Recognition: unknown
Stable Multimodal Graph Unlearning via Feature-Dimension Aware Quantile Selection
Pith reviewed 2026-05-07 17:33 UTC · model grok-4.3
The pith
Feature-dimension aware quantile selection prevents over-editing of high-dimensional layers in multimodal graph unlearning, preserving utility while achieving forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
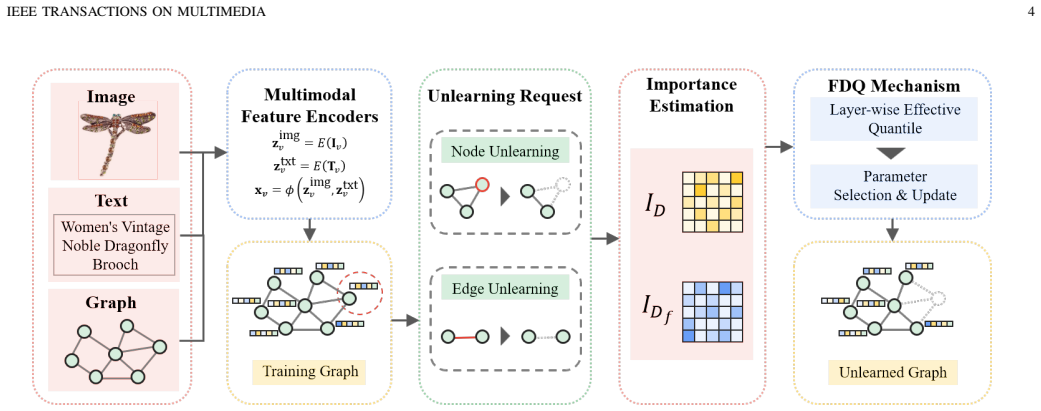
FDQ adaptively identifies high-dimensional input projection layers in multimodal GNNs and applies more conservative quantile thresholds when constructing suppression sets for unlearning, while keeping the importance estimation mechanism fixed; this yields effective forgetting for node and edge requests with substantially less utility degradation than uniform selection across layers.
What carries the argument
The Feature-Dimension Aware Quantile (FDQ) selection that adjusts suppression thresholds higher for layers with large input feature dimensions during parameter editing in graph unlearning.
If this is right
- Node and edge unlearning requests can be handled efficiently without layer-specific retraining.
- Utility is preserved on multimodal datasets such as Ele-Fashion and Goodreads-NC after forgetting.
- Membership inference attacks remain ineffective after the unlearning step.
- The framework provides a general solution for privacy-aware updates in high-dimensional multimodal graph models.
Where Pith is reading between the lines
- The same dimension-aware threshold logic could be tested on other multimodal architectures that contain high-dimensional projection layers, such as vision-language models.
- If input dimension correlates strongly with knowledge concentration, the approach might reduce the frequency of full model retraining in regulated graph applications.
- Extending the quantile adjustment to dynamic graphs or streaming data would require checking whether layer dimensions remain stable over time.
- The method leaves open whether similar selective editing improves unlearning stability in non-graph multimodal settings.
Load-bearing premise
Existing unlearning methods apply the same parameter selection and editing rules to every GNN layer even when high-dimensional input projections hold most cross-modal knowledge.
What would settle it
An experiment showing that uniform quantile thresholds achieve equal or better utility retention and equivalent resistance to membership inference attacks on the same multimodal graphs as FDQ would falsify the necessity of dimension-aware adjustment.
Figures



read the original abstract
Graph unlearning remains a critical technique for supporting privacy-preserving and sustainable multimodal graph learning. However, we observe that existing unlearning strategies tend to apply uniform parameter selection and editing across all graph neural network (GNN) layers, which is especially harmful for multimodal graphs where high-dimensional input projections encode dominant cross-modal knowledge. As a result, over-editing these sensitive layers often leads to catastrophic utility degradation after forgetting, undermining both stable learning and effective privacy protection. To address this gap, we propose FDQ, a Feature-Dimension Aware Quantile framework for multimodal graph unlearning. FDQ adaptively identifies high-dimensional input projection layers and applies more conservative, FDQ-guided quantile thresholds when constructing suppression sets, while keeping the underlying importance estimation mechanism unchanged. FDQ is seamlessly integrated with diagonal sensitivity-based parameter importance analysis to enable efficient node and edge unlearning under general forget requests. Through extensive experiments on Ele-Fashion and Goodreads-NC, we demonstrate that FDQ consistently achieves strong utility preservation while maintaining effective forgetting against membership inference attacks. Overall, FDQ offers a principled and robust solution for privacy-aware unlearning in high-dimensional multimodal graph systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FDQ, a Feature-Dimension Aware Quantile framework for stable multimodal graph unlearning. It observes that uniform parameter selection and editing across GNN layers harms multimodal graphs because high-dimensional input projection layers encode dominant cross-modal knowledge, leading to utility degradation. FDQ adaptively applies more conservative quantile thresholds to these layers while reusing an unchanged importance estimation mechanism, integrated with diagonal sensitivity-based analysis for node and edge unlearning. Experiments on Ele-Fashion and Goodreads-NC are claimed to demonstrate strong utility preservation alongside effective forgetting against membership inference attacks.
Significance. If the results hold with adequate quantification, FDQ provides a targeted, efficient way to stabilize unlearning in multimodal graph settings by avoiding over-editing of sensitive layers without redesigning the core importance estimator. This could advance privacy-preserving graph ML, particularly where cross-modal knowledge is concentrated in high-dimensional projections. The reuse of existing mechanisms and evaluation on two datasets are practical strengths.
major comments (2)
- [Method] Method description: the claim that conservative FDQ-guided quantile thresholds on high-dimensional input projection layers still ensure effective forgetting lacks any derivation, bound, or analysis showing that the reduced suppression set size crosses the threshold needed for unlearning success; residual unedited parameters in these layers could permit membership inference attacks to succeed while utility remains high.
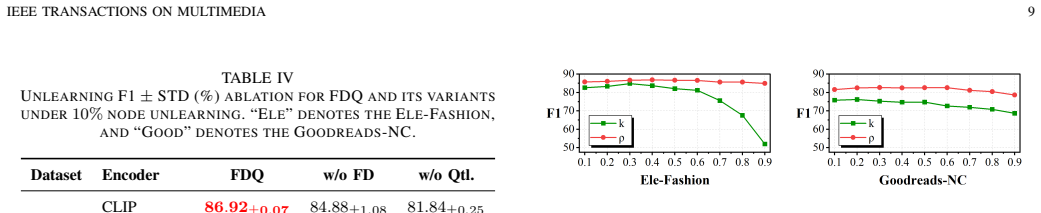
- [Experiments] Experiments section: the abstract asserts 'consistent' strong utility preservation and 'effective forgetting' on Ele-Fashion and Goodreads-NC, yet provides no quantitative metrics, error bars, specific MIA success rates, or utility scores, leaving the central utility-forgetting tradeoff only moderately supported.
minor comments (2)
- [Method] Clarify how high-dimensional layers are identified and the exact form of the FDQ quantile adjustment (e.g., via pseudocode or explicit formula) to improve reproducibility.
- [Introduction] The motivation paragraph would benefit from citing specific prior uniform unlearning strategies in GNNs to better contextualize the gap.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional rigor and clarity are needed, and we will revise accordingly to strengthen the presentation of both the method and experimental results.
read point-by-point responses
-
Referee: [Method] Method description: the claim that conservative FDQ-guided quantile thresholds on high-dimensional input projection layers still ensure effective forgetting lacks any derivation, bound, or analysis showing that the reduced suppression set size crosses the threshold needed for unlearning success; residual unedited parameters in these layers could permit membership inference attacks to succeed while utility remains high.
Authors: We acknowledge that the manuscript currently lacks a formal derivation or bound to guarantee that the conservative quantile thresholds in high-dimensional layers still achieve sufficient forgetting. The approach relies on the diagonal sensitivity-based importance estimator to prioritize parameters, but no explicit analysis of residual membership leakage is provided. In the revised version, we will add a dedicated theoretical subsection deriving a bound on the unlearning success probability, showing that the reduced suppression set size in these layers remains above the threshold required to limit MIA success under the existing importance estimation mechanism. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts 'consistent' strong utility preservation and 'effective forgetting' on Ele-Fashion and Goodreads-NC, yet provides no quantitative metrics, error bars, specific MIA success rates, or utility scores, leaving the central utility-forgetting tradeoff only moderately supported.
Authors: The referee correctly notes that the abstract does not include specific quantitative metrics, which limits the immediate support for the claims. Although the experiments section contains the relevant results, we will revise the abstract to explicitly report key utility scores, MIA success rates, and error bars from the runs on both datasets. We will also add a brief summary of these metrics in the experiments section to make the utility-forgetting tradeoff more transparent and quantitatively supported. revision: yes
Circularity Check
No circularity detected; method reuses unchanged estimator without self-referential derivation
full rationale
The paper proposes FDQ by adaptively selecting more conservative quantile thresholds for high-dimensional input projection layers while explicitly keeping the underlying importance estimation mechanism unchanged and integrating it with existing diagonal sensitivity-based analysis. No equations, derivations, or self-citations are presented that reduce any claimed prediction or result to the inputs by construction. The approach does not rename fitted parameters as predictions, import uniqueness theorems from self-citations, or smuggle ansatzes; experimental claims on Ele-Fashion and Goodreads-NC stand as external validation rather than tautological restatements. This is the common case of an applied method extension with independent empirical support.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-dimensional input projections encode dominant cross-modal knowledge in multimodal graphs
invented entities (1)
-
FDQ-guided quantile thresholds
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Graph learning,
F. Xia, C. Peng, J. Ren, F. G. Febrinanto, R. Luo, V . Saikrishna, S. Yu, and X. Kong, “Graph learning,”Foundations and Trends® in Signal Processing, vol. 19, no. 4, pp. 362–519, 2026. IEEE TRANSACTIONS ON MULTIMEDIA 10
2026
-
[2]
Telling peer direct effects from indirect effects in observational network data,
X. Du, J. Li, D. Cheng, L. Liu, W. Gao, X. Chen, and Z. Xu, “Telling peer direct effects from indirect effects in observational network data,” inForty-second International Conference on Machine Learning, 2025
2025
-
[3]
Graph learn- ing for anomaly analytics: Algorithms, applications, and challenges,
J. Ren, F. Xia, I. Lee, A. Noori Hoshyar, and C. Aggarwal, “Graph learn- ing for anomaly analytics: Algorithms, applications, and challenges,” ACM Transactions on Intelligent Systems and Technology, vol. 14, no. 2, pp. 1–29, 2023
2023
-
[4]
OpenViewer: Openness-aware multi-view learning,
S. Du, Z. Fang, Y . Tan, C. Wang, S. Wang, and W. Guo, “OpenViewer: Openness-aware multi-view learning,” inProceedings of the 39th AAAI Conference on Artificial Intelligence, 2025, pp. 16 389–16 397
2025
-
[5]
Multi- type social patterns-based graph learning,
S. Yu, Z. Han, F. Ding, H. Huang, R. Luo, G. Han, and F. Xia, “Multi- type social patterns-based graph learning,”Neurocomputing, vol. 637, p. 130039, 2025
2025
-
[6]
Dualgnn: Dual graph neural network for multimedia recommendation,
Q. Wang, Y . Wei, J. Yin, J. Wu, X. Song, and L. Nie, “Dualgnn: Dual graph neural network for multimedia recommendation,”IEEE Transactions on Multimedia, vol. 25, pp. 1074–1084, 2021
2021
-
[7]
General data protection regulation,
P. Regulation, “General data protection regulation,”Intouch, vol. 25, pp. 1–5, 2018
2018
-
[8]
Synthetic forgetting without access: A few-shot zero-glance framework for ma- chine unlearning,
Q. Song, N. Yang, Z. Xu, Y . Li, W. Shao, and F. Xia, “Synthetic forgetting without access: A few-shot zero-glance framework for ma- chine unlearning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 30, 2026, pp. 25 545–25 553
2026
-
[9]
Graph unlearning,
M. Chen, Z. Zhang, T. Wang, M. Backes, M. Humbert, and Y . Zhang, “Graph unlearning,” inProceedings of the 2022 ACM SIGSAC confer- ence on computer and communications security, 2022
2022
-
[10]
IDEA: A flexible frame- work of certified unlearning for graph neural networks,
Y . Dong, B. Zhang, Z. Lei, N. Zou, and J. Li, “IDEA: A flexible frame- work of certified unlearning for graph neural networks,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024
2024
-
[11]
Towards effective and general graph unlearning via mutual evolution,
X. Li, Y . Zhao, Z. Wu, W. Zhang, R.-H. Li, and G. Wang, “Towards effective and general graph unlearning via mutual evolution,” inPro- ceedings of the 38th AAAI Conference on Artificial Intelligence, 2024
2024
-
[12]
Erase then rectify: A training-free parameter editing approach for cost-effective graph unlearning,
Z.-R. Yang, J. Han, C.-D. Wang, and H. Liu, “Erase then rectify: A training-free parameter editing approach for cost-effective graph unlearning,” inProceedings of the 39th AAAI Conference on Artificial Intelligence, 2025
2025
-
[13]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, 2021, pp. 8748–8763
2021
-
[14]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 15 180–15 190
2023
-
[15]
Machine unlearning,
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine unlearning,” in2021 IEEE symposium on security and privacy (SP), 2021
2021
-
[16]
Inductive graph unlearning,
C.-L. Wang, M. Huai, and D. Wang, “Inductive graph unlearning,” in 32nd USENIX Security Symposium (USENIX Security 23), 2023
2023
-
[17]
Gnndelete: A general unlearning strategy for graph neural networks,
J. Cheng, G. Dasoulas, H. He, C. Agarwal, and M. Zitnik, “Gnndelete: A general unlearning strategy for graph neural networks,” inInternational Conference on Learning Representations, 2023
2023
-
[18]
Scalable and certifiable graph unlearning: Over- coming the approximation error barrier,
L. Yi and Z. Wei, “Scalable and certifiable graph unlearning: Over- coming the approximation error barrier,” inProceedings of the 13th International Conference on Learning Representations, 2025
2025
-
[19]
arXiv preprint arXiv:2402.05322 , year =
C. Peng, J. He, and F. Xia, “Learning on multimodal graphs: A survey,” arXiv preprint arXiv:2402.05322, 2024
-
[20]
Heteroge- neous graph learning for explainable recommendation over academic networks,
X. Chen, T. Tang, J. Ren, I. Lee, H. Chen, and F. Xia, “Heteroge- neous graph learning for explainable recommendation over academic networks,” inIEEE/WIC/ACM International Conference on Web Intelli- gence and Intelligent Agent Technology, 2021, pp. 29–36
2021
-
[21]
Multimodal multi-graph fusion learning for Alzheimer’s disease diagnosis,
A. Dong, Y . Cai, L. Wang, J. Xu, G. Lv, and G. Zhao, “Multimodal multi-graph fusion learning for Alzheimer’s disease diagnosis,”IEEE Transactions on Multimedia, 2025
2025
-
[22]
Multi- modal learning with graphs,
Y . Ektefaie, G. Dasoulas, A. Noori, M. Farhat, and M. Zitnik, “Multi- modal learning with graphs,”Nature Machine Intelligence, vol. 5, no. 4, pp. 340–350, 2023
2023
-
[23]
Unigraph2: Learning a unified embedding space to bind multimodal graphs,
Y . He, Y . Sui, X. He, Y . Liu, Y . Sun, and B. Hooi, “Unigraph2: Learning a unified embedding space to bind multimodal graphs,” inProceedings of the ACM Web Conference 2025, 2025, pp. 1759–1770
2025
-
[24]
Graphgpt- o: Synergistic multimodal comprehension and generation on graphs,
Y . Fang, B. Jin, J. Shen, S. Ding, Q. Tan, and J. Han, “Graphgpt- o: Synergistic multimodal comprehension and generation on graphs,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 19 467–19 476
2025
-
[25]
Hierarchy-aware multimodal distillation for recommendation,
M. Jian, T. Wang, M. Yang, and L. Wu, “Hierarchy-aware multimodal distillation for recommendation,”IEEE Transactions on Multimedia, 2026
2026
-
[26]
Large language models on graphs: A comprehensive survey,
B. Jin, G. Liu, C. Han, M. Jiang, H. Ji, and J. Han, “Large language models on graphs: A comprehensive survey,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 12, pp. 8622–8642, 2024
2024
-
[27]
A comprehensive study on text-attributed graphs: Benchmarking and rethinking,
H. Yan, C. Li, R. Long, C. Yan, J. Zhao, W. Zhuang, J. Yin, P. Zhang, W. Han, H. Sunet al., “A comprehensive study on text-attributed graphs: Benchmarking and rethinking,”Advances in Neural Information Processing Systems, vol. 36, pp. 17 238–17 264, 2023
2023
-
[28]
Graph transformers: A survey,
A. Shehzad, F. Xia, S. Abid, C. Peng, S. Yu, D. Zhang, and K. Verspoor, “Graph transformers: A survey,”IEEE Transactions on Neural Networks and Learning Systems, 2026
2026
-
[29]
Gita: Graph to visual and textual integration for vision- language graph reasoning,
Y . Wei, S. Fu, W. Jiang, Z. Zhang, Z. Zeng, Q. Wu, J. Kwok, and Y . Zhang, “Gita: Graph to visual and textual integration for vision- language graph reasoning,”Advances in neural information processing systems, vol. 37, pp. 44–72, 2024
2024
-
[30]
ViDR-GNN: Vision implicit discriminative reorganization graph neural networks,
Z. Zhang, X. Cao, X. Zhang, L. Peng, L. Ma, and J. Yang, “ViDR-GNN: Vision implicit discriminative reorganization graph neural networks,” IEEE Transactions on Multimedia, 2025
2025
-
[31]
Mo- saic of modalities: A comprehensive benchmark for multimodal graph learning,
J. Zhu, Y . Zhou, S. Qian, Z. He, T. Zhao, N. Shah, and D. Koutra, “Mo- saic of modalities: A comprehensive benchmark for multimodal graph learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 14 215–14 224
2025
-
[32]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[33]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[34]
Rmtrans: Robust multimodal transformers for patient prognosis under backdoor threats,
T. Tang, G. Han, R. Luo, F. Ding, S. Yu, and I. Lee, “Rmtrans: Robust multimodal transformers for patient prognosis under backdoor threats,” ACM Transactions on Intelligent Systems and Technology, vol. 17, no. 3, pp. 1–25, 2026
2026
-
[35]
Cglb: Benchmark tasks for continual graph learning,
X. Zhang, D. Song, and D. Tao, “Cglb: Benchmark tasks for continual graph learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 13 006–13 021, 2022
2022
-
[36]
Multidelete for multimodal machine unlearn- ing,
J. Cheng and H. Amiri, “Multidelete for multimodal machine unlearn- ing,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 165–184
2024
-
[37]
Multi-modal recommen- dation unlearning for legal, licensing, and modality constraints,
Y . Sinha, M. Mandal, and M. Kankanhalli, “Multi-modal recommen- dation unlearning for legal, licensing, and modality constraints,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 12, 2025, pp. 12 541–12 549
2025
-
[38]
Membership inference attack on graph neural networks,
I. E. Olatunji, W. Nejdl, and M. Khosla, “Membership inference attack on graph neural networks,” in2021 Third IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), 2021
2021
-
[39]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,”Pro- ceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[40]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Y . Hou, J. Li, Z. He, A. Yan, X. Chen, and J. McAuley, “Bridging language and items for retrieval and recommendation,”arXiv preprint arXiv:2403.03952, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Justifying recommendations using distantly-labeled reviews and fine-grained aspects,
J. Ni, J. Li, and J. McAuley, “Justifying recommendations using distantly-labeled reviews and fine-grained aspects,” inProceedings of the 2019 conference on empirical methods in natural language pro- cessing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), 2019, pp. 188–197
2019
-
[42]
Item recommendation on monotonic behavior chains,
M. Wan and J. McAuley, “Item recommendation on monotonic behavior chains,” inProceedings of the 12th ACM conference on recommender systems, 2018, pp. 86–94
2018
-
[43]
Fine-grained spoiler detection from large-scale review corpora,
M. Wan, R. Misra, N. Nakashole, and J. McAuley, “Fine-grained spoiler detection from large-scale review corpora,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 2605–2610
2019
-
[44]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review arXiv 2023
-
[45]
Fast machine unlearning without retraining through selective synaptic dampening,
J. Foster, S. Schoepf, and A. Brintrup, “Fast machine unlearning without retraining through selective synaptic dampening,” inProceedings of the 38th AAAI conference on artificial intelligence, vol. 38, no. 11, 2024, pp. 12 043–12 051. IEEE TRANSACTIONS ON MULTIMEDIA 11 Jingjing Zhoureceived the M.S. degree from Shan- dong University in 2004 and the Ph.D. ...
2024
-
[46]
Her research interests include artificial intelligence, graph learning, and computer networks
She is currently Associate Professor in School of Information and Electronic Engineering, Zhejiang Gongshang University, China. Her research interests include artificial intelligence, graph learning, and computer networks. Yongshuai Yangis an M.S. student at School of Information and Electronic Engineering, Zhejiang Gongshang University, China. He receive...
2024
-
[47]
Renqiang Luoreceived the B.Sc
Her research interests include graph learning, algorithmic fairness, responsible AI. Renqiang Luoreceived the B.Sc. degree from University of Science and Technology of China, Hefei, China, in 2016, and the M.Sc. degree from University of South Australia, Adelaide, Australia, in 2019. He received a Ph.D. degree in the School of Software, Dalian University ...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.