Recognition: 2 theorem links
· Lean TheoremVL-SAM-v3: Memory-Guided Visual Priors for Open-World Object Detection
Pith reviewed 2026-05-12 01:29 UTC · model grok-4.3
The pith
VL-SAM-v3 augments open-world object detection by retrieving visual prototypes from a memory bank to create fine-grained priors that improve recognition of rare categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
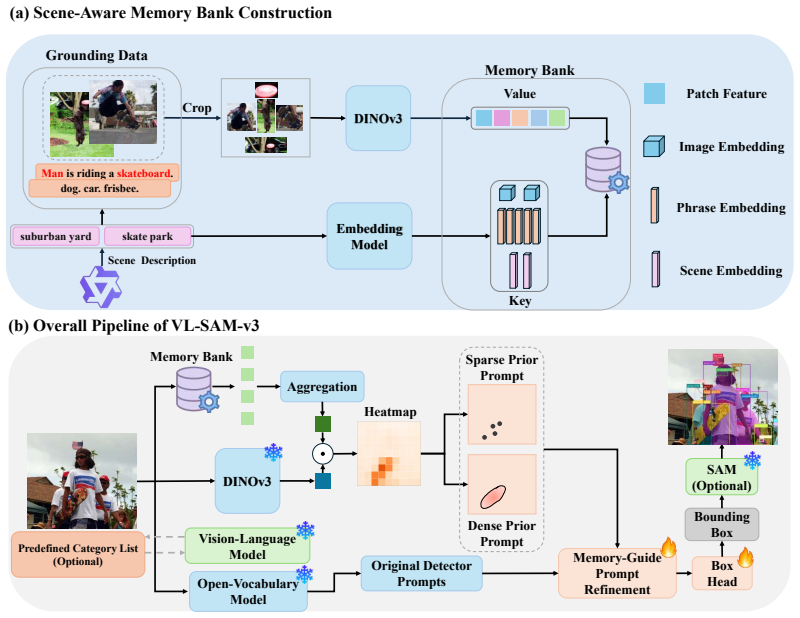
VL-SAM-v3 is a unified framework that augments open-world detection with retrieval-grounded external visual memory. Once candidate categories are available, it retrieves relevant visual prototypes from a non-parametric memory bank and transforms them into sparse priors for instance-level spatial anchoring and dense priors for class-aware local context. These priors are integrated with the original detection prompts via Memory-Guided Prompt Refinement. The resulting shared retrieval-and-refinement mechanism supports both open-vocabulary and open-ended inference, and zero-shot experiments on LVIS demonstrate consistent performance improvements with particularly strong gains on rare categories.
What carries the argument
Memory-Guided Prompt Refinement, which converts retrieved visual prototypes into complementary sparse spatial priors and dense contextual priors and fuses them with the detector's original prompts.
If this is right
- Detection accuracy rises in zero-shot open-vocabulary settings on LVIS.
- Detection accuracy rises in zero-shot open-ended settings on LVIS.
- Gains are largest on rare categories.
- The same retrieval-and-refinement step improves performance when applied to a stronger base detector.
- Visual priors complement textual semantics for fine-grained appearance and cluttered scenes.
Where Pith is reading between the lines
- Non-parametric visual memory could serve as a lightweight complement to parametric models across other vision tasks that struggle with rare classes.
- Detection performance might scale further if the memory bank grows in size or diversity without any model retraining.
- The approach could be tested on additional benchmarks beyond LVIS to check whether the gains hold for different scene distributions.
- Dynamic updating of the memory bank could allow detectors to incorporate new visual knowledge over time.
Load-bearing premise
The visual prototypes pulled from the non-parametric memory bank supply enough fine-grained appearance detail to improve detection beyond what coarse textual semantics alone can provide.
What would settle it
Zero-shot evaluation of VL-SAM-v3 on LVIS where adding the memory-retrieved priors produces no gain or a drop in average precision for rare categories compared with the un-augmented baseline detector.
Figures


read the original abstract
Open-world object detection aims to localize and recognize objects beyond a fixed closed-set label space. It is commonly divided into two categories, i.e., open-vocabulary detection, which assumes a predefined category list at test time, and open-ended detection, which requires generating candidate categories during the inference. Existing methods rely primarily on coarse textual semantics and parametric knowledge, which often provide insufficient visual evidence for fine-grained appearance variation, rare categories, and cluttered scenes. In this paper, we propose VL-SAM-v3, a unified framework that augments open-world detection with retrieval-grounded external visual memory. Specifically, once candidate categories are available, VL-SAM-v3 retrieves relevant visual prototypes from a non-parametric memory bank and transforms them into two complementary visual priors, i.e., sparse priors for instance-level spatial anchoring and dense priors for class-aware local context. These priors are integrated with the original detection prompts via Memory-Guided Prompt Refinement, enabling a shared retrieval-and-refinement mechanism that supports open-vocabulary and open-ended inference. Extensive zero-shot experiments on LVIS show that VL-SAM-v3 consistently improves detection performance under both open-vocabulary and open-ended inference, with particularly strong gains on rare categories. Moreover, experiments with a stronger open-vocabulary detector (i.e., SAM3) validate the generality of the proposed retrieval-and-refinement mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VL-SAM-v3, a unified framework for open-world object detection that augments detectors with retrieval-grounded external visual memory. Candidate categories trigger retrieval of visual prototypes from a non-parametric memory bank; these are converted into sparse priors (instance-level spatial anchoring) and dense priors (class-aware local context), which are fused with detection prompts through Memory-Guided Prompt Refinement. The same retrieval-and-refinement mechanism supports both open-vocabulary and open-ended inference. Zero-shot experiments on LVIS are reported to yield consistent gains, especially on rare categories, with additional validation on a stronger baseline (SAM3).
Significance. If the memory bank is verifiably disjoint from LVIS and retrieval supplies genuine fine-grained appearance evidence beyond text, the approach would address a recognized limitation of purely parametric or textual priors in open-world detection. The unified handling of open-vocabulary and open-ended settings plus the SAM3 generality test are strengths. However, the absence of quantitative results, ablations, or construction details in the abstract, combined with the unverifiable zero-shot status, currently limits the assessed impact.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent improvements' and 'particularly strong gains on rare categories' on LVIS is stated without any numerical results, baselines, error bars, or ablation tables. This renders the empirical contribution unverifiable from the provided text and is load-bearing for acceptance.
- [Methods (memory bank)] Methods section describing the non-parametric memory bank: no details are supplied on source datasets, construction procedure, indexing mechanism, or explicit safeguards ensuring zero overlap with LVIS training/validation/test images and annotations. Because the zero-shot claim on rare categories rests on the memory bank supplying external visual evidence, this omission creates a direct risk of indirect supervision or leakage that must be resolved.
minor comments (2)
- [Introduction] Clarify the relationship between VL-SAM-v3 and prior VL-SAM versions; a brief comparison table would help readers understand incremental contributions.
- [Experiments] The term 'SAM3' is used without definition or citation; confirm whether it refers to a public model, an internal variant, or a typo for an existing baseline.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive feedback. We have revised the manuscript to directly address the concerns regarding the abstract and the memory bank description, improving verifiability while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent improvements' and 'particularly strong gains on rare categories' on LVIS is stated without any numerical results, baselines, error bars, or ablation tables. This renders the empirical contribution unverifiable from the provided text and is load-bearing for acceptance.
Authors: We agree that the abstract would benefit from explicit numerical support for the claims. In the revised version, we have updated the abstract to include key quantitative results from the LVIS experiments (e.g., absolute mAP gains on rare categories for both open-vocabulary and open-ended settings relative to strong baselines), while directing readers to the full tables, error bars, and ablations in the experimental section. This change makes the empirical contribution verifiable from the abstract without exceeding typical length constraints. revision: yes
-
Referee: [Methods (memory bank)] Methods section describing the non-parametric memory bank: no details are supplied on source datasets, construction procedure, indexing mechanism, or explicit safeguards ensuring zero overlap with LVIS training/validation/test images and annotations. Because the zero-shot claim on rare categories rests on the memory bank supplying external visual evidence, this omission creates a direct risk of indirect supervision or leakage that must be resolved.
Authors: We thank the referee for identifying this important omission. The original Methods section provided only a high-level description; we have now expanded it substantially in the revision to detail: (1) source datasets (public collections such as ImageNet subsets and other disjoint corpora, explicitly excluding any LVIS images or annotations), (2) construction procedure (per-category prototype extraction via a frozen visual encoder on curated exemplar images), (3) indexing mechanism (FAISS-based approximate nearest-neighbor search for scalable retrieval), and (4) safeguards (automated image-ID and perceptual-hash overlap checks against all LVIS splits, plus a verification script released with the code). These additions confirm the memory bank supplies genuine external visual evidence with no leakage, supporting the zero-shot setting. revision: yes
Circularity Check
No circularity in empirical retrieval-and-refinement framework
full rationale
The paper describes an empirical method that augments detection prompts via retrieval of visual prototypes from a non-parametric memory bank followed by Memory-Guided Prompt Refinement. No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the abstract or method summary. The central claims rest on zero-shot experimental gains on LVIS rather than any closed-loop construction where outputs are forced by inputs or prior self-citations. The derivation chain is therefore self-contained as a proposed engineering pipeline whose validity is tested externally.
Axiom & Free-Parameter Ledger
invented entities (1)
-
non-parametric memory bank of visual prototypes
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearMemory-Guided Prompt Refinement module
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Guiping Cao, Tao Wang, Wenjian Huang, Xiangyuan Lan, Jianguo Zhang, and Dongmei Jiang. Open-det: An efficient learning framework for open-ended detection.arXiv preprint arXiv:2505.20639, 2025
-
[3]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Jianing Yang, David F Fouhey, Joyce Chai, and Shengyi Qian. Multi-object hallucination in vision language models.Advances in Neural Information Processing Systems, 37:44393–44418, 2024
work page 2024
-
[5]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
YOLO- World: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. YOLO- World: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 16901–16911, 2024
work page 2024
-
[7]
Achal Dave, Piotr Dollár, Deva Ramanan, Alexander Kirillov, and Ross Girshick. Evaluating large-vocabulary object detectors: The devil is in the details.arXiv preprint arXiv:2102.01066, 2021
-
[8]
The faiss library.IEEE Transactions on Big Data, 2025
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre- Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. The faiss library.IEEE Transactions on Big Data, 2025
work page 2025
-
[9]
Learning to prompt for open-vocabulary object detection with vision-language model
Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. Learning to prompt for open-vocabulary object detection with vision-language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14084–14093, 2022
work page 2022
-
[10]
PromptDet: Towards open-vocabulary detection using uncurated images
Chengjian Feng, Yujie Zhong, Zequn Jie, Xiangxiang Chu, Haibing Ren, Xiaolin Wei, Weidi Xie, and Lin Ma. PromptDet: Towards open-vocabulary detection using uncurated images. In European Conference on Computer Vision, pages 701–717. Springer, 2022
work page 2022
-
[11]
Shenghao Fu, Qize Yang, Qijie Mo, Junkai Yan, Xihan Wei, Jingke Meng, Xiaohua Xie, and Wei- Shi Zheng. LLMDet: Learning strong open-vocabulary object detectors under the supervision of large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14987–14997, 2025
work page 2025
-
[12]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Lvis: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019
work page 2019
-
[14]
OW-DETR: Open-world detection transformer
Akshita Gupta, Sanath Narayan, KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Mubarak Shah. OW-DETR: Open-world detection transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9235–9244, 2022
work page 2022
-
[15]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5v and glm-4.1v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. Product quantization for nearest neighbor search.IEEE transactions on pattern analysis and machine intelligence, 33(1):117–128, 2010
work page 2010
-
[17]
T-rex2: Towards generic object detection via text-visual prompt synergy
Qing Jiang, Feng Li, Zhaoyang Zeng, Tianhe Ren, Shilong Liu, and Lei Zhang. T-rex2: Towards generic object detection via text-visual prompt synergy. InEuropean Conference on Computer Vision, pages 38–57. Springer, 2024
work page 2024
-
[18]
Towards open world object detection
KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Vineeth N Balasubramanian. Towards open world object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5830–5840, 2021
work page 2021
-
[19]
Retrieval-augmented open- vocabulary object detection
Jooyeon Kim, Eulrang Cho, Sehyung Kim, and Hyunwoo J Kim. Retrieval-augmented open- vocabulary object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17427–17436, 2024
work page 2024
-
[20]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023
work page 2023
-
[21]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
work page 2020
-
[22]
Jiaxuan Li, Duc Minh V o, Akihiro Sugimoto, and Hideki Nakayama. EVCAP: Retrieval- augmented image captioning with external visual-name memory for open-world comprehension. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13733–13742, 2024
work page 2024
-
[23]
Liunian Li, Zi-Yi Dou, Nanyun Peng, and Kai-Wei Chang. Desco: Learning object recognition with rich language descriptions.Advances in Neural Information Processing Systems, 36: 37511–37526, 2023
work page 2023
-
[24]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10965–10975, 2022
work page 2022
-
[25]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720, 2026
work page internal anchor Pith review arXiv 2026
-
[26]
Generative region-language pretraining for open-ended object detection
Chuang Lin, Yi Jiang, Lizhen Qu, Zehuan Yuan, and Jianfei Cai. Generative region-language pretraining for open-ended object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13958–13968, 2024
work page 2024
-
[27]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[28]
Zhiwei Lin and Yongtao Wang. VL-SAM-v2: Open-world object detection with general and specific query fusion.arXiv preprint arXiv:2505.18986, 2025
-
[29]
Zhiwei Lin, Yongtao Wang, and Zhi Tang. Training-free open-ended object detection and segmentation via attention as prompts.Advances in Neural Information Processing Systems, 37: 69588–69606, 2024
work page 2024
-
[30]
Grounding DINO: Marrying DINO with grounded pre- training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding DINO: Marrying DINO with grounded pre- training for open-set object detection. InEuropean Conference on Computer Vision, pages 38–55. Springer, 2024. 11
work page 2024
-
[31]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[32]
Retrieval augmented classification for long-tail visual recognition
Alexander Long, Wei Yin, Thalaiyasingam Ajanthan, Vu Nguyen, Pulak Purkait, Ravi Garg, Alan Blair, Chunhua Shen, and Anton Van den Hengel. Retrieval augmented classification for long-tail visual recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6959–6969, 2022
work page 2022
-
[33]
Capdet: Unifying dense captioning and open-world detection pretraining
Yanxin Long, Youpeng Wen, Jianhua Han, Hang Xu, Pengzhen Ren, Wei Zhang, Shen Zhao, and Xiaodan Liang. Capdet: Unifying dense captioning and open-world detection pretraining. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15233–15243, 2023
work page 2023
-
[34]
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection.Advances in Neural Information Processing Systems, 36:72983–73007, 2023
work page 2023
-
[35]
OpenScene: 3d scene understanding with open vocabularies
Songyou Peng, Kyle Genova, Chiyu Jiang, Andrea Tagliasacchi, Marc Pollefeys, Thomas Funkhouser, et al. OpenScene: 3d scene understanding with open vocabularies. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 815–824, 2023
work page 2023
-
[36]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 779–788, 2016
work page 2016
-
[37]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks.Advances in Neural Information Processing Systems, 28, 2015
work page 2015
-
[38]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Simon Schrodi, David T Hoffmann, Max Argus, V olker Fischer, and Thomas Brox. Two effects, one trigger: On the modality gap, object bias, and information imbalance in contrastive vision-language models.arXiv preprint arXiv:2404.07983, 2024
-
[40]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Hao Wang, Pengzhen Ren, Zequn Jie, Xiao Dong, Chengjian Feng, Yinlong Qian, Lin Ma, Dongmei Jiang, Yaowei Wang, Xiangyuan Lan, et al. Ov-dino: Unified open-vocabulary detection with language-aware selective fusion.arXiv preprint arXiv:2407.07844, 2024
-
[42]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Yifan Xu, Mengdan Zhang, Chaoyou Fu, Peixian Chen, Xiaoshan Yang, Ke Li, and Changsheng Xu. Multi-modal queried object detection in the wild.Advances in Neural Information Processing Systems, 36:4452–4469, 2023
work page 2023
-
[44]
Lewei Yao, Jianhua Han, Youpeng Wen, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, Chunjing Xu, and Hang Xu. Detclip: Dictionary-enriched visual-concept paralleled pre-training for open-world detection.Advances in Neural Information Processing Systems, 35:9125–9138, 2022
work page 2022
-
[45]
Detclipv2: Scalable open-vocabulary object detection pre-training via word-region alignment
Lewei Yao, Jianhua Han, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, and Hang Xu. Detclipv2: Scalable open-vocabulary object detection pre-training via word-region alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23497–23506, 2023. 12
work page 2023
-
[46]
DetCLIPv3: Towards versatile generative open-vocabulary object detection
Lewei Yao, Renjie Pi, Jianhua Han, Xiaodan Liang, Hang Xu, Wei Zhang, Zhenguo Li, and Dan Xu. DetCLIPv3: Towards versatile generative open-vocabulary object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27391–27401, 2024
work page 2024
-
[47]
Haotian Zhang, Pengchuan Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, and Jianfeng Gao. Glipv2: Unifying localization and vision-language understanding.Advances in Neural Information Processing Systems, 35: 36067–36080, 2022
work page 2022
-
[48]
Xiangyu Zhao, Yicheng Chen, Shilin Xu, Xiangtai Li, Xinjiang Wang, Yining Li, and Haian Huang. An open and comprehensive pipeline for unified object grounding and detection.arXiv preprint arXiv:2401.02361, 2024
-
[49]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022. 13 A Additional implementation details This section provides additional implementation details for the external visual memory in VL-SAM- v3. We first describe how scene descriptors are...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.