Recognition: unknown
FACTOR: Counterfactual Training-Free Test-Time Adaptation for Open-Vocabulary Object Detection
Pith reviewed 2026-05-08 01:22 UTC · model grok-4.3
The pith
Counterfactual image perturbations let open-vocabulary detectors suppress spurious attribute predictions at test time without updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By perturbing test images along non-causal attributes and comparing region-level predictions between original and counterfactual views, FACTOR quantifies attribute sensitivity, semantic relevance, and prediction variation to selectively suppress attribute-dependent predictions in open-vocabulary object detection, improving robustness under distribution shifts without any parameter updates or online optimization.
What carries the argument
Counterfactual view generation via targeted perturbations of non-causal attributes, followed by region-level prediction comparison to measure sensitivity and suppress attribute-dependent outputs.
If this is right
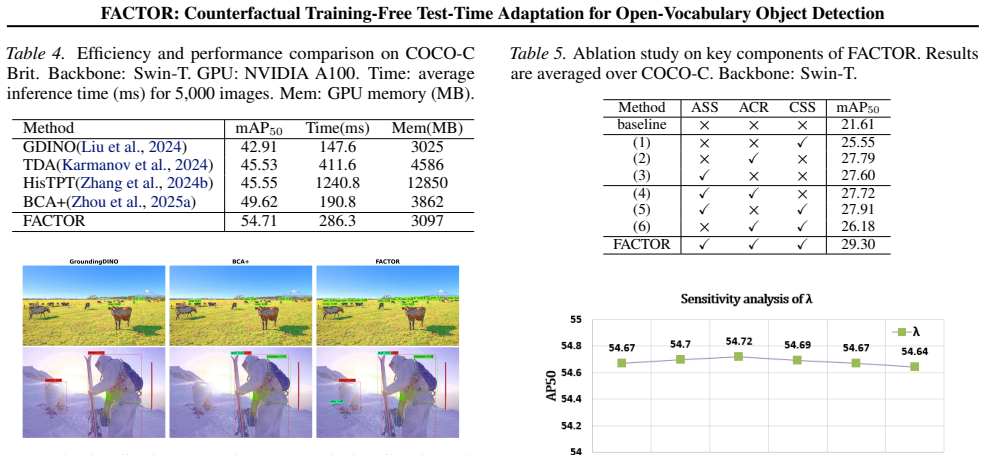
- FACTOR outperforms prior TTA methods on PASCAL-C, COCO-C, and FoggyCityscapes benchmarks.
- The framework requires no parameter updates or online optimization during adaptation.
- Explicit counterfactual reasoning addresses attribute-specific failures that global calibration misses.
- Suppression is applied selectively per region based on quantified sensitivity and relevance.
Where Pith is reading between the lines
- The same perturbation-and-compare logic could apply to other open-vocabulary tasks such as segmentation where attribute biases also appear.
- If perturbation choices can be automated from data statistics, the method might reduce reliance on manual attribute selection.
- This test-time isolation of non-causal factors points to broader uses of lightweight causal-style checks for handling biases in deployed vision systems.
Load-bearing premise
Perturbing test images along non-causal attributes produces valid counterfactual views that accurately isolate attribute sensitivity without introducing new biases or artifacts.
What would settle it
An experiment where performance gains vanish when the same method is applied with random or causal-attribute perturbations instead of non-causal ones, or when the counterfactual views produce prediction changes unrelated to the targeted attributes.
Figures




read the original abstract
Open-vocabulary object detection often fails under distribution shifts, as it can be misled by spurious correlations between non-causal visual attributes (e.g., brightness, texture) and object categories. Existing test-time adaptation (TTA) methods either depend on costly online optimization or perform global calibration, overlooking the attribute-specific nature of these failures. To address this, we propose FACTOR (counterFACtual training-free Test-time adaptation for Open-vocabulaRy object detection), a lightweight framework grounded in counterfactual reasoning. By perturbing test images along non-causal attributes and comparing region-level predictions between original and counterfactual views, FACTOR quantifies attribute sensitivity, semantic relevance, and prediction variation to selectively suppress attribute-dependent predictions-without parameter updates. Experiments on PASCAL-C, COCO-C, and FoggyCityscapes show that FACTOR consistently outperforms prior TTA methods, demonstrating that explicit counterfactual reasoning effectively improves robustness under distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FACTOR, a training-free test-time adaptation framework for open-vocabulary object detection that relies on counterfactual reasoning. It perturbs test images along non-causal attributes (e.g., brightness, texture), compares region-level predictions between original and perturbed views to quantify attribute sensitivity, semantic relevance, and prediction variation, and selectively suppresses attribute-dependent predictions without any parameter updates or optimization. Experiments on PASCAL-C, COCO-C, and FoggyCityscapes demonstrate consistent outperformance over prior TTA methods.
Significance. If the perturbations produce valid counterfactuals that isolate only non-causal attribute sensitivity without altering semantic content, FACTOR offers a lightweight, interpretable alternative to optimization-based TTA for improving robustness in open-vocabulary detection under distribution shifts. The explicit counterfactual mechanism provides a principled way to address spurious correlations, which could be valuable for deployment scenarios where online fine-tuning is impractical.
major comments (1)
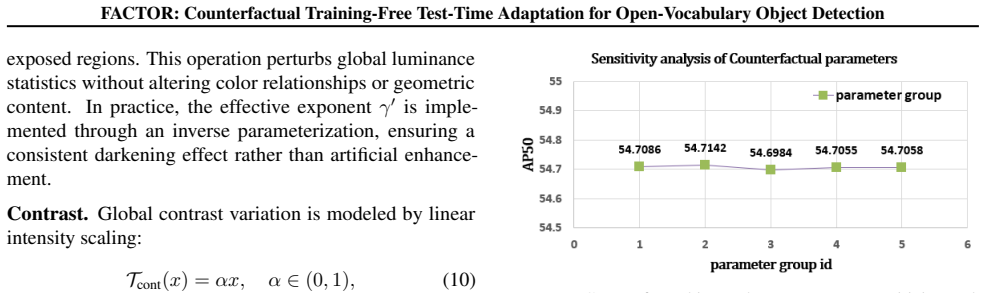
- [Section 3.2] Section 3.2: The perturbation operators and the subsequent scoring of attribute sensitivity, semantic relevance, and prediction variation are described, but the manuscript provides no formal guarantee or empirical validation (e.g., ablation studies checking preservation of object shape, occlusion, or category-discriminative textures) that these operators alter only non-causal attributes. This assumption is load-bearing for the central claim, as any unintended semantic alteration would mean the region-level differences suppress predictions for reasons unrelated to the intended spurious correlations, directly affecting the reported gains on PASCAL-C, COCO-C, and FoggyCityscapes.
minor comments (1)
- [Abstract] Abstract: The claim that FACTOR 'consistently outperforms prior TTA methods' is stated without any quantitative metrics, specific baselines, perturbation details, or ablation results, which reduces immediate assessability of the practical impact.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below, with a commitment to strengthen the paper where the concern is valid.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2: The perturbation operators and the subsequent scoring of attribute sensitivity, semantic relevance, and prediction variation are described, but the manuscript provides no formal guarantee or empirical validation (e.g., ablation studies checking preservation of object shape, occlusion, or category-discriminative textures) that these operators alter only non-causal attributes. This assumption is load-bearing for the central claim, as any unintended semantic alteration would mean the region-level differences suppress predictions for reasons unrelated to the intended spurious correlations, directly affecting the reported gains on PASCAL-C, COCO-C, and FoggyCityscapes.
Authors: We agree that the manuscript would benefit from explicit empirical validation of the perturbation operators. The operators target standard non-causal attributes (brightness via gamma correction, texture via Gaussian filtering or noise) drawn from the robustness literature, where such changes are not expected to alter object shape or category-discriminative semantics. However, we acknowledge the absence of dedicated ablations in the current version. In the revised manuscript, we will add: (i) quantitative checks measuring IoU of region proposals and stability of open-vocabulary predictions on clean images before/after perturbation; (ii) qualitative visualizations confirming no introduced occlusions or identity-altering texture shifts; and (iii) an expanded discussion of the design rationale with references to prior work on attribute-specific perturbations. These additions will directly support the central claim. A formal mathematical guarantee is not feasible without a complete causal model of image formation, which lies beyond the paper's scope. revision: yes
- A formal mathematical guarantee that the chosen perturbation operators alter exclusively non-causal attributes.
Circularity Check
No circularity: method is a direct heuristic comparison without derivations or self-referential fits
full rationale
The paper describes FACTOR as a training-free TTA approach that perturbs test images along non-causal attributes, compares region-level predictions between original and perturbed views, and uses the differences to quantify attribute sensitivity, semantic relevance, and prediction variation before selective suppression. No equations, parameter fitting, uniqueness theorems, or derivation chains are presented that could reduce outputs to inputs by construction. The central mechanism is an empirical, direct comparison procedure rather than a closed mathematical loop or self-citation load-bearing premise. This renders the approach self-contained with no detectable circularity in its claimed reasoning.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Test-Time Adaptive Object Detection with Foundation Model , author=. 2025 , eprint=
2025
-
[2]
2022 , eprint=
Simple Open-Vocabulary Object Detection with Vision Transformers , author=. 2022 , eprint=
2022
-
[3]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[4]
2024 , organization=
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. 2024 , organization=
2024
-
[5]
IEEE Transactions on knowledge and data engineering , volume=
A survey on transfer learning , author=. IEEE Transactions on knowledge and data engineering , volume=. 2009 , publisher=
2009
-
[6]
2025 , publisher=
A comprehensive survey on test-time adaptation under distribution shifts , author=. 2025 , publisher=
2025
-
[7]
2025 , eprint=
Generalizing Vision-Language Models to Novel Domains: A Comprehensive Survey , author=. 2025 , eprint=
2025
-
[8]
International conference on machine learning , pages=
Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[9]
Test-time classifier adjustment module for model-agnostic domain generalization , author=
-
[10]
Revisiting realistic test-time training: Sequential inference and adaptation by anchored clustering , author=
-
[11]
End-to-end semi-supervised object detection with soft teacher , author=
-
[12]
2023 , eprint=
Stfar: Improving object detection robustness at test-time by self-training with feature alignment regularization , author=. 2023 , eprint=
2023
-
[13]
Efficient Test-Time Adaptation of Vision-Language Models , author=
-
[14]
Bayesian Test-Time Adaptation for Vision-Language Models , author=
-
[15]
2021 , eprint=
Counterfactual Generative Networks , author=. 2021 , eprint=
2021
-
[16]
2019 , eprint=
Counterfactual Visual Explanations , author=. 2019 , eprint=
2019
-
[17]
2021 , eprint=
Counterfactual VQA: A Cause-Effect Look at Language Bias , author=. 2021 , eprint=
2021
-
[18]
2018 , eprint=
Counterfactual Fairness , author=. 2018 , eprint=
2018
-
[19]
2022 , eprint=
Counterfactual Explanations and Algorithmic Recourses for Machine Learning: A Review , author=. 2022 , eprint=
2022
-
[20]
2025 , eprint=
Bayesian Test-time Adaptation for Object Recognition and Detection with Vision-language Models , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Explaining Domain Shifts in Language: Concept erasing for Interpretable Image Classification , author=. 2025 , eprint=
2025
-
[22]
What how and when should object detectors update in continually changing test domains? , author=
-
[23]
Test-time prompt tuning for zero-shot generalization in vision-language models , author=
-
[24]
R-TPT: Improving Adversarial Robustness of Vision-Language Models through Test-Time Prompt Tuning , author=
-
[25]
O-TPT: Orthogonality Constraints for Calibrating Test-time Prompt Tuning in Vision-Language Models , author=
-
[26]
Diverse data augmentation with diffusions for effective test-time prompt tuning , author=
-
[27]
2025 , eprint=
VLOD-TTA: Test-Time Adaptation of Vision-Language Object Detectors , author=. 2025 , eprint=
2025
-
[28]
Historical test-time prompt tuning for vision foundation models , author=
-
[29]
2016 , eprint=
The CMA evolution strategy: A tutorial , author=. 2016 , eprint=
2016
-
[30]
2017 , eprint=
Population based training of neural networks , author=. 2017 , eprint=
2017
-
[31]
Deep residual learning for image recognition , author=
-
[32]
2016 , publisher=
Faster R-CNN: Towards real-time object detection with region proposal networks , author=. 2016 , publisher=
2016
-
[33]
International conference on machine learning , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[34]
FILIP: Fine-grained Interactive Language-Image Pre-Training , author=
-
[35]
PaLI: A Jointly-Scaled Multilingual Language-Image Model , author=
-
[36]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation , author=
-
[37]
DetCLIP: dictionary-enriched visual-concept paralleled pre-training for open-world detection , author=
-
[38]
Learning to prompt for vision-language models.Int
Zhou, Kaiyang and Yang, Jingkang and Loy, Chen Change and Liu, Ziwei , year=. Learning to Prompt for Vision-Language Models , volume=. doi:10.1007/s11263-022-01653-1 , number=
-
[39]
2022 , eprint=
Conditional Prompt Learning for Vision-Language Models , author=. 2022 , eprint=
2022
-
[40]
Grounded language-image pre-training , author=
-
[41]
Open-vocabulary object detection using captions , author=
-
[42]
2020 , organization=
End-to-end object detection with transformers , author=. 2020 , organization=
2020
-
[43]
Tent: Fully Test-Time Adaptation by Entropy Minimization , author=
-
[44]
International conference on machine learning , pages=
Large-scale evolution of image classifiers , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[45]
IEEE Transactions on evolutionary computation , volume=
A survey on evolutionary computation approaches to feature selection , author=. IEEE Transactions on evolutionary computation , volume=. 2015 , publisher=
2015
-
[46]
Regularized evolution for image classifier architecture search , author=
-
[47]
Yolo-world: Real-time open-vocabulary object detection , author=
-
[48]
Swin transformer: Hierarchical vision transformer using shifted windows , author=
-
[49]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[50]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection , author=
-
[51]
2015 , publisher=
The pascal visual object classes challenge: A retrospective , author=. 2015 , publisher=
2015
-
[52]
2019 , eprint=
Benchmarking robustness in object detection: Autonomous driving when winter is coming , author=. 2019 , eprint=
2019
-
[53]
2018 , publisher=
Semantic foggy scene understanding with synthetic data , author=. 2018 , publisher=
2018
-
[54]
The cityscapes dataset for semantic urban scene understanding , author=
-
[55]
2014 , organization=
Microsoft coco: Common objects in context , author=. 2014 , organization=
2014
-
[56]
Efficient Test-time Adaptive Object Detection via Sensitivity-Guided Pruning , author=
-
[57]
Lit: Zero-shot transfer with locked-image text tuning , author=
-
[58]
2022 , organization=
Contrastive vision-language pre-training with limited resources , author=. 2022 , organization=
2022
-
[59]
IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Towards online domain adaptive object detection , author=. IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[60]
Dual prototype evolving for test-time generalization of vision-language models , author=
-
[61]
2014 , eprint=
Notes on Kullback-Leibler Divergence and Likelihood , author=. 2014 , eprint=
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.