Recognition: no theorem link
Design and Implementation of BNN-Based Object Detection on FPGA
Pith reviewed 2026-05-12 01:35 UTC · model grok-4.3
The pith
A YOLOv3-tiny-like object detector using 1-bit weights runs on FPGA in Verilog RTL with 0.999964 correlation to its ONNX software counterpart.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
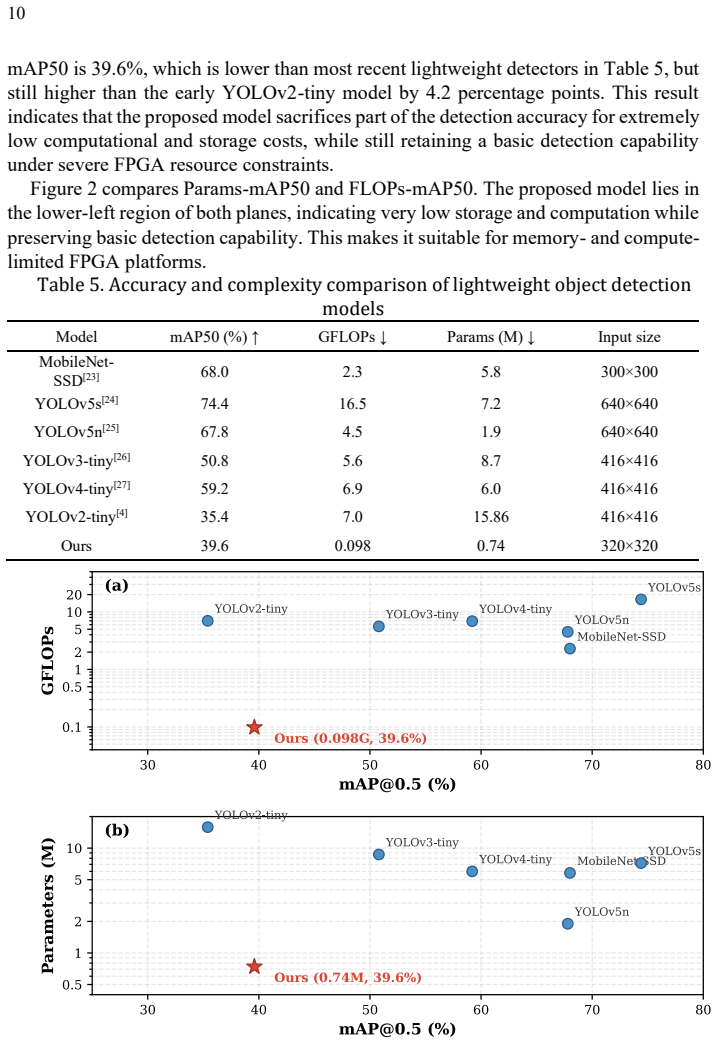
The central claim is that a hybrid-precision BNN detector, with 1-bit weights and 8-bit activations in most layers plus fixed-point heads, can be implemented on FPGA such that the final detection outputs match the software ONNX node at a correlation of 0.999964 and mean absolute error of 0.020027, while achieving 39.6 percent mAP50 on VOC.
What carries the argument
The binary convolution processing element that fuses Mul_prev channel compensation directly into the accumulation step so per-channel scaling occurs without extra multipliers.
If this is right
- Object detection becomes feasible on low-cost FPGAs with far lower memory footprint than full-precision networks.
- The design supports real-time inference for embedded vision at 0.098 GFLOPs.
- Hybrid 1-bit weight and 8-bit activation layers preserve enough accuracy for practical use on VOC.
Where Pith is reading between the lines
- The same RTL structure could be reused for other BNN vision tasks by swapping the final head.
- Power and latency measurements on physical FPGA boards would reveal whether simulation numbers translate to deployed performance.
- Direct connection to camera sensors on the same FPGA fabric would eliminate external data movement overhead.
Load-bearing premise
The Verilog code correctly performs the binary convolutions, post-processing quantization, and fused channel compensation without numerical or logical errors beyond those captured by the reported simulation metrics.
What would settle it
Feeding the same test images into actual FPGA hardware and measuring the deviation in raw detection outputs from the ONNX reference; correlation dropping well below 0.999 or error rising above 0.02 would falsify the implementation.
Figures

read the original abstract
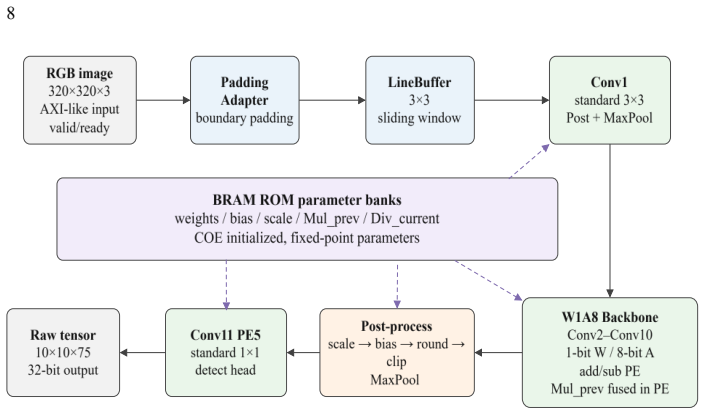
This paper implements a Binary Neural Network (BNN) based YOLOv3-tiny-like object detector on a low-cost FPGA. The network takes 320*320*3 RGB images as input. Its main convolution layers use 1-bit weights and 8-bit activations, while Conv1 and the final detection head use fixed-point standard convolutions. From the trained ONNX model, weights, biases, and quantization parameters are extracted, converted to fixed point, packed into COE files, and stored in Vivado BRAM ROMs. The hardware is written fully in Verilog RTL and includes padding, line buffering, binary convolution, quantization post-processing, max pooling, and detection-head computation. For layers where Mul_prev is indexed by input channel and Div_current by output channel, Mul_prev is fused in-to the BNN PE so that channel-wise compensation is applied during accumulation. On VOC, the model obtains 39.6% mAP50 with 0.098 GFLOPs and 0.74 M parameters. RTL simulation shows that the final raw detection output reaches a correlation coefficient of 0.999964 and a mean absolute error of 0.020027 against the corresponding ONNX node.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the design and Verilog RTL implementation of a mixed-precision BNN variant of YOLOv3-tiny for object detection on FPGA. Input images are 320×320×3 RGB; main convolution layers use 1-bit weights and 8-bit activations while Conv1 and the detection head use fixed-point standard convolutions. Weights, biases and quantization parameters are extracted from a trained ONNX model, packed into COE files and stored in BRAM ROMs. The hardware includes padding, line buffers, binary-convolution PEs, quantization post-processing, max-pooling and detection-head computation, with Mul_prev channel compensation fused into the accumulation path. On VOC the model reports 39.6 % mAP50 at 0.098 GFLOPs and 0.74 M parameters. RTL simulation of the final raw detection tensor yields a correlation of 0.999964 and MAE of 0.020027 versus the corresponding ONNX node.
Significance. If the reported simulation fidelity holds, the work supplies a concrete, low-resource FPGA realization of a BNN object detector whose numerical output matches an independent reference model to high precision. The explicit verification of binary-convolution PEs, quantization post-processing and Mul_prev fusion against an ONNX oracle is a strength for an engineering implementation paper and could serve as a useful reference for edge-AI accelerator designs.
major comments (2)
- [Results / Implementation] The manuscript provides no post-synthesis resource utilization (LUTs, BRAMs, DSPs) or timing (Fmax, slack) figures for the target FPGA. These metrics are load-bearing for any claim of a practical low-cost FPGA implementation and should be reported together with the RTL simulation results.
- [Network Architecture / Experimental Setup] Exact layer counts, per-layer bit-width choices, and the training/quantization procedure used to obtain the ONNX model are not stated. Without these details the 39.6 % mAP50 figure cannot be reproduced or compared with other BNN detectors, weakening the experimental section.
minor comments (2)
- [Abstract] The abstract and results section should explicitly name the target FPGA device and the Vivado version used for synthesis and simulation.
- [Hardware Architecture] Notation for Mul_prev and Div_current should be defined once in a table or equation before being used in the hardware-description paragraphs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [Results / Implementation] The manuscript provides no post-synthesis resource utilization (LUTs, BRAMs, DSPs) or timing (Fmax, slack) figures for the target FPGA. These metrics are load-bearing for any claim of a practical low-cost FPGA implementation and should be reported together with the RTL simulation results.
Authors: We agree with the referee that post-synthesis metrics are essential to substantiate the practicality of the FPGA implementation. The current work primarily focuses on the Verilog RTL design and its functional verification through simulation against the ONNX model. In the revised manuscript, we will add the post-synthesis resource utilization figures (including LUTs, BRAMs, and DSPs) and timing reports (Fmax and slack) for the target FPGA. revision: yes
-
Referee: [Network Architecture / Experimental Setup] Exact layer counts, per-layer bit-width choices, and the training/quantization procedure used to obtain the ONNX model are not stated. Without these details the 39.6 % mAP50 figure cannot be reproduced or compared with other BNN detectors, weakening the experimental section.
Authors: We thank the referee for this observation. Although the abstract outlines the bit-width choices at a high level, we acknowledge the need for more precise details. In the revised version, we will include exact layer counts, a per-layer specification of bit-widths for weights and activations, and a description of the training and quantization procedure that led to the ONNX model. This will improve reproducibility and allow better comparison with related BNN object detectors. revision: yes
Circularity Check
No significant circularity; implementation validated externally
full rationale
This is an engineering implementation paper describing Verilog RTL for a mixed-precision BNN YOLOv3-tiny variant on FPGA. The load-bearing claim is that the hardware produces raw detection outputs matching an independent ONNX reference model (correlation 0.999964, MAE 0.020027) and achieves 39.6% mAP50 on the standard VOC dataset. No mathematical derivations, equations, or predictions are presented that reduce to self-fitted parameters, self-citations, or ansatzes. Weights and quantization parameters are extracted from a separately trained ONNX model and used as fixed inputs to the RTL; the simulation directly compares against that external model rather than deriving the match by construction. No self-citation chains or uniqueness theorems appear in the provided text. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Weight bit-width for main layers
- Activation bit-width for main layers
axioms (2)
- standard math Binary convolution can be realized by XNOR and population count operations with subsequent scaling.
- domain assumption RTL simulation accurately predicts post-synthesis behavior for the described neural network operations.
Reference graph
Works this paper leans on
-
[1]
In: Advances in Neural Information Processing Systems (2015)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In: Advances in Neural Information Processing Systems (2015)
work page 2015
-
[2]
In: Euro- pean Conference on Computer Vision, pp
Liu, W., Anguelov, D., Erhan, D., et al.: SSD: Single Shot MultiBox Detector. In: Euro- pean Conference on Computer Vision, pp. 21-37 (2016)
work page 2016
-
[3]
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You Only Look Once: Unified, Real - Time Object Detection. In: CVPR, pp. 779-788 (2016)
work page 2016
-
[4]
Redmon, J., Farhadi, A.: YOLO9000: Better, Faster, Stronger. In: CVPR, pp. 7263 -7271 (2017)
work page 2017
-
[5]
YOLOv3: An Incremental Improvement
Redmon, J., Farhadi, A.: YOLOv3: An Incremental Improvement. arXiv:1804.02767 (2018)
work page internal anchor Pith review arXiv 2018
-
[6]
Courbariaux, M., Bengio, Y., David, J.P.: BinaryConnect: Training Deep Neural Networks with Binary Weights during Propagations. In: NeurIPS (2015)
work page 2015
-
[7]
Hubara, I., Courbariaux, M., Soudry, D., et al.: Binarized Neural Networks. arXiv:1602.02830 (2016)
-
[8]
Rastegari, M., Ordonez, V., Redmon, J., Farhadi, A.: XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In: ECCV, pp. 525-542 (2016)
work page 2016
-
[9]
Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients,
Zhou, S., Wu, Y., Ni, Z., et al.: DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv:1606.06160 (2016)
-
[10]
Liu, Z., Shen, Z., Savvides, M., Cheng, K.T.: ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions. arXiv:2003.03488 (2020)
-
[11]
Esser, S.K., McKinstry, J.L., Bablani, D., et al.: Learned Step Size Quantization. In: ICLR (2020)
work page 2020
-
[12]
Jacob, B., Kligys, S., Chen, B., et al.: Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In: CVPR, pp. 2704-2713 (2018)
work page 2018
-
[13]
Proceedings of the IEEE 105(12), 2295-2329 (2017)
Sze, V., Chen, Y.H., Yang, T.J., Emer, J.: Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proceedings of the IEEE 105(12), 2295-2329 (2017)
work page 2017
-
[14]
Umuroglu, Y., Fraser, N.J., Gambardella, G., et al.: FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. In: FPGA, pp. 65-74 (2017)
work page 2017
-
[15]
ACM TRETS 11(3), Ar- ticle 16 (2018)
Blott, M., Preusser, T.B., Fraser, N.J., et al.: FINN -R: An End -to-End Deep -Learning Framework for Fast Exploration of Quantized Neural Networks. ACM TRETS 11(3), Ar- ticle 16 (2018)
work page 2018
-
[16]
Sharma, H., Park, J., Mahajan, D., et al.: From High-Level Deep Neural Models to FPGAs. In: MICRO (2016)
work page 2016
-
[17]
Journal of Instrumentation 13(07), P07027 (2018)
Duarte, J., Han, S., Harris, P., et al.: Fast Inference of Deep Neural Networks in FPGAs for Particle Physics. Journal of Instrumentation 13(07), P07027 (2018)
work page 2018
-
[18]
Zhao, R., Song, W., Zhang, W., et al.: Accelerating Binarized Convolutional Neural Net- works with Software-Programmable FPGAs. In: FPGA, pp. 15-24 (2017)
work page 2017
-
[19]
Su, Y., Seng, K.P., Ang, L.M., Smith, J.: Binary Neural Networks in FPGAs: Architec- tures, Tool Flows and Hardware Comparisons. Sensors 23(22), 9254 (2023)
work page 2023
-
[20]
Journal of Circuits, Sys- tems and Computers 33(10), 2450170 (2024)
Ji, M., Al -Ars, Z., Chang, Y., Zhang, B.: Fully Pipelined FPGA Acceleration of Binary Convolutional Neural Networks with Neural Architecture Search. Journal of Circuits, Sys- tems and Computers 33(10), 2450170 (2024)
work page 2024
-
[21]
Parallel Com- puting, 103138 (2025)
Qian, W., Zhu, Z., Zhu, C., Zhu, Y.: FPGA-Based Accelerator for YOLOv5 Object Detec- tion with Optimized Computation and Data Access for Edge Deployment. Parallel Com- puting, 103138 (2025)
work page 2025
-
[22]
Computer Applications and Software 42(9) (2025)
Wen, C.J., Wang, L.T., Wang, Q., Jiang, S.: Design and Implementation of FPGA Accel- eration for YOLOv3-tiny. Computer Applications and Software 42(9) (2025)
work page 2025
-
[23]
In: Advances in Neural Information Processing Systems 31 (NeurIPS 2018) (2018)
Wang, R.J., Li, X., Ling, C.X.: Pelee: A Real -Time Object Detection System on Mobile Devices. In: Advances in Neural Information Processing Systems 31 (NeurIPS 2018) (2018)
work page 2018
-
[24]
Zhang, X., Liu, C., Yang, D., Song, T., Ye, Y., Li, K., Song, Y.: RFAConv: Receptive - Field Attention Convolution for Improving Convolutional Neural Networks. arXiv:2304.03198 (2023)
-
[25]
Jocher, G.: YOLOv5 by Ultralytics. Zenodo (2020). https://doi.org/10.5281/ze- nodo.3908559, last accessed 2026/04/28
work page doi:10.5281/ze- 2020
-
[26]
ISPRS International Journal of Geo-Information 14(9), 364 (2025)
Su, C., Zhu, L., Dai, W., Zhou, J., Wang, J., Mao, Y., Sun, J.: Nav-YOLO: A Lightweight and Efficient Object Detection Model for Real -Time Indoor Navigation on Mobile Plat- forms. ISPRS International Journal of Geo-Information 14(9), 364 (2025)
work page 2025
-
[27]
Information 16(10), 871 (2025)
El Hamdouni, S., Hdioud, B., El Fkihi, S.: Enhanced Lightweight Object Detection Model in Complex Scenes: An Improved YOLOv8n Approach. Information 16(10), 871 (2025)
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.