Recognition: unknown
Revisiting the Travel Planning Capabilities of Large Language Models
Pith reviewed 2026-05-07 16:48 UTC · model grok-4.3
The pith
Large language models extract explicit travel constraints accurately but fail to infer implicit requirements and correct their own planning errors effectively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decomposing travel planning into the atomic sub-capabilities of Constraint Extraction, Tool Use, Plan Generation, Error Identification, and Error Correction, and evaluating each one separately with oracle intermediate contexts, the study establishes that LLMs are proficient at extracting explicit constraints but struggle to infer implicit open-world requirements, exhibit structural biases during plan generation, and perform ineffective self-correction marked by excessive sensitivity and erroneous persistence.
What carries the argument
The five atomic sub-capabilities and the decoupled evaluation protocol that supplies oracle intermediate contexts to isolate each capability without cascading errors.
If this is right
- Training methods must target implicit requirement inference separately from explicit constraint handling.
- Plan generation modules need mechanisms to counteract structural biases that appear even in isolation.
- Self-correction loops require redesign to reduce over-sensitivity and error persistence.
- Future benchmarks should adopt decoupled protocols to diagnose specific failure modes rather than relying on end-to-end plan quality.
- Improvements on these atomic skills would directly raise performance on other long-horizon reasoning tasks.
Where Pith is reading between the lines
- Real-world deployment of LLM planners would still require human review for unspoken constraints such as weather or personal preferences.
- The same decomposition approach could diagnose weaknesses in LLM performance on project scheduling or scientific experiment design.
- Models trained with explicit signals for open-world inference might close the gap observed here.
- User studies with actual travelers could test whether the isolated weaknesses produce plans that fail in practice.
Load-bearing premise
The five chosen sub-capabilities fully cover travel planning and the oracle contexts isolate each skill without introducing new biases or artificial advantages.
What would settle it
An LLM that achieves comparable accuracy on inferring implicit open-world requirements as on explicit constraints when tested in the same isolated, oracle-provided setup would falsify the reported performance contrast.
Figures





read the original abstract
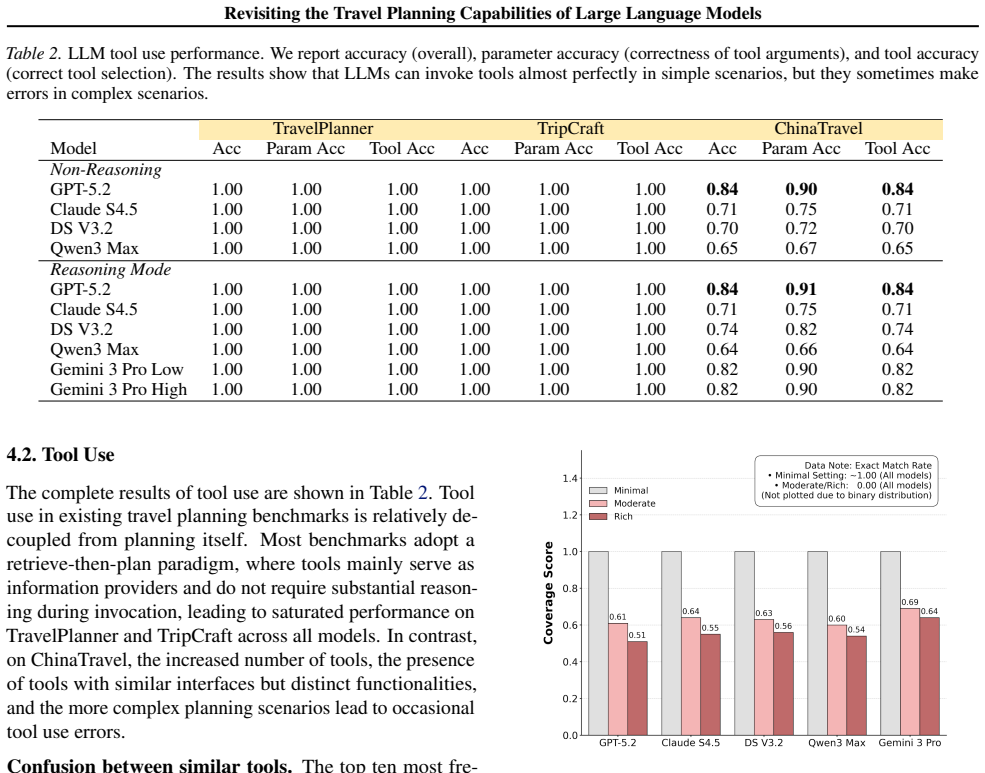
Travel planning serves as a critical task for long-horizon reasoning, exposing significant deficits in LLMs. However, existing benchmarks and evaluations primarily assess final plans in an end-to-end manner, which lacks interpretability and makes it difficult to analyze the root causes of failures. To bridge this gap, we decompose travel planning into five constituent atomic sub-capabilities, including \emph{Constraint Extraction}, \emph{Tool Use}, \emph{Plan Generation}, \emph{Error Identification}, and \emph{Error Correction}. We implement a decoupled evaluation protocol leveraging oracle intermediate contexts to rigorously isolate these components, thereby measuring the atomic performance boundary without the noise of cascading errors. Our results highlight a clear contrast in performance: while LLMs are proficient in extracting explicit constraints, they struggle to infer implicit, open-world requirements. Furthermore, they exhibit structural biases in plan generation and suffer from ineffective self-correction, characterized by excessive sensitivity and erroneous persistence. These findings offer precise directions for improving LLM reasoning and planning abilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper decomposes travel planning into five atomic sub-capabilities (Constraint Extraction, Tool Use, Plan Generation, Error Identification, Error Correction) and introduces a decoupled evaluation protocol that supplies oracle intermediate contexts to isolate each component without cascading errors. It reports that LLMs handle explicit constraints well but struggle with implicit open-world requirements, exhibit structural biases during plan generation, and display ineffective self-correction characterized by excessive sensitivity and erroneous persistence.
Significance. If the empirical contrasts hold under more realistic conditions, the work supplies a useful fine-grained diagnostic for LLM long-horizon reasoning deficits and concrete targets for improvement. The decomposition itself and the explicit isolation of sub-capabilities constitute a methodological contribution that could be adopted by subsequent studies.
major comments (2)
- [Evaluation Protocol] The decoupled protocol (Abstract and Evaluation section) supplies perfect oracle outputs for prior stages when testing Error Identification and Error Correction. This removes realistic cascading mistakes, so the reported 'excessive sensitivity and erroneous persistence' in self-correction may be an artifact of the clean context rather than an intrinsic limitation; the same concern applies to the structural biases claimed for Plan Generation.
- [Results] No implementation details, concrete benchmarks, quantitative tables, or error analysis appear in the abstract or are referenced in the reader's summary, making it impossible to verify the magnitude of the claimed performance contrasts or to reproduce the structural-bias findings.
minor comments (1)
- [Abstract] The abstract would be strengthened by naming the specific LLMs, travel-planning dataset, and number of instances used so readers can immediately gauge the scope of the evaluation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below with clarifications on our methodology and planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation Protocol] The decoupled protocol (Abstract and Evaluation section) supplies perfect oracle outputs for prior stages when testing Error Identification and Error Correction. This removes realistic cascading mistakes, so the reported 'excessive sensitivity and erroneous persistence' in self-correction may be an artifact of the clean context rather than an intrinsic limitation; the same concern applies to the structural biases claimed for Plan Generation.
Authors: We appreciate this important point regarding the decoupled protocol. The design intentionally supplies oracle intermediate contexts to isolate each sub-capability and measure its atomic performance boundary without confounding from upstream errors, which is the core methodological contribution for fine-grained diagnosis. We agree that this may not fully replicate cascading effects in fully realistic end-to-end settings. In the revision, we will expand the Evaluation section with a dedicated limitations paragraph explicitly discussing this trade-off and will include additional end-to-end experiments (without oracle contexts) to show how the isolated deficits manifest under more integrated conditions. revision: partial
-
Referee: [Results] No implementation details, concrete benchmarks, quantitative tables, or error analysis appear in the abstract or are referenced in the reader's summary, making it impossible to verify the magnitude of the claimed performance contrasts or to reproduce the structural-bias findings.
Authors: The abstract is a concise high-level summary by design and does not contain implementation details or tables. The full manuscript provides these in Section 3 (Methodology and Implementation), Section 4 (Experiments and Benchmarks) with quantitative tables reporting performance on each sub-capability, and Section 5 (Error Analysis) that breaks down structural biases and self-correction patterns with concrete examples. The reader's summary is an external overview and not part of the paper. We will revise the abstract to include brief pointers to these sections and ensure all claims are directly supported by the presented data and released artifacts. revision: partial
Circularity Check
No circularity; empirical evaluation defines its own test protocol without reduction to fitted inputs or self-citations
full rationale
The paper decomposes travel planning into five explicitly defined sub-capabilities and implements a decoupled oracle protocol to isolate performance, as stated in the abstract: 'we decompose travel planning into five constituent atomic sub-capabilities... leveraging oracle intermediate contexts to rigorously isolate these components, thereby measuring the atomic performance boundary without the noise of cascading errors.' This methodological choice is self-contained and does not derive any result by construction from prior fits, self-citations, or renamings. All claims (e.g., proficiency in explicit constraints vs. struggles with implicit ones) are direct empirical measurements under the stated protocol, with no load-bearing self-referential steps or equations that collapse to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chaudhuri, S., Purkar, P., Raghav, R., Mallick, S., Gupta, M., Jana, A., and Ghosh, S. Tripcraft: A benchmark for spatio-temporally fine grained travel planning.arXiv preprint arXiv:2502.20508,
-
[2]
Choi, J., Yoon, J., Chen, J., Jha, S., and Pfister, T. At- las: Constraints-aware multi-agent collaboration for real- world travel planning.arXiv preprint arXiv:2509.25586,
-
[3]
Retail: Towards real-world travel planning for large language models
Guo, Y ., and Wang, Y . Retail: Towards real-world travel planning for large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 14881–14913, 2025
2025
-
[3]
Retail: Towards real-world travel planning for large language models
Deng, B., Feng, Y ., Liu, Z., Wei, Q., Zhu, X., Chen, S., Guo, Y ., and Wang, Y . Retail: Towards real-world travel planning for large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 14881–14913,
2025
-
[4]
Memp: Exploring Agent Procedural Memory
Fang, R., Liang, Y ., Wang, X., Wu, J., Qiao, S., Xie, P., Huang, F., Chen, H., and Zhang, N. Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[6]
Large language models can solve real-world planning rigorously with formal verification tools
Hao, Y ., Chen, Y ., Zhang, Y ., and Fan, C. Large language models can solve real-world planning rigorously with formal verification tools. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3434–3483, 2025
2025
-
[6]
Large language models can solve real-world planning rigorously with formal verification tools
Hao, Y ., Chen, Y ., Zhang, Y ., and Fan, C. Large language models can solve real-world planning rigorously with formal verification tools. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 3434–3483,
2025
-
[7]
Hua, W., Wan, M., V ADREVU, J. S. S. S., Nadel, R., Zhang, Y ., and Wang, C. Interactive speculative planning: En- hance agent efficiency through co-design of system and user interface. InProceedings of the 13th International Conference on Learning Representations, 2025
2025
-
[7]
T., Fazel-Zarandi, M., and Tian, Y
Ju, D., Jiang, S., Cohen, A., Foss, A., Mitts, S., Zharmagam- betov, A., Amos, B., Li, X., Kao, J. T., Fazel-Zarandi, M., and Tian, Y . To the globe (TTG): Towards language- driven guaranteed travel planning. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing: System Demonstrations, pp. 240–249,
2024
-
[8]
P., Tafjord, O., and Clark, P
Jansen, P., C ˆot´e, M.-A., Khot, T., Bransom, E., Dalvi Mishra, B., Majumder, B. P., Tafjord, O., and Clark, P. Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents.Ad- vances in Neural Information Processing Systems, 2024
2024
-
[8]
Karmakar, P., Chaudhuri, S., Mallick, S., Gupta, M., Jana, A., and Ghosh, S. Triptide: A benchmark for adap- tive travel planning under disruptions.arXiv preprint arXiv:2510.21329,
-
[9]
T., Fazel-Zarandi, M., and Tian, Y
Ju, D., Jiang, S., Cohen, A., Foss, A., Mitts, S., Zharmagam- betov, A., Amos, B., Li, X., Kao, J. T., Fazel-Zarandi, M., and Tian, Y . To the globe (TTG): Towards language- driven guaranteed travel planning. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing: System Demonstrations, pp. 240–249, 2024
2024
-
[9]
Li, R., Hu, Z., Qu, W., Zhang, J., Yin, Z., Zhang, S., Huang, X., Wang, H., Wang, T., Pang, J., Ouyang, W., Bai, L., Zuo, W., Duan, L.-Y ., Zhou, D., and Tang, S. Labu- topia: High-fidelity simulation and hierarchical bench- mark for scientific embodied agents.arXiv preprint arXiv:2505.22634,
-
[10]
P., and Murthy, A
Stechly, K., Bhambri, S., Saldyt, L. P., and Murthy, A. B. Position: Llms can’t plan, but can help planning in llm- modulo frameworks. InProceedings of the 41st Inter- national Conference on Machine Learning, pp. 22895– 22907, 2024
2024
-
[10]
Lu, Z., Lu, W., Tao, Y ., Dai, Y ., Chen, Z., Zhuang, H., Chen, C., Peng, H., and Zeng, Z. Decompose, plan in parallel, and merge: A novel paradigm for large language models based planning with multiple constraints.arXiv preprint arXiv:2506.02683,
-
[11]
Ning, Y ., Liu, R., Wang, J., Chen, K., Li, W., Fang, J., Zheng, K., Tan, N., and Liu, H. Deeptravel: An end-to-end agen- tic reinforcement learning framework for autonomous travel planning agents.arXiv preprint arXiv:2509.21842,
-
[12]
2024- 09-12
URL https://openai.com/index/ learning-to-reason-with-llms/ . 2024- 09-12. Qin, Y ., Liang, S., Ye, Y ., Zhu, K., Yan, L., Lu, Y ., Lin, Y ., Cong, X., Tang, X., Qian, B., et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InProceedings of the 12th International Conference on Learning Representations,
2024
-
[13]
9 Revisiting the Travel Planning Capabilities of Large Language Models Qu, Y ., Xiao, H., Li, F., Zhou, H., and Dai, X. Trip- score: Benchmarking and rewarding real-world travel planning with fine-grained evaluation.arXiv preprint arXiv:2510.09011,
-
[14]
Llm with tools: A survey.arXiv preprint arXiv:2409.18807, 2024
Shen, Z. Llm with tools: A survey.arXiv preprint arXiv:2409.18807,
-
[15]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Cong, X., Tang, X., Qian, B., et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InProceedings of the 12th International Conference on Learning Representations, 2024. 9 Revisiting the Travel Planning Capabilities of Large Language Models
2024
-
[15]
Personal large language model agents: A case study on tailored travel planning
Singh, H., Verma, N., Wang, Y ., Bharadwaj, M., Fashandi, H., Ferreira, K., and Lee, C. Personal large language model agents: A case study on tailored travel planning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 486–514,
2024
-
[16]
github.io/IJCAI2025/
URL https://chinatravel-competition. github.io/IJCAI2025/. 2025-08-25. Wang, K., Shen, Y ., Lv, C., Zheng, X., and Huang, X.- J. Triptailor: A real-world benchmark for personalized travel planning. InFindings of the Association for Com- putational Linguistics, pp. 9705–9723,
2025
-
[17]
Chinatravel: An open-ended travel planning benchmark with compositional constraint validation for language agents
Guo, L.-Z., and Li, Y .-F. Chinatravel: An open-ended travel planning benchmark with compositional constraint validation for language agents. InProceedings of the 14th International Conference on Learning Representations, 2026
2026
-
[17]
Scienceworld: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp
Wang, R., Jansen, P., C ˆot´e, M.-A., and Ammanabrolu, P. Scienceworld: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11279– 11298,
2022
-
[18]
Personal travel solver: A preference-driven llm-solver system for travel planning
Shao, Z., Wu, J., Chen, W., and Wang, X. Personal travel solver: A preference-driven llm-solver system for travel planning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 27622–27642, 2025
2025
-
[18]
URL https://lilianweng.github.io/posts/ 2023-06-23-agent/. 2023-06-23. Xie, C. and Zou, D. A human-like reasoning framework for multi-phases planning task with large language models. arXiv preprint arXiv:2405.18208,
-
[19]
Yang, H., Yue, S., and He, Y . Auto-gpt for online decision making: Benchmarks and additional opinions.arXiv preprint arXiv:2306.02224,
-
[20]
Reflexion: Language agents with verbal rein- forcement learning.Advances in Neural Information Processing Systems, 2023
Yao, S. Reflexion: Language agents with verbal rein- forcement learning.Advances in Neural Information Processing Systems, 2023
2023
-
[20]
Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
Zhang, C., Goh, X. D., Li, D., Zhang, H., and Liu, Y . Plan- ning with multi-constraints via collaborative language agents. InProceedings of the 31st International Confer- ence on Computational Linguistics, pp. 10054–10082, 2025a. Zhang, K., Chen, X., Liu, B., Xue, T., Liao, Z., Liu, Z., Wang, X., Ning, Y ., Chen, Z., Fu, X., et al. Agent learning via ear...
-
[21]
Personal large language model agents: A case study on tailored travel planning
Singh, H., Verma, N., Wang, Y ., Bharadwaj, M., Fashandi, H., Ferreira, K., and Lee, C. Personal large language model agents: A case study on tailored travel planning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp. 486–514, 2024. TPC Organizers. Chinatravel competition, 2025. URL https://china...
2024
-
[21]
Statistics of Errors in Plan Generation Figure 6 and Figure 7 show the specific causes of errors in the plans generated by the model
10 Revisiting the Travel Planning Capabilities of Large Language Models A. Statistics of Errors in Plan Generation Figure 6 and Figure 7 show the specific causes of errors in the plans generated by the model. On TripCraft, Gemini 3 Pro exhibits a high number of all error types due to the large number of solutions with formatting errors. 0 20 40 60 80 Erro...
2022
-
[22]
Triptailor: A real-world benchmark for personalized travel planning
Wang, K., Shen, Y ., Lv, C., Zheng, X., and Huang, X.- J. Triptailor: A real-world benchmark for personalized travel planning. InFindings of the Association for Com- putational Linguistics, pp. 9705–9723, 2025
2025
-
[23]
Scienceworld: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp
Wang, R., Jansen, P., C ˆot´e, M.-A., and Ammanabrolu, P. Scienceworld: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11279– 11298, 2022
2022
-
[24]
Llm-powered autonomous agents, 2023
Weng, L. Llm-powered autonomous agents, 2023. URL https://lilianweng.github.io/posts/ 2023-06-23-agent/. 2023-06-23
2023
-
[26]
Travelplanner: a benchmark for real-world planning with language agents
Xie, J., Zhang, K., Chen, J., Zhu, T., Lou, R., Tian, Y ., Xiao, Y ., and Su, Y . Travelplanner: a benchmark for real-world planning with language agents. InProceedings of the 41st International Conference on Machine Learning, pp. 54590–54613, 2024
2024
-
[28]
R., and Cao, Y
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y . React: Synergizing reasoning and acting in language models. InProceedings of the 11th International Conference on Learning Representations, 2023
2023
-
[30]
A Survey of Large Language Models
Min, Y ., Zhang, B., Zhang, J., Dong, Z., et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 2023. 10 Revisiting the Travel Planning Capabilities of Large Language Models A. Statistics of Errors in Plan Generation Figure 6 and Figure 7 show the specific causes of errors in the plans generated by the model. On TripCraft, Gemini 3 Pro...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.