Recognition: 2 theorem links
What Happens Inside Agent Memory? Circuit Analysis from Emergence to Diagnosis
Pith reviewed 2026-05-08 18:29 UTC · model grok-4.3
The pith
Agent memory in language models activates routing decisions before it can store or retrieve facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across the Qwen-3 model family from 0.6B to 14B parameters and two memory frameworks, routing circuitry for memory decisions becomes causally detectable at 0.6B parameters while content-handling circuitry shows no detectable signal until 4B parameters. Write and Read operations both converge on a late-layer hub that already exists in the base model as a context-grounding substrate, and memory framing recruits a memory-specific direction on this substrate rather than creating a new one. The resulting circuit map supports an unsupervised diagnostic that localizes silent memory failures to the responsible stage at up to 76.2 percent accuracy.
What carries the argument
Feature circuits that implement the write, manage, and read stages of agent memory, with early routing circuitry and a late-layer shared hub as the central objects.
If this is right
- Small models can make memory routing decisions without yet being able to extract or ground the relevant facts.
- Memory frameworks primarily recruit existing base-model structures instead of requiring entirely new learned components.
- Unsupervised stage-level diagnostics can localize failures more accurately than supervised baselines.
- The core computations are properties of the base model and transfer across different memory interfaces.
- Circuit signatures provide a concrete handle for monitoring and guiding the design of agent memory systems.
Where Pith is reading between the lines
- Scaling memory performance may require separate attention to closing the gap between early routing and later content circuits.
- Targeted interventions on the shared late-layer hub could improve memory reliability without retraining the entire model.
- The same circuit-tracing approach could be applied to other agent components such as planning or tool use.
- Memory systems might be made more robust by explicitly strengthening content circuits in models below 4B parameters.
Load-bearing premise
The circuits found by activation patching and attribution are the actual causal mechanisms for the memory stages rather than correlated but non-causal patterns.
What would settle it
An experiment that intervenes on the identified routing circuits at 0.6B parameters and finds no change in memory routing behavior would falsify the causal claim.
Figures










read the original abstract
Agent memory failures are silent: an LLM-based agent can produce a fluent response even when it fails to extract, retain, or retrieve the information needed across sessions. The write-manage-read loop describes the external pipeline of these systems but leaves open which internal computations implement each stage. Tracing feature circuits across the Qwen-3 family (0.6B--14B) and two memory frameworks (mem0 and A-MEM), we report two mechanistic findings and one deliverable. First, control is detectable before content: routing circuitry is causally active at 0.6B, while content circuitry produces no detectable signal until 4B, exposing a deployment regime where small models route memory decisions before they can reliably extract or ground the underlying facts. Second, the shared hub is recruited, not created: Write and Read converge on a late-layer hub that already exists in the base model as a context-grounding substrate, and memory framing recruits a memory-specific functional direction on this substrate rather than building one of its own. Both findings transfer across mem0 and A-MEM, indicating that the underlying computations are properties of the base model rather than of any particular interface. Building on this circuit structure, we develop an unsupervised stage-level diagnostic that localizes silent failures to the responsible operation up to 76.2% accuracy, outperforming the strongest supervised baseline by 13 points. Together, these results point to circuit-level signatures as a practical handle for monitoring and structurally-guided design of agent memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper traces feature circuits in the Qwen-3 model family (0.6B–14B) across two agent memory frameworks (mem0 and A-MEM) to identify internal implementations of the write-manage-read loop. It reports that routing circuitry becomes causally active at 0.6B while content circuitry only appears at 4B, that write and read operations recruit an existing late-layer context-grounding hub rather than creating a new one, and that these patterns transfer across frameworks. Building on the circuits, the authors introduce an unsupervised diagnostic that localizes silent memory failures to the responsible stage with up to 76.2% accuracy, outperforming the strongest supervised baseline by 13 points.
Significance. If the causal claims are substantiated, the work supplies concrete mechanistic evidence for how memory routing and content handling emerge with scale and how existing base-model circuits are repurposed, which could inform both monitoring of agent failures and structurally guided memory design. The explicit cross-framework transfer and the unsupervised diagnostic (76.2% accuracy) are practical strengths that move beyond purely correlational scaling observations.
major comments (2)
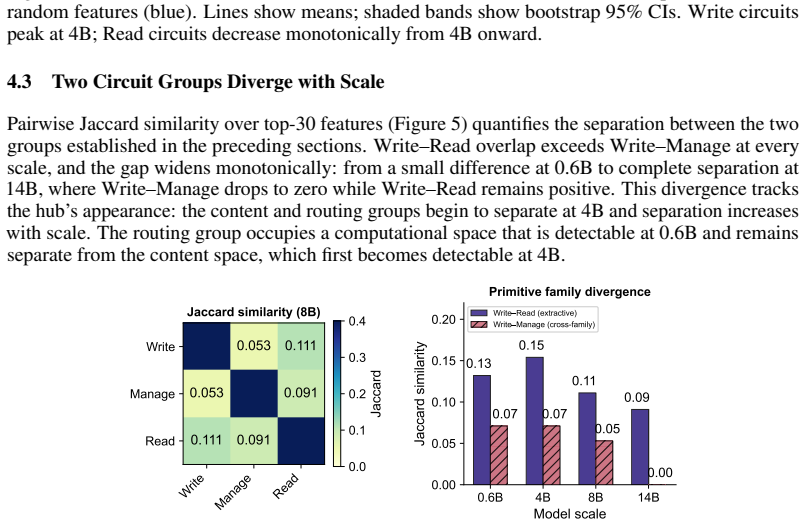
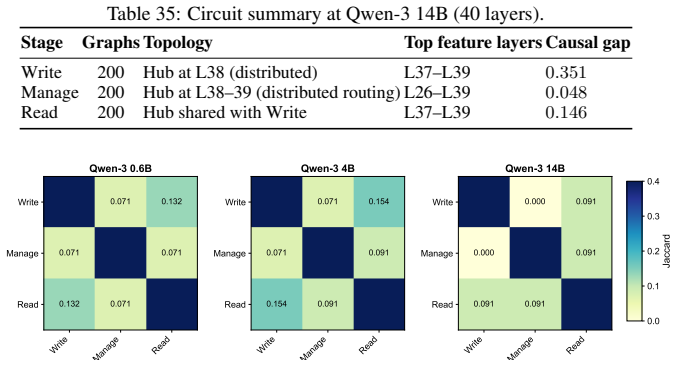
- [Section 4.2] Section 4.2 (emergence results): the claim that 'routing circuitry is causally active at 0.6B' while content circuitry shows 'no detectable signal until 4B' is load-bearing for the precedence finding. The manuscript must specify the exact causal interventions (e.g., feature ablation or activation patching) and report the selective degradation in routing decisions versus content extraction; correlational metrics alone (activation magnitude or feature presence) would reduce the result to a scaling correlation.
- [Section 5.3] Section 5.3 (unsupervised diagnostic): the reported 76.2% accuracy and 13-point gain over the supervised baseline depend on the identified circuits faithfully corresponding to write-manage-read stages. The paper should include an ablation showing that diagnostic performance collapses when the same number of non-causal features are substituted, and must detail how stage labels are assigned without post-hoc selection.
minor comments (2)
- The abstract and Section 3 would benefit from a concise description of the circuit-identification pipeline (SAE features, directional analysis, or patching protocol) so readers can assess post-hoc selection risk without reading the full methods.
- [Figure 3] Figure 3 (scaling plots): add error bars across multiple random seeds and clarify the exact threshold used to declare 'no detectable signal' for content circuitry.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback, which has helped clarify the presentation of our causal results and the validation of the diagnostic. We address each major comment below and have revised the manuscript to incorporate the requested details and additional experiments.
read point-by-point responses
-
Referee: [Section 4.2] Section 4.2 (emergence results): the claim that 'routing circuitry is causally active at 0.6B' while content circuitry shows 'no detectable signal until 4B' is load-bearing for the precedence finding. The manuscript must specify the exact causal interventions (e.g., feature ablation or activation patching) and report the selective degradation in routing decisions versus content extraction; correlational metrics alone (activation magnitude or feature presence) would reduce the result to a scaling correlation.
Authors: We agree that the causal nature of the emergence claims requires explicit intervention details rather than relying solely on correlational evidence. The original manuscript described the circuit identification process and noted causal activity but presented the scale-specific results primarily via activation patterns. In the revised version, we have expanded Section 4.2 with a dedicated paragraph and new figure detailing the activation patching protocol used: at each model scale we ablated the discovered routing and content features in turn, measuring the resulting change in task performance. This shows selective degradation—patching routing features impairs routing decisions at 0.6B while leaving content extraction largely intact, with the reverse pattern emerging only at 4B. Full quantitative results and statistical tests are now reported in the main text and Appendix C to substantiate the precedence finding beyond correlation. revision: yes
-
Referee: [Section 5.3] Section 5.3 (unsupervised diagnostic): the reported 76.2% accuracy and 13-point gain over the supervised baseline depend on the identified circuits faithfully corresponding to write-manage-read stages. The paper should include an ablation showing that diagnostic performance collapses when the same number of non-causal features are substituted, and must detail how stage labels are assigned without post-hoc selection.
Authors: We acknowledge that demonstrating the diagnostic's dependence on the causal circuits, rather than on any features, strengthens the result. In the revised manuscript we have added an ablation study to Section 5.3 in which we substitute the circuit-derived features with an equal number of randomly selected non-causal features drawn from the same layers; diagnostic accuracy falls to near-chance levels, confirming specificity. We have also clarified the stage-labeling procedure in the methods: labels are assigned automatically according to the scale thresholds at which each circuit type first exhibits a causal patching effect (as established in Section 4), using fixed effect-size criteria with no iterative or post-hoc tuning based on diagnostic performance. This process is fully deterministic and reproducible from the patching data alone. revision: yes
Circularity Check
No circularity: empirical circuit tracing and diagnostic are self-contained
full rationale
The paper's central claims rest on direct empirical observations from feature circuit tracing across Qwen-3 model scales (0.6B to 14B) and two external memory frameworks (mem0, A-MEM). No equations, fitted parameters, or self-definitional reductions appear in the derivation; the precedence of routing over content circuitry, the recruitment of an existing hub, and the 76.2% unsupervised diagnostic accuracy are presented as measured outcomes from activation analysis and comparisons to baselines, not quantities defined by the authors' own prior fits or citations. The work is self-contained against external benchmarks and does not invoke load-bearing self-citations or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature circuits identified via activation patching or similar methods correspond to the causal computations implementing memory stages.
Reference graph
Works this paper leans on
-
[1]
2024 , date =
New embedding models and. 2024 , date =
2024
-
[2]
Which Agent Causes Task Failures and When? On Automated Failure Attribution of
Shaokun Zhang and Ming Yin and Jieyu Zhang and Jiale Liu and Zhiguang Han and Jingyang Zhang and Beibin Li and Chi Wang and Huazheng Wang and Yiran Chen and Qingyun Wu , booktitle=. Which Agent Causes Task Failures and When? On Automated Failure Attribution of. 2025 , url=
2025
-
[3]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[4]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review arXiv
-
[5]
How does
Michael Hanna and Ollie Liu and Alexandre Variengien , booktitle=. How does. 2023 , url=
2023
-
[6]
The Twelfth International Conference on Learning Representations , year=
Successor Heads: Recurring, Interpretable Attention Heads In The Wild , author=. The Twelfth International Conference on Learning Representations , year=
-
[7]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[8]
The 2023 Conference on Empirical Methods in Natural Language Processing , year=
Dissecting Recall of Factual Associations in Auto-Regressive Language Models , author=. The 2023 Conference on Empirical Methods in Natural Language Processing , year=
2023
-
[9]
Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers , author=. arXiv preprint arXiv:2603.07670 , year=
-
[10]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review arXiv
-
[11]
, author=
MemGPT: towards LLMs as operating systems. , author=. 2023 , publisher=
2023
-
[12]
A-Mem: Agentic Memory for
Wujiang Xu and Zujie Liang and Kai Mei and Hang Gao and Juntao Tan and Yongfeng Zhang , booktitle=. A-Mem: Agentic Memory for. 2025 , url=
2025
-
[13]
Agentic memory: Learning unified long-term and short-term memory management for large language model agents , author=. arXiv preprint arXiv:2601.01885 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Ama-bench: Evaluating long-horizon memory for agentic applications, 2026
AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications , author=. arXiv preprint arXiv:2602.22769 , year=
-
[15]
Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning , author=. arXiv preprint arXiv:2508.19828 , year=
work page internal anchor Pith review arXiv
-
[16]
Gonzalez and Ion Stoica , booktitle=
Mert Cemri and Melissa Z Pan and Shuyi Yang and Lakshya A Agrawal and Bhavya Chopra and Rishabh Tiwari and Kurt Keutzer and Aditya Parameswaran and Dan Klein and Kannan Ramchandran and Matei Zaharia and Joseph E. Gonzalez and Ion Stoica , booktitle=. Why Do Multi-Agent. 2025 , url=
2025
-
[17]
Proceedings of the National Academy of Sciences , volume=
Explaining neural scaling laws , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[18]
The Eleventh International Conference on Learning Representations , year=
Progress measures for grokking via mechanistic interpretability , author=. The Eleventh International Conference on Learning Representations , year=
-
[19]
General Agent Evaluation , author=. arXiv preprint arXiv:2602.22953 , year=
work page internal anchor Pith review arXiv
-
[20]
arXiv preprint arXiv:2603.00026 , year=
ActMem: Bridging the Gap Between Memory Retrieval and Reasoning in LLM Agents , author=. arXiv preprint arXiv:2603.00026 , year=
-
[21]
Memory in the Age of AI Agents
Memory in the age of ai agents , author=. arXiv preprint arXiv:2512.13564 , year=
work page internal anchor Pith review arXiv
-
[22]
Evaluating Memory in
Yuanzhe Hu and Yu Wang and Julian McAuley , booktitle=. Evaluating Memory in. 2026 , url=
2026
-
[23]
MemoryArena: Benchmarking agent memory in interdependent multi-session agentic tasks , author=. arXiv preprint arXiv:2602.16313 , year=
-
[24]
Mem2ActBench: A Benchmark for Evaluating Long-Term Memory Utilization in Task-Oriented Autonomous Agents , author=. arXiv preprint arXiv:2601.19935 , year=
-
[25]
Atommem : Learnable dynamic agentic memory with atomic memory operation, 2026
AtomMem: Learnable Dynamic Agentic Memory with Atomic Memory Operation , author=. arXiv preprint arXiv:2601.08323 , year=
-
[26]
Fademem: Biologically-inspired forgetting for efficient agent memory , author=. arXiv preprint arXiv:2601.18642 , year=
-
[27]
Continuum memory architectures for long-horizon LLM agents.arXiv preprint arXiv:2601.09913, 2026
Continuum Memory Architectures for Long-Horizon LLM Agents , author=. arXiv preprint arXiv:2601.09913 , year=
-
[28]
Open Problems in Mechanistic Interpretability
Open problems in mechanistic interpretability , author=. arXiv preprint arXiv:2501.16496 , year=
work page internal anchor Pith review arXiv
-
[29]
2025 , url =
Anthropic , title =. 2025 , url =
2025
-
[30]
Circuit-tracer: A new library for finding feature circuits
Hanna, Michael and Piotrowski, Mateusz and Lindsey, Jack and Ameisen, Emmanuel. Circuit-Tracer: A New Library for Finding Feature Circuits. Proceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2025. doi:10.18653/v1/2025.blackboxnlp-1.14
-
[31]
Advances in Neural Information Processing Systems , volume=
Transcoders find interpretable llm feature circuits , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
The Thirteenth International Conference on Learning Representations , year=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[33]
Scaling sparse feature circuit finding for in-context learning, 2025
Scaling sparse feature circuit finding for in-context learning , author=. arXiv preprint arXiv:2504.13756 , year=
-
[34]
Forty-second International Conference on Machine Learning , year=
Towards global-level mechanistic interpretability: A perspective of modular circuits of large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[35]
The Twelfth International Conference on Learning Representations , year=
Circuit Component Reuse Across Tasks in Transformer Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[36]
Mondorf, Philipp and Wold, Sondre and Plank, Barbara. Circuit Compositions: Exploring Modular Structures in Transformer-Based Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.727
-
[37]
GitHub repository , howpublished =
Chase, Harrison , title =. GitHub repository , howpublished =. 2022 , publisher =
2022
-
[38]
Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models
Hanna, Michael and Mueller, Aaron. Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.164
-
[39]
Advances in Neural Information Processing Systems , volume=
LLM circuit analyses are consistent across training and scale , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
ZhongXiang Sun and Xiaoxue Zang and Kai Zheng and Jun Xu and Xiao Zhang and Weijie Yu and Yang Song and Han Li , booktitle=. ReDe. 2025 , url=
2025
-
[41]
The Thirteenth International Conference on Learning Representations , year=
Retrieval Head Mechanistically Explains Long-Context Factuality , author=. The Thirteenth International Conference on Learning Representations , year=
-
[42]
arXiv preprint arXiv:2601.04131 , year=
ContextFocus: Activation Steering for Contextual Faithfulness in Large Language Models , author=. arXiv preprint arXiv:2601.04131 , year=
-
[43]
The Fourteenth International Conference on Learning Representations , year=
Toward Faithful Retrieval-Augmented Generation with Sparse Autoencoders , author=. The Fourteenth International Conference on Learning Representations , year=
-
[44]
Beyond Black-Box Interventions: Latent Probing for Faithful Retrieval-Augmented Generation
Probing Latent Knowledge Conflict for Faithful Retrieval-Augmented Generation , author=. arXiv preprint arXiv:2510.12460 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
arXiv preprint arXiv:2601.09445 , year=
Where Knowledge Collides: A Mechanistic Study of Intra-Memory Knowledge Conflict in Language Models , author=. arXiv preprint arXiv:2601.09445 , year=
-
[46]
The Thirteenth International Conference on Learning Representations , year=
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , author=. The Thirteenth International Conference on Learning Representations , year=
-
[47]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review arXiv
-
[48]
The Fourteenth International Conference on Learning Representations , year=
Latent Planning Emerges with Scale , author=. The Fourteenth International Conference on Learning Representations , year=
-
[49]
Proceedings of the AAAI conference on artificial intelligence , volume=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[50]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents , author=. arXiv preprint arXiv:2601.03236 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[52]
The Eleventh International Conference on Learning Representations , year=
Mass-Editing Memory in a Transformer , author=. The Eleventh International Conference on Learning Representations , year=
-
[53]
2025 , url =
Betley, Nicholas and Engels, Joshua and Ward, Thomas and Belrose, Nora and Millidge, Beren and Grosse, Roger and Gao, Leo and Collins, Katherine and Jue, Tony and Wu, Jeff and Marks, Samuel and Wu, William and Saunders, William and Leike, Jan and Mislove, Alan and Christiano, Paul and Hubinger, Evan and others , title =. 2025 , url =
2025
-
[54]
Advances in Neural Information Processing Systems , volume =
Improving Alignment and Robustness with Circuit Breakers , author =. Advances in Neural Information Processing Systems , volume =. 2024 , url =
2024
-
[55]
arXiv preprint , year=
How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior , author=. arXiv preprint , year=
-
[56]
AgentSys: Secure and dynamic LLM agents through explicit hierarchical memory management,
AgentSys: Secure and Dynamic LLM Agents Through Explicit Hierarchical Memory Management , author=. arXiv preprint arXiv:2602.07398 , year=
-
[57]
Multi-agent memory from a computer architecture perspective: Visions and challenges ahead
Multi-Agent Memory from a Computer Architecture Perspective: Visions and Challenges Ahead , author=. arXiv preprint arXiv:2603.10062 , year=
-
[58]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages=
-
[59]
Frontiers in Psychology , volume=
Enhancing memory retrieval in generative agents through LLM-trained cross attention networks , author=. Frontiers in Psychology , volume=. 2025 , publisher=
2025
-
[60]
ACM Transactions on Information Systems , volume=
A survey on the memory mechanism of large language model-based agents , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[61]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei. Evaluating Very Long-Term Conversational Memory of LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.747
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.