Recognition: unknown
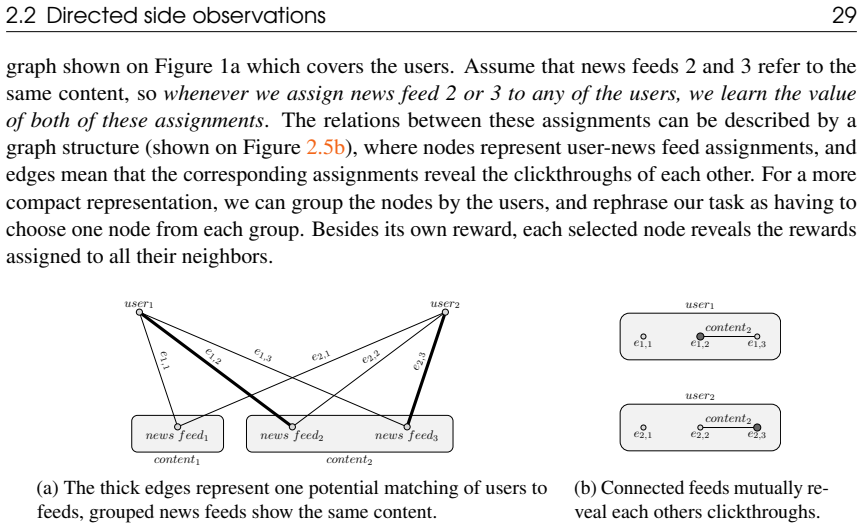
Bandits on graphs and structures
Pith reviewed 2026-05-07 17:00 UTC · model grok-4.3
The pith
Representing bandit actions as graphs or using smoothness and structural priors makes learning feasible in exponential and infinite action spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that investigating structural properties of sequential problems, with emphasis on graph representations of actions and large or infinite structured domains, brings bandit solutions closer to practical use. This covers smoothness of rewards on graphs via spectral methods, side observations, influence maximization, kernel bandits including unknown smoothness, polymatroid bandits, and bandits with infinitely many arms. The thesis presents these as a survey of contributions demonstrating that such structures enable efficient learning where naive approaches fail.
What carries the argument
Graph representations of action spaces together with smoothness, side observations, and other structural assumptions that compress the effective search space in bandit problems.
If this is right
- Spectral bandits on graphs achieve improved regret by using the graph Laplacian to capture reward smoothness across connected actions.
- Side observations in graph bandits accelerate learning by propagating feedback from neighboring actions.
- Kernel bandits with unknown smoothness extend function optimization to continuous domains without prior knowledge of the Lipschitz constant.
- Polymatroid and infinite-arm bandits handle exponential or countably infinite action sets through submodular or structural priors.
- Influence maximization bandits apply these ideas to select seed nodes that maximize spread under graph diffusion models.
Where Pith is reading between the lines
- The same structural lens could be applied to non-stationary or adversarial settings where action graphs change over time.
- These representations might reduce sample complexity in reinforcement learning when states or actions inherit similar graph structure.
- Practical deployment would benefit from testing how robust the methods remain when the assumed graph or kernel only approximately matches reality.
Load-bearing premise
That graph and structural representations of actions will produce solutions that remain both theoretically sound and practically usable without hidden performance costs or limitations not addressed in the original work.
What would settle it
An empirical evaluation on a large real-world problem where a standard bandit algorithm without graph or structural assumptions matches or exceeds the regret and runtime of the structured methods while remaining computationally tractable.
Figures














read the original abstract
The goal of this thesis is to investigate the structural properties of certain sequential problems in order to bring the solutions closer to a practical use. In the first part, we put a special emphasis on structures that can be represented as graphs on actions. In the second part, we study the large action spaces that can be of exponential size in the number of base actions or even infinite. For graph bandits, we consider the settings of smoothness of rewards (spectral bandits), side observations, and influence maximization. For large structured domains, we cover kernel bandits, polymatroid bandits, bandits for function optimization (including unknown smoothness), and infinitely many-arms bandits. The thesis aspires to be a survey of the author's contributions on graph and structured bandits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This manuscript is a PhD thesis surveying the author's prior contributions on bandit algorithms that exploit structural properties of sequential decision problems. The first part focuses on graph-structured action spaces, covering spectral smoothness (spectral bandits), side observations, and influence maximization. The second part addresses large or infinite action spaces, including kernel bandits, polymatroid bandits, function optimization (with unknown smoothness), and infinitely many-arms bandits. The central aim is to investigate these structures to make theoretical solutions more practical.
Significance. As a compilation and synthesis of existing results rather than a source of new theorems or experiments, the manuscript could provide a useful reference point for the bandits community if the integration across works is coherent and highlights transferable insights on scalability. The focus on graph and structural assumptions aligns with ongoing efforts to move beyond unstructured multi-armed bandits, but the lack of new empirical comparisons or unified theoretical frameworks limits its potential impact relative to a standard research article.
minor comments (2)
- Abstract: the phrasing 'brings the solutions closer to a practical use' is vague; it would be clearer to specify concrete metrics or settings (e.g., regret reduction factors or computational savings) where the structural assumptions yield improvements over unstructured baselines.
- The manuscript would benefit from an explicit section comparing the computational and statistical trade-offs across the surveyed settings (e.g., spectral vs. polymatroid assumptions) to strengthen the practical-use narrative.
Simulated Author's Rebuttal
We thank the referee for their review and recommendation of minor revision. The thesis is a synthesis of prior contributions, and we address the points on coherence, transferable insights, and impact below.
read point-by-point responses
-
Referee: As a compilation and synthesis of existing results rather than a source of new theorems or experiments, the manuscript could provide a useful reference point for the bandits community if the integration across works is coherent and highlights transferable insights on scalability. The focus on graph and structural assumptions aligns with ongoing efforts to move beyond unstructured multi-armed bandits, but the lack of new empirical comparisons or unified theoretical frameworks limits its potential impact relative to a standard research article.
Authors: We agree that the thesis compiles prior results and thank the referee for noting its alignment with current research. The manuscript integrates the works by organizing them into graph bandits (spectral smoothness, side observations, influence maximization) and structured bandits (kernel, polymatroid, unknown smoothness, infinite arms), with cross-references highlighting transferable ideas such as smoothness assumptions enabling scalability. We have revised the introduction and added a dedicated discussion subsection to explicitly call out these insights. As this is a thesis rather than a new research article, we did not introduce fresh experiments or a single unified framework; however, we have added a comparative table in the conclusion summarizing regret bounds and practical trade-offs from the original papers, and we now flag unified frameworks as an open direction. revision: partial
Circularity Check
No significant circularity: survey of prior external contributions
full rationale
This thesis is framed explicitly as a survey compiling the author's prior publications on graph bandits (spectral smoothness, side observations, influence maximization) and large structured domains (kernels, polymatroids, function optimization, infinite arms). No new derivations, parameter fits, or predictions are introduced within the document itself; all load-bearing results are referenced to independent prior works. The derivation chain therefore consists of external citations rather than any self-referential reduction, fitted-input renaming, or ansatz smuggling internal to this text, rendering the content self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improved algorithms for linear stochastic bandits
Abbasi-Yadkori, Yasin, Dávid Pál, and Csaba Szepesvári (2011). “Improved algorithms for linear stochastic bandits”. In:Neural Information Processing Systems(cited on pages 9, 18)
2011
-
[1]
Improved algorithms for linear stochastic bandits
Abbasi-Yadkori, Yasin, Dávid Pál, and Csaba Szepesvári (2011). “Improved algorithms for linear stochastic bandits”. In:Neural Information Processing Systems(cited on pages 9, 18). Agrawal, Shipra and Navin Goyal (2013). “Thompson sampling for contextual bandits with linear payoffs”. In:International Conference on Machine Learning(cited on pages 9, 16, 18)...
-
[2]
Thompson sampling for contextual bandits with linear payoffs
Agrawal, Shipra and Navin Goyal (2013). “Thompson sampling for contextual bandits with linear payoffs”. In:International Conference on Machine Learning(cited on pages 9, 16, 18)
2013
-
[2]
Delay and cooperation in nonstochastic bandits
4, pages 1148–1185 (cited on page 73). Cesa-Bianchi, Nicolò, Claudio Gentile, Yishay Mansour, and Alberto Minora (2016). “Delay and cooperation in nonstochastic bandits”. In:Conference on Learning Theory(cited on page 34). Cesa-Bianchi, Nicolò, Claudio Gentile, and Giovanni Zappella (2013). “A gang of bandits”. In: Neural Information Processing Systems(ci...
2016
-
[3]
Fast randomized kernel methods with statisti- cal guarantees
Alaoui, Ahmed El and Michael W. Mahoney (2015). “Fast randomized kernel methods with statisti- cal guarantees”. In:Neural Information Processing Systems.URL: https://papers.nips. cc/paper/5716-fast-randomized-kernel-ridge-regression-with-statistical- guarantees.pdf(cited on page 53)
2015
-
[3]
Apolo: Making sense of large network data by combining rich user interaction and machine learning
5, pages 1404–1422 (cited on pages 28, 29). Chau, Duen Horng, Aniket Kittur, Jason I. Hong, and Christos Faloutsos (2011). “Apolo: Making sense of large network data by combining rich user interaction and machine learning”. In: Conference on Human Factors in Computing Systems.URL: https://www.cc.gatech.edu/ %7B~%7Ddchau/papers/11-chi-apolo.pdf(cited on pa...
-
[4]
Online learning with feedback graphs: Beyond bandits
Alon, Noga, Nicolò Cesa-Bianchi, Ofer Dekel, and Tomer Koren (2015). “Online learning with feedback graphs: Beyond bandits”. In:Conference on Learning Theory(cited on pages 24, 28, 34, 39)
2015
-
[4]
Zhu, Xiaojin (2008).Semi-supervised learning literature survey
Springer (cited on page 19). Zhu, Xiaojin (2008).Semi-supervised learning literature survey. Technical report
2008
-
[5]
Technical report (cited on page 34)
Alon, Noga, Nicolò Cesa-Bianchi, Claudio Gentile, Shie Mannor, Yishay Mansour, and Ohad Shamir (2014).Nonstochastic multi-armed bandits with graph-structured feedback. Technical report (cited on page 34)
2014
-
[6]
From bandits to experts: A tale of domination and independence
Alon, Noga, Nicolò Cesa-Bianchi, Claudio Gentile, and Yishay Mansour (2013). “From bandits to experts: A tale of domination and independence”. In:Neural Information Processing Systems (cited on pages 8, 24, 26–28, 33–35, 39)
2013
-
[7]
Diversified utility maximization for recommendations
Ashkan, Azin, Branislav Kveton, Shlomo Berkovsky, and Zheng Wen (2014). “Diversified utility maximization for recommendations”. In:Conference on Recommender Systems(cited on page 57). — (2015). “Optimal greedy diversity for recommendation”. In:International Joint Conferences on Artificial Intelligence(cited on page 57)
2014
-
[8]
Minimax policies for adversarial and stochastic bandits
Audibert, Jean-Yves and Sébastien Bubeck (2009). “Minimax policies for adversarial and stochastic bandits”. In:Conference on Learning Theory(cited on page 75)
2009
-
[9]
Regret in online combinatorial optimization
Audibert, Jean-Yves, Sébastien Bubeck, and Gábor Lugosi (2014). “Regret in online combinatorial optimization”. In:Mathematics of Operations Research39, pages 31–45 (cited on pages 28, 59). 78 References
2014
-
[10]
Best arm identification in multi-armed bandits
Audibert, Jean-Yves, Sébastien Bubeck, and Rémi Munos (2010). “Best arm identification in multi-armed bandits”. In:Conference on Learning Theory(cited on page 75)
2010
-
[11]
Using confidence bounds for exploitation-exploration trade-offs
Auer, Peter (2002). “Using confidence bounds for exploitation-exploration trade-offs”. In:Journal of Machine Learning Research3, pages 397–422 (cited on pages 9, 16, 19, 49, 51)
2002
-
[12]
UCB revisited: Improved regret bounds for the stochastic multi-armed bandit problem
Auer, Peter and Ronald Ortner (2010). “UCB revisited: Improved regret bounds for the stochastic multi-armed bandit problem”. In:Periodica Mathematica Hungarica(cited on page 18)
2010
-
[13]
Online stochastic optimization under correlated bandit feedback
Azar, Mohammad Gheshlaghi, Alessandro Lazaric, and Emma Brunskill (2014). “Online stochastic optimization under correlated bandit feedback”. In:International Conference on Machine Learning.URL:https://proceedings.mlr.press/v32/azar14.pdf(cited on pages 63– 67)
2014
-
[15]
Learning from neighbours
Bala, Venkatesh and Sanjeev Goyal (1998). “Learning from neighbours”. In:Review of Economic Studies65.3, pages 595–621 (cited on page 34). — (2001). “Conformism and diversity under social learning”. In:Economic Theory17, pages 101– 120 (cited on page 34)
1998
-
[16]
Online influence maximization in non-stationary social networks
Bao, Yixin, Xiaoke Wang, Zhi Wang, Chuan Wu, and Francis C. M. Lau (Apr. 2016). “Online influence maximization in non-stationary social networks”. In:International Symposium on Quality of Service(cited on page 44). Barabási, Albert-László and Réka Albert (1999). “Emergence of scaling in random networks”. In: Science286, page 11 (cited on pages 37, 41). Ba...
2016
-
[17]
Regularization and semi-supervised learning on large graphs
Belkin, Mikhail, Irina Matveeva, and Partha Niyogi (2004). “Regularization and semi-supervised learning on large graphs”. In:Conference on Learning Theory.URL: https://people.cs. uchicago.edu/%7B~%7Dniyogi/papersps/reg%7B%5C_%7Dcolt.pdf (cited on page 15)
2004
-
[18]
Manifold regularization: A geo- metric framework for learning from labeled and unlabeled examples
Belkin, Mikhail, Partha Niyogi, and Vikas Sindhwani (2006). “Manifold regularization: A geo- metric framework for learning from labeled and unlabeled examples”. In:Journal of Machine Learning Research7, pages 2399–2434.URL: https://www.jmlr.org/papers/volume7/ belkin06a/belkin06a.pdf(cited on page 15)
2006
-
[19]
Bandit problems with infinitely many arms
Berry, Donald A., Robert W. Chen, Alan Zame, David C. Heath, and Larry A. Shepp (1997). “Bandit problems with infinitely many arms”. In:Annals of Statistics25, pages 2103–2116 (cited on pages 9, 47, 71, 72, 75, 76)
1997
-
[20]
Athena Scientific (cited on page 57)
Bertsimas, Dimitris and John Tsitsiklis (1997).Introduction to linear optimization. Athena Scientific (cited on page 57)
1997
-
[21]
A learning agent for wireless news access
Billsus, Daniel, Michael J. Pazzani, and James Chen (2000). “A learning agent for wireless news access”. In:International Conference on Intelligent User Interfaces(cited on page 15)
2000
-
[22]
Social network search as a volatile multi-armed bandit problem
Bnaya, Zahy, Rami Puzis, Roni Stern, and Ariel Felner (2013). “Social network search as a volatile multi-armed bandit problem”. In:Human Journal2.2, pages 84–98 (cited on page 44). 79
2013
-
[23]
Two-target algorithms for infinite-armed bandits with Bernoulli rewards
Bonald, Thomas and Alexandre Proutière (2013). “Two-target algorithms for infinite-armed bandits with Bernoulli rewards”. In:Neural Information Processing Systems(cited on pages 71, 72, 75, 76)
2013
-
[24]
Stochastic bandits with side observations on networks
Buccapatnam, Swapna, Atilla Eryilmaz, and Ness B. Shroff (2014). “Stochastic bandits with side observations on networks”. In:International Conference on Measurement and Modeling of Computer Systems(cited on pages 33, 39)
2014
-
[25]
Adaptive-treed bandits
Bull, Adam D. (2015). “Adaptive-treed bandits”. In:Bernoulli21.4, pages 2289–2307 (cited on pages 63, 64)
2015
-
[26]
Optimal adaptive policies for sequential allocation problems
Burnetas, Apostolos N. and Michael N. Katehakis (1996). “Optimal adaptive policies for sequential allocation problems”. In:Advances in Applied Mathematics17.2, pages 122–142 (cited on page 7)
1996
-
[27]
Analysis of Nyström method with sequential ridge leverage scores
Calandriello, Daniele, Alessandro Lazaric, and Michal Valko (2016). “Analysis of Nyström method with sequential ridge leverage scores”. In:Uncertainty in Artificial Intelligence(cited on page 53)
2016
-
[28]
Leveraging side observations in stochastic bandits
Caron, Stéphane, Branislav Kveton, Marc Lelarge, and Smriti Bhagat (2012). “Leveraging side observations in stochastic bandits.” In:Uncertainty in Artificial Intelligence(cited on pages 33, 39)
2012
-
[29]
Simple regret for infinitely many armed bandits
Carpentier, Alexandra and Michal Valko (2015). “Simple regret for infinitely many armed bandits”. In:International Conference on Machine Learning(cited on pages 9, 74–76). — (2016). “Revealing graph bandits for maximizing local influence”. In:International Conference on Artificial Intelligence and Statistics(cited on pages 8, 42)
2015
-
[30]
Challenging the empirical mean and empirical variance: A deviation study
Catoni, Olivier (2012). “Challenging the empirical mean and empirical variance: A deviation study”. In:Annales de l’Institut Henri Poincaré, Probabilités et Statistiques. V olume 48. 4, pages 1148–1185 (cited on page 73)
2012
-
[31]
Delay and cooperation in nonstochastic bandits
Cesa-Bianchi, Nicolò, Claudio Gentile, Yishay Mansour, and Alberto Minora (2016). “Delay and cooperation in nonstochastic bandits”. In:Conference on Learning Theory(cited on page 34)
2016
-
[32]
A gang of bandits
Cesa-Bianchi, Nicolò, Claudio Gentile, and Giovanni Zappella (2013). “A gang of bandits”. In: Neural Information Processing Systems(cited on pages 20, 22, 39)
2013
-
[33]
Combinatorial bandits
Cesa-Bianchi, Nicolò and Gábor Lugosi (2006).Prediction, learning, and games(cited on page 13). — (2012). “Combinatorial bandits”. In:Journal of Computer and System Sciences. V olume 78. 5, pages 1404–1422 (cited on pages 28, 29)
2006
-
[34]
Apolo: Making sense of large network data by combining rich user interaction and machine learning
Chau, Duen Horng, Aniket Kittur, Jason I. Hong, and Christos Faloutsos (2011). “Apolo: Making sense of large network data by combining rich user interaction and machine learning”. In: Conference on Human Factors in Computing Systems.URL: https://www.cc.gatech.edu/ %7B~%7Ddchau/papers/11-chi-apolo.pdf(cited on page 15)
2011
-
[35]
Scalable influence maximization for prevalent viral marketing in large-scale social networks
Chen, Wei, Chi Wang, and Yajun Wang (2010). “Scalable influence maximization for prevalent viral marketing in large-scale social networks”. In:Knowledge Discovery and Data Mining (cited on page 44)
2010
-
[36]
Combinatorial multi-armed bandit and its extension to probabilistically triggered arms
Chen, Wei, Yajun Wang, and Yang Yuan (2016). “Combinatorial multi-armed bandit and its extension to probabilistically triggered arms”. In:Journal of Machine Learning Research17. URL: https : / / www . jmlr . org / papers / volume17 / 14 - 298 / 14 - 298 . pdf(cited on page 43). 80 References
2016
-
[37]
Contextual bandits with linear payoff functions
Chu, Lei, Lihong Li, Lev Reyzin, and Robert E. Schapire (2011). “Contextual bandits with linear payoff functions”. In:International Conference on Artificial Intelligence and Statistics(cited on pages 19, 51–53)
2011
-
[38]
Online learning with feedback graphs without the graphs
Cohen, Alon, Tamir Hazan, and Tomer Koren (2016). “Online learning with feedback graphs without the graphs”. In:International Conference on Machine Learning(cited on page 35). “Collaborative filtering Bandits” (2016). In:Conference on Research and Development in Informa- tion Retrieval(cited on page 21)
2016
-
[39]
Unimodal bandits: Regret lower bounds and optimal algorithms
Combes, Richard and Alexandre Proutière (2014). “Unimodal bandits: Regret lower bounds and optimal algorithms”. In:International Conference on Machine Learning(cited on page 21)
2014
-
[40]
Stochastic process bandits: Upper confidence bounds algorithms via generic chaining
Contal, Emile and Nicolas Vayatis (Feb. 2016). “Stochastic process bandits: Upper confidence bounds algorithms via generic chaining”. In: arXiv:1602.04976(cited on page 53)
-
[41]
Bandit algorithms for tree search
Coquelin, Pierre-Arnaud and Rémi Munos (2007). “Bandit algorithms for tree search”. In:Uncer- tainty in Artificial Intelligence(cited on page 63)
2007
-
[42]
Efficient selectivity and backup operators in Monte-Carlo tree search
Coulom, Rémi (2007). “Efficient selectivity and backup operators in Monte-Carlo tree search”. In:Computers and games4630, pages 72–83.URL: https : / / hal . inria . fr / inria - 00116992/document(cited on page 63)
2007
-
[43]
Parallelizing exploration-exploitation tradeoffs in Gaussian process bandit optimization
Desautels, Thomas, Andreas Krause, and Joel Burdick (2012). “Parallelizing exploration-exploitation tradeoffs in Gaussian process bandit optimization”. In:International Conference on Machine Learning(cited on page 19)
2012
-
[44]
Submodular functions, matroids, and certain polyhedra
Edmonds, Jack (1970). “Submodular functions, matroids, and certain polyhedra”. In:Combinatorial Structures and Their Applications, pages 69–87 (cited on page 56)
1970
-
[45]
Rules of thumb for social learning
Ellison, Glenn and Drew Fudenberg (1993). “Rules of thumb for social learning”. In:Journal of Political Economy101.4, pages 612–643 (cited on page 34). Erd˝os, Paul and Alfréd Rényi (1959). “On random graphs”. In:Publicationes Mathematicae6, pages 290–297 (cited on page 35)
1993
-
[46]
Networked bandits with disjoint linear payoffs
Fang, Meng and Dacheng Tao (2014). “Networked bandits with disjoint linear payoffs”. In:Inter- national Conference on Knowledge Discovery and Data Mining(cited on page 21)
2014
-
[47]
Multistage campaigning in social networks
Farajtabar, Mehrdad, Xiaojing Ye, Sahar Harati, Le Song, and Hongyuan Zha (2016). “Multistage campaigning in social networks”. In:Neural Information Processing Systems(cited on page 44)
2016
-
[48]
Annals of discrete mathematics (cited on page 57)
Fujishige, Satoru (2005).Submodular functions and optimization. Annals of discrete mathematics (cited on page 57)
2005
-
[49]
Adaptive submodular maximization in bandit setting
Gabillon, Victor, Branislav Kveton, Zheng Wen, Brian Eriksson, and S. Muthukrishnan (2013). “Adaptive submodular maximization in bandit setting”. In:Neural Information Processing Systems(cited on page 61). — (2014). “Large-scale optimistic adaptive submodularity”. In:AAAI Conference on Artificial Intelligence(cited on page 61)
2013
-
[50]
Combinatorial network optimization with unknown variables: Multi-armed bandits with linear rewards and individual observations
Gai, Yi, Bhaskar Krishnamachari, and Rahul Jain (2012). “Combinatorial network optimization with unknown variables: Multi-armed bandits with linear rewards and individual observations”. In:Transactions on Networking20.5, pages 1466–1478 (cited on page 60)
2012
-
[51]
Bayesian learning in social networks
Gale, Douglas and Shachar Kariv (2003). “Bayesian learning in social networks”. In:Games and Economic Behavior45.2, pages 329–346 (cited on page 34)
2003
-
[52]
Technical report
Gelly, Sylvain, Wang Yizao, Rémi Munos, and Olivier Teytaud (2006).Modification of UCT with patterns in Monte-Carlo Go. Technical report. Inria.URL: https://hal.inria.fr/inria- 00117266(cited on page 63)
2006
-
[53]
Online clustering of bandits
Gentile, Claudio, Shuai Li, and Giovanni Zappella (2014). “Online clustering of bandits”. In: International Conference on Machine Learning(cited on pages 21, 39)
2014
-
[54]
Ising bandits with side Information
Ghosh, Shaona and Adam Prügel-Bennett (2015). “Ising bandits with side Information”. In:Euro- pean Conference on Machine Learning(cited on page 34). 81
2015
-
[55]
Community structure in social and biological networks
Girvan, Michelle and Mark E J Newman (2002). “Community structure in social and biological networks.” In:National Academy of Sciences of the United States of America99.12, pages 7821– 6 (cited on page 37)
2002
-
[56]
Black-box optimization of noisy functions with unknown smoothness
Grill, Jean-Bastien, Michal Valko, and Rémi Munos (2015). “Black-box optimization of noisy functions with unknown smoothness”. In:Neural Information Processing Systems.URL: https: //papers.nips.cc/paper/5721-black-box-optimization-of-noisy-functions- with-unknown-smoothness.pdf(cited on pages 9, 63–65, 67, 68). — (2016). “Blazing the trails before beating...
2015
-
[57]
Online spectral learning on a graph with bandit feedback
Gu, Quanquan and Jiawei Han (2014). “Online spectral learning on a graph with bandit feedback”. In:International Conference on Data Mining(cited on pages 20, 39)
2014
-
[58]
Online submodular set cover, ranking, and repeated active learning
Guillory, Andrew and Jeff Bilmes (2011). “Online submodular set cover, ranking, and repeated active learning”. In:Neural Information Processing Systems(cited on page 61)
2011
-
[59]
Collaborative filtering as a multi-armed bandit
Guillou, Frédéric, Romaric Gaudel, and Philippe Preux (Dec. 2015). “Collaborative filtering as a multi-armed bandit”. In:NIPS Workshop on Machine Learning for eCommerce(cited on page 22). — (2016). “Scalable explore-exploit collaborative filtering”. In:Pacific Asia Conference on Infor- mation Systems(cited on page 22)
2015
-
[60]
Classification with kernel Mahalanobis dis- tance classifiers
Haasdonk, Bernard and El ˙zbieta P˛ ekalska (2010). “Classification with kernel Mahalanobis dis- tance classifiers”. In:Advances in Data Analysis, Data Handling and Business Intelligence, pages 351–361 (cited on pages 49, 50)
2010
-
[61]
Cheap Bandits
Hanawal, Manjesh, Venkatesh Saligrama, Michal Valko, and Rémi Munos (2015). “Cheap Bandits”. In:International Conference on Machine Learning(cited on pages 8, 20)
2015
-
[62]
Approximation to Bayes risk in repeated play
Hannan, James (1957). “Approximation to Bayes risk in repeated play”. In:Contributions to the theory of games3, pages 97–139 (cited on page 29)
1957
-
[63]
Fundamentals of Data Mining in Genomics and Proteomics
Hauskrecht, Milos, Richard Pelikan, Michal Valko, and James Lyons-Weiler (2006). “Fundamentals of Data Mining in Genomics and Proteomics”. In: edited by Berrar, Dubitzky, and Granzow. Springer. Chapter Feature Se (cited on page 71)
2006
-
[64]
Cambridge University Press.URL: www.scholat.com/ teamwork/teamworkdownloadscholar.html?id=542%7B%5C&%7DteamId=316 (cited on page 15)
Jannach, Dietmar, Markus Zanker, Alexander Felfernig, and Gerhard Friedrich (2010).Recom- mender systems: An introduction. Cambridge University Press.URL: www.scholat.com/ teamwork/teamworkdownloadscholar.html?id=542%7B%5C&%7DteamId=316 (cited on page 15). Kaggle (2013).Kaggle.URL:https://www.kaggle.com/(cited on page 69)
2010
-
[65]
Efficient algorithms for online decision problems
Kalai, Adam and Santosh Vempala (2005). “Efficient algorithms for online decision problems”. In: Journal of Computer and System Sciences71.3, pages 291–307 (cited on page 29)
2005
-
[66]
Efficient Thompson sampling for online matrix-factorization recommendation
Kawale, Jaya, Hung Hai Bui, Branislav Kveton, Long Tran-Thanh, and Sanjay Chawla (2015). “Efficient Thompson sampling for online matrix-factorization recommendation”. In:Neural Information Processing Systems(cited on page 22)
2015
-
[67]
Maximizing the spread of influence through a social network
Kempe, David, Jon Kleinberg, and Éva Tardos (2003). “Maximizing the spread of influence through a social network”. In:Knowledge Discovery and Data Mining, page 137 (cited on pages 39, 43). — (2015). “Maximizing the spread of influence through a social network”. In:Theory of Computing 11.4, pages 105–147 (cited on pages 8, 39)
2003
-
[68]
Multi-armed bandit problems in metric spaces
Kleinberg, Robert, Aleksandrs Slivkins, and Eli Upfal (2008). “Multi-armed bandit problems in metric spaces”. In:Symposium on Theory Of Computing(cited on pages 63, 64, 66). Kocák, Tomáš, Gergely Neu, and Michal Valko (2016a). “Online learning with Erd˝os–Rényi side- observation graphs”. In:Conference on Uncertainty in Artificial Intelligence(cited on pag...
-
[69]
Bandit-based Monte-Carlo planning
Kocsis, Levente and Csaba Szepesvári (2006). “Bandit-based Monte-Carlo planning”. In:European Conference on Machine Learning(cited on pages 63, 65)
2006
-
[70]
Collaborative learning of stochastic bandits over a social network
Kolla, Ravi Kumar, Krishna Jagannathan, and Aditya Gopalan (2016). “Collaborative learning of stochastic bandits over a social network”. In:Annual Allerton Conference on Communication, Control, and Computing(cited on page 33)
2016
-
[71]
Hedging structured concepts
Koolen, Wouter M., Manfred K. Warmuth, and Jyrki Kivinen (2010). “Hedging structured concepts”. In:Conference on Learning Theory(cited on pages 28, 29)
2010
-
[72]
Distributed clustering of linear bandits in peer to peer networks
Korda, Nathan, Balázs Szörényi, and Shuai Li (Apr. 2016). “Distributed clustering of linear bandits in peer to peer networks”. In:International Conference on Machine Learning.URL: https: //proceedings.mlr.press/v48/korda16.pdf(cited on page 21)
2016
-
[73]
Combinatorial preconditioners and multilevel solvers for problems in computer vision and image processing
Koutis, Ioannis, Gary L. Miller, and David Tolliver (2011). “Combinatorial preconditioners and multilevel solvers for problems in computer vision and image processing”. In:Computer Vision and Image Understanding115.12, pages 1638–1646.URL: https://www.cs.cmu.edu/ %7B~%7D./jkoutis/papers/cviu%7B%5C_%7Dpreprint.pdf(cited on page 19)
2011
-
[74]
Matroid bandits: Fast combinatorial optimization with learning
Kveton, Branislav, Zheng Wen, Azin Ashkan, Hoda Eydgahi, and Brian Eriksson (2014). “Matroid bandits: Fast combinatorial optimization with learning”. In:Uncertainty in Artificial Intelligence (cited on pages 58–60)
2014
-
[75]
Learning to act greedily: Polymatroid semi-bandits
Kveton, Branislav, Zheng Wen, Azin Ashkan, and Michal Valko (2016). “Learning to act greedily: Polymatroid semi-bandits”. In:Journal of Machine Learning Research(cited on pages 9, 47, 60, 61)
2016
-
[76]
Online influence maximization
Lei, Siyu, Silviu Maniu, Luyi Mo, Reynold Cheng, and Pierre Senellart (2015). “Online influence maximization”. In:Knowledge Discovery and Data mining(cited on page 43)
2015
-
[77]
A contextual-bandit approach to personalized news article recommendation
Li, Lihong, Wei Chu, John Langford, and Robert E. Schapire (2010). “A contextual-bandit approach to personalized news article recommendation”. In:International World Wide Web Conference (cited on pages 9, 16–18)
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.