Recognition: unknown
MASRA: MLLM-Assisted Semantic-Relational Consistent Alignment for Video Temporal Grounding
Pith reviewed 2026-05-08 01:27 UTC · model grok-4.3
The pith
An MLLM used only at training time supplies event descriptions and clip captions that enforce semantic-temporal and relational consistency in video grounding models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
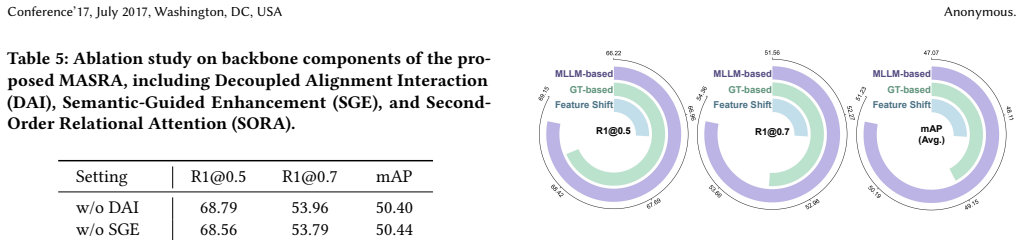
MASRA instantiates two MLLM-assisted alignments that operate on generated event descriptions with spans and clip captions: ESTA strengthens correspondence between semantics and temporal events to improve span-level separability, while LRCA aligns a textual relation matrix with the temporal feature similarity matrix to enforce consistency and capture local structure; these are augmented by semantic-guided enhancement, second-order relational attention, and Decoupled Alignment Interaction with a context-aware codebook that absorbs query-irrelevant semantics, yielding higher grounding accuracy without MLLM cost at test time.
What carries the argument
Dual MLLM-assisted alignments (ESTA for semantic-temporal correspondence and LRCA for relational matrix matching) plus Decoupled Alignment Interaction with a context-aware codebook.
Load-bearing premise
The MLLM-generated event descriptions and clip captions are accurate and unbiased enough to serve as reliable priors that genuinely improve alignment rather than adding noise.
What would settle it
Retrain the same backbone with randomly corrupted or human-mismatched MLLM-style captions and measure whether grounding metrics fall to or below the no-MASRA baseline on the same test sets.
Figures






read the original abstract
Video Temporal Grounding (VTG) faces a cross-modal semantic gap that often leads to background features being incorrectly aligned with the query, while directly matching the query to moments results in insufficient discriminability and consistency of temporal semantics. To address this issue, we propose MLLM-Assisted Semantic-Relational Consistent Alignment (MASRA), a training-time MLLM-based optimization framework for VTG. MASRA leverages an MLLM during training to produce two forms of textual priors, namely event-level descriptions with temporal spans and clip-level captions, and instantiates two MLLM-assisted alignments. Event Semantic Temporal Alignment (ESTA) aligns temporal context with event semantics to explicitly strengthen the correspondence between semantics and temporal events and improve span-level separability. Local Relational Consistency Alignment (LRCA) constructs a textual relation matrix derived from clip-level captions and aligns it with the temporal feature similarity matrix in the model, enhancing temporal consistency while capturing local structural information. MASRA includes two simple supporting modules, semantic-guided enhancement and second-order relational attention, to better utilize the learned semantic context and relational structure. Moreover, we introduce Decoupled Alignment Interaction (DAI) with a context-aware codebook to adaptively absorb query-irrelevant semantics and alleviate the cross-modal gap. The MLLM is only invoked during training and is not used at inference. Extensive experiments show that MASRA outperforms existing methods, and ablation studies validate its effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address the cross-modal semantic gap in Video Temporal Grounding (VTG) by proposing MASRA, a training-time MLLM-based optimization framework. It uses an MLLM to generate event-level descriptions with temporal spans and clip-level captions as textual priors. These enable two alignment modules: Event Semantic Temporal Alignment (ESTA) to strengthen semantics-temporal event correspondence and improve span separability, and Local Relational Consistency Alignment (LRCA) to align a textual relation matrix from clip captions with the model's temporal feature similarity matrix for better consistency and local structure. Supporting components include semantic-guided enhancement, second-order relational attention, and Decoupled Alignment Interaction (DAI) with a context-aware codebook to absorb query-irrelevant semantics. The MLLM is invoked only during training and decoupled from inference. The authors assert that extensive experiments demonstrate outperformance over existing methods and that ablation studies validate the components' effectiveness.
Significance. If the performance claims hold with rigorous validation, MASRA could advance VTG research by showing a practical way to inject MLLM-derived semantic and relational priors at training time only, mitigating cross-modal misalignment without inference overhead. The training-inference decoupling and focus on both event-level and local relational consistency are design strengths that could inspire similar augmentation strategies in other cross-modal temporal tasks.
major comments (1)
- Abstract: The central claim that 'extensive experiments show that MASRA outperforms existing methods, and ablation studies validate its effectiveness' is asserted without any quantitative results, baseline comparisons, dataset specifications, metric values, or analysis of variability (e.g., error bars or statistical significance). This absence leaves the primary empirical support for the contribution ungrounded in the provided summary and weakens evaluation of whether the proposed alignments deliver meaningful gains.
minor comments (1)
- The motivation for ESTA and LRCA is clearly tied to the stated semantic gap, but the manuscript would benefit from explicit pseudocode or algorithmic outlines for the alignment objectives and the DAI codebook update rule to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive feedback on our manuscript. We are pleased that the significance of the training-time MLLM-assisted approach is recognized. Below, we provide a point-by-point response to the major comment.
read point-by-point responses
-
Referee: Abstract: The central claim that 'extensive experiments show that MASRA outperforms existing methods, and ablation studies validate its effectiveness' is asserted without any quantitative results, baseline comparisons, dataset specifications, metric values, or analysis of variability (e.g., error bars or statistical significance). This absence leaves the primary empirical support for the contribution ungrounded in the provided summary and weakens evaluation of whether the proposed alignments deliver meaningful gains.
Authors: We agree that the abstract would benefit from including specific quantitative results to more effectively communicate the empirical contributions. While the full manuscript provides detailed experimental results, including comparisons on multiple datasets with metrics such as Recall@1 and mIoU, along with ablation studies, the abstract currently summarizes these findings at a high level. In the revised version, we will incorporate key quantitative highlights into the abstract, such as the performance improvements on standard VTG benchmarks (e.g., Charades-STA and ActivityNet), specific metric gains over baselines, and a brief note on the consistency of results across experiments. Regarding variability, we will ensure the experimental section includes error bars or multiple runs where applicable, and reference this in the abstract if space permits. This change will better ground the claims without compromising the abstract's conciseness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces MASRA as a training-time framework that augments VTG models with MLLM-generated priors via two new alignment modules (ESTA and LRCA) plus supporting components (semantic-guided enhancement, second-order relational attention, and DAI). These are explicitly motivated by the stated cross-modal semantic gap and temporal consistency issues, with the MLLM usage decoupled from inference. No equations, derivations, or first-principles results appear that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The architecture is presented as a coherent set of independent design choices validated by experiments and ablations, with no load-bearing steps that equate outputs to inputs via renaming, ansatz smuggling, or uniqueness theorems from the authors' prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. 2017. Localizing moments in video with natural language. In IEEE/CVF International Conference on Computer Vision (ICCV). 5803–5812
2017
-
[2]
Zhuo Cao, Bingqing Zhang, Heming Du, Xin Yu, Xue Li, and Sen Wang. 2025. Flashvtg: Feature layering and adaptive score handling network for video tempo- ral grounding. InW ACV. IEEE, 9226–9236
2025
-
[3]
Long Chen, Chujie Lu, Siliang Tang, Jun Xiao, Dong Zhang, Chilie Tan, and Xiaolin Li. 2020. Rethinking the bottom-up framework for query-based video localization. InAAAI Conference on Artificial Intelligence (AAAI), Vol. 34. 10551– 10558
2020
-
[4]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al . 2024. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 24185– 24198
2024
-
[5]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in Neural Information Processing Systems (NeurIPS)36 (2023), 49250–49267
2023
-
[6]
Xin Ding, Hao Wu, Yifan Yang, Shiqi Jiang, Qianxi Zhang, Donglin Bai, Zhibo Chen, and Ting Cao. 2025. Streammind: Unlocking full frame rate streaming video dialogue through event-gated cognition. InIEEE/CVF International Conference on Computer Vision (ICCV). 13448–13459
2025
-
[7]
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. 2019. Slow- fast networks for video recognition. InIEEE/CVF International Conference on Computer Vision (ICCV). 6202–6211
2019
-
[8]
Shenghao Fu, Qize Yang, Qijie Mo, Junkai Yan, Xihan Wei, Jingke Meng, Xiaohua Xie, and Wei-Shi Zheng. 2025. Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14987–14997
2025
-
[9]
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. 2017. Tall: Temporal activity localization via language query. InIEEE/CVF International Conference on Computer Vision (ICCV). 5267–5275
2017
-
[10]
Junyu Gao and Changsheng Xu. 2021. Fast video moment retrieval. InIEEE/CVF International Conference on Computer Vision (ICCV). 1523–1532
2021
-
[11]
Tiancheng Gu, Kaicheng Yang, Ziyong Feng, Xingjun Wang, Yanzhao Zhang, Dingkun Long, Yingda Chen, Weidong Cai, and Jiankang Deng. 2025. Breaking the modality barrier: Universal embedding learning with multimodal llms. In ACM International Conference on Multimedia (ACM MM). 2860–2869
2025
-
[12]
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang
-
[13]
In International Conference on Learning Representations (ICLR)
TRACE: Temporal Grounding Video LLM via Causal Event Modeling. In International Conference on Learning Representations (ICLR)
-
[14]
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. 2024. Vtimellm: Empower llm to grasp video moments. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14271–14280
2024
-
[15]
Jinhyun Jang, Jungin Park, Jin Kim, Hyeongjun Kwon, and Kwanghoon Sohn
-
[16]
InIEEE/CVF International Conference on Computer Vision (ICCV)
Knowing Where to Focus: Event-aware Transformer for Video Grounding. InIEEE/CVF International Conference on Computer Vision (ICCV). 13846–13856
-
[17]
Pu Jian, Donglei Yu, and Jiajun Zhang. 2024. Large language models know what is key visual entity: An LLM-assisted multimodal retrieval for VQA. InEMNLP. 10939–10956
2024
- [18]
-
[19]
Pilhyeon Lee and Hyeran Byun. 2024. Bam-detr: Boundary-aligned moment detection transformer for temporal sentence grounding in videos. InEuropean Conference on Computer Vision (ECCV). Springer, 220–238
2024
-
[20]
Jie Lei, Tamara L Berg, and Mohit Bansal. 2021. Detecting moments and highlights in videos via natural language queries.Advances in Neural Information Processing Systems (NeurIPS)34 (2021), 11846–11858
2021
-
[21]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326(2024)
work page internal anchor Pith review arXiv 2024
-
[22]
Juncheng Li, Junlin Xie, Long Qian, Linchao Zhu, Siliang Tang, Fei Wu, Yi Yang, Yueting Zhuang, and Xin Eric Wang. 2022. Compositional temporal grounding with structured variational cross-graph correspondence learning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3032–3041
2022
-
[23]
Pandeng Li, Chen-Wei Xie, Hongtao Xie, Liming Zhao, Lei Zhang, Yun Zheng, Deli Zhao, and Yongdong Zhang. 2023. Momentdiff: Generative video moment retrieval from random to real.Advances in Neural Information Processing Systems (NeurIPS)36 (2023)
2023
-
[24]
Wei Li, Hehe Fan, Yongkang Wong, Yi Yang, and Mohan S Kankanhalli. 2024. Improving Context Understanding in Multimodal Large Language Models via Multimodal Composition Learning.. InInternational Conference on Machine Learn- ing (ICML), Vol. 3. 7
2024
-
[25]
Wei Liao, Chunyan Xu, Chenxu Wang, and Zhen Cui. 2025. LLM-Assisted Semantic Guidance for Sparsely Annotated Remote Sensing Object Detection. In IEEE/CVF International Conference on Computer Vision (ICCV). 22519–22528
2025
-
[26]
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. 2023. Univtg: Towards unified video-language temporal grounding. InIEEE/CVF International Conference on Computer Vision (ICCV). 2794–2804
2023
-
[27]
Daizong Liu and Wei Hu. 2022. Skimming, locating, then perusing: A human- like framework for natural language video localization. InACM International Conference on Multimedia (ACM MM). 4536–4545
2022
-
[28]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved baselines with visual instruction tuning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 26296–26306
2024
-
[29]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in Neural Information Processing Systems (NeurIPS)36 (2023), 34892–34916
2023
-
[30]
Meng Liu, Xiang Wang, Liqiang Nie, Qi Tian, Baoquan Chen, and Tat-Seng Chua. 2018. Cross-modal moment localization in videos. InACM International Conference on Multimedia (ACM MM). 843–851
2018
-
[31]
Ye Liu, Siyuan Li, Yang Wu, Chang-Wen Chen, Ying Shan, and Xiaohu Qie. 2022. Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3042–3051
2022
-
[32]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations (ICLR)
2019
-
[33]
Chujie Lu, Long Chen, Chilie Tan, Xiaolin Li, and Jun Xiao. 2019. Debug: A dense bottom-up grounding approach for natural language video localization. InEmpirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 5144–5153
2019
- [34]
-
[35]
WonJun Moon, Sangeek Hyun, SangUk Park, Dongchan Park, and Jae-Pil Heo
-
[36]
InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Query-dependent video representation for moment retrieval and highlight detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 23023–23033
-
[37]
Ke Ning, Lingxi Xie, Jianzhuang Liu, Fei Wu, and Qi Tian. 2021. Interaction- integrated network for natural language moment localization.IEEE Transactions on Image Processing30 (2021), 2538–2548
2021
-
[38]
2025.GPT-5 System Card
OpenAI. 2025.GPT-5 System Card. Technical Report. OpenAI
2025
-
[39]
Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. InConference on Empirical Methods in Natural Language Processing (EMNLP). 1532–1543
2014
-
[40]
David Pujol-Perich, Sergio Escalera, and Albert Clapés. 2025. Sparse-dense side- tuner for efficient video temporal grounding. InIEEE/CVF International Conference on Computer Vision (ICCV). 21515–21524
2025
-
[41]
Mengxue Qu, Xiaodong Chen, Wu Liu, Alicia Li, and Yao Zhao. 2024. Chatvtg: Video temporal grounding via chat with video dialogue large language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1847– 1856
2024
-
[42]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML). 8748–8763
2021
-
[43]
Ran Ran, Jiwei Wei, Shiyuan He, Zeyu Ma, Chaoning Zhang, Ning Xie, and Yang Yang. 2025. KDA: Knowledge Diffusion Alignment with Enhanced Context for Video Temporal Grounding. InIEEE/CVF International Conference on Computer Vision (ICCV). 23311–23320
2025
-
[44]
Michaela Regneri, Marcus Rohrbach, Dominikus Wetzel, Stefan Thater, Bernt Schiele, and Manfred Pinkal. 2013. Grounding action descriptions in videos. Transactions of the Association for Computational Linguistics1 (2013), 25–36
2013
-
[45]
Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556(2014)
work page internal anchor Pith review arXiv 2014
-
[46]
Hao Sun, Mingyao Zhou, Wenjing Chen, and Wei Xie. 2024. Tr-detr: Task- reciprocal transformer for joint moment retrieval and highlight detection. In AAAI Conference on Artificial Intelligence (AAAI), Vol. 38. 4998–5007
2024
-
[47]
Xiaolong Sun, Liushuai Shi, Le Wang, Sanping Zhou, Kun Xia, Yabing Wang, and Gang Hua. 2025. Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding. InAAAI Conference on Artificial Intelligence (AAAI)
2025
-
[48]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review arXiv 2023
-
[49]
Junjie Wang, Bin Chen, Yulin Li, Bin Kang, Yichi Chen, and Zhuotao Tian. 2025. Declip: Decoupled learning for open-vocabulary dense perception. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14824–14834
2025
-
[50]
Jiamian Wang, Pichao Wang, Dongfang Liu, Qiang Guan, Sohail Dianat, Majid Rabbani, Raghuveer Rao, and Zhiqiang Tao. 2025. Diffusion-Inspired Truncated Sampler for Text-Video Retrieval.Advances in Neural Information Processing Systems (NeurIPS)37 (2025), 3882–3906
2025
-
[51]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review arXiv 2024
-
[52]
Zhenzhi Wang, Limin Wang, Tao Wu, Tianhao Li, and Gangshan Wu. 2022. Neg- ative sample matters: A renaissance of metric learning for temporal grounding. InAAAI Conference on Artificial Intelligence (AAAI), Vol. 36. 2613–2623
2022
-
[53]
Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Xiangtai Li, Wentao Liu, and Chen Change Loy. 2024. CLIPSelf: Vision Transformer Distills Itself for Open- Vocabulary Dense Prediction. InInternational Conference on Learning Representa- tions (ICLR)
2024
-
[54]
Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Wentao Liu, and Chen Change Loy. 2024. Clim: Contrastive language-image mosaic for region representation. InAAAI Conference on Artificial Intelligence (AAAI), Vol. 38. 6117–6125
2024
-
[55]
Yicheng Xiao, Zhuoyan Luo, Yong Liu, Yue Ma, Hengwei Bian, Yatai Ji, Yujiu Yang, and Xiu Li. 2024. Bridging the gap: A unified video comprehension framework for moment retrieval and highlight detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18709–18719
2024
-
[56]
Huijuan Xu, Kun He, Bryan A Plummer, Leonid Sigal, Stan Sclaroff, and Kate Saenko. 2019. Multilevel language and vision integration for text-to-clip retrieval. InAAAI Conference on Artificial Intelligence (AAAI), Vol. 33. 9062–9069
2019
-
[57]
Jin Yang, Ping Wei, Huan Li, and Ziyang Ren. 2024. Task-Driven Exploration: Decoupling and Inter-Task Feedback for Joint Moment Retrieval and Highlight Detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18308–18318
2024
-
[58]
Yitian Yuan, Lin Ma, Jingwen Wang, Wei Liu, and Wenwu Zhu. 2019. Semantic conditioned dynamic modulation for temporal sentence grounding in videos. Advances in Neural Information Processing Systems (NeurIPS)32 (2019)
2019
-
[59]
Runhao Zeng, Haoming Xu, Wenbing Huang, Peihao Chen, Mingkui Tan, and Chuang Gan. 2020. Dense regression network for video grounding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10287–10296
2020
- [60]
-
[61]
Hao Zhang, Aixin Sun, Wei Jing, and Joey Tianyi Zhou. 2023. Temporal sentence grounding in videos: A survey and future directions.IEEE Transactions on Pattern Analysis and Machine Intelligence(2023)
2023
-
[62]
Mingxing Zhang, Yang Yang, Xinghan Chen, Yanli Ji, Xing Xu, Jingjing Li, and Heng Tao Shen. 2021. Multi-stage aggregated transformer network for temporal language localization in videos. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12669–12678
2021
-
[63]
Songyang Zhang, Houwen Peng, Jianlong Fu, and Jiebo Luo. 2020. Learning 2d temporal adjacent networks for moment localization with natural language. In AAAI Conference on Artificial Intelligence (AAAI), Vol. 34. 12870–12877
2020
- [64]
-
[65]
Zixiang Zhao, Lilun Deng, Haowen Bai, Yukun Cui, Zhipeng Zhang, Yulun Zhang, Haotong Qin, Dongdong Chen, Jiangshe Zhang, Peng Wang, et al. 2024. Image Fusion via Vision-Language Model. InInternational Conference on Machine Learning (ICML). 60749–60765
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.