control methods for deformable object manipulation , author=. Science Robotics , volume=. 2021 , publisher=
2021
-
[14]
IEEE Transactions on Robotics , volume=
Path planning for deformable linear objects , author=. IEEE Transactions on Robotics , volume=. 2006 , publisher=
2006
-
[15]
ACM SIGGRAPH 2008 papers , pages=
Discrete elastic rods , author=. ACM SIGGRAPH 2008 papers , pages=
2008
-
[16]
International Conference on Machine Learning , pages=
Do differentiable simulators give better policy gradients? , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[17]
, author=
Deep Recurrent Q-Learning for Partially Observable MDPs. , author=. AAAI fall symposia , volume=
-
[18]
arXiv preprint arXiv:2405.17784 , year=
Adaptive horizon actor-critic for policy learning in contact-rich differentiable simulation , author=. arXiv preprint arXiv:2405.17784 , year=
-
[19]
Forty-first International Conference on Machine Learning , year=
Adaptive-gradient policy optimization: Enhancing policy learning in non-smooth differentiable simulations , author=. Forty-first International Conference on Machine Learning , year=
-
[20]
1994 , publisher=
Mixture density networks , author=. 1994 , publisher=
1994
-
[21]
International conference on machine learning , pages=
Learning latent dynamics for planning from pixels , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[22]
Dream to Control: Learning Behaviors by Latent Imagination
Dream to control: Learning behaviors by latent imagination , author=. arXiv preprint arXiv:1912.01603 , year=
work page internal anchor Pith review arXiv 1912
-
[23]
Neural computation , volume=
An efficient gradient-based algorithm for on-line training of recurrent network trajectories , author=. Neural computation , volume=. 1990 , publisher=
1990
-
[24]
Advances in neural information processing systems , volume=
Deep equilibrium models , author=. Advances in neural information processing systems , volume=
-
[25]
Advances in neural information processing systems , volume=
Memory-efficient backpropagation through time , author=. Advances in neural information processing systems , volume=
-
[26]
International conference on machine learning , pages=
Optnet: Differentiable optimization as a layer in neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[27]
Advances in neural information processing systems , volume=
Neural ordinary differential equations , author=. Advances in neural information processing systems , volume=
-
[28]
Advances in neural information processing systems , volume=
Deep reinforcement learning in a handful of trials using probabilistic dynamics models , author=. Advances in neural information processing systems , volume=
-
[29]
IEEE transactions on automatic control , volume=
Multivariate stochastic approximation using a simultaneous perturbation gradient approximation , author=. IEEE transactions on automatic control , volume=. 2002 , publisher=
2002
-
[30]
Handbook of statistics , volume=
The cross-entropy method for optimization , author=. Handbook of statistics , volume=. 2013 , publisher=
2013
-
[31]
Evolution strategies as a scalable alternative to reinforcement learning , author=. arXiv preprint arXiv:1703.03864 , year=
-
[32]
Advances in neural information processing systems , volume=
Simple random search of static linear policies is competitive for reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[33]
International Conference on Machine Learning , pages=
The differentiable cross-entropy method , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[34]
Conference on Robot Learning , pages=
Sample-efficient cross-entropy method for real-time planning , author=. Conference on Robot Learning , pages=. 2021 , organization=
2021
-
[35]
Advances in neural information processing systems , volume=
Differentiable mpc for end-to-end planning and control , author=. Advances in neural information processing systems , volume=
-
[36]
Advances in Neural Information Processing Systems , volume=
Pontryagin differentiable programming: An end-to-end learning and control framework , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2010.07078 , year=
Differentiable implicit layers , author=. arXiv preprint arXiv:2010.07078 , year=
-
[38]
arXiv preprint arXiv:1910.00935 , year=
Difftaichi: Differentiable programming for physical simulation , author=. arXiv preprint arXiv:1910.00935 , year=
-
[39]
Plasticinelab: A soft-body manipulation benchmark with differentiable physics , author=. arXiv preprint arXiv:2104.03311 , year=
-
[40]
Conference on Robot Learning , pages=
Softgym: Benchmarking deep reinforcement learning for deformable object manipulation , author=. Conference on Robot Learning , pages=. 2021 , organization=
2021
-
[41]
arXiv preprint arXiv:2106.13281 , year=
Brax--a differentiable physics engine for large scale rigid body simulation , author=. arXiv preprint arXiv:2106.13281 , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Differentiable simulation of soft multi-body systems , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
2019 International conference on robotics and automation (ICRA) , pages=
Chainqueen: A real-time differentiable physical simulator for soft robotics , author=. 2019 International conference on robotics and automation (ICRA) , pages=. 2019 , organization=
2019
-
[44]
ACM Transactions on Graphics (ToG) , volume=
Diffpd: Differentiable projective dynamics , author=. ACM Transactions on Graphics (ToG) , volume=. 2021 , publisher=
2021
-
[45]
Proceedings of the 2003 ACM SIGGRAPH/Eurographics symposium on Computer animation , pages=
Discrete shells , author=. Proceedings of the 2003 ACM SIGGRAPH/Eurographics symposium on Computer animation , pages=
2003
-
[46]
Learning to Simulate Complex Physics with Graph Networks , booktitle =
Alvaro Sanchez. Learning to Simulate Complex Physics with Graph Networks , booktitle =. 2020 , publisher =
2020
-
[47]
Learning Mesh-Based Simulation with Graph Networks , booktitle =
Tobias Pfaff and Meire Fortunato and Alvaro Sanchez. Learning Mesh-Based Simulation with Graph Networks , booktitle =. 2021 , publisher =
2021
-
[48]
8th International Conference on Learning Representations (ICLR) , year =
Philipp Holl and Nils Thuerey and Vladlen Koltun , title =. 8th International Conference on Learning Representations (ICLR) , year =
-
[49]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Eliot Xing and Vernon Luk and Jean Oh , title =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.