Recognition: unknown
Poisson Empirical Bayes via Gamma-Smoothed Nonparametric Maximum Likelihood
Pith reviewed 2026-05-07 12:58 UTC · model grok-4.3
The pith
Gamma mixture smoothing of the NPMLE achieves optimal posterior mean rates and shorter plug-in confidence sets for Poisson empirical Bayes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Gamma-smoothed NPMLE models the unknown prior as a mixture of Gamma distributions, thereby approximating continuous priors while retaining the computational tractability of classical NPMLE. This estimator attains the optimal nearly parametric rate for estimating posterior means and, under compact support of the mixing distribution, polynomial rates for estimating the prior and posterior densities. Plug-in empirical Bayes confidence sets built from the estimator achieve asymptotically exact marginal coverage and expected lengths that asymptotically match the oracle-optimal marginal coverage sets.
What carries the argument
The Gamma-smoothed nonparametric maximum likelihood estimator, which represents the mixing distribution as a finite Gamma mixture to produce a continuous prior approximation while preserving the convex optimization problem of the classical NPMLE.
If this is right
- Posterior mean estimates converge at the nearly parametric rate.
- Prior and posterior density estimates converge at polynomial rates when the mixing distribution has compact support.
- Plug-in confidence sets achieve asymptotically exact marginal coverage.
- The sets have shorter expected length than existing NPMLE-based procedures while matching oracle performance.
Where Pith is reading between the lines
- The same Gamma-mixture smoothing device could be applied to empirical Bayes problems for other exponential families.
- The shorter intervals may reduce the number of discoveries declared in large-scale multiple-testing settings that use Poisson observations.
- Direct comparison of the smooth NPMLE against kernel or spline-based smoothers on the same Poisson data would isolate the benefit of the mixture representation.
Load-bearing premise
The mixing distribution has compact support on a fixed interval.
What would settle it
A simulation study in which the constructed confidence sets fail to maintain marginal coverage close to the nominal level or produce intervals whose average length does not improve over standard NPMLE-based intervals on data generated from a compactly supported prior.
Figures




read the original abstract
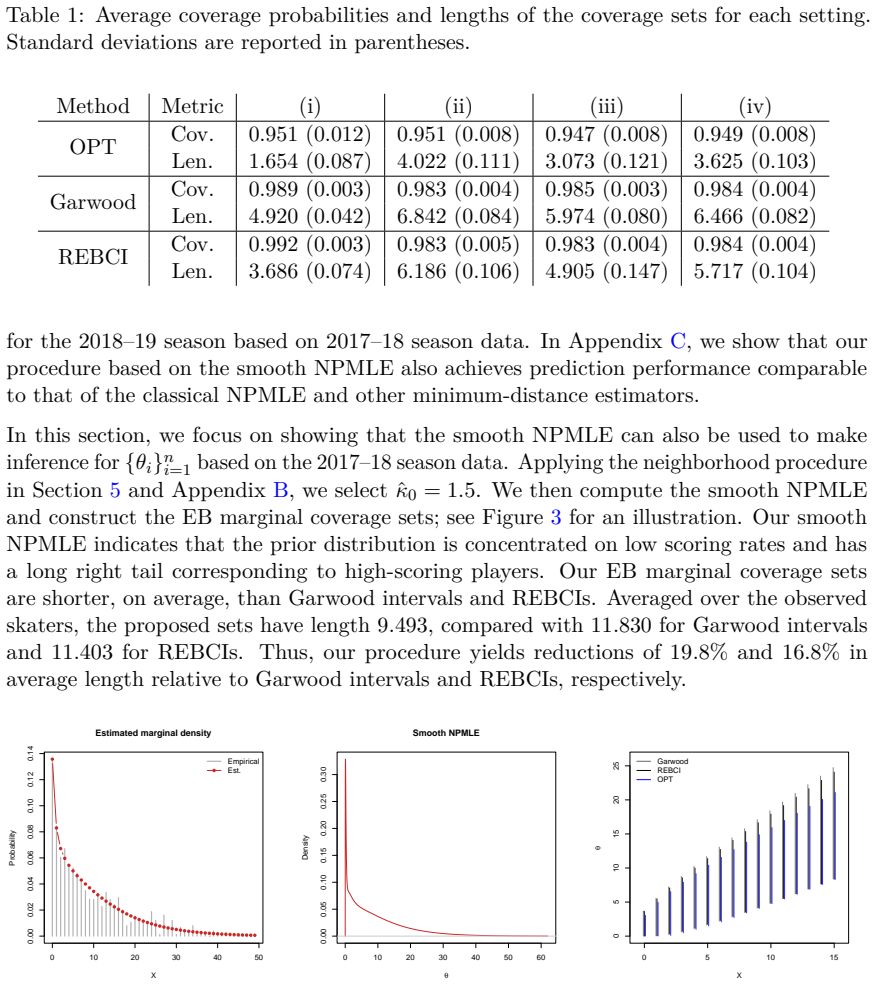
Empirical Bayes methods are widely used for large-scale estimation and inference in the Poisson means problem. Existing results establish theoretical properties of the nonparametric maximum likelihood estimator (NPMLE) for optimal posterior mean estimation, but comparatively less is known about uncertainty quantification (i.e., construction of confidence sets). Two main challenges in constructing confidence sets for the latent parameters based on the NPMLE are its discreteness and its slow rate of prior estimation. We resolve these limitations by introducing a smooth NPMLE that models the prior as a Gamma mixture, which is a flexible class capable of approximating a wide range of continuous priors on $(0,\infty)$. This procedure preserves the convex optimization structure of the classical NPMLE. The smooth NPMLE achieves the optimal nearly parametric rate for posterior mean estimation. Moreover, it achieves a polynomial convergence rate for prior and posterior density estimation under a compact support assumption on the mixing distribution. Based on the smooth NPMLE, we construct plug-in empirical Bayes confidence sets that mimic the oracle optimal (in terms of expected length) marginal coverage sets. We show theoretically and empirically that these sets achieve asymptotically exact marginal coverage and are substantially shorter than existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Gamma-mixture smoothed NPMLE for the prior in the Poisson empirical Bayes problem. This preserves the convex optimization structure of classical NPMLE while enabling smooth estimation. It claims the optimal nearly parametric rate for posterior mean estimation (without compact support), polynomial rates for prior and posterior density estimation under compact support of the mixing distribution, and constructs plug-in EB confidence sets that achieve asymptotically exact marginal coverage while being shorter than existing methods, with supporting theory and simulations.
Significance. If the derivations hold, the work is significant for providing computationally tractable uncertainty quantification in empirical Bayes for Poisson data, filling a gap between optimal point estimation and reliable inference. The Gamma mixture choice is flexible for continuous priors on (0,∞), and the preservation of convex optimization is a practical strength. Reproducible simulations and explicit rates add value.
major comments (2)
- [Abstract and § on density estimation rates] Abstract and theoretical results: The polynomial convergence rates for prior/posterior density estimation and the asymptotically exact marginal coverage of the plug-in confidence sets are stated to require a compact support assumption on the mixing distribution. For the Poisson means problem with support (0,∞), this assumption is not automatic (e.g., for Gamma or log-normal priors), and the approximation bias of the finite Gamma mixture may not vanish at a polynomial rate without it, making the UQ guarantees load-bearing on this condition.
- [Confidence set construction and coverage theorem] Section on confidence set construction: The plug-in sets are claimed to mimic oracle optimal expected length and achieve exact coverage. The proof sketch must explicitly show how the density estimation error (polynomial only under compact support) controls the coverage deviation; if the nearly-parametric posterior mean rate is used separately, clarify whether the coverage result reduces to it or requires the stronger density rate throughout.
minor comments (2)
- Specify how the number of Gamma mixture components is selected in practice and theory (e.g., via cross-validation or fixed for rates).
- In the simulation section, list the exact existing methods compared and report quantitative length and coverage metrics with standard errors.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback, which highlights important clarifications needed regarding assumptions and proof details. We address each major comment point by point below and have revised the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and § on density estimation rates] Abstract and theoretical results: The polynomial convergence rates for prior/posterior density estimation and the asymptotically exact marginal coverage of the plug-in confidence sets are stated to require a compact support assumption on the mixing distribution. For the Poisson means problem with support (0,∞), this assumption is not automatic (e.g., for Gamma or log-normal priors), and the approximation bias of the finite Gamma mixture may not vanish at a polynomial rate without it, making the UQ guarantees load-bearing on this condition.
Authors: We agree that the compact support assumption is essential for the polynomial rates on prior and posterior density estimation as well as for the asymptotically exact marginal coverage of the plug-in confidence sets, and this is explicitly stated in the abstract and the relevant theorem statements. The nearly parametric rate for posterior mean estimation holds without compact support, as shown in our main point estimation result. Under compact support, finite Gamma mixtures achieve polynomial approximation bias because they are dense in the continuous densities on compact intervals. We acknowledge that for common unbounded priors such as Gamma or log-normal, the assumption does not hold automatically and the bias may decay more slowly. We will add a dedicated remark in the introduction and a discussion section clarifying the scope of the UQ results, noting practical cases where compact support can be imposed via truncation, and outlining potential slower-rate extensions for unbounded supports. revision: yes
-
Referee: [Confidence set construction and coverage theorem] Section on confidence set construction: The plug-in sets are claimed to mimic oracle optimal expected length and achieve exact coverage. The proof sketch must explicitly show how the density estimation error (polynomial only under compact support) controls the coverage deviation; if the nearly-parametric posterior mean rate is used separately, clarify whether the coverage result reduces to it or requires the stronger density rate throughout.
Authors: The coverage result requires the stronger polynomial rate from density estimation under compact support to bound the deviation in coverage probability. Specifically, the sup-norm or total-variation error in the estimated marginal density and the induced posterior controls the difference between the plug-in coverage and the oracle coverage, driving it to zero at a polynomial rate. The nearly parametric posterior-mean rate is used separately to establish that the expected length of the plug-in sets asymptotically matches the oracle optimal length. We will expand the proof sketch in the revised manuscript to include the explicit chaining of inequalities showing how the density estimation error propagates to the coverage deviation, thereby clarifying the distinct roles of the two rates. revision: yes
Circularity Check
No significant circularity; claims rest on explicit assumptions and standard asymptotics
full rationale
The derivation chain begins with a Gamma-mixture smooth NPMLE formulated as a convex optimization problem that preserves the structure of classical NPMLE. Posterior-mean rate optimality is stated as following from this optimization without reduction to fitted inputs by construction. Polynomial density rates and plug-in confidence-set coverage are derived under the explicitly declared compact-support assumption on the mixing distribution; this assumption is not hidden or self-referential but is required for the bias term to vanish at polynomial speed. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled via prior work, and no known empirical pattern is merely renamed. The construction of the confidence sets mimics oracle marginal coverage via plug-in estimation, but the coverage guarantee is obtained from separate asymptotic arguments rather than tautological re-labeling of fitted quantities. The overall argument is therefore self-contained against external benchmarks once the compact-support condition is granted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption compact support assumption on the mixing distribution
Reference graph
Works this paper leans on
-
[1]
Armstrong, Michal Kolesár, and Mikkel Plagborg-Møller
Timothy B. Armstrong, Michal Kolesár, and Mikkel Plagborg-Møller. Robust empirical Bayes confidence intervals.Econometrica, 90(6):2567–2602, 2022
2022
-
[2]
Parametric convergence rate of some nonparametric estimators in mixtures of power series distributions.Electronic Journal of Statistics, 19(2):3686–3722, 2025
Fadoua Balabdaoui, Harald Besdziek, and Yong Wang. Parametric convergence rate of some nonparametric estimators in mixtures of power series distributions.Electronic Journal of Statistics, 19(2):3686–3722, 2025
2025
-
[3]
A general framework for empirical Bayes estimation in discrete linear exponential family.Journal of Machine Learning Research, 22(67):1–46, 2021
Trambak Banerjee, Qiang Liu, Gourab Mukherjee, and Wengunag Sun. A general framework for empirical Bayes estimation in discrete linear exponential family.Journal of Machine Learning Research, 22(67):1–46, 2021
2021
-
[4]
Adaptive density estimation based on a mixture of Gammas.Electronic Journal of Statistics, 11(1):916–962, 2017
Natalia Bochkina and Judith Rousseau. Adaptive density estimation based on a mixture of Gammas.Electronic Journal of Statistics, 11(1):916–962, 2017
2017
-
[5]
Hogg, and Sam T
Jo Bovy, David W. Hogg, and Sam T. Roweis. Extreme deconvolution: Inferring complete distribution functions from noisy, heterogeneous and incomplete observations. The Annals of Applied Statistics, 5(2B):1657–1677, 2011
2011
-
[6]
Brown and Eitan Greenshtein
Lawrence D. Brown and Eitan Greenshtein. Nonparametric empirical Bayes and compound decision approaches to estimation of a high-dimensional vector of normal means.The Annals of Statistics, 37(4):1685–1704, 2009
2009
- [8]
-
[9]
A semi-parametric estimator of a risk distribution.Insurance: Mathematics and Economics, 13(1):75–81, 1993
Jacques Carriere. A semi-parametric estimator of a risk distribution.Insurance: Mathematics and Economics, 13(1):75–81, 1993
1993
-
[10]
Cordy and David R
Clifford B. Cordy and David R. Thomas. Deconvolution of a distribution function. Journal of the American Statistical Association, 92(440):1459–1465, 1997
1997
-
[11]
Smoothed NPML estimation of the risk distribu- tion underlying Bonus-Malus systems
Michel Denuit and Philippe Lambert. Smoothed NPML estimation of the risk distribu- tion underlying Bonus-Malus systems. InProceedings of the Casualty Actuarial Society, volume 88, page 142–174, 2001
2001
-
[12]
Ronald A. DeVore. Degree of approximation. InApproximation Theory II, volume 241, pages 117–161. 1976
1976
-
[13]
Achieving Bayes MMSE performance in the sparse signal + Gaussian white noise model when the noise level is unknown
David Donoho and Galen Reeves. Achieving Bayes MMSE performance in the sparse signal + Gaussian white noise model when the noise level is unknown. In2013 IEEE International Symposium on Information Theory, pages 101–105, 2013
2013
-
[14]
David L. Donoho. One-sided inference about functionals of a density.The Annals of Statistics, 16(4):1390–1420, 1988
1988
-
[15]
Institute of Mathematical Statistics Monographs
Bradley Efron.Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction. Institute of Mathematical Statistics Monographs. Cambridge University Press, 2010
2010
-
[16]
Two modeling strategies for empirical Bayes estimation.Statistical Science, 29(2):285–301, 2014
Bradley Efron. Two modeling strategies for empirical Bayes estimation.Statistical Science, 29(2):285–301, 2014. 13
2014
-
[17]
Empirical Bayes deconvolution estimates.Biometrika, 103(1):1–20, 2016
Bradley Efron. Empirical Bayes deconvolution estimates.Biometrika, 103(1):1–20, 2016
2016
-
[18]
Bayes, oracle Bayes and empirical Bayes.Statistical Science, 34(2): 177–201, 2019
Bradley Efron. Bayes, oracle Bayes and empirical Bayes.Statistical Science, 34(2): 177–201, 2019
2019
-
[19]
F. Garwood. Fiducial limits for the Poisson distribution.Biometrika, 28(3/4):437–442, 1936
1936
-
[20]
Conver- gence of smoothed empirical measures with applications to entropy estimation.IEEE Transactions on Information Theory, 66(7):4368–4391, 2020
Ziv Goldfeld, Kristjan Greenewald, Jonathan Niles-Weed, and Yury Polyanskiy. Conver- gence of smoothed empirical measures with applications to entropy estimation.IEEE Transactions on Information Theory, 66(7):4368–4391, 2020
2020
-
[21]
I. J. Good and G. H. Toulmin. The number of new species, and the increase in population coverage, when a sample is increased.Biometrika, 43(1/2):45–63, 1956
1956
-
[22]
Nonparametric mixture MLEs under Gaussian- smoothed optimal transport distance.IEEE Transactions on Information Theory, 69 (12):7823–7835, 2023
Fang Han, Zhen Miao, and Yandi Shen. Nonparametric mixture MLEs under Gaussian- smoothed optimal transport distance.IEEE Transactions on Information Theory, 69 (12):7823–7835, 2023
2023
-
[23]
Yanjun Han, Jonathan Niles-Weed, Yandi Shen, and Yihong Wu. Besting Good–Turing: Optimality of non-parametric maximum likelihood for distribution estimation.arXiv preprint arXiv:2509.07355, 2025. URL https://arxiv.org/abs/2509.07355
-
[24]
Peter Hoff and Surya Tokdar. Selective and marginal selective inference for exceptional groups.arXiv preprint arXiv:2509.13538, 2025. URL https://arxiv.org/abs/2509.13538
-
[25]
Confidence intervals for nonparametric empirical Bayes analysis.Journal of the American Statistical Association, 117(539):1192–1199, 2022
Nikolaos Ignatiadis and Stefan Wager. Confidence intervals for nonparametric empirical Bayes analysis.Journal of the American Statistical Association, 117(539):1192–1199, 2022
2022
-
[26]
Teh, and Yihong Wu
Soham Jana, Yury Polyanskiy, Anzo Z. Teh, and Yihong Wu. Empirical Bayes via ERM and Rademacher complexities: the Poisson model. InProceedings of Thirty Sixth Conference on Learning Theory, volume 195 ofProceedings of Machine Learning Research, pages 5199–5235, 2023
2023
-
[27]
Optimal empirical Bayes estimation for the Poisson model via minimum-distance methods.Information and Inference: A Journal of the IMA, 14(4):iaaf027, 2025
Soham Jana, Yury Polyanskiy, and Yihong Wu. Optimal empirical Bayes estimation for the Poisson model via minimum-distance methods.Information and Inference: A Journal of the IMA, 14(4):iaaf027, 2025
2025
-
[28]
General maximum likelihood empirical Bayes estimation of normal means.The Annals of Statistics, 37(4):1647–1684, 2009
Wenhua Jiang and Cun-Hui Zhang. General maximum likelihood empirical Bayes estimation of normal means.The Annals of Statistics, 37(4):1647–1684, 2009
2009
-
[29]
Function estimation in the empirical Bayes setting.arXiv preprint arXiv:2601.18689, 2026
Benjamin Kang, Yury Polyanskiy, and Anzo Teh. Function estimation in the empirical Bayes setting.arXiv preprint arXiv:2601.18689, 2026. URL https://arxiv.org/abs/26 01.18689
-
[30]
Taehyun Kim and Bodhisattva Sen. Empirical Bayes estimation and inference via smooth nonparametric maximum likelihood.arXiv preprint arXiv:2603.27843, 2026. URL https://arxiv.org/abs/2603.27843
-
[31]
REBayes: An R package for empirical Bayes mixture methods.Journal of Statistical Software, 82(8):1–26, 2017
Roger Koenker and Jiaying Gu. REBayes: An R package for empirical Bayes mixture methods.Journal of Statistical Software, 82(8):1–26, 2017
2017
-
[32]
Convex optimization, shape constraints, compound 14 decisions, and empirical Bayes rules.Journal of the American Statistical Association, 109(506):674–685, 2014
Roger Koenker and Ivan Mizera. Convex optimization, shape constraints, compound 14 decisions, and empirical Bayes rules.Journal of the American Statistical Association, 109(506):674–685, 2014
2014
-
[33]
Laird and Thomas A
Nan M. Laird and Thomas A. Louis. Empirical Bayes confidence intervals based on bootstrap samples.Journal of the American Statistical Association, 82(399):739–750, 1987
1987
-
[34]
Asymptotic properties of maximum likelihood estimates in the mixed Poisson model.The Annals of Statistics, 12(4):1388–1399, 1984
Diane Lambert and Luke Tierney. Asymptotic properties of maximum likelihood estimates in the mixed Poisson model.The Annals of Statistics, 12(4):1388–1399, 1984
1984
-
[35]
Lindsay.Mixture models: theory, geometry, and applications
Bruce G. Lindsay.Mixture models: theory, geometry, and applications. Institute of Mathematical Statistics, 1995
1995
-
[36]
Global properties of kernel estimators for mixing densities in discrete exponential family models.Statistica Sinica, 6(3):561–578, 1996
Wei-Liem Loh and Cun-Hui Zhang. Global properties of kernel estimators for mixing densities in discrete exponential family models.Statistica Sinica, 6(3):561–578, 1996
1996
-
[37]
J. S. Maritz. Smooth empirical Bayes estimation for one-parameter discrete distributions. Biometrika, 53(3–4):417–429, 1966
1966
-
[38]
P. Massart. The tight constant in the Dvoretzky-Kiefer-Wolfowitz inequality.The Annals of Probability, 18(3):1269–1283, 1990
1990
-
[39]
Zhen Miao, Weihao Kong, Ramya Korlakai Vinayak, Wei Sun, and Fang Han. Fisher- Pitman permutation tests based on nonparametric Poisson mixtures with application to single cell genomics.Journal of the American Statistical Association, 119(545):394–406, 2024
2024
-
[40]
Carl N. Morris. Parametric empirical Bayes inference: theory and applications.Journal of the American Statistical Association, 78(381):47–55, 1983
1983
-
[41]
Springer Nature Switzerland, Cham, 2024
Valentin Patilea and Jean-Marie Rolin.Smooth Versus Likelihood Estimation for a Class of Mixtures of Discrete Distributions, pages 315–339. Springer Nature Switzerland, Cham, 2024
2024
-
[42]
Yury Polyanskiy and Yihong Wu. Sharp regret bounds for empirical Bayes and compound decision problems.arXiv preprint arXiv:2109.03943, 2021. URL https: //arxiv.org/abs/2109.03943
-
[43]
Frank C. Porter. Confidence intervals for the Poisson distribution.arXiv preprint arXiv:2509.02852, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
An empirical Bayes approach to statistics
Herbert Robbins. An empirical Bayes approach to statistics. InProceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume I: Con- tributions to the Theory of Statistics, pages 157–164, 1956
1956
-
[45]
On the nonparametric maximum likeli- hood estimator for Gaussian location mixture densities with application to Gaussian denoising.The Annals of Statistics, 48(2):738–762, 2020
Sujayam Saha and Adityanand Guntuboyina. On the nonparametric maximum likeli- hood estimator for Gaussian location mixture densities with application to Gaussian denoising.The Annals of Statistics, 48(2):738–762, 2020
2020
-
[46]
Wei Shen and Thomas A. Louis. Empirical Bayes estimation via the smoothing by roughening approach.Journal of Computational and Graphical Statistics, 8(4):800–823, 1999
1999
-
[47]
Poisson empirical Bayes estimation: When doesg-modeling beat f-modeling in theory (and in practice)?The Annals of Statistics, 54(1):146–175, 2026
Yandi Shen and Yihong Wu. Poisson empirical Bayes estimation: When doesg-modeling beat f-modeling in theory (and in practice)?The Annals of Statistics, 54(1):146–175, 2026. 15
2026
-
[48]
Maximum likelihood estimation of a compound Poisson process.The Annals of Statistics, 4(6):1200–1209, 1976
Leopold Simar. Maximum likelihood estimation of a compound Poisson process.The Annals of Statistics, 4(6):1200–1209, 1976
1976
-
[49]
Multivariate, het- eroscedastic empirical Bayes via nonparametric maximum likelihood.Journal of the Royal Statistical Society Series B: Statistical Methodology, 87(1):1–32, 2024
Jake A Soloff, Adityanand Guntuboyina, and Bodhisattva Sen. Multivariate, het- eroscedastic empirical Bayes via nonparametric maximum likelihood.Journal of the Royal Statistical Society Series B: Statistical Methodology, 87(1):1–32, 2024
2024
-
[50]
False discovery rates: a new deal.Biostatistics, 18(2):275–294, 2016
Matthew Stephens. False discovery rates: a new deal.Biostatistics, 18(2):275–294, 2016
2016
-
[51]
American Mathematical Society, Providence, RI, 4 edition, 1975
Gábor Szegő.Orthogonal Polynomials, volume 23 ofAmerican Mathematical Society Colloquium Publications. American Mathematical Society, Providence, RI, 4 edition, 1975
1975
-
[52]
Comparing Poisson and Gaussian channels (extended)
Anzo Teh and Yury Polyanskiy. Comparing Poisson and Gaussian channels (extended). In2023 IEEE International Symposium on Information Theory, 2023
2023
-
[53]
Solving empirical Bayes via transform- ers.arXiv preprint arXiv:2502.09844, 2025
Anzo Teh, Mark Jabbour, and Yury Polyanskiy. Solving empirical Bayes via transform- ers.arXiv preprint arXiv:2502.09844, 2025. URL https://arxiv.org/abs/2502.09844
-
[54]
Identifiability of mixtures.The Annals of Mathematical Statistics, 32 (1):244–248, 1961
Henry Teicher. Identifiability of mixtures.The Annals of Mathematical Statistics, 32 (1):244–248, 1961
1961
-
[55]
A. F. Timan.Theory of Approximation of Functions of a Real Variable. Elsevier, 2014
2014
-
[56]
Mixtures of Gamma distri- butions with applications.Journal of Computational and Graphical Statistics, 10(3): 440–454, 2001
Michael Wiper, David Rios Insua, and Fabrizio Ruggeri. Mixtures of Gamma distri- butions with applications.Journal of Computational and Graphical Statistics, 10(3): 440–454, 2001
2001
-
[57]
On estimating mixing densities in discrete exponential family models
Cun-Hui Zhang. On estimating mixing densities in discrete exponential family models. The Annals of Statistics, 23(3), 1995. 16 Appendix A Discussion on the polynomial convergence rate of the smooth NPMLE Illustration of the polynomial rateFirst, we provide simulation results to illustrate that the total variation distance betweeng “Hn and gH∗decays at a p...
1995
-
[58]
LetXi and Zi denote the goals scored by playeri in the 2017–18 and 2018–19 seasons, respectively
and our smooth NPMLE. LetXi and Zi denote the goals scored by playeri in the 2017–18 and 2018–19 seasons, respectively. As noted by Jana et al.[26], if, conditionally on θi, the past and future counts are independent and both follow the Poisson model with mean θi, then the predictor ofZi that minimizes mean squared error isE[Zi|Xi] = E[θi|Xi]. Therefore, ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.