Recognition: unknown
Bridging the Embodiment Gap: Disentangled Cross-Embodiment Video Editing
Pith reviewed 2026-05-07 15:40 UTC · model grok-4.3
The pith
By factorizing videos into independent task and embodiment latents, a new editing method converts a single human demonstration into a coherent robot execution video without any paired cross-embodiment data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our method factorizes a demonstration video into two orthogonal latent spaces by enforcing a dual contrastive objective: it minimizes mutual information between the spaces to ensure independence while maximizing intra-space consistency to create stable representations. A parameter-efficient adapter injects these latent codes into a frozen video diffusion model, enabling the synthesis of a coherent robot execution video from a single human demonstration, without requiring paired cross-embodiment data.
What carries the argument
Dual contrastive objective that creates orthogonal task and embodiment latent spaces, combined with a parameter-efficient adapter that injects the codes into a frozen video diffusion model.
If this is right
- The generated videos are temporally consistent and morphologically accurate for the target robot.
- The method works from only a single human demonstration video.
- No paired human-robot examples are needed during training or inference.
- Internet-scale human video collections become usable for robot learning.
- The approach produces coherent robot demonstrations suitable for downstream imitation learning.
Where Pith is reading between the lines
- The same factorization could support video editing across other embodiment changes, such as different robot morphologies or animated characters.
- Policies trained directly on the edited videos might inherit better generalization than those trained on limited robot data.
- The separation might reduce the cost of robot data collection by substituting public human videos for many tasks.
Load-bearing premise
That a dual contrastive objective applied to video latents will reliably separate task content from embodiment kinematics without any paired cross-embodiment examples.
What would settle it
A case in which the generated robot video shows incorrect limb proportions or joint trajectories that do not match the target robot morphology while still attempting the demonstrated task.
Figures












read the original abstract
Learning robotic manipulation from human videos is a promising solution to the data bottleneck in robotics, but the distribution shift between humans and robots remains a critical challenge. Existing approaches often produce entangled representations, where task-relevant information is coupled with human-specific kinematics, limiting their adaptability. We propose a generative framework for cross-embodiment video editing that directly addresses this by learning explicitly disentangled task and embodiment representations. Our method factorizes a demonstration video into two orthogonal latent spaces by enforcing a dual contrastive objective: it minimizes mutual information between the spaces to ensure independence while maximizing intra-space consistency to create stable representations. A parameter-efficient adapter injects these latent codes into a frozen video diffusion model, enabling the synthesis of a coherent robot execution video from a single human demonstration, without requiring paired cross-embodiment data. Experiments show our approach generates temporally consistent and morphologically accurate robot demonstrations, offering a scalable solution to leverage internet-scale human video for robot learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a generative framework for cross-embodiment video editing to address the distribution shift between human and robot videos in robotic manipulation learning. It factorizes demonstration videos into two orthogonal latent spaces (task and embodiment) by applying a dual contrastive objective that minimizes mutual information between the spaces for independence while maximizing intra-space consistency. A parameter-efficient adapter then injects these latent codes into a frozen video diffusion model, allowing synthesis of coherent robot execution videos from single human demonstrations without requiring paired cross-embodiment data. The abstract asserts that experiments produce temporally consistent and morphologically accurate robot videos.
Significance. If the disentanglement and editing pipeline hold, the work could be significant for robotics by enabling scalable use of internet-scale human videos for robot learning without paired data or large robot datasets. The parameter-efficient adapter and frozen diffusion model approach is practically attractive for efficiency. However, the absence of any quantitative validation in the provided description limits assessment of whether these benefits are realized.
major comments (2)
- [Abstract] Abstract: The central claim that 'experiments show our approach generates temporally consistent and morphologically accurate robot demonstrations' is unsupported by any metrics (e.g., temporal consistency scores, morphological error measures), baselines, ablations, or implementation details. Without this evidence, the soundness of the core contribution cannot be evaluated.
- [Method] Method description (dual contrastive objective): The factorization into task and embodiment spaces relies solely on minimizing mutual information between latents and maximizing intra-space consistency on unpaired human/robot videos. No explicit cross-embodiment invariance signal exists (no paired examples of the same task under both embodiments), so it is unclear whether the resulting codes will be invariant to kinematics changes; this directly undermines the guarantee that swapping embodiment codes yields morphologically correct robot motion.
minor comments (1)
- [Abstract and Method] The abstract and method overview would benefit from explicit equations for the dual contrastive losses and the adapter injection mechanism to clarify the implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the two major comments point by point below, outlining the revisions we will implement to improve clarity and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experiments show our approach generates temporally consistent and morphologically accurate robot demonstrations' is unsupported by any metrics (e.g., temporal consistency scores, morphological error measures), baselines, ablations, or implementation details. Without this evidence, the soundness of the core contribution cannot be evaluated.
Authors: We agree that the abstract claim requires explicit quantitative backing for proper evaluation. The full manuscript presents qualitative video results and initial consistency checks, but to directly address this, we will revise the abstract to reference specific metrics (e.g., optical-flow-based temporal consistency and keypoint-based morphological error) and add a dedicated experiments subsection with baselines, ablations, and implementation details. These changes will be incorporated in the revised version. revision: yes
-
Referee: [Method] Method description (dual contrastive objective): The factorization into task and embodiment spaces relies solely on minimizing mutual information between latents and maximizing intra-space consistency on unpaired human/robot videos. No explicit cross-embodiment invariance signal exists (no paired examples of the same task under both embodiments), so it is unclear whether the resulting codes will be invariant to kinematics changes; this directly undermines the guarantee that swapping embodiment codes yields morphologically correct robot motion.
Authors: The dual contrastive objective is intended to induce the required invariance implicitly from unpaired data. Minimizing mutual information between the two latent spaces across mixed human and robot videos encourages the task latent to discard embodiment-specific kinematics, while maximizing intra-task consistency pulls representations of the same task together regardless of embodiment. This contrastive signal, applied over diverse unpaired examples, enables the subsequent swapping to produce morphologically accurate outputs. We will expand the method section with additional intuition, a worked example of the loss terms, and supporting ablation analysis to make this mechanism explicit. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents a generative framework that factorizes videos into task and embodiment latents via an explicitly designed dual contrastive objective (MI minimization plus intra-space consistency maximization) followed by adapter-based injection into a frozen diffusion model. This is a procedural definition of the method rather than a derivation in which any claimed result or prediction reduces by construction to its own inputs, a fitted parameter, or a self-citation chain. No load-bearing self-citations, uniqueness theorems, or renamings of known results appear in the provided text. The central claims rest on the empirical behavior of the proposed losses on unpaired data, which is an independent modeling choice and not tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- adapter parameters
axioms (1)
- domain assumption Task-relevant information and embodiment-specific kinematics can be represented as independent orthogonal latent factors
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Bahety, A., Mandikal, P., Abbatematteo, B., and Mart ´ın- Mart´ın, R. Screwmimic: Bimanual imitation from hu- man videos with screw space projection.arXiv preprint arXiv:2405.03666,
-
[3]
Hot3d: Hand and object tracking in 3d from egocentric multi-view videos, 2025
Banerjee, P., Shkodrani, S., Moulon, P., Hampali, S., Han, S., Zhang, F., Zhang, L., Fountain, J., Miller, E., Basol, S., et al. Hot3d: Hand and object tracking in 3d from egocen- tric multi-view videos.arXiv preprint arXiv:2411.19167,
-
[4]
Improving image generation with better captions.Computer Sci- ence
Ouyang, L., Zhuang, J., Lee, J., Guo, Y ., et al. Improving image generation with better captions.Computer Sci- ence. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3): 8, 2023
2023
-
[4]
URL https://arxiv.org/abs/2412.19437. Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), ...
work page internal anchor Pith review arXiv 2019
-
[5]
Video depth anything: Consistent depth estimation for super-long videos
Chen, S., Guo, H., Zhu, S., Zhang, F., Huang, Z., Feng, J., and Kang, B. Video depth anything: Consistent depth estimation for super-long videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 22831–22840, 2025
2025
-
[5]
Gigahands: A massive annotated dataset of bimanual hand activities.arXiv preprint arXiv:2412.04244,
Fu, R., Zhang, D., Jiang, A., Fu, W., Funk, A., Ritchie, D., and Sridhar, S. Gigahands: A massive annotated dataset of bimanual hand activities.arXiv preprint arXiv:2412.04244,
-
[6]
Club: a contrastive log-ratio upper bound of mutual information
Cheng, P., Hao, W., Dai, S., Liu, J., Gan, Z., and Carin, L. Club: a contrastive log-ratio upper bound of mutual information. InProceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020
2020
-
[6]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video,
Hoque, R., Huang, P., Yoon, D. J., Sivapurapu, M., and Zhang, J. Egodex: Learning dexterous manipula- tion from large-scale egocentric video.arXiv preprint arXiv:2505.11709,
-
[7]
The trimmed iterative closest point algorithm
Chetverikov, D., Svirko, D., Stepanov, D., and Krsek, P. The trimmed iterative closest point algorithm. In2002 Inter- national Conference on Pattern Recognition, volume 3, pp. 545–548. IEEE, 2002
2002
-
[7]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Hu, Y ., Guo, Y ., Wang, P., Chen, X., Wang, Y .-J., Zhang, J., Sreenath, K., Lu, C., and Chen, J. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803,
work page internal anchor Pith review arXiv
-
[8]
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y ., and Liu, Y . Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598,
-
[9]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186, 2019
2019
-
[9]
Egomimic: Scaling imitation learning via egocentric video, 2024
9 Submission and Formatting Instructions for ICML 2026 Kareer, S., Patel, D., Punamiya, R., Mathur, P., Cheng, S., Wang, C., Hoffman, J., and Xu, D. Egomimic: Scal- ing imitation learning via egocentric video, 2024.URL https://arxiv. org/abs/2410.24221. Kim, H., Kang, J., Kang, H., Cho, M., Kim, S. J., and Lee, Y . Uniskill: Imitating human videos via cro...
-
[10]
J., and Hilliges, O
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M. J., and Hilliges, O. Arctic: A dataset for dexterous bimanual hand-object manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12943–12954, 2023
2023
- [10]
-
[11]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
URLhttps://arxiv.org/abs/2506.15742. Lepert, M., Fang, J., and Bohg, J. Masquerade: Learning from in-the-wild human videos using data-editing.arXiv preprint arXiv:2508.09976, 2025a. Lepert, M., Fang, J., and Bohg, J. Phantom: Training robots without robots using only human videos.arXiv preprint arXiv:2503.00779, 2025b. Li, G., Lyu, Y ., Liu, Z., Hou, C., ...
work page internal anchor Pith review arXiv
-
[12]
The” something something” video database for learning and evaluating visual com- mon sense
Goyal, R., Ebrahimi Kahou, S., Michalski, V ., Materzynska, J., Westphal, S., Kim, H., Haenel, V ., Fruend, I., Yianilos, P., Mueller-Freitag, M., et al. The” something something” video database for learning and evaluating visual com- mon sense. InProceedings of the IEEE international conference on computer vision, pp. 5842–5850, 2017
2017
-
[12]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review arXiv
-
[13]
Ego4d: Around the world in 3,000 hours of egocentric video
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Hamburger, J., Jiang, H., Liu, M., Liu, X., et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pp. 18995–19012, 2022
2022
-
[13]
Nasiriany, S., Kirmani, S., Ding, T., Smith, L., Zhu, Y ., Driess, D., Sadigh, D., and Xiao, T. Rt-affordance: Af- fordances are versatile intermediate representations for robot manipulation.arXiv preprint arXiv:2411.02704,
-
[14]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review arXiv
-
[15]
R+ x: Retrieval and execution from everyday human videos
Papagiannis, G., Di Palo, N., Vitiello, P., and Johns, E. R+ x: Retrieval and execution from everyday human videos. arXiv preprint arXiv:2407.12957,
-
[16]
Vbench: Compre- hensive benchmark suite for video generative models
Huang, Z., He, Y ., Yu, J., Zhang, F., Si, C., Jiang, Y ., Zhang, Y ., Wu, T., Jin, Q., Chanpaisit, N., et al. Vbench: Compre- hensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21807–21818, 2024
2024
-
[16]
Learning to transfer human hand skills for robot manipulations.arXiv preprint arXiv:2501.04169,
Park, S., Lee, S., Choi, M., Lee, J., Kim, J., Kim, J., and Joo, H. Learning to transfer human hand skills for robot manipulations.arXiv preprint arXiv:2501.04169,
-
[17]
Dreamgen: Unlocking generalization in robot learning through neural trajectories.arXiv e-prints, pp
Jang, J., Ye, S., Lin, Z., Xiang, J., Bjorck, J., Fang, Y ., Hu, F., Huang, S., Kundalia, K., Lin, Y .-C., et al. Dreamgen: Unlocking generalization in robot learning through neural trajectories.arXiv e-prints, pp. arXiv–2505, 2025
2025
-
[17]
Humanoid policy˜ human policy,
Qiu, R.-Z., Yang, S., Cheng, X., Chawla, C., Li, J., He, T., Yan, G., Yoon, D. J., Hoque, R., Paulsen, L., et al. Humanoid policy˜ human policy.arXiv preprint arXiv:2503.13441,
-
[18]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V ., Hu, Y .-T., Hu, R., Ryali, C., Ma, T., Khedr, H., R ¨adle, R., Rolland, C., Gustafson, L., et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review arXiv
-
[19]
10 Submission and Formatting Instructions for ICML 2026 Tu, Y ., Luo, H., Chen, X., Ji, S., Bai, X., and Zhao, H. Videoanydoor: High-fidelity video object insertion with precise motion control.arXiv preprint arXiv:2501.01427,
-
[20]
Kim, H., Kang, J., Kang, H., Cho, M., Kim, S. J., and Lee, Y . Uniskill: Imitating human videos via cross-embodiment skill representations.arXiv preprint arXiv:2505.08787, 2025
-
[20]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., and Gelly, S. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717,
work page internal anchor Pith review arXiv
-
[21]
Mimicplay: Long- horizon imitation learning by watching hu- man play
Wang, C., Fan, L., Sun, J., Zhang, R., Fei-Fei, L., Xu, D., Zhu, Y ., and Anandkumar, A. Mimicplay: Long- horizon imitation learning by watching human play.arXiv preprint arXiv:2302.12422,
-
[22]
Motion inversion for video customization
Wang, L., Mai, Z., Shen, G., Liang, Y ., Tao, X., Wan, P., Zhang, D., Li, Y ., and Chen, Y .-C. Motion inversion for video customization. InProceedings of the Special Inter- est Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pp. 1–12, 2025a. Wang, X., Zhang, S., Tang, L., Zhang, Y ., Gao, C., Wang, Y ., and Sang, N. ...
-
[23]
Lepert, M., Fang, J., and Bohg, J. Masquerade: Learning from in-the-wild human videos using data-editing.arXiv preprint arXiv:2508.09976, 2025a
-
[23]
Wei, Y ., Zhang, S., Qing, Z., Yuan, H., Liu, Z., Liu, Y ., Zhang, Y ., Zhou, J., and Shan, H. Dreamvideo: Com- posing your dream videos with customized subject and motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6537– 6549, 2024a. Wei, Z., Xu, Z., Guo, J., Hou, Y ., Gao, C., Cai, Z., Luo, J., and Shao, L. ...
-
[24]
Lepert, M., Fang, J., and Bohg, J. Phantom: Training robots without robots using only human videos.arXiv preprint arXiv:2503.00779, 2025b
-
[24]
URLhttps://arxiv.org/abs/2508.02324. Wu, W., Li, Z., Gu, Y ., Zhao, R., He, Y ., Zhang, D. J., Shou, M. Z., Li, Y ., Gao, T., and Zhang, D. Draganything: Motion control for anything using entity representation. InEuropean Conference on Computer Vision, pp. 331–
work page internal anchor Pith review arXiv
-
[25]
Li, G., Lyu, Y ., Liu, Z., Hou, C., Zhang, J., and Zhang, S. H2r: A human-to-robot data augmentation for robot pre- training from videos.arXiv preprint arXiv:2505.11920, 2025a
-
[25]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y ., Hong, W., Zhang, X., Feng, G., et al. Cogvideox: Text-to-video diffusion models with an ex- pert transformer.arXiv preprint arXiv:2408.06072,
work page internal anchor Pith review arXiv
-
[26]
Li, S., Gao, Y ., Sadigh, D., and Song, S. Unified video action model.arXiv preprint arXiv:2503.00200, 2025b
work page internal anchor Pith review arXiv
-
[26]
Latent Action Pretraining from Videos
Ye, S., Jang, J., Jeon, B., Joo, S., Yang, J., Peng, B., Mandlekar, A., Tan, R., Chao, Y .-W., Lin, B. Y ., et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758,
-
[27]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., and Zhu, J. Rdt-1b: a diffusion founda- tion model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024a
work page internal anchor Pith review arXiv
-
[27]
Ye, W., Liu, F., Ding, Z., Gao, Y ., Rybkin, O., and Abbeel, P. Video2policy: Scaling up manipulation tasks in simulation through internet videos.arXiv preprint arXiv:2502.09886,
-
[28]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review arXiv 2022
-
[28]
Dragnuwa: Fine-grained control in video generation by integrating text, image, and trajectory
Yin, S., Wu, C., Liang, J., Shi, J., Li, H., Ming, G., and Duan, N. Dragnuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089,
-
[29]
One-shot imita- tion learning with invariance matching for robotic ma- nipulation, 2024
Zhang, X. and Boularias, A. One-shot imitation learning with invariance matching for robotic manipulation.arXiv preprint arXiv:2405.13178,
-
[30]
Follow your pose: Pose-guided text-to-video generation using pose-free videos
Chen, Q. Follow your pose: Pose-guided text-to-video generation using pose-free videos. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 4117–4125, 2024
2024
-
[30]
Zhang, Y ., Gu, J., Wang, L.-W., Wang, H., Cheng, J., Zhu, Y ., and Zou, F. Mimicmotion: High-quality human mo- tion video generation with confidence-aware pose guid- ance.arXiv preprint arXiv:2406.19680,
-
[31]
G., and Li, Z
Du, Y ., Thuruthel, T. G., and Li, Z. Towards generalist robot learning from internet video: A survey.Journal of Artificial Intelligence Research, 83, 2025
2025
-
[31]
Z., Zhang, D
11 Submission and Formatting Instructions for ICML 2026 Zhao, R., Gu, Y ., Wu, J. Z., Zhang, D. J., Liu, J.-W., Wu, W., Keppo, J., and Shou, M. Z. Motiondirector: Mo- tion customization of text-to-video diffusion models. In European Conference on Computer Vision, pp. 273–290. Springer,
2026
-
[32]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T. Z., Kumar, V ., Levine, S., and Finn, C. Learn- ing fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705,
work page internal anchor Pith review arXiv
-
[33]
Zhu, Y ., Lim, A., Stone, P., and Zhu, Y . Vision-based manipulation from single human video with open-world object graphs.arXiv preprint arXiv:2405.20321,
-
[34]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0
Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 6892–6903. IEEE, 2024
2024
-
[34]
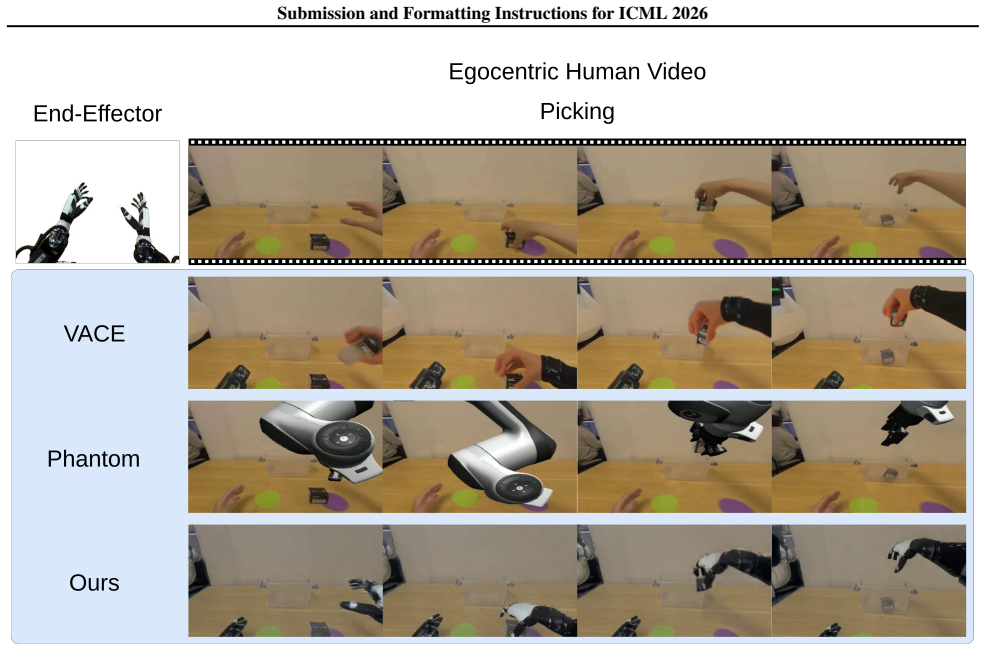
12 Submission and Formatting Instructions for ICML 2026 Figure 5.Qualitative comparison of cross-embodiment video editing on the ‘grasping a plastic bottle’ task. A. CLUB Variational Model Details To implement the mutual information minimization via the CLUB estimator, we employ a variational approximation qϕ(zemb|ztask) parameterized by a Multi-Layer Per...
2026
-
[38]
Learning transferable visual models from natural language supervision
Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pp. 8748–8763. PmLR, 2021
2021
-
[39]
Matena, M., Zhou, Y ., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21 (140):1–67, 2020
2020
-
[43]
W., Myers, V ., Kim, M
Hansen-Estruch, P., He, A. W., Myers, V ., Kim, M. J., Du, M., et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pp. 1723–1736. PMLR, 2023
2023
-
[46]
C., Sheikh, H
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P. Image quality assessment: from error visibility to struc- tural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[48]
Vidman: Exploiting implicit dynamics from video diffusion model for effective robot manipulation
Liang, X. Vidman: Exploiting implicit dynamics from video diffusion model for effective robot manipulation. Advances in Neural Information Processing Systems, 37: 41051–41075, 2024
2024
-
[50]
J., Shou, M
Wu, W., Li, Z., Gu, Y ., Zhao, R., He, Y ., Zhang, D. J., Shou, M. Z., Li, Y ., Gao, T., and Zhang, D. Draganything: Motion control for anything using entity representation. InEuropean Conference on Computer Vision, pp. 331– 348. Springer, 2024
2024
-
[55]
A., Shechtman, E., and Wang, O
Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 586–595, 2018
2018
-
[58]
Motionpro: A precise motion controller for image-to-video generation
Zhang, Z., Long, F., Qiu, Z., Pan, Y ., Liu, W., Yao, T., and Mei, T. Motionpro: A precise motion controller for image-to-video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 27957–27967, 2025. 11 Submission and Formatting Instructions for ICML 2026
2025
-
[59]
Z., Zhang, D
Zhao, R., Gu, Y ., Wu, J. Z., Zhang, D. J., Liu, J.-W., Wu, W., Keppo, J., and Shou, M. Z. Motiondirector: Mo- tion customization of text-to-video diffusion models. In European Conference on Computer Vision, pp. 273–290. Springer, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.