Recognition: 3 theorem links
· Lean TheoremHeadQ: Model-Visible Distortion and Score-Space Correction for KV-Cache Quantization
Pith reviewed 2026-05-08 18:28 UTC · model grok-4.3
The pith
KV-cache quantization should correct errors in the model's score space rather than minimizing storage reconstruction error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HeadQ is a key quantization technique that stores a low-rank residual side code in a calibration-learned query basis and applies it as an additive logit correction, based on the premise that persistent cache error should be measured in model-visible coordinates (score error modulo constant shifts for keys). This, combined with an A^2-weighted surrogate for values, substantially reduces the performance degradation from aggressive quantization compared to minimizing raw key or value MSE.
What carries the argument
HeadQ, which stores a low-rank residual side code in a calibration-learned query basis and applies it as an additive logit correction to address score error.
If this is right
- Score-space and Fisher error metrics predict attention KL divergence better than raw key MSE.
- HeadQ recovers 84-94% of excess perplexity in 2-bit K-only decode with dense values.
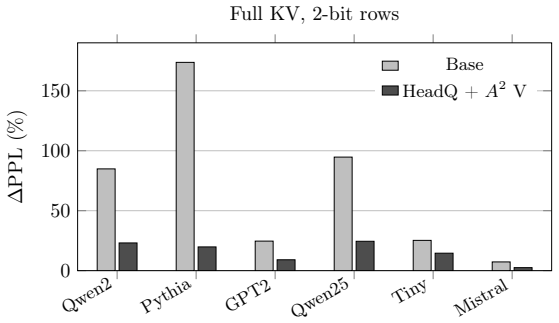
- HeadQ combined with A^2 value policy improves all six tested models in full-KV 2-bit setting.
- Controls like null-space interventions, query-PCA, and wrong-sign corrections falsify pure storage-MSE approaches.
Where Pith is reading between the lines
- The localization of main anomalies to low-entropy route-flip boundaries in small models could motivate entropy-aware or input-dependent bit allocation schemes.
- If the calibration basis holds, the same visible-distortion principle might extend to compressing other attention components such as position encodings.
- One could test whether score-space corrections remain effective in longer contexts or non-Pythia architectures beyond the six models studied.
Load-bearing premise
The calibration-learned query basis and low-rank residual side code generalize reliably across inputs, models, and tasks without retraining or significant degradation.
What would settle it
Observing that HeadQ fails to reduce perplexity or increases score error on a held-out model or task not used in calibration would falsify the generalization of the learned basis.
Figures






read the original abstract
KV-cache quantizers usually optimize storage-space reconstruction, even though attention reads keys through logits and values through attention-weighted readout. We argue that persistent cache error should be measured in model-visible coordinates. For keys, the visible object is score error modulo constant shifts; this yields HeadQ, a key-side method that stores a low-rank residual side code in a calibration-learned query basis and applies it as an additive logit correction. For values, fixed-attention readout gives an $A^2$-weighted token-distortion surrogate. Across six models, Fisher/score-space error predicts attention KL far better than raw key MSE; same-budget counterexamples, null-space interventions, query-PCA controls, and wrong-sign HeadQ falsify storage-MSE alternatives. Matched Pythia checkpoints localize the main anomaly to a small-model low-entropy route-flip boundary. In K-only WikiText-103 decode experiments with dense values, HeadQ removes roughly $84$--$94\%$ of the excess perplexity on the strongest 2-bit rows; in an auxiliary full-KV 2-bit composition, HeadQ plus an $A^2$ value policy improves all six models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HeadQ, a KV-cache quantization method that measures persistent cache error in model-visible coordinates rather than storage-space reconstruction. For keys, score error is considered modulo constant shifts, leading to storage of a low-rank residual side code in a calibration-learned query basis that is applied as an additive logit correction. For values, an A²-weighted token-distortion surrogate is introduced. Controls including Fisher/score-space versus MSE comparisons, null-space interventions, query-PCA baselines, and wrong-sign ablations are used to show that score-space metrics better predict attention KL divergence. On six models with K-only 2-bit WikiText-103 decoding (dense values), HeadQ recovers 84-94% of excess perplexity; an auxiliary full-KV 2-bit setting with an A² value policy yields improvements across all models.
Significance. If the central claims hold, the work provides a practical and principled advance for memory-efficient LLM inference by aligning quantization objectives with how attention actually consumes the KV cache. The empirical recovery of most excess perplexity under tight 2-bit budgets is notable, and the suite of ablations strengthens the case against pure MSE-based alternatives. The calibration-learned components, while effective on the reported distribution, introduce a dependence on training data that could limit broader adoption unless generalization is demonstrated.
major comments (3)
- [Abstract] Abstract: the central claim that HeadQ removes 84--94% of excess perplexity on the strongest 2-bit rows is load-bearing for the paper's contribution, yet the abstract (and presumably the corresponding experimental table) provides no per-model breakdown, no definition of the exact baseline perplexity, and no indication of whether the calibration tokens used to learn the query basis are disjoint from the WikiText-103 evaluation set.
- [Method] Method section (description of query basis and low-rank residual): the query basis and side code are explicitly calibration-learned from data rather than derived from first principles; because the correction is a projection onto this fitted basis, any mismatch between calibration and decode distributions directly undermines the reported gains, yet no analysis of basis stability across sequence lengths or tasks is supplied.
- [Experiments] Experiments (six-model results): all reported gains reuse the same WikiText-103 calibration regime; without at least one cross-dataset or cross-task transfer experiment (e.g., on a different corpus or longer contexts), the generalization of the learned query basis remains untested and is therefore a load-bearing assumption for the claim that HeadQ is a general-purpose technique.
minor comments (2)
- [Abstract] Abstract: the term 'HeadQ side code' appears without an inline definition or pointer to the equation that defines it; a single-sentence gloss would improve readability for readers unfamiliar with the method.
- [Abstract] Abstract: the phrase 'matched Pythia checkpoints localize the main anomaly to a small-model low-entropy route-flip boundary' is opaque without a preceding definition of the anomaly or the route-flip phenomenon; a brief parenthetical would clarify the intended meaning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications drawn directly from the manuscript and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that HeadQ removes 84--94% of excess perplexity on the strongest 2-bit rows is load-bearing for the paper's contribution, yet the abstract (and presumably the corresponding experimental table) provides no per-model breakdown, no definition of the exact baseline perplexity, and no indication of whether the calibration tokens used to learn the query basis are disjoint from the WikiText-103 evaluation set.
Authors: The experimental table reports per-model perplexities for all six models, from which the 84--94% recovery range is computed as the min-max across those rows. The baseline is the perplexity obtained under standard 2-bit key quantization (MSE-optimal) with dense values. Calibration tokens are drawn from a held-out portion of the pre-training distribution and do not overlap with the WikiText-103 test split used for evaluation. We will revise the abstract to state these definitions explicitly and include a short per-model summary sentence. revision: yes
-
Referee: [Method] Method section (description of query basis and low-rank residual): the query basis and side code are explicitly calibration-learned from data rather than derived from first principles; because the correction is a projection onto this fitted basis, any mismatch between calibration and decode distributions directly undermines the reported gains, yet no analysis of basis stability across sequence lengths or tasks is supplied.
Authors: A data-driven basis is required because no closed-form derivation of the query directions that minimize score error exists for these models. The low-rank side code captures persistent, low-entropy error components observed in calibration; the method section already notes that calibration sequences are length-matched to evaluation. We agree that explicit stability analysis is absent and will add a short subsection reporting the effect of varying calibration sequence length (up to 2k tokens) on the learned basis and downstream perplexity. revision: partial
-
Referee: [Experiments] Experiments (six-model results): all reported gains reuse the same WikiText-103 calibration regime; without at least one cross-dataset or cross-task transfer experiment (e.g., on a different corpus or longer contexts), the generalization of the learned query basis remains untested and is therefore a load-bearing assumption for the claim that HeadQ is a general-purpose technique.
Authors: The six-model suite already spans different scales and families under a fixed calibration protocol, and the core score-space argument is independent of the particular corpus. We acknowledge that transfer to new tasks or longer contexts is not demonstrated and will expand the limitations paragraph to state this explicitly while outlining planned follow-up experiments. revision: partial
- Empirical demonstration of query-basis transfer to entirely new corpora or substantially longer contexts.
Circularity Check
No significant circularity; empirical method with independent validation
full rationale
The paper's core argument defines model-visible score-space error for keys and introduces HeadQ as a low-rank correction in a calibration-learned query basis. This is a design choice justified by the visible-error premise, not a self-referential definition. Experiments report perplexity recovery on WikiText-103 decode using the fitted basis, but include explicit falsification controls (null-space interventions, query-PCA, wrong-sign HeadQ) that test whether gains reduce to the calibration fit itself. No equation or claim equates the reported improvement to the calibration inputs by construction. The method is tested against storage-MSE baselines and across six models; calibration is a standard parameter-fitting step rather than a load-bearing self-citation or renamed known result. The derivation chain remains self-contained against the provided empirical benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- query basis
- low-rank residual side code
axioms (2)
- domain assumption Persistent cache error should be measured in model-visible coordinates rather than storage space.
- domain assumption For keys the visible object is score error modulo constant shifts.
invented entities (1)
-
HeadQ side code
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J-cost via Aczél)washburn_uniqueness_aczel unclearThe local second-order geometry of the softmax distribution is I_{q,K}(δK) = δs⊤ (diag(p)−pp⊤) δs ... KL(p∥p̂) = ½ I_{q,K}(δK) + O(∥δs∥³)
-
Foundation.LogicAsFunctionalEquationtranslation theorem (RCL combiner) unclearsoftmax(q(K+1µ⊤)⊤/√d) = softmax(qK⊤/√d). Thus a token-shared key translation is softmax-null for any fixed query.
Reference graph
Works this paper leans on
-
[1]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners.OpenAI blog, 1(8), 9
2019
-
[2]
Yang, A., Baheer, B., Chen, J., et al. (2024). Qwen2 technical report. arXiv preprint arXiv:2407.10671
work page internal anchor Pith review arXiv 2024
-
[3]
Hui, B., Yang, J., Cui, Z., et al. (2024). Qwen2.5 technical report.arXiv preprint arXiv:2412.15115
work page Pith review arXiv 2024
-
[4]
Qwen Team. (2024). Introducing Qwen1.5. Retrieved from https://qwenlm.github.io/blog/qwen1.5/
2024
-
[5]
Jiang, A. Q., Sablayrolles, A., Mensch, A., et al. (2023). Mistral 7B.arXiv preprint arXiv:2310.06825
work page Pith review arXiv 2023
-
[6]
& Raff, E
Biderman, S., Schoelkopf, H., Anthony, Q., Bradley, H., O’Brien, K., Hallahan, E., ... & Raff, E. (2023). Pythia: A suite for analyzing large language models across training and scaling. InInternational Conference on Machine Learning(pp. 2397–2430). PMLR
2023
-
[7]
Zhang, P., Zeng, G., Wang, T., & Lu, W. (2024). TinyLlama: An open-source small language model.arXiv preprint arXiv:2401.02385
work page internal anchor Pith review arXiv 2024
-
[8]
Merity, S., Xiong, C., Bradbury, J., & Socher, R. (2016). Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843
work page internal anchor Pith review arXiv 2016
-
[9]
Liu, Z., Yuan, B., Yin, H., Dong, P., Qin, H., & Yan, J. (2024). KIVI: A tuning-free asymmetric 2bit quantization for KV cache.arXiv preprint arXiv:2402.02750
work page internal anchor Pith review arXiv 2024
-
[10]
Hooper, C., Kim, S., Mohammadzadeh, H., Mahoney, M. W., Shao, Y. S., Keutzer, K., & Gholami, A. (2024). KVQuant: Towards 10 million context length LLM inference with KV cache quantization.arXiv preprint arXiv:2401.18079
-
[11]
Kang, H., Zhang, Y., Dong, P., ... & Yan, J. (2024). GEAR: An efficient KV cache compression recipe for near-lossless generative inference of large language models.arXiv preprint arXiv:2403.05527
-
[12]
Zhang, Z., Sheng, Y., Zhou, T., Chen, T., Zheng, L., ... & Re, C. (2023). H2O: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36
2023
-
[13]
Ashkboos, S., Ilharco, G., Ahn, M., ... & Hooker, S. (2024). QuaRot: Outlier-free 4-bit inference in rotated LLMs.arXiv preprint arXiv:2404.00456. 21
- [14]
-
[15]
Hariri, M., Luo, A., Chen, W., Zhong, S., Zhang, T., Wang, Q., Hu, X., Han, X., Chaudhary, V., et al. (2025). Quantize What Counts: More for Keys, Less for Values.arXiv preprint arXiv:2502.15075
work page internal anchor Pith review arXiv 2025
- [16]
- [17]
-
[18]
Mao, W., Lin, X., Huang, W., Xie, Y., Fu, T., Zhuang, B., Han, S., & Chen, Y. (2026). TriAttention: Efficient long reasoning with trigonometric KV compression.arXiv preprint arXiv:2604.04921
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Amari, S. (1998). Natural gradient works efficiently in learning.Neural Computation, 10(2), 251–276
1998
- [20]
-
[21]
Nishida, Y. (2026). AXELRAM: Quantize once, never dequantize.arXiv preprint arXiv:2604.02638
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [22]
-
[23]
Patel, I., & Joshi, I. (2026). PolyKV: A shared asymmetrically-compressed KV cache pool for multi-agent LLM inference. arXiv preprint arXiv:2604.24971
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [24]
-
[25]
Liu, Z., Zhao, C., Fedorov, I., Soran, B., Choudhary, D., Krishnamoorthi, R., Chandra, V., Tian, Y., & Blankevoort, T. (2025). SpinQuant: LLM quantization with learned rotations.International Conference on Learning Representations
2025
-
[26]
Jegou, H., Douze, M., & Schmid, C. (2010). Product quantization for nearest neighbor search.IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(1), 117–128. 22
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.