Recognition: unknown
Random test functions, H⁻¹ norm equivalence, and stochastic variational physics-informed neural networks
Pith reviewed 2026-05-07 14:49 UTC · model grok-4.3
The pith
The H^{-1} norm of any functional is equivalent to its expected squared evaluation against a random test function whose distribution depends only on the domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that the H^{-1} norm of any functional is equivalent to its expected squared evaluation against a random test function whose distribution depends only on the domain. Realisations of this random test function have negative Sobolev regularity for d greater than or equal to 2, yet this roughness does not prevent averaging over the distribution from exactly recovering the correct weak topology, independently of the differential operator. This equivalence introduces stochastically weak solutions, which coincide with classical weak solutions, and motivates stochastic variational physics-informed neural networks trained by minimising an empirical approximation of the stocha
What carries the argument
A domain-dependent probability distribution over test functions such that the expected value of the squared pairing with any functional recovers the H^{-1} norm and the associated weak topology.
Load-bearing premise
There exists a distribution over random test functions, depending only on the domain, for which the expected squared evaluation exactly equals the H^{-1} norm of the functional for any functional.
What would settle it
A concrete counterexample consisting of a domain, a specific functional, and its H^{-1} norm that does not match the computed expectation over samples from the proposed random test function distribution.
Figures

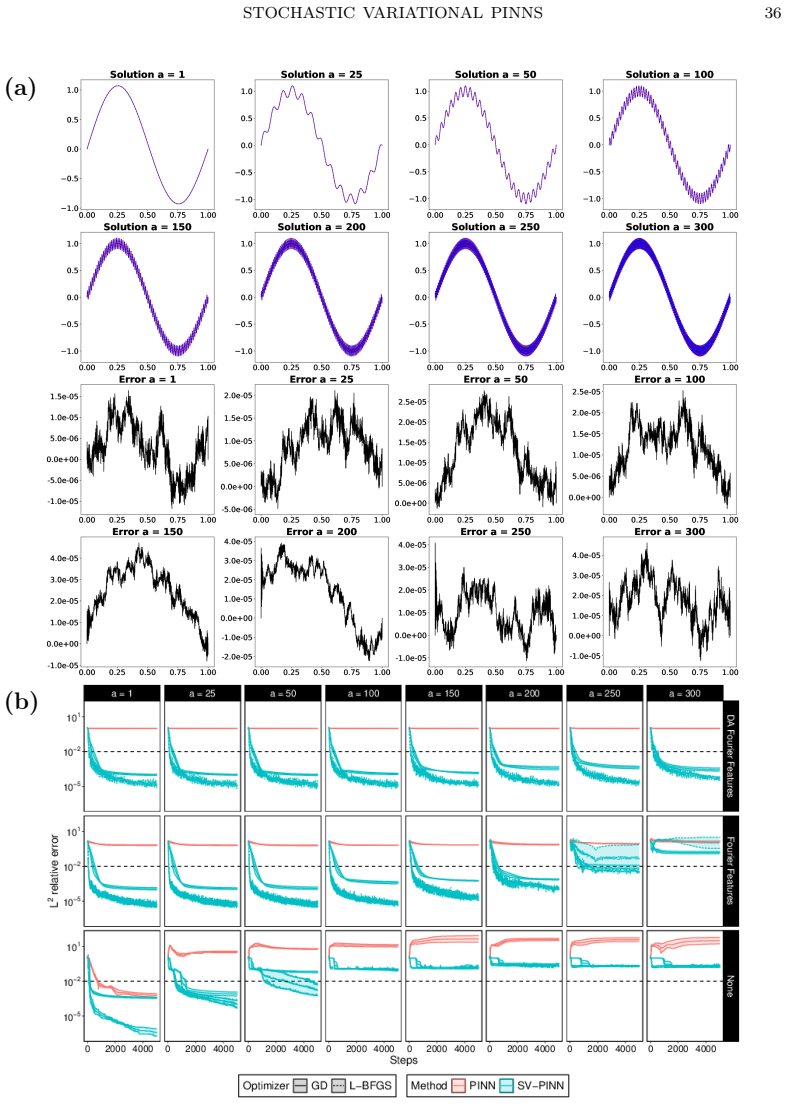
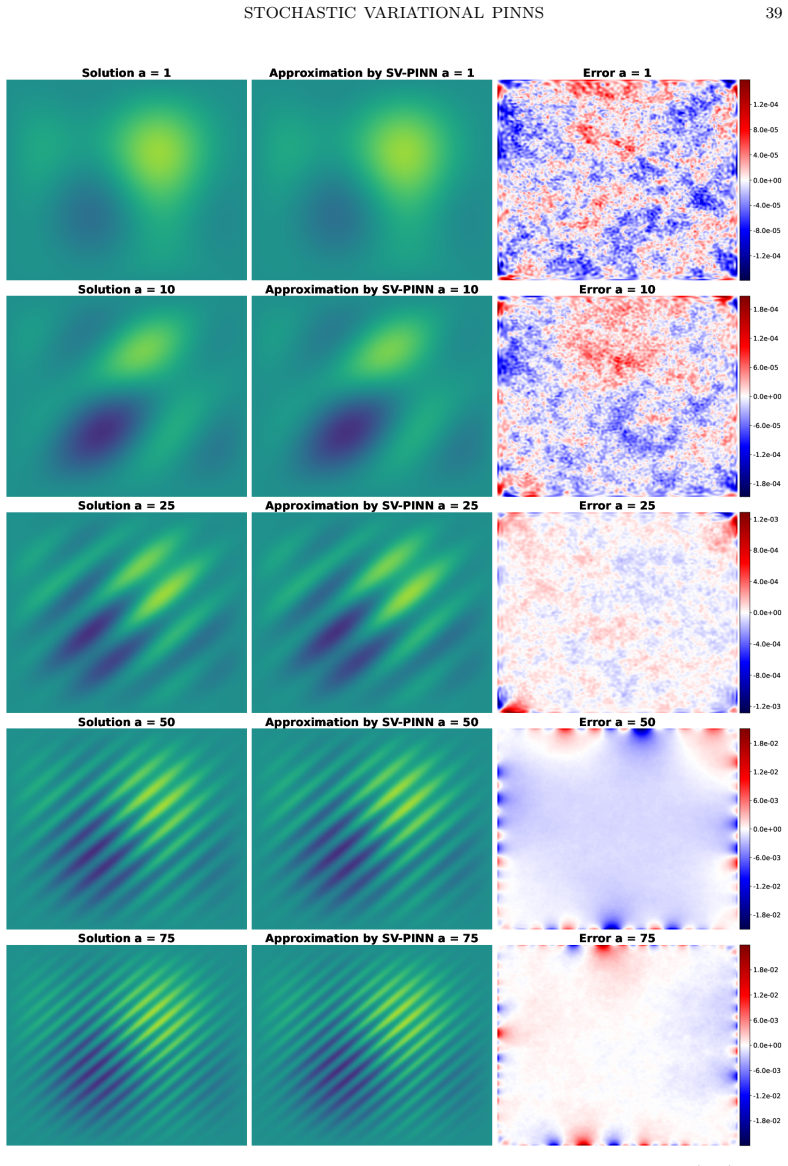


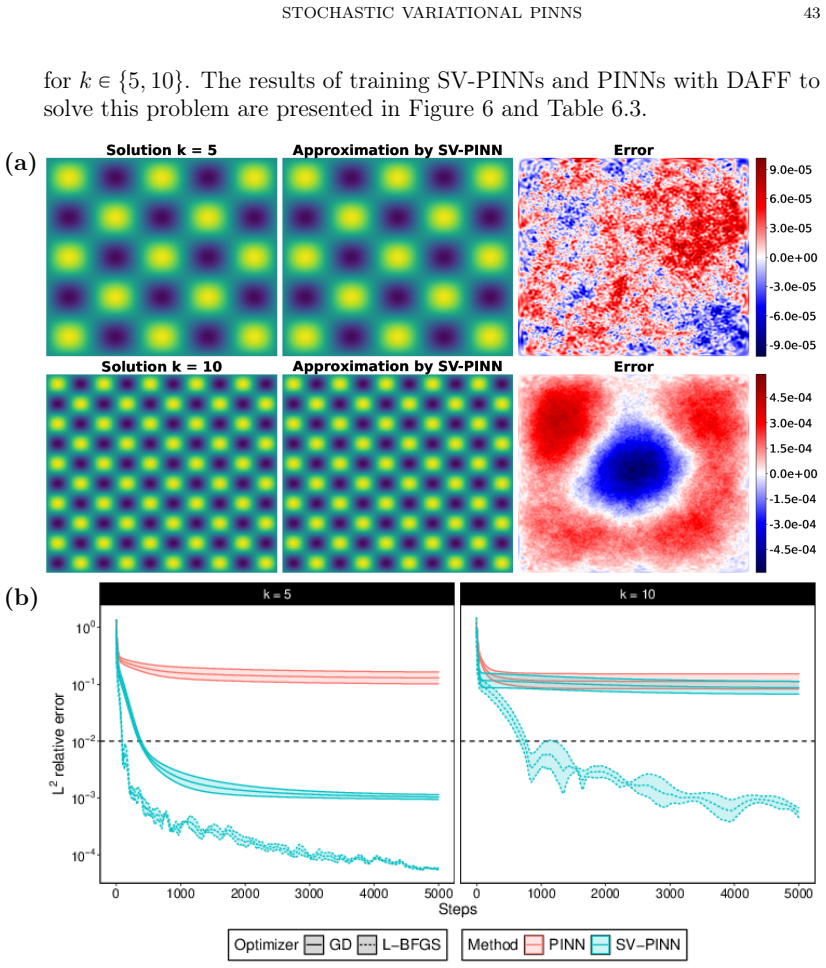

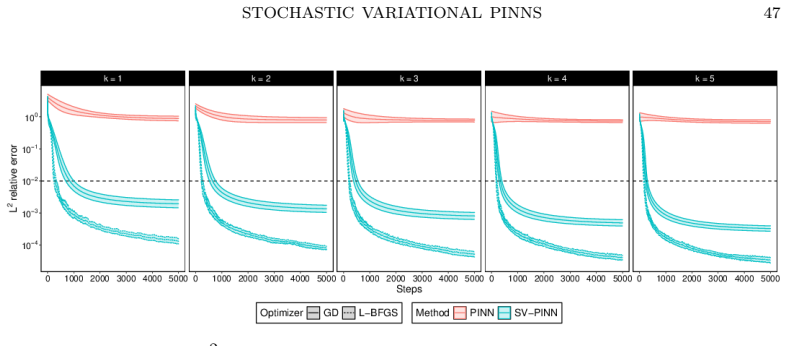





read the original abstract
The dual norm characterisation of weak solutions of second-order linear elliptic partial differential equations is mathematically natural but computationally intractable: evaluating the $H^{-1}$ norm of a residual requires a supremum over an infinite-dimensional function space. We prove that the $H^{-1}$ norm of any functional is equivalent to its expected squared evaluation against a random test function whose distribution depends only on the domain. Crucially, realisations of this random test function have negative Sobolev regularity for $d \geq 2$, yet this roughness is not an obstacle: averaging over the distribution exactly recovers the correct weak topology, independently of the differential operator. This equivalence introduces the notion of stochastically weak solutions, which coincide with classical weak solutions, and motivates stochastic variational physics-informed neural networks (SV-PINNs): neural networks trained by minimising an empirical approximation of the stochastic norm of the PDE residual. Although instantiated here with neural networks as trial spaces, the underlying principle is independent of the approximation architecture and suggests a broader paradigm for numerical methods based on stochastic rather than deterministic test spaces. The framework extends naturally to higher-order elliptic, parabolic and hyperbolic equations and to abstract operator equations on Hilbert spaces. As a proof of concept, we present numerical experiments on eight challenging second-order linear elliptic problems spanning high-frequency and multi-scale solutions, indefinite operators, variable coefficients, and non-standard domains, in which SV-PINNs consistently and significantly outperform standard PINNs, recovering solutions to within one percent relative error in hundreds of L-BFGS steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proves that the H^{-1} norm of any functional is equivalent to the square root of its expected squared pairing against a random test function whose law depends only on the domain. This equivalence is independent of the differential operator, yields stochastically weak solutions that coincide with classical weak solutions, and motivates SV-PINNs: neural networks trained by minimizing an empirical Monte-Carlo approximation to the stochastic residual norm. The framework is illustrated on eight second-order linear elliptic problems (high-frequency, multi-scale, indefinite, variable-coefficient, non-standard domains) where SV-PINNs recover solutions to within 1% relative error in a few hundred L-BFGS iterations and consistently outperform standard PINNs.
Significance. If the equivalence is rigorously established, the work supplies a computationally tractable, operator-independent surrogate for the dual norm that removes the need to solve auxiliary supremum problems. This is a genuine advance for variational PINNs and related mesh-free methods. The numerical evidence on a deliberately diverse test suite, together with the claim that negative Sobolev regularity of the random fields does not obstruct recovery of the H^{-1} topology, strengthens the practical case. The extension sketched to higher-order, parabolic, hyperbolic and abstract Hilbert-space problems further increases potential impact.
minor comments (2)
- [Abstract] Abstract: the statement that solutions are recovered “to within one percent relative error” should specify the norm (L^2, H^1, etc.) in which the error is measured and indicate whether the figure is an average or worst-case value over the eight test problems.
- [Numerical experiments] Implementation details for sampling the random test functions (discretization of the covariance operator, number of Monte-Carlo samples per loss evaluation, and handling of the negative-order regularity for d ≥ 2) are only sketched; a short algorithmic box or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive and encouraging report, which accurately summarizes the main theoretical result on the H^{-1} equivalence and its use in SV-PINNs, as well as the numerical experiments on diverse elliptic problems. We appreciate the assessment of significance and the recommendation for minor revision.
Circularity Check
No significant circularity
full rationale
The paper's central result is a functional-analytic existence proof: there exists a random test function distribution (depending only on the domain) such that the expected squared duality pairing recovers the H^{-1} norm exactly. This is achieved by taking the covariance operator of the random field to be the inverse Riesz map of the H^1_0 inner product, which is a standard, operator-independent construction on the domain. The equivalence therefore holds by the definition of covariance and the Riesz representation theorem, but this constitutes a valid mathematical demonstration rather than a self-referential loop or a fitted quantity renamed as a prediction. No load-bearing step in the derivation reduces to its own inputs by construction; the subsequent SV-PINN training procedure follows from the established equivalence without circularity. The argument is self-contained against external functional-analytic benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard properties of Sobolev spaces H^1 and its dual H^{-1} for second-order elliptic operators
- ad hoc to paper Existence of a random test-function distribution depending only on the domain such that expectation of squared evaluations recovers the H^{-1} norm independently of the operator
Reference graph
Works this paper leans on
-
[1]
Galerkin neural networks: A framework for ap- proximating variational equations with error control.SIAM Journal on Scientific Computing, 43(4):A2474–A2501, 2021
Mark Ainsworth and Justin Dong. Galerkin neural networks: A framework for ap- proximating variational equations with error control.SIAM Journal on Scientific Computing, 43(4):A2474–A2501, 2021
2021
-
[2]
A stochastic collocation method for elliptic partial differential equations with random input data.SIAM Journal on Nu- merical Analysis, 45(3):1005–1034, 2007
Ivo Babuška, Fabio Nobile, and Raúl Tempone. A stochastic collocation method for elliptic partial differential equations with random input data.SIAM Journal on Nu- merical Analysis, 45(3):1005–1034, 2007
2007
-
[3]
Rademacher and gaussian complexities: Risk bounds and structural results.Journal of machine learning research, 3(Nov):463–482, 2002
Peter L Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results.Journal of machine learning research, 3(Nov):463–482, 2002
2002
-
[4]
Automatic differentiation in machine learning: a survey.Journal of machine learning research, 18(153):1–43, 2018
Atilim Gunes Baydin, Barak A Pearlmutter, Alexey Andreyevich Radul, and Jef- frey Mark Siskind. Automatic differentiation in machine learning: a survey.Journal of machine learning research, 18(153):1–43, 2018
2018
-
[5]
Variational physics informed neural networks: the role of quadratures and test functions.Journal of Scientific Computing, 92(3):100, 2022
Stefano Berrone, Claudio Canuto, and Moreno Pintore. Variational physics informed neural networks: the role of quadratures and test functions.Journal of Scientific Computing, 92(3):100, 2022
2022
-
[6]
Efficient and modular implicit differentiation.arXiv preprint arXiv:2105.15183, 2021
Mathieu Blondel, Quentin Berthet, Marco Cuturi, Roy Frostig, Stephan Hoyer, Felipe Llinares-López, Fabian Pedregosa, and Jean-Philippe Vert. Efficient and modular implicit differentiation.arXiv preprint arXiv:2105.15183, 2021
-
[7]
Equivalence of measures and asymptotically op- timal linear prediction for gaussian random fields with fractional-order covariance operators.Bernoulli, 29(2):1476–1504, 2023
David Bolin and Kristin Kirchner. Equivalence of measures and asymptotically op- timal linear prediction for gaussian random fields with fractional-order covariance operators.Bernoulli, 29(2):1476–1504, 2023
2023
-
[8]
Oxford University Press, 02 2013
Stephane Boucheron, Gabor Lugosi, and Pascal Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 02 2013. STOCHASTIC V ARIATIONAL PINNS 66
2013
-
[9]
JAX: composable transformations of Python+NumPy pro- grams, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, DougalMaclaurin, GeorgeNecula, AdamPaszke, JakeVanderPlas, SkyeWanderman- Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy pro- grams, 2018
2018
-
[10]
Cambridge University Press, 2001
Dietrich Braess.Finite elements: Theory, fast solvers, and applications in solid me- chanics. Cambridge University Press, 2001
2001
-
[11]
Estimation of linear functionals on sobolev spaces with application to fourier transforms and spline interpolation.SIAM Journal on Numerical Analysis, 7(1):112–124, 1970
James H Bramble and Stephen Reginald Hilbert. Estimation of linear functionals on sobolev spaces with application to fourier transforms and spline interpolation.SIAM Journal on Numerical Analysis, 7(1):112–124, 1970
1970
-
[12]
Springer, 2011
Haim Brezis.Functional analysis, Sobolev spaces and partial differential equations. Springer, 2011
2011
-
[13]
Elsevier, 2010
Vladimir Britanak, Patrick C Yip, and Kamisetty Ramamohan Rao.Discrete cosine and sine transforms: general properties, fast algorithms and integer approximations. Elsevier, 2010
2010
-
[14]
Alberto Miño Calero, Luis Salamanca, and Konstantinos E Tatsis. Enhancing physics- informed neural networks with domain-aware fourier features: Towards improved performance and interpretable results.arXiv preprint arXiv:2603.02948, 2026
-
[15]
Solving and learning nonlinear pdes with gaussian processes.Journal of Computational Physics, 447:110668, 2021
Yifan Chen, Bamdad Hosseini, Houman Owhadi, and Andrew M Stuart. Solving and learning nonlinear pdes with gaussian processes.Journal of Computational Physics, 447:110668, 2021
2021
-
[16]
Bayesian probabilistic numerical methods.SIAM review, 61(4):756–789, 2019
Jon Cockayne, Chris J Oates, Timothy John Sullivan, and Mark Girolami. Bayesian probabilistic numerical methods.SIAM review, 61(4):756–789, 2019
2019
-
[17]
Interscience Publishers, 1953
Richard Courant and David Hilbert.Methods of mathematical physics, volume 1. Interscience Publishers, 1953
1953
-
[18]
Scientific machine learning through physics– informed neural networks: Where we are and what’s next.Journal of Scientific Com- puting, 92(3):88, 2022
Salvatore Cuomo, Vincenzo Schiano Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics– informed neural networks: Where we are and what’s next.Journal of Scientific Com- puting, 92(3):88, 2022
2022
-
[19]
The DeepMind JAX Ecosystem, 2020
DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, An- toine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Ke- maev, Michael King, Markus Kunesch, L...
2020
-
[20]
Discontinuous petrov–galerkin (dpg) method.Encyclopedia of Computational Mechanics, 2:777–792, 2017
Leszek Demkowicz and Jay Gopalakrishnan. Discontinuous petrov–galerkin (dpg) method.Encyclopedia of Computational Mechanics, 2:777–792, 2017. STOCHASTIC V ARIATIONAL PINNS 67
2017
-
[21]
Neural network approximation
Ronald DeVore, Boris Hanin, and Guergana Petrova. Neural network approximation. Acta Numerica, 30:327–444, 2021
2021
-
[22]
Hitchhiker’s guide to the fractional sobolev spaces.Bulletin des sciences mathématiques, 136(5):521–573, 2012
Eleonora Di Nezza, Giampiero Palatucci, and Enrico Valdinoci. Hitchhiker’s guide to the fractional sobolev spaces.Bulletin des sciences mathématiques, 136(5):521–573, 2012
2012
-
[23]
Cambridge university press, 2019
Rick Durrett.Probability: theory and examples, volume 49. Cambridge university press, 2019
2019
-
[24]
American mathematical society, 2022
Lawrence C Evans.Partial differential equations, volume 19. American mathematical society, 2022
2022
-
[25]
Han Gao, Matthew J Zahr, and Jian-Xun Wang. Physics-informed graph neural galerkin networks: A unified framework for solving pde-governed forward and inverse problems.Computer Methods in Applied Mechanics and Engineering, 390:114502, 2022
2022
-
[26]
Understanding the difficulty of training deep feed- forward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feed- forward neural networks. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010
2010
-
[27]
Springer, 2017
Wolfgang Hackbusch.Elliptic differential equations: theory and numerical treatment, volume 18. Springer, 2017
2017
-
[28]
An iterative deep ritz method for mono- tone elliptic problems.Journal of Computational Physics, 527:113791, 2025
Tianhao Hu, Bangti Jin, and Fengru Wang. An iterative deep ritz method for mono- tone elliptic problems.Journal of Computational Physics, 527:113791, 2025
2025
-
[29]
100 years of weyl’s law.Bulletin of Mathematical Sciences, 6(3):379–452, 2016
Victor Ivrii. 100 years of weyl’s law.Bulletin of Mathematical Sciences, 6(3):379–452, 2016
2016
-
[30]
Stochastic galerkin and collocation methods for quantifying uncertainty in differential equations: a review.The Proceed- ings of ANZIAM, 50:C815–C830, 2008
John Davis Jakeman and Stephen Gwyn Roberts. Stochastic galerkin and collocation methods for quantifying uncertainty in differential equations: a review.The Proceed- ings of ANZIAM, 50:C815–C830, 2008
2008
-
[31]
An improved method for computing a discrete hankel transform
H Fisk Johnson. An improved method for computing a discrete hankel transform. Computer physics communications, 43(2):181–202, 1987
1987
-
[32]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422– 440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422– 440, 2021
2021
-
[33]
Ehsan Kharazmi, Zhongqiang Zhang, and George Em Karniadakis. Variational physics-informed neural networks for solving partial differential equations.arXiv preprint arXiv:1912.00873, 2019
-
[34]
hp-vpinns: Varia- tional physics-informed neural networks with domain decomposition.Computer Meth- ods in Applied Mechanics and Engineering, 374:113547, 2021
Ehsan Kharazmi, Zhongqiang Zhang, and George Em Karniadakis. hp-vpinns: Varia- tional physics-informed neural networks with domain decomposition.Computer Meth- ods in Applied Mechanics and Engineering, 374:113547, 2021
2021
-
[35]
STOCHASTIC V ARIATIONAL PINNS 68
SeungilKim.Fractionalordersobolevspacesfortheneumannlaplacianandthevector laplacian.Journal of the Korean Mathematical Society, 57(3):721–745, 2020. STOCHASTIC V ARIATIONAL PINNS 68
2020
-
[36]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[37]
Smoothness estimation for whittle–matérn processes on closed riemannian manifolds.Stochastic Processes and their Applications, 189:104685, 2025
Moritz Korte-Stapff, Toni Karvonen, and Éric Moulines. Smoothness estimation for whittle–matérn processes on closed riemannian manifolds.Stochastic Processes and their Applications, 189:104685, 2025
2025
-
[38]
The spde approach for gaussian and non-gaussian fields: 10 years and still running.Spatial Statistics, 50:100599, 2022
Finn Lindgren, David Bolin, and Håvard Rue. The spde approach for gaussian and non-gaussian fields: 10 years and still running.Spatial Statistics, 50:100599, 2022
2022
-
[39]
Finn Lindgren, Håvard Rue, and Johan Lindström. An explicit link between gaussian fields and gaussian markov random fields: the stochastic partial differential equation approach.Journal of the Royal Statistical Society Series B: Statistical Methodology, 73(4):423–498, 2011
2011
-
[40]
Cambridge University Press, 2014
Gabriel J Lord, Catherine E Powell, and Tony Shardlow.An introduction to compu- tational stochastic PDEs, volume 50. Cambridge University Press, 2014
2014
-
[41]
Learning nonlinear operators via deeponet based on the universal approximation the- orem of operators.Nature machine intelligence, 3(3):218–229, 2021
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation the- orem of operators.Nature machine intelligence, 3(3):218–229, 2021
2021
-
[42]
Physics-informed neural networks for pde prob- lems: A comprehensive review.Artificial Intelligence Review, 58(10):323, 2025
Kuang Luo, Jingshang Zhao, Yingping Wang, Jiayao Li, Junjie Wen, Jiong Liang, Henry Soekmadji, and Shaolin Liao. Physics-informed neural networks for pde prob- lems: A comprehensive review.Artificial Intelligence Review, 58(10):323, 2025
2025
-
[43]
Randomized algorithms for matrices and data.Foundations and Trends®in Machine Learning, 3(2):123–224, 2011
Michael W Mahoney. Randomized algorithms for matrices and data.Foundations and Trends®in Machine Learning, 3(2):123–224, 2011
2011
-
[44]
Diego Marcondes. Complexity dependent error rates for physics-informed statistical learning via the small-ball method.arXiv preprint arXiv:2510.23149, 2025
-
[45]
Self-adaptive physics-informed neural networks.Journal of Computational Physics, 474:111722, 2023
Levi D McClenny and Ulisses M Braga-Neto. Self-adaptive physics-informed neural networks.Journal of Computational Physics, 474:111722, 2023
2023
-
[46]
Learning without concentration.Journal of the ACM (JACM), 62(3):1–25, 2015
Shahar Mendelson. Learning without concentration.Journal of the ACM (JACM), 62(3):1–25, 2015
2015
-
[47]
Updating quasi-newton matrices with limited storage.Mathematics of computation, 35(151):773–782, 1980
Jorge Nocedal. Updating quasi-newton matrices with limited storage.Mathematics of computation, 35(151):773–782, 1980
1980
-
[48]
A pde approach to fractional diffusion in general domains: a priori error analysis.Foundations of Com- putational Mathematics, 15(3):733–791, 2015
Ricardo H Nochetto, Enrique Otárola, and Abner J Salgado. A pde approach to fractional diffusion in general domains: a priori error analysis.Foundations of Com- putational Mathematics, 15(3):733–791, 2015
2015
-
[49]
Cambridge University Press, 2012
Ivan Nourdin and Giovanni Peccati.Normal approximations with Malliavin calculus: from Stein’s method to universality, volume 192. Cambridge University Press, 2012
2012
-
[50]
Springer, 2006
David Nualart.The Malliavin calculus and related topics. Springer, 2006
2006
-
[51]
Python Software Foundation, 2024
Python Core Team.Python: A dynamic, open source programming language. Python Software Foundation, 2024. Version 3.9.2. STOCHASTIC V ARIATIONAL PINNS 69
2024
-
[52]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
2019
-
[53]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. Advances in neural information processing systems, 20, 2007
2007
-
[54]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neu- ral networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
2019
-
[55]
Prentice-Hall, 1974
GilbertStrang, GeorgeJFix, andDSGriffin.An analysis of the finite-element method. Prentice-Hall, 1974
1974
-
[56]
A randomized kaczmarz algorithm with exponential convergence.Journal of Fourier Analysis and Applications, 15(2):262– 278, 2009
Thomas Strohmer and Roman Vershynin. A randomized kaczmarz algorithm with exponential convergence.Journal of Fourier Analysis and Applications, 15(2):262– 278, 2009
2009
-
[57]
Majorizing measures: the generic chaining.The Annals of Proba- bility, 24(3):1049–1103, 1996
Michel Talagrand. Majorizing measures: the generic chaining.The Annals of Proba- bility, 24(3):1049–1103, 1996
1996
-
[58]
Springer, 2005
Michel Talagrand.The generic chaining: upper and lower bounds of stochastic pro- cesses. Springer, 2005
2005
-
[59]
Springer Science & Business Media, 2007
Vidar Thomée.Galerkin finite element methods for parabolic problems, volume 25. Springer Science & Business Media, 2007
2007
-
[60]
From pinns to pikans: Recent advances in physics-informed machine learning.Machine Learning for Com- putational Science and Engineering, 1(1):15, 2025
Juan Diego Toscano, Vivek Oommen, Alan John Varghese, Zongren Zou, Nazanin Ah- madi Daryakenari, Chenxi Wu, and George Em Karniadakis. From pinns to pikans: Recent advances in physics-informed machine learning.Machine Learning for Com- putational Science and Engineering, 1(1):15, 2025
2025
-
[61]
An introduction to malliavin calculus.arXiv preprint arXiv:2502.07941, 2025
Luciano Tubaro and Margherita Zanella. An introduction to malliavin calculus.arXiv preprint arXiv:2502.07941, 2025
-
[62]
London School of Economics and Political Science (United Kingdom), 2008
Limin Wang.Karhunen-Loeve expansions and their applications. London School of Economics and Political Science (United Kingdom), 2008
2008
-
[63]
Piratenets: Physics- informed deep learning with residual adaptive networks.Journal of Machine Learning Research, 25(402):1–51, 2024
Sifan Wang, Bowen Li, Yuhan Chen, and Paris Perdikaris. Piratenets: Physics- informed deep learning with residual adaptive networks.Journal of Machine Learning Research, 25(402):1–51, 2024
2024
-
[64]
Respecting causality is all you need for training physics-informed neural networks
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality is all you need for training physics-informed neural networks.arXiv preprint arXiv:2203.07404, 2022
-
[65]
STOCHASTIC V ARIATIONAL PINNS 70
SifanWang, YujunTeng, andParisPerdikaris.Understandingandmitigatinggradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021. STOCHASTIC V ARIATIONAL PINNS 70
2021
-
[66]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics- informed neural networks.Computer Methods in Applied Mechanics and Engineering, 384:113938, 2021
2021
-
[67]
When and why pinns fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
2022
-
[68]
On stationary processes in the plane.Biometrika, pages 434–449, 1954
Peter Whittle. On stationary processes in the plane.Biometrika, pages 434–449, 1954
1954
-
[69]
Stochastic-processes in several dimensions.Bulletin of the Interna- tional Statistical Institute, 40(2):974–994, 1963
Peter Whittle. Stochastic-processes in several dimensions.Bulletin of the Interna- tional Statistical Institute, 40(2):974–994, 1963
1963
-
[70]
Sketching as a tool for numerical linear algebra.Foundations and Trends®in Theoretical Computer Science, 10(1-2):1–157, 2014
David P Woodruff. Sketching as a tool for numerical linear algebra.Foundations and Trends®in Theoretical Computer Science, 10(1-2):1–157, 2014
2014
-
[71]
Weak transnet: A petrov-galerkin based neural network method for solving elliptic pdes: Z
Zhihang Xu, Min Wang, and Zhu Wang. Weak transnet: A petrov-galerkin based neural network method for solving elliptic pdes: Z. xu, m. wang, z. wang.Journal of Scientific Computing, 107(2):60, 2026
2026
-
[72]
The deep ritz method: a deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics, 6(1):1– 12, 2018
Bing Yu et al. The deep ritz method: a deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics, 6(1):1– 12, 2018
2018
-
[73]
A natural deep ritz method for essential boundary value problems.Journal of Computational Physics, 537:114133, 2025
Haijun Yu and Shuo Zhang. A natural deep ritz method for essential boundary value problems.Journal of Computational Physics, 537:114133, 2025
2025
-
[74]
Weak adversarial networks for high-dimensional partial differential equations.Journal of Computational Physics, 411:109409, 2020
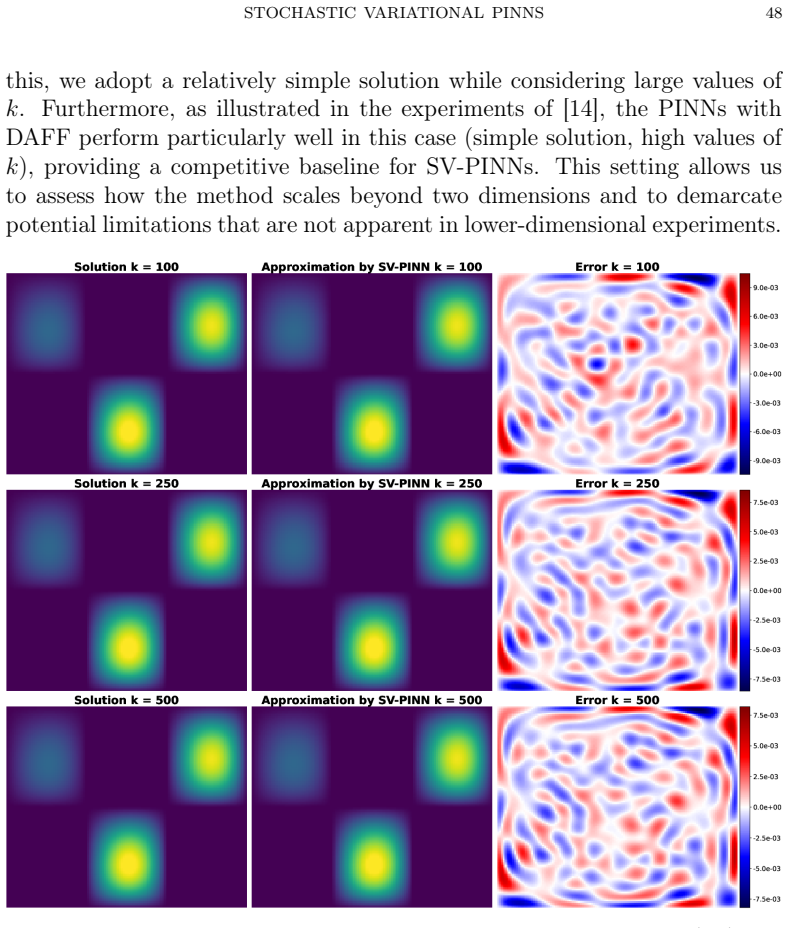
Yaohua Zang, Gang Bao, Xiaojing Ye, and Haomin Zhou. Weak adversarial networks for high-dimensional partial differential equations.Journal of Computational Physics, 411:109409, 2020. AppendixA.More details about the experiments Table A.8 present the details about the implementation of each experi- ment. T able A.8.Hyperparameters of the experiments in hyp...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.