Recognition: unknown
MILE: Mixture of Incremental LoRA Experts for Continual Semantic Segmentation across Domains and Modalities
Pith reviewed 2026-05-07 17:50 UTC · model grok-4.3
The pith
MILE adds lightweight LoRA experts per task and uses prototype-guided gating to handle continual semantic segmentation across domains and modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MILE instantiates a dedicated low-rank adapter expert for each new task, trains that expert exclusively on its task data while the base remains frozen, and routes inference inputs via a prototype-guided gate that selects the most suitable expert. The approach yields strong accuracy on domain-incremental and modality-incremental segmentation benchmarks together with improved stability, plasticity, and scalability compared with prior expert-based continual learners.
What carries the argument
Incremental LoRA experts combined with a prototype-guided gating network that selects the appropriate expert at inference time without task identity labels.
If this is right
- Parameter count grows only marginally with each added task, so dozens of experts fit inside the size of one full model.
- Each expert trains independently, eliminating interference with previously learned tasks.
- The same frozen base plus lightweight experts works for both domain shifts and modality shifts in segmentation.
- Training and storage costs remain low because only the small LoRA modules are updated and stored per task.
Where Pith is reading between the lines
- The method could extend to other dense prediction tasks such as depth estimation or instance segmentation if prototypes are defined for those outputs.
- Because experts are added incrementally, the framework supports open-ended streams of new domains without periodic full-model retraining.
- If the gate occasionally errs on edge cases, a lightweight fallback to a generic expert could be added without changing the core design.
Load-bearing premise
The prototype-guided gate can correctly identify which expert to use when the input comes from a domain or modality never seen during training.
What would settle it
Measure segmentation accuracy on a held-out domain or modality when the gate is forced to pick a mismatched expert; a large drop relative to an oracle gate would falsify the claim that the gating works reliably without task labels.
Figures


read the original abstract
Continual semantic segmentation requires models to adapt to new domains or modalities without sacrificing performance on previously learned tasks. Expert-based learning, in which task-specific modules specialize in different domains, has proven effective in mitigating forgetting. These methods include dynamic expansion, which suffers from scalability issues, or parameter isolation, which constrains the ability to learn new tasks. We introduce Mixture of Incremental LoRA Experts (MILE), a modular and parameter-efficient framework for continual segmentation across both domains and modalities. MILE leverages Low-Rank Adaptation (LoRA) to instantiate lightweight experts for each new task while keeping the pretrained base network frozen. Each expert is trained exclusively on its task data, thus avoids overwriting previously learned information. A prototype-guided gating mechanism dynamically selects the most appropriate expert at inference. MILE achieves the benefits of expert-based learning while overcoming its scalability limitations. It requires only a marginal parameter increase per task and tens of LoRA adapters are needed before matching the size of a single full model, making it highly efficient in both training and storage. Across domain- and modality-incremental benchmarks, MILE achieves strong performance while ensuring better stability, plasticity, and scalability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
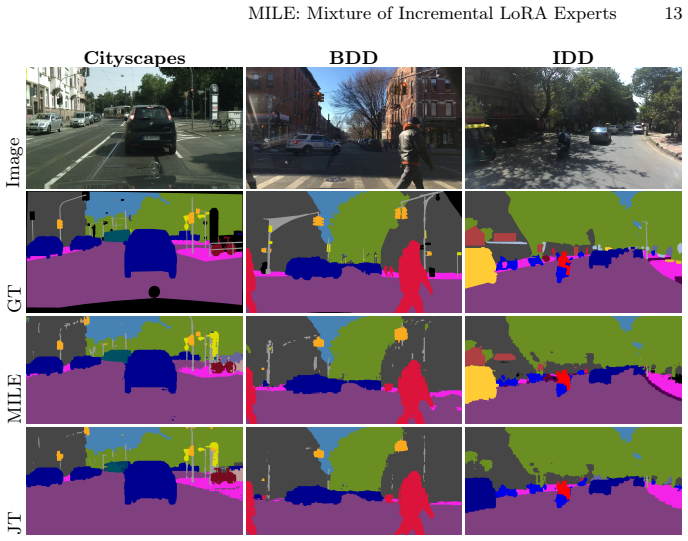
Summary. The paper introduces MILE, a modular framework for continual semantic segmentation across domains and modalities. It freezes a pretrained backbone and adds task-specific LoRA experts, each trained exclusively on its own data to avoid forgetting. A prototype-guided gating mechanism selects the appropriate expert at inference without task labels. The central claim is that this achieves the benefits of expert-based continual learning (stability and plasticity) while overcoming scalability limitations of dynamic expansion methods, with only marginal parameter growth per task such that tens of LoRA adapters match the size of one full model, and reports strong benchmark performance.
Significance. If the experimental support holds, the work would be significant for continual learning in computer vision by offering a parameter-efficient expert-mixture approach that scales better than full-model expansion or parameter-isolation baselines. It directly addresses real-world needs for adapting segmentation models to new domains or modalities (e.g., RGB to depth or cross-dataset shifts) while preserving prior performance, and the emphasis on LoRA-based modularity could influence efficient adaptation techniques more broadly.
major comments (2)
- [Method section (gating description)] The prototype-guided gating mechanism is load-bearing for the headline claim of reliable expert selection at inference without task identity. The manuscript provides insufficient detail on prototype construction (e.g., embedding averaging or storage), the distance metric for nearest-prototype selection, and any handling of out-of-distribution inputs from unseen modalities or domains. Because each expert is trained in isolation on its task data and the base network is frozen, any mismatch in embeddings due to distribution shift directly risks incorrect routing, undermining both stability and plasticity guarantees.
- [Experiments section] The abstract asserts strong benchmark results and superior stability/plasticity/scalability, yet the provided text contains no quantitative tables, ablation studies, forgetting metrics, or error bars. Without these in the experimental section, it is impossible to verify whether the reported gains are attributable to the gating and LoRA design rather than baseline choices or hyperparameter tuning.
minor comments (2)
- [Method] Notation for the gating function and prototype distance could be formalized with an equation to improve clarity and reproducibility.
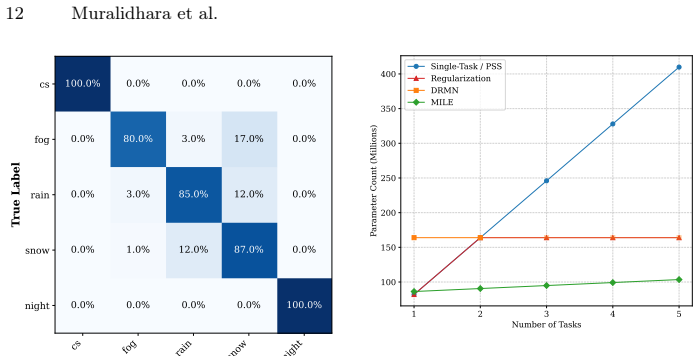
- [Introduction or Experiments] The claim that 'tens of LoRA adapters are needed before matching the size of a single full model' would benefit from an explicit parameter-count comparison table against full fine-tuning and prior expert methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity in the method description and experimental presentation. We address each point below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Method section (gating description)] The prototype-guided gating mechanism is load-bearing for the headline claim of reliable expert selection at inference without task identity. The manuscript provides insufficient detail on prototype construction (e.g., embedding averaging or storage), the distance metric for nearest-prototype selection, and any handling of out-of-distribution inputs from unseen modalities or domains. Because each expert is trained in isolation on its task data and the base network is frozen, any mismatch in embeddings due to distribution shift directly risks incorrect routing, undermining both stability and plasticity guarantees.
Authors: We agree that additional details on the prototype-guided gating are necessary to fully support the claims. In the revised manuscript, we will expand the relevant method subsection to specify: prototypes are constructed by averaging the embeddings produced by the frozen backbone on each task's training samples and stored as fixed vectors; nearest-prototype selection uses Euclidean distance in the embedding space; and for out-of-distribution inputs, the mechanism defaults to the closest available prototype while we will add discussion of potential limitations and a confidence threshold for routing decisions. These clarifications will address concerns about embedding mismatches and routing reliability. revision: yes
-
Referee: [Experiments section] The abstract asserts strong benchmark results and superior stability/plasticity/scalability, yet the provided text contains no quantitative tables, ablation studies, forgetting metrics, or error bars. Without these in the experimental section, it is impossible to verify whether the reported gains are attributable to the gating and LoRA design rather than baseline choices or hyperparameter tuning.
Authors: We acknowledge that the experimental presentation in the reviewed version may not have sufficiently highlighted the supporting results. We will revise the Experiments section to include explicit quantitative tables reporting mIoU and other metrics across benchmarks, dedicated ablation studies isolating the contributions of the gating mechanism and LoRA experts, standard forgetting metrics (e.g., backward transfer), and error bars from multiple random seeds. This will allow direct verification that performance gains stem from the proposed design. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents MILE as a new architectural framework combining frozen base networks, task-specific LoRA experts, and a prototype-guided gating mechanism for continual segmentation. All performance claims (stability, plasticity, scalability) are tied to empirical results on external benchmarks rather than any internal equations or derivations that reduce by construction to fitted parameters, self-citations, or renamed inputs. No load-bearing step equates a reported gain to a quantity defined inside the paper itself; the gating and expert selection are presented as independent design choices whose reliability is evaluated externally.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A frozen pretrained backbone retains sufficient general visual features for new domains and modalities.
- domain assumption Task-specific experts can be trained independently without catastrophic interference.
invented entities (2)
-
Prototype-guided gating mechanism
no independent evidence
-
Incremental LoRA experts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: CVPR (2017)
Aljundi, R., Chakravarty, P., Tuytelaars, T.: Expert gate: Lifelong learning with a network of experts. In: CVPR (2017)
2017
-
[2]
In: CVPR (2016)
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: CVPR (2016)
2016
-
[3]
In: Asian Conference on Pattern Recognition (2023)
Deng, Y., Xiang, X.: Replaying styles for continual semantic segmentation across domains. In: Asian Conference on Pattern Recognition (2023)
2023
-
[4]
Advances in Data Science and Information Engineering (2021)
Farahani, A., Voghoei, S., Rasheed, K., Arabnia, H.R.: A brief review of domain adaptation. Advances in Data Science and Information Engineering (2021)
2021
-
[5]
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
Fernando, C., Banarse, D., Blundell, C., Zwols, Y., Ha, D., Rusu, A.A., Pritzel, A., Wierstra, D.: Pathnet: Evolution channels gradient descent in super neural networks. arXiv:1701.08734. (2017)
work page Pith review arXiv 2017
-
[6]
In: WACV (2022)
Garg, P., Saluja, R., Balasubramanian, V.N., Arora, C., Subramanian, A., Jawa- har, C.: Multi-domain incremental learning for semantic segmentation. In: WACV (2022)
2022
-
[7]
In: WACV (2025)
Hegde, N., Muralidhara, S., Schuster, R., Stricker, D.: Modality-incremental learn- ing with disjoint relevance mapping networks for image-based semantic segmenta- tion. In: WACV (2025)
2025
-
[8]
In: ACM CSCS (2021)
Hell, F., Hinz, G., Liu, F., Goyal, S., Pei, K., Lytvynenko, T., Knoll, A., Yiqiang, C.: Monitoring perception reliability in autonomous driving: Distributional shift detection for estimating the impact of input data on prediction accuracy. In: ACM CSCS (2021)
2021
-
[9]
In: ICLR (2022)
Hu, E.J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[10]
In: IV (2021)
Kalb, T., Roschani, M., Ruf, M., Beyerer, J.: Continual learning for class-and domain-incremental semantic segmentation. In: IV (2021)
2021
-
[11]
Proceedings of the National Academy of Sciences (2017)
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.: Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences (2017)
2017
-
[12]
NeurIPS (2022) MILE: Mixture of Incremental LoRA Experts 15
Lin, Z., Pathak, D., Wang, Y.X., Ramanan, D., Kong, S.: Continual learning with evolving class ontologies. NeurIPS (2022) MILE: Mixture of Incremental LoRA Experts 15
2022
-
[13]
CVPR (2022)
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. CVPR (2022)
2022
-
[14]
In: ECCV (2018)
Mallya, A., Davis, D., Lazebnik, S.: Piggyback: Adapting a single network to mul- tiple tasks by learning to mask weights. In: ECCV (2018)
2018
-
[15]
In: CVPR (2018)
Mallya, A., Lazebnik, S.: Packnet: Adding multiple tasks to a single network by iterative pruning. In: CVPR (2018)
2018
-
[16]
In: Psychology of Learning and Motivation
McCloskey, M., Cohen, N.J.: Catastrophic interference in connectionist networks: The sequential learning problem. In: Psychology of Learning and Motivation. El- sevier (1989)
1989
-
[17]
Frontiers in Psychology (2013)
Mermillod, M., Bugaiska, A., Bonin, P.: The stability-plasticity dilemma: Investi- gating the continuum from catastrophic forgetting to age-limited learning effects. Frontiers in Psychology (2013)
2013
-
[18]
In: ICCVW (2019)
Michieli, U., Zanuttigh, P.: Incremental learning techniques for semantic segmen- tation. In: ICCVW (2019)
2019
-
[19]
In: ECCV (2024)
Muralidhara, S., Bukhari, S., Schneider, G., Stricker, D., Schuster, R.: Cleo: Con- tinual learning of evolving ontologies. In: ECCV (2024)
2024
-
[20]
In: ICPRAM (2025)
Muralidhara, S., Schuster, R., Stricker, D.: Domain-incremental semantic segmen- tation for autonomous driving under adverse driving conditions. In: ICPRAM (2025)
2025
-
[21]
Muralidhara, S., Stricker, D., Schuster, R.: Clora: Parameter-efficient continual learning with low-rank adaptation. arXiv:2507.19887 (2025)
-
[22]
In: ECCV (2024)
Park, M.Y., Lee, J.H., Park, G.M.: Versatile incremental learning: Towards class and domain-agnostic incremental learning. In: ECCV (2024)
2024
-
[23]
Pattern Recognition (2023)
Qiu, Y., Shen, Y., Sun, Z., Zheng, Y., Chang, X., Zheng, W., Wang, R.: Sats: Self-attention transfer for continual semantic segmentation. Pattern Recognition (2023)
2023
-
[24]
Rusu, A.A., Rabinowitz, N.C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., Hadsell, R.: Progressive neural networks. arXiv:1606.04671 (2016)
work page internal anchor Pith review arXiv 2016
-
[25]
In: ICCV (2021)
Sakaridis, C., Dai, D., Van Gool, L.: ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding. In: ICCV (2021)
2021
-
[26]
TPAMI (2024)
Toldo, M., Michieli, U., Zanuttigh, P.: Learning with style: Continual semantic segmentation across tasks and domains. TPAMI (2024)
2024
-
[27]
In: WACV (2019)
Varma, G., Subramanian, A., Namboodiri, A., Chandraker, M., Jawahar, C.: Idd: A dataset for exploring problems of autonomous navigation in unconstrained en- vironments. In: WACV (2019)
2019
-
[28]
In: IROS (2020)
Vertens, J., Zürn, J., Burgard, W.: Heatnet: Bridging the day-night domain gap in semantic segmentation with thermal images. In: IROS (2020)
2020
-
[29]
NeurIPS (2021)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. NeurIPS (2021)
2021
-
[30]
In: CVPR (2020)
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., Madhavan, V., Darrell, T.: Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In: CVPR (2020)
2020
-
[31]
TPAMI (2024)
Yuan, B., Zhao, D.: A survey on continual semantic segmentation: Theory, chal- lenge, method and application. TPAMI (2024)
2024
-
[32]
In: CVPR (2022)
Zhang, C.B., Xiao, J.W., Liu, X., Chen, Y.C., Cheng, M.M.: Representation com- pensation networks for continual semantic segmentation. In: CVPR (2022)
2022
-
[33]
TPAMI (2024)
Zhou,D.W.,Wang,Q.W.,Qi,Z.H.,Ye,H.J.,Zhan,D.C.,Liu,Z.:Class-incremental learning: A survey. TPAMI (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.