Recognition: unknown
Understanding Self-Supervised Learning via Latent Distribution Matching
Pith reviewed 2026-05-07 17:02 UTC · model grok-4.3
The pith
Self-supervised learning works by matching representations to an assumed latent model while maximizing their entropy to avoid collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We cast SSL as latent distribution matching (LDM): learning representations that maximize their log-probability under an assumed latent model (alignment), while maximizing latent entropy to prevent collapse (uniformity). This view unifies independent component analysis with contrastive, non-contrastive, and predictive SSL methods, including stop gradient approaches. Leveraging LDM, we derive a nonlinear, sampling-free Bayesian filtering model with a Kalman-based predictor for high-dimensional timeseries. We further prove that predictive LDM yields identifiable latent representations under mild assumptions, even with nonlinear predictors.
What carries the argument
Latent distribution matching, the combined objective of maximizing log-probability under an assumed latent model for alignment and maximizing entropy for uniformity.
If this is right
- Contrastive, non-contrastive, and predictive SSL methods all arise as instances of the same alignment-plus-uniformity objective.
- Predictive SSL recovers unique identifiable latent variables even when predictors are nonlinear.
- A sampling-free Bayesian filter with Kalman predictor can be obtained for high-dimensional time series.
- New SSL methods can be constructed by selecting different latent models and optimizing the matching objective.
Where Pith is reading between the lines
- The framework may help choose latent models that better fit the statistics of specific datasets or domains.
- Identifiability results could improve the use of self-supervised representations for causal or scientific tasks.
- Standard SSL losses could be tested to see whether they implicitly perform distribution matching under particular priors.
- The approach might extend to graphs or text by defining appropriate latent models for those data types.
Load-bearing premise
That a suitable assumed latent model exists whose log-probability can be maximized by the learned representations.
What would settle it
An experiment in which a standard SSL method succeeds on a benchmark but fails to increase the log-probability of representations under the latent model the paper links to that method.
Figures



read the original abstract
Self-supervised learning (SSL) excels at finding general-purpose latent representations from complex data, yet lacks a unifying theoretical framework that explains the diverse existing methods and guides the design of new ones. We cast SSL as latent distribution matching (LDM): learning representations that maximize their log-probability under an assumed latent model (alignment), while maximizing latent entropy to prevent collapse (uniformity). This view unifies independent component analysis with contrastive, non-contrastive, and predictive SSL methods, including stop gradient approaches. Leveraging LDM, we derive a nonlinear, sampling-free Bayesian filtering model with a Kalman-based predictor for high-dimensional timeseries. We further prove that predictive LDM yields identifiable latent representations under mild assumptions, even with nonlinear predictors. Overall, LDM clarifies the assumptions behind established SSL methods and provides principled guidance for developing new approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript casts self-supervised learning (SSL) as latent distribution matching (LDM): representations are learned by maximizing their log-probability under an assumed latent model (alignment term) while maximizing latent entropy to prevent collapse (uniformity term). This perspective is used to unify independent component analysis with contrastive, non-contrastive, and predictive SSL methods (including stop-gradient variants). The authors derive a nonlinear, sampling-free Bayesian filtering model with a Kalman-based predictor for high-dimensional time series and prove that predictive LDM produces identifiable latent representations under mild assumptions, even when the predictor is nonlinear.
Significance. If the unification and identifiability result hold, the work supplies a coherent theoretical account that explains why diverse SSL objectives succeed and offers guidance for new designs. The identifiability theorem for nonlinear predictors is a potentially high-impact contribution, as it directly addresses representation collapse and identifiability concerns that have limited prior theoretical analyses of SSL.
major comments (2)
- [§4] §4 (Identifiability theorem): The proof that predictive LDM yields identifiable latents with nonlinear predictors relies on a list of 'mild assumptions' whose precise statements (e.g., conditions on latent independence, density support, or invertibility of the predictor) are not enumerated in a form that permits direct verification against the implicit distributions induced by standard contrastive or stop-gradient objectives. Without this explicit list, it is impossible to confirm that the alignment and uniformity terms remain compatible with the theorem's hypotheses in high-dimensional regimes.
- [§3.2] §3.2 (Derivation of the Kalman-based predictor): The claim that the derived nonlinear Bayesian filtering model is sampling-free and directly instantiates LDM is load-bearing for the practical contribution, yet the manuscript does not show that the resulting objective reduces to the alignment-plus-uniformity form without additional post-hoc choices of the latent model density.
minor comments (2)
- Notation for the assumed latent density p(z) is introduced without an explicit statement of whether it is fixed a priori or learned jointly; this ambiguity appears in multiple places and should be clarified in a single definition box.
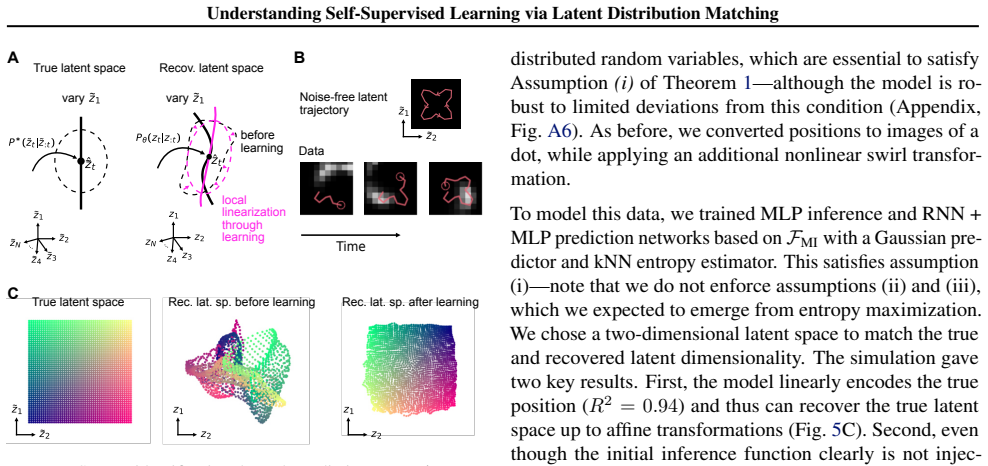
- Figure 2 (unification diagram) uses arrows whose direction and meaning are not defined in the caption or surrounding text, making it difficult to trace how each SSL family maps onto the LDM terms.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Identifiability theorem): The proof that predictive LDM yields identifiable latents with nonlinear predictors relies on a list of 'mild assumptions' whose precise statements (e.g., conditions on latent independence, density support, or invertibility of the predictor) are not enumerated in a form that permits direct verification against the implicit distributions induced by standard contrastive or stop-gradient objectives. Without this explicit list, it is impossible to confirm that the alignment and uniformity terms remain compatible with the theorem's hypotheses in high-dimensional regimes.
Authors: We agree that an explicit enumeration of the assumptions would improve verifiability. In the revised manuscript we will add a dedicated paragraph immediately following the theorem statement that lists all mild assumptions in precise mathematical form, covering latent independence, density support conditions, and predictor invertibility requirements. We will also include a short discussion relating these assumptions to the implicit distributions arising from contrastive, non-contrastive, and stop-gradient objectives, showing that the alignment and uniformity terms satisfy the hypotheses even in high dimensions. revision: yes
-
Referee: [§3.2] §3.2 (Derivation of the Kalman-based predictor): The claim that the derived nonlinear Bayesian filtering model is sampling-free and directly instantiates LDM is load-bearing for the practical contribution, yet the manuscript does not show that the resulting objective reduces to the alignment-plus-uniformity form without additional post-hoc choices of the latent model density.
Authors: We thank the referee for this observation. The derivation begins from the LDM objective and selects a latent model density (corresponding to the Kalman structure) that is motivated directly by the uniformity term; the resulting predictor is therefore sampling-free by construction. In the revision we will expand §3.2 with an explicit step-by-step reduction that derives the alignment-plus-uniformity objective from the Bayesian filtering equations without any additional post-hoc density choices, and we will move the full algebraic details to an appendix for clarity. revision: yes
Circularity Check
No significant circularity in LDM casting or identifiability proof
full rationale
The paper introduces latent distribution matching as a new theoretical casting of SSL that reinterprets alignment as maximizing log-probability under an assumed latent model and uniformity as maximizing entropy. It claims unification with ICA and various SSL methods plus a new nonlinear Bayesian filtering derivation and an identifiability result under mild assumptions. No quoted equations or self-citations reduce any central prediction or proof to a fitted input, self-defined quantity, or prior author result by construction. The framework is presented as self-contained reinterpretation and extension rather than tautological renaming or load-bearing self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Lin, P.-E
Ahmad, I. and Lin, P.-E. A nonparametric estimation of the entropy for absolutely continuous distributions (corresp.). IEEE Transactions on Information Theory, 22(3):372– 375, 1976
1976
-
[1]
Alshammari, S., Hershey, J., Feldmann, A., Freeman, W
ISSN 2835-8856. Alshammari, S., Hershey, J., Feldmann, A., Freeman, W. T., and Hamilton, M. I-con: A unifying framework for rep- resentation learning.arXiv preprint arXiv:2504.16929,
-
[2]
and Ganev, S
Aitchison, L. and Ganev, S. K. InfoNCE is variational infer- ence in a recognition parameterised model.Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review arXiv
-
[3]
Lejepa: Provable and scalable self-supervised learning without the heuristics, 2025
Balestriero, R. and LeCun, Y . Lejepa: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544,
-
[4]
The hidden uniform cluster prior in self-supervised learning
Assran, M., Balestriero, R., Duval, Q., Bordes, F., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., and Ballas, N. The hidden uniform cluster prior in self-supervised learning. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[4]
Gaus- sian embeddings: How jepas secretly learn your data density.arXiv preprint arXiv:2510.05949,
Balestriero, R., Ballas, N., Rabbat, M., and LeCun, Y . Gaus- sian embeddings: How jepas secretly learn your data density.arXiv preprint arXiv:2510.05949,
-
[5]
Bardes, A., Ponce, J., and LeCun, Y . Vicreg: Variance- invariance-covariance regularization for self-supervised learning.arXiv preprint arXiv:2105.04906,
-
[6]
Revisiting Feature Prediction for Learning Visual Representations from Video
Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y ., Assran, M., and Ballas, N. Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471,
work page internal anchor Pith review arXiv
- [7]
-
[8]
and Agakov, F
Barber, D. and Agakov, F. The im algorithm: a variational approach to information maximization.Advances in neu- ral information processing systems, 16(320):201, 2004
2004
-
[8]
and LeCun, Y
Dawid, A. and LeCun, Y . Introduction to latent variable energy-based models: a path toward autonomous machine intelligence.Journal of Statistical Mechanics: Theory and Experiment, 2024(10):104011,
2024
-
[9]
Halvagal, M. S. and Zenke, F. The combination of hebbian and predictive plasticity learns invariant object represen- tations in deep sensory networks.Nature neuroscience, 26(11):1906–1915,
1906
-
[10]
Hromadka, S., Biegun, K., Fox, L., Heald, J., and Sahani, M. Maximum likelihood learning of latent dynamics without reconstruction.arXiv preprint arXiv:2505.23569,
-
[11]
Reverse engineering self-supervised learning
LeCun, Y . Reverse engineering self-supervised learning. Advances in Neural Information Processing Systems, 36: 58324–58345, 2023
2023
-
[11]
Distribu- tion matching for self-supervised transfer learning.arXiv preprint arXiv:2502.14424,
Jiao, Y ., Ma, W., Sun, D., Wang, H., and Wang, Y . Distribu- tion matching for self-supervised transfer learning.arXiv preprint arXiv:2502.14424,
-
[12]
A probabilistic model behind self- supervised learning.Transactions on Machine Learning Research, 2024
Bizeul, A., Sch ¨olkopf, B., and Allen, C. A probabilistic model behind self- supervised learning.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. 9 Understanding Self-Supervised Learning via Latent Distribution Matching
2024
-
[12]
G., Halvagal, M
Mohammadi, A. G., Halvagal, M. S., and Zenke, F. Under- standing cortical computation through the lens of joint- embedding predictive architectures.bioRxiv, pp. 2025– 11,
2025
-
[13]
and Cranmer, K
Brehmer, J. and Cranmer, K. Flows for simultaneous mani- fold learning and density estimation.Advances in neural information processing systems, 33:442–453, 2020
2020
-
[13]
and Favaro, P
Noroozi, M. and Favaro, P. Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles. In Leibe, B., Matas, J., Sebe, N., and Welling, M. (eds.), Computer Vision – ECCV 2016, Lecture Notes in Com- puter Science, pp. 69–84, Cham,
2016
-
[14]
Infomax and maximum likelihood for blind source separation.IEEE Signal processing letters, 4(4): 112–114, 2002
Cardoso, J.-F. Infomax and maximum likelihood for blind source separation.IEEE Signal processing letters, 4(4): 112–114, 2002
2002
-
[14]
Springer Inter- national Publishing. ISBN 978-3-319-46466-4. doi: 10.1007/978-3-319-46466-4
-
[15]
A simple framework for contrastive learning of visual rep- resentations
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. A simple framework for contrastive learning of visual rep- resentations. InInternational conference on machine learning, pp. 1597–1607. PmLR, 2020
2020
-
[15]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review arXiv
-
[16]
and He, K
Chen, X. and He, K. Exploring simple siamese represen- tation learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pp. 15750–15758, 2021
2021
-
[16]
E., Balestriero, R., Brendel, W., and Klindt, D
Reizinger, P., Bizeul, A., Juhos, A., V ogt, J. E., Balestriero, R., Brendel, W., and Klindt, D. Cross-entropy is all you need to invert the data generating process.arXiv preprint arXiv:2410.21869,
-
[17]
Your contrastive learning problem is secretly a distribution alignment problem.Advances in Neural Information Processing Systems, 37:91597–91617, 2024
Chen, Z., Lin, C.-H., Liu, R., Xiao, J., and Dyer, E. Your contrastive learning problem is secretly a distribution alignment problem.Advances in Neural Information Processing Systems, 37:91597–91617, 2024
2024
-
[17]
Reizinger, P., Balestriero, R., Klindt, D., and Brendel, W. Position: An empirically grounded identifiability theory will accelerate self-supervised learning research.arXiv preprint arXiv:2504.13101,
-
[18]
Blind source separation and independent component analysis: A review.Neural Information Processing-Letters and Reviews, 6(1):1–57, 2005
Choi, S., Cichocki, A., Park, H.-M., and Lee, S.-Y . Blind source separation and independent component analysis: A review.Neural Information Processing-Letters and Reviews, 6(1):1–57, 2005. da Costa, V . G. T., Fini, E., Nabi, M., Sebe, N., and Ricci, E. solo-learn: A library of self-supervised methods for visual representation learning.Journal of Machine...
2005
-
[18]
Lifting archi- tectural constraints of injective flows.arXiv preprint arXiv:2306.01843,
Sorrenson, P., Draxler, F., Rousselot, A., Hummerich, S., Zimmermann, L., and K ¨othe, U. Lifting archi- tectural constraints of injective flows.arXiv preprint arXiv:2306.01843,
-
[19]
13 A.2 Related frameworks
12 Understanding Self-Supervised Learning via Latent Distribution Matching Appendix Contents A Mathematical appendix 13 A.1 Notation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 A.2 Related frameworks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13...
2021
-
[20]
and LeCun, Y
Dawid, A. and LeCun, Y . Introduction to latent variable energy-based models: a path toward autonomous machine intelligence.Journal of Statistical Mechanics: Theory and Experiment, 2024(10):104011, 2024. G´alvez, B. R., Blaas, A., Rodr´ıguez, P., Golinski, A., Suau, X., Ramapuram, J., Busbridge, D., and Zappella, L. The role of entropy and reconstruction ...
2024
-
[20]
Here, models often compute the data- likelihood in latent, instead of data space, by applying the change of variables formula
or normalizing flow networks (Papamakarios et al., 2021). Here, models often compute the data- likelihood in latent, instead of data space, by applying the change of variables formula. Specifically, if the transformation g from latent variableszto dataxis invertible L(θ, g) =⟨logP θ(x)⟩Pdata(x) = logP θ(g−1(x)) + log|J g−1(x)| Pdata(x) , (23) where Pθ is ...
2021
-
[21]
Geiger, B. C. and Kubin, G. On the information loss in memoryless systems: the multivariate case. In22th In- ternational Zurich Seminar on Communications (IZS). Eidgen¨ossische Technische Hochschule Z¨urich, 2012
2012
-
[21]
(26) In summary, for an invertible data generation process, maximum likelihood learning is equivalent toLDM in latent space
L(θ, f)∝ logP θ(f(x)) + 1 2 log|J f(x)Jf(x)T | Pdata(x) +H Pdata[x] =⟨logP θ(f(x))⟩ Pdata(x) +H Pdata[f(x)] =−D KL[Pdata(f(x))∥P θ(f(x))]. (26) In summary, for an invertible data generation process, maximum likelihood learning is equivalent toLDM in latent space. This also means that, in principle, we can estimate the log-likelihood of a datapoint based o...
2025
-
[22]
Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
2020
-
[22]
Thus, the objective function naturally penalizes topological defects and encourages the encoder to effectively ’unfold’ the data manifold into the latent space
HP [f(x)] =H P [x] + 1 2 log|J f(x)Jf(x)T | P(x) −H P [x|f(x)] (29) This equation holds for piecewise invertible f, i.e., most non-degenerate neural networks—see also the derivation in Section A.7.2. Thus, the objective function naturally penalizes topological defects and encourages the encoder to effectively ’unfold’ the data manifold into the latent spa...
2023
-
[23]
Grosmark, A. D. and Buzs´aki, G. Diversity in neural firing dynamics supports both rigid and learned hippocampal sequences.Science, 351(6280):1440–1443, 2016
2016
-
[23]
In the last step we usedP θ(z, z′) =P θ(z′|z)Pθ(z)
and deterministic encoders, the average likelihood becomes ⟨logP θ(z, z′)⟩R(z,z ′) = Z (logP θ(z, z′)⟨R(z|x)R(z ′|x′)⟩Pdata(x,x′) dz dz′ = Z (logP θ(z, z′))R(z|x)R(z ′|x′)dz dz ′ Pdata(x,x′) =⟨logP θ(f(x), f(x ′))⟩Pdata(x,x′) =⟨logP θ(f(x ′)|f(x)) + logP θ(f(x))⟩ Pdata(x,x′) , (38) where in the third step we usedR(z|x) =δ(z−f(x)). In the last step we used...
2020
-
[24]
A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9052– 9071, 2024
Tao, D. A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9052– 9071, 2024
2024
-
[24]
as approximately maximizing entropy. These models have the general loss function F= X t ⟨logP θ(SG[zt]|z:t)⟩R(zt,z:t) , (49) where commonly, but not necessarily,Pθ is a Normal distribution with either fixed or variable variance. To recall, in the proposed framework of LDM, the goal for a temporal model is the same as before, with the general loss function...
2020
-
[25]
Halvagal, M. S. and Zenke, F. The combination of hebbian and predictive plasticity learns invariant object represen- tations in deep sensory networks.Nature neuroscience, 26(11):1906–1915, 2023
1906
-
[25]
Here an empirical prior on latent variables is assumed, similar to the model in Aitchison & Ganev (2024)
we make the choices Pθ(z) =R(z), Pθ(z′|z) = 1 Z exp(τ p(z)T z′), (53) where p(·) is the predictor, and latent variables are normalized to lie on the sphere. Here an empirical prior on latent variables is assumed, similar to the model in Aitchison & Ganev (2024). Future work might explore models with a proper prior to reduce the need for additional model r...
2024
-
[26]
S., Laborieux, A., and Zenke, F
Halvagal, M. S., Laborieux, A., and Zenke, F. Implicit variance regularization in non-contrastive ssl.Advances in Neural Information Processing Systems, 36:63409– 63436, 2023
2023
-
[26]
The result is closely related to the Mazur-Ulam Theorem, which states that any surjective isometry (measure preserving map) between normed spaces is affine (Mazur & Ulam, 1932)
and hence ignore the first term, since recovery arises only from the conditional distributions. The result is closely related to the Mazur-Ulam Theorem, which states that any surjective isometry (measure preserving map) between normed spaces is affine (Mazur & Ulam, 1932). Importantly, linearity results entirely from the noise structure of the Gaussian, w...
1932
-
[27]
with latent variables on the sphere. Theorem 2 (restated).(Affine identifiability of vMF predictive model)Under the assumptions (i)–(iii) of Theorem 1, and a von Mises-Fisher latent predictive distribution P(z t|z:t) = 1 ZP exp(βP zT t p(z:t)) and a matching model, the transforming functionhbetween latent variables is affine. Proof.The proof remains the s...
2012
-
[28]
Nonlinear ica us- ing auxiliary variables and generalized contrastive learn- ing
Hyvarinen, A., Sasaki, H., and Turner, R. Nonlinear ica us- ing auxiliary variables and generalized contrastive learn- ing. InThe 22nd international conference on artificial intelligence and statistics, pp. 859–868. PMLR, 2019. Hyv¨arinen, A., Khemakhem, I., and Morioka, H. Nonlinear independent component analysis for principled disentan- glement in unsup...
2019
-
[28]
(2023), i.e., model inputs were spike-counts of 120 neurons in 25 ms bins
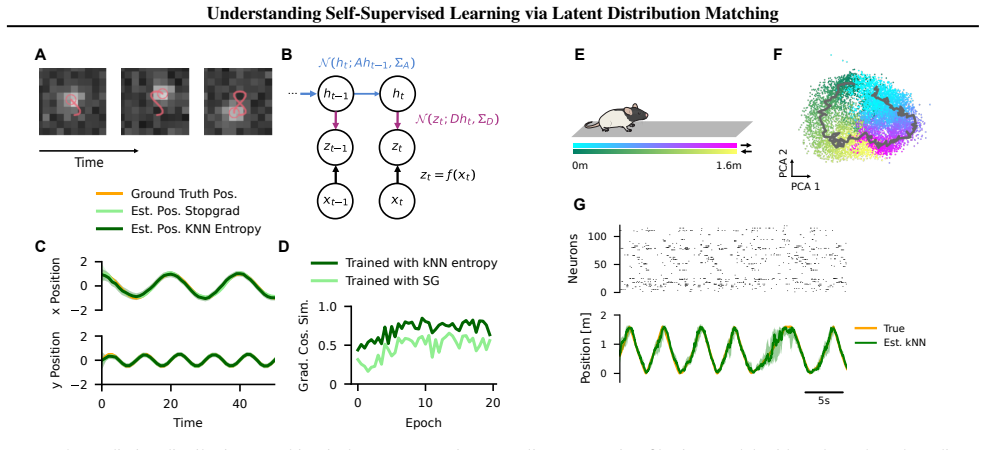
based on the pre-processing as described in Schneider et al. (2023), i.e., model inputs were spike-counts of 120 neurons in 25 ms bins. For one epoch we sampled 100000 windows of length ∼10 s from the full spike-train (about 45 min), training for 16 epochs. For the Kalman filter we chose an 8D observation and 16D latent space. For the encoders we used the...
2023
-
[29]
A7) we used the same setup, training on 100000 samples for 20 epochs
For the second experiment (Fig. A7) we used the same setup, training on 100000 samples for 20 epochs. Probabilistic representations in categorical SSL.We used ResNet-18 as encoder, with an additional soft-max output layer, training for 30 epochs. 27 Understanding Self-Supervised Learning via Latent Distribution Matching C. Supplementary figures and tables...
2022
-
[30]
Kirchhof, M., Kasneci, E., and Oh, S. J. Probabilistic con- trastive learning recovers the correct aleatoric uncertainty of ambiguous inputs. InInternational Conference on Machine Learning, pp. 17085–17104. PMLR, 2023
2023
-
[30]
or SICReg (Balestriero & LeCun, 2025), could also be a problem in practice, even when exact identification is not required, since it can lead to a mismatch between empirical and model conditional distributions (e.g., the model makes Gaussian-distributed predictions, while the empirical conditional latent distribution has a different shape). For KDE entrop...
2025
-
[31]
Sample estimate of the entropy of a random vector.Probl
Kozachenko, L. Sample estimate of the entropy of a random vector.Probl. Pered. Inform., 23:9, 1987. 10 Understanding Self-Supervised Learning via Latent Distribution Matching
1987
-
[32]
and Parks, H.Geometric integration theory
Krantz, S. and Parks, H.Geometric integration theory. Springer, 2008
2008
-
[33]
Krantz, S. G. and Parks, H. R.The implicit function theorem: history, theory, and applications. Springer Science & Business Media, 2002
2002
-
[34]
G., Schmidt, T., and Schneider, S
Laiz, R. G., Schmidt, T., and Schneider, S. Self-supervised contrastive learning performs non-linear system identifi- cation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[35]
and Pant, S
Lombardi, D. and Pant, S. Nonparametric k-nearest- neighbor entropy estimator.Physical Review E, 93(1): 013310, 2016
2016
-
[36]
On the principles of par- simony and self-consistency for the emergence of intelli- gence.Frontiers of Information Technology & Electronic Engineering, 23(9):1298–1323, 2022
Ma, Y ., Tsao, D., and Shum, H.-Y . On the principles of par- simony and self-consistency for the emergence of intelli- gence.Frontiers of Information Technology & Electronic Engineering, 23(9):1298–1323, 2022
2022
-
[37]
Maaten, L. v. d. and Hinton, G. Visualizing data using t-sne.Journal of machine learning research, 9(Nov): 2579–2605, 2008
2008
-
[38]
and Ulam, S
Mazur, S. and Ulam, S. Sur les transformations isom´etriques d’espaces vectoriels norm´es.CR Acad. Sci. Paris, 194 (946-948):116, 1932
1932
-
[39]
G., Halvagal, M
Mohammadi, A. G., Halvagal, M. S., and Zenke, F. Under- standing cortical computation through the lens of joint- embedding predictive architectures.bioRxiv, pp. 2025– 11, 2025
2025
-
[40]
Representa- tion uncertainty in self-supervised learning as variational inference
Nakamura, H., Okada, M., and Taniguchi, T. Representa- tion uncertainty in self-supervised learning as variational inference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 16484–16493, 2023
2023
-
[43]
Estimation of entropy and mutual information
Paninski, L. Estimation of entropy and mutual information. Neural computation, 15(6):1191–1253, 2003
2003
-
[44]
J., Mohamed, S., and Lakshminarayanan, B
Papamakarios, G., Nalisnick, E., Rezende, D. J., Mohamed, S., and Lakshminarayanan, B. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
2021
-
[45]
On variational bounds of mutual informa- tion
Tucker, G. On variational bounds of mutual informa- tion. InInternational conference on machine learning, pp. 5171–5180. PMLR, 2019
2019
-
[46]
The intrinsic dimension of images and its impact on learning
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., and Gold- stein, T. The intrinsic dimension of images and its impact on learning. InInternational Conference on Learning Representations, 2021
2021
-
[49]
On linear identifia- bility of learned representations
Roeder, G., Metz, L., and Kingma, D. On linear identifia- bility of learned representations. InInternational Con- ference on Machine Learning, pp. 9030–9039. PMLR, 2021
2021
-
[50]
Positivity of entropy production in nonequilib- rium statistical mechanics.Journal of Statistical Physics, 85(1):1–23, 1996
Ruelle, D. Positivity of entropy production in nonequilib- rium statistical mechanics.Journal of Statistical Physics, 85(1):1–23, 1996
1996
-
[51]
A theoretical analysis of contrastive unsupervised representation learning
Khandeparkar, H. A theoretical analysis of contrastive unsupervised representation learning. InInternational conference on machine learning, pp. 5628–5637. PMLR, 2019
2019
-
[52]
H., and Mathis, M
Schneider, S., Lee, J. H., and Mathis, M. W. Learnable latent embeddings for joint behavioural and neural analysis. Nature, 617(7960):360–368, 2023. Shwartz Ziv, R. and LeCun, Y . To compress or not to compress—self-supervised learning and information the- ory: A review.Entropy, 26(3):252, 2024
2023
-
[53]
G., and LeCun, Y
Shwartz-Ziv, R., Balestriero, R., Kawaguchi, K., Rudner, T. G., and LeCun, Y . An information theory perspective on variance-invariance-covariance regularization.Ad- vances in Neural Information Processing Systems, 36: 33965–33998, 2023
2023
-
[55]
An extension of slow feature analysis for nonlinear blind source separation.The Journal of Machine Learning Research, 15(1):921–947, 2014
Sprekeler, H., Zito, T., and Wiskott, L. An extension of slow feature analysis for nonlinear blind source separation.The Journal of Machine Learning Research, 15(1):921–947, 2014. 11 Understanding Self-Supervised Learning via Latent Distribution Matching
2014
-
[56]
Contrastive multiview coding
Tian, Y ., Krishnan, D., and Isola, P. Contrastive multiview coding. InEuropean conference on computer vision, pp. 776–794. Springer, 2020
2020
-
[57]
Understanding self- supervised learning dynamics without contrastive pairs
Tian, Y ., Chen, X., and Ganguli, S. Understanding self- supervised learning dynamics without contrastive pairs. InInternational Conference on Machine Learning, pp. 10268–10278. PMLR, 2021
2021
-
[58]
K., Gelly, S., and Lucic, M
Tschannen, M., Djolonga, J., Rubenstein, P. K., Gelly, S., and Lucic, M. On mutual information maximization for representation learning. InInternational Conference on Learning Representations, 2020. V on K¨ugelgen, J., Sharma, Y ., Gresele, L., Brendel, W., Sch¨olkopf, B., Besserve, M., and Locatello, F. Self- supervised learning with data augmentations p...
2020
-
[59]
I., Soulat, H., Yu, C., and Sahani, M
Walker, W. I., Soulat, H., Yu, C., and Sahani, M. Un- supervised representation learning with recognition- parametrised probabilistic models. InInternational Con- ference on Artificial Intelligence and Statistics, pp. 4209– 4230. PMLR, 2023
2023
-
[60]
and Isola, P
Wang, T. and Isola, P. Understanding contrastive represen- tation learning through alignment and uniformity on the hypersphere. InInternational conference on machine learning, pp. 9929–9939. PMLR, 2020
2020
-
[61]
and Liu, D
Zhouyin, Z. and Liu, D. Understanding neural networks with logarithm determinant entropy estimator.Neurocom- puting, pp. 131520, 2025
2025
-
[62]
S., Sharma, Y ., Schneider, S., Bethge, M., and Brendel, W
Zimmermann, R. S., Sharma, Y ., Schneider, S., Bethge, M., and Brendel, W. Contrastive learning inverts the data generating process. InInternational conference on machine learning, pp. 12979–12990. PMLR, 2021. 12 Understanding Self-Supervised Learning via Latent Distribution Matching Appendix Contents A Mathematical appendix 13 A.1 Notation . . . . . . . ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.