Recognition: unknown
DACP: A Scientific Data Access and Collaboration Protocol
Pith reviewed 2026-05-07 13:13 UTC · model grok-4.3
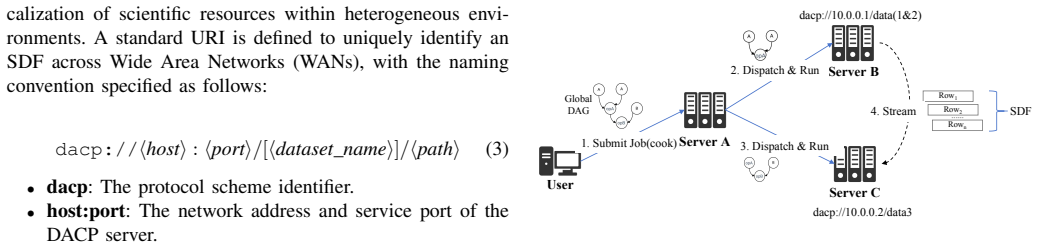
The pith
DACP protocol uses unified resource IDs and reverse supply to let scientists discover data, run in-situ computations, and stream results across centers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DACP defines the Streaming Data Frame (SDF) as its core data model. Through Unified Resource Identification, columnar stream framing, and a reverse supply mechanism, DACP enables data discovery, in-situ computation, and the streaming return of results across scientific data centers, thereby facilitating efficient cross-domain collaboration. The paper also supplies faird, a reference server implementation that shows how the protocol can be realized in practice.
What carries the argument
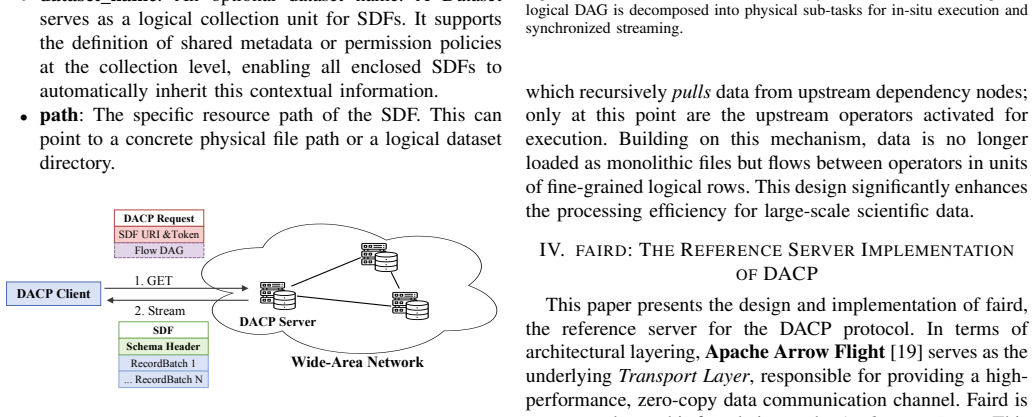
The Streaming Data Frame (SDF) together with Unified Resource Identification, columnar stream framing, and a reverse supply mechanism. SDF serves as the uniform data model that carries framing, discovery, and streaming so that computation can occur at the data location rather than after bulk transfer.
If this is right
- Data no longer needs to be copied in full before analysis, lowering transfer costs and latency.
- Cross-domain teams can run computations directly on remote holdings and receive only the derived results.
- A single protocol layer replaces ad-hoc integrations between centers.
- Reference implementations such as faird provide a concrete starting point for building larger infrastructures.
Where Pith is reading between the lines
- The approach could be extended to enforce fine-grained access policies at the frame level rather than at the file level.
- Similar framing and reverse-supply ideas might apply to real-time sensor networks or distributed simulation outputs.
- Adoption would be helped by open-source client libraries that hide the protocol details from end-user tools.
- Performance claims could be tested by measuring end-to-end latency for typical AI4Science workflows before and after DACP deployment.
Load-bearing premise
The combination of SDF framing, URI, and reverse supply will actually eliminate data silos and deliver the claimed interoperability gains once implemented, without major performance, security, or adoption obstacles.
What would settle it
Multiple independent scientific data centers deploy compatible DACP servers and successfully locate each other's datasets, execute in-situ queries, and receive streamed results with no custom per-center adapters and without transferring raw data volumes.
Figures


read the original abstract
Scientific computing is rapidly entering a data-intensive era. However, existing general-purpose network protocol stacks face limitations in eliminating data silos and improving data accessibility and interoperability, making it difficult to effectively meet the demands of emerging paradigms such as AI4Science. To address these challenges, we propose the Data Access and Collaboration Protocol (DACP). DACP defines the Streaming Data Frame (SDF) as its core data model. Through Unified Resource Identification, columnar stream framing, and a reverse supply mechanism, DACP enables data discovery, in-situ computation, and the streaming return of results across scientific data centers, thereby facilitating efficient cross-domain collaboration. Furthermore, this paper introduces faird, a reference server implementation of DACP. This work provides a viable path for building scalable and collaborative scientific data infrastructures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Data Access and Collaboration Protocol (DACP) to overcome limitations of existing network protocols in handling scientific data silos and interoperability needs for AI4Science. It defines the Streaming Data Frame (SDF) as the core data model and claims that Unified Resource Identification, columnar stream framing, and a reverse supply mechanism enable data discovery, in-situ computation, and streaming return of results across data centers. The manuscript also introduces faird as a reference server implementation to support scalable collaborative scientific data infrastructures.
Significance. If the protocol mechanisms deliver the claimed interoperability and efficiency gains upon implementation and adoption, the work could meaningfully advance scientific data infrastructure by reducing silos and supporting cross-domain collaboration in data-intensive fields. The inclusion of a reference implementation provides a concrete foundation that could facilitate community testing and extension.
major comments (2)
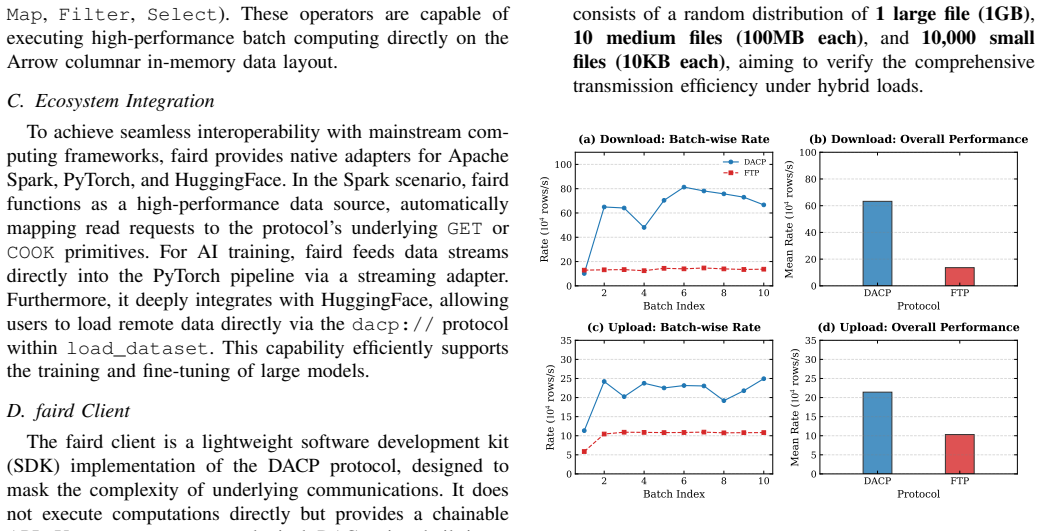
- [Abstract and §1] Abstract and §1 (Introduction): The central claims that DACP 'enables data discovery, in-situ computation, and the streaming return of results' and thereby 'facilitating efficient cross-domain collaboration' rest entirely on architectural assertions without any supporting measurements, proofs, or comparative analysis.
- [faird reference server section] faird reference server section: The implementation is described but contains no performance benchmarks, scalability tests, security analysis, throughput measurements under realistic workloads, or head-to-head comparisons against HTTP/2, Globus, iRODS, or columnar formats over gRPC, leaving the efficiency and interoperability advantages unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript proposing the Data Access and Collaboration Protocol (DACP). We address the major comments point by point below, clarifying the paper's focus as a protocol design and reference implementation while acknowledging areas for improvement.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1 (Introduction): The central claims that DACP 'enables data discovery, in-situ computation, and the streaming return of results' and thereby 'facilitating efficient cross-domain collaboration' rest entirely on architectural assertions without any supporting measurements, proofs, or comparative analysis.
Authors: The manuscript presents DACP as a protocol proposal, with the abstract and introduction stating the capabilities enabled by its core Streaming Data Frame model and mechanisms (Unified Resource Identification, columnar stream framing, and reverse supply). These are substantiated through the detailed architectural description in the body of the paper rather than through empirical data. We agree that the framing could be clearer regarding the absence of measurements and will revise the abstract and Section 1 to explicitly position the work as a design contribution, noting that quantitative evaluations and comparisons are planned for future work. revision: partial
-
Referee: [faird reference server section] faird reference server section: The implementation is described but contains no performance benchmarks, scalability tests, security analysis, throughput measurements under realistic workloads, or head-to-head comparisons against HTTP/2, Globus, iRODS, or columnar formats over gRPC, leaving the efficiency and interoperability advantages unverified.
Authors: The faird reference server is presented as an open implementation to demonstrate protocol feasibility and support community adoption, consistent with the referee's summary. The section emphasizes architectural realization of DACP features over performance metrics. We concur that benchmarks and analyses would strengthen the paper and will add a dedicated subsection outlining high-level performance considerations, basic security properties of the design, and explicit plans for future benchmarking and comparisons. Full head-to-head evaluations under realistic workloads, however, exceed the scope of this design-focused manuscript. revision: partial
Circularity Check
No circularity: protocol specification with no derivations or self-referential elements
full rationale
The paper is a forward-looking protocol specification that defines DACP, Streaming Data Frame (SDF), Unified Resource Identification, columnar stream framing, and reverse supply mechanism. It contains no mathematical derivations, equations, fitted parameters, predictions, or self-citations that could reduce to inputs by construction. Architectural claims about data discovery and collaboration are presented as design features rather than derived results. The work is self-contained as a specification proposal without load-bearing steps that invoke uniqueness theorems or prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing general-purpose network protocol stacks face limitations in eliminating data silos and improving data accessibility and interoperability.
invented entities (2)
-
Streaming Data Frame (SDF)
no independent evidence
-
DACP protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
T. Hey, S. Tansley, K. M. Tolleet al.,The fourth paradigm: data- intensive scientific discovery. Microsoft research Redmond, W A, 2009, vol. 1
2009
-
[2]
The fair guiding principles for scientific data management and stewardship,
M. D. Wilkinson, M. Dumontier, I. J. Aalbersberg, G. Appleton, M. Ax- ton, A. Baak, N. Blomberg, J.-W. Boiten, L. B. da Silva Santos, P. E. Bourneet al., “The fair guiding principles for scientific data management and stewardship,”Scientific data, vol. 3, no. 1, pp. 1–9, 2016
2016
-
[3]
Scientific discovery in the age of artificial intelligence,
H. Wang, T. Fu, Y . Du, W. Gao, K. Huang, Z. Liu, P. Chandak, S. Liu, P. Van Katwyk, A. Deacet al., “Scientific discovery in the age of artificial intelligence,”Nature, vol. 620, no. 7972, pp. 47–60, 2023
2023
-
[4]
Data integration: The teenage years,
A. Halevy, A. Rajaraman, and J. Ordille, “Data integration: The teenage years,” inProceedings of the 32nd international conference on Very large data bases, 2006, pp. 9–16
2006
-
[5]
Research data network: Concept, systems and applications,
S. Zhihong, Z. Xiaojie, W. Huajin, T. Jizhou, G. Xuebing, W. Hui, M. Yufang, and W. Linhuan, “Research data network: Concept, systems and applications,”Frontiers of Data and Computing, vol. 6, no. 4, pp. 3–21, 2024
2024
-
[6]
Data-intensive applications, challenges, techniques and technologies: A survey on big data,
C. P. Chen and C.-Y . Zhang, “Data-intensive applications, challenges, techniques and technologies: A survey on big data,”Information sci- ences, vol. 275, pp. 314–347, 2014
2014
-
[7]
Cloud-native repositories for big scientific data,
R. P. Abernathey, T. Augspurger, A. Banihirwe, C. C. Blackmon-Luca, T. J. Crone, C. L. Gentemann, J. J. Hamman, N. Henderson, C. Lepore, T. A. McCaieet al., “Cloud-native repositories for big scientific data,” Computing in Science & Engineering, vol. 23, no. 2, pp. 26–35, 2021
2021
-
[8]
Near-data processing: Insights from a micro- 46 workshop,
R. Balasubramonian, J. Chang, T. Manning, J. H. Moreno, R. Murphy, R. Nair, and S. Swanson, “Near-data processing: Insights from a micro- 46 workshop,”IEEE Micro, vol. 34, no. 4, pp. 36–42, 2014
2014
-
[9]
A protocol for packet network intercommunica- tion,
V . Cerf and R. Kahn, “A protocol for packet network intercommunica- tion,”IEEE Transactions on communications, vol. 22, no. 5, pp. 637– 648, 1974
1974
-
[10]
The world-wide web,
T. Berners-Lee, R. Cailliau, A. Luotonen, H. F. Nielsen, and A. Secret, “The world-wide web,”Communications of the ACM, vol. 37, no. 8, pp. 76–82, 1994
1994
-
[11]
The semantic web revisited,
N. Shadbolt, T. Berners-Lee, and W. Hall, “The semantic web revisited,” IEEE intelligent systems, vol. 21, no. 3, pp. 96–101, 2006
2006
-
[12]
Principled design of the modern web architecture,
R. T. Fielding and R. N. Taylor, “Principled design of the modern web architecture,”ACM Transactions on Internet Technology (TOIT), vol. 2, no. 2, pp. 115–150, 2002
2002
-
[13]
Performance evaluation of object serialization libraries in xml, json and binary formats,
K. Maeda, “Performance evaluation of object serialization libraries in xml, json and binary formats,” in2012 Second International Confer- ence on Digital Information and Communication Technology and it’s Applications (DICTAP). IEEE, 2012, pp. 177–182
2012
-
[14]
A file transfer protocol (ftp),
M. Gien, “A file transfer protocol (ftp),”Computer Networks (1976), vol. 2, no. 4-5, pp. 312–319, 1978
1976
-
[15]
The globus striped gridftp framework and server,
W. Allcock, J. Bresnahan, R. Kettimuthu, and M. Link, “The globus striped gridftp framework and server,” inSC’05: Proceedings of the 2005 ACM/IEEE conference on Supercomputing. IEEE, 2005, pp. 54– 54
2005
-
[16]
Hierarchical data format 5: Hdf5,
S. Koranne, “Hierarchical data format 5: Hdf5,” inHandbook of open source tools. Springer, 2010, pp. 191–200
2010
-
[17]
Http extensions for web distributed authoring and ver- sioning (webdav),
L. Dusseault, “Http extensions for web distributed authoring and ver- sioning (webdav),” Tech. Rep., 2007
2007
-
[18]
The quic transport protocol: Design and internet-scale deployment,
A. Langley, A. Riddoch, A. Wilk, A. Vicente, C. Krasic, D. Zhang, F. Yang, F. Kouranov, I. Swett, J. Iyengaret al., “The quic transport protocol: Design and internet-scale deployment,” inProceedings of the conference of the ACM special interest group on data communication, 2017, pp. 183–196
2017
-
[19]
Apache arrow: A cross-language development platform for in-memory data,
The Apache Software Foundation, “Apache arrow: A cross-language development platform for in-memory data,” 2024, accessed: 2025-12-20. [Online]. Available: https://arrow.apache.org/
2024
-
[20]
Yelp Open Dataset,
Yelp Inc., “Yelp Open Dataset,” 2025, accessed: 2025-12-29. [Online]. Available: https://www.yelp.com/dataset
2025
-
[21]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.