Recognition: 2 theorem links
· Lean TheoremDiffusion Masked Pretraining for Dynamic Point Cloud
Pith reviewed 2026-05-12 03:44 UTC · model grok-4.3
The pith
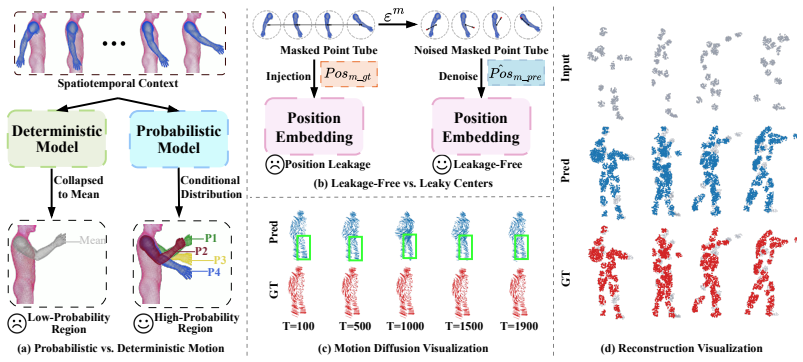
DiMP applies diffusion to masked tube centers and inter-frame displacements to remove positional leakage and model full motion distributions in dynamic point cloud pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose Diffusion Masked Pretraining (DiMP), a self-supervised framework that introduces diffusion modeling into both positional inference and motion learning for dynamic point clouds. It applies forward diffusion noise exclusively to masked tube centers and predicts the clean centers from visible spatio-temporal context, thereby removing positional leakage while retaining clean temporal anchors. It further recasts point-wise inter-frame displacement supervision as a DDPM noise-prediction objective conditioned on decoded representations, driving the encoder to capture the full conditional distribution of motions rather than collapsing to deterministic means.
What carries the argument
Diffusion applied selectively to masked tube centers for positional inference combined with DDPM noise-prediction for conditioned inter-frame displacements.
If this is right
- Encoder representations transfer to offline action segmentation with an absolute accuracy gain of 11.21 percent over the backbone alone.
- Performance improves by 13.65 percent under causally constrained online inference settings.
- Visible coordinates remain clean temporal anchors because diffusion noise is applied only to masked centers.
- The encoder learns the full conditional distribution of plausible inter-frame motions instead of single deterministic estimates.
- The same unified framework supports both positional and motion objectives without separate proxy targets.
Where Pith is reading between the lines
- The same selective-diffusion pattern could be tested on masked pretraining for video or skeleton sequences where positional leakage is also common.
- Tasks that explicitly require uncertainty estimates, such as future trajectory prediction, might show larger benefits from the distributional motion objective than classification tasks.
- Running DiMP on point-cloud datasets with varying density or longer temporal spans would test whether the leakage and distribution fixes remain effective at scale.
- If the gains prove robust, DiMP-style pretraining could reduce the amount of labeled data needed for fine-tuning dynamic point cloud models.
Load-bearing premise
The downstream gains are caused specifically by the diffusion-based removal of leakage and the modeling of motion distributions rather than by other differences in training setup or dataset effects.
What would settle it
An ablation experiment that keeps all other training details fixed but reintroduces direct ground-truth positional embeddings or switches back to deterministic mean targets for displacements, showing that the reported accuracy gains disappear.
Figures





read the original abstract
Dynamic point cloud pretraining is still dominated by masked reconstruction objectives. However, these objectives inherit two key limitations. Existing methods inject ground-truth tube centers as decoder positional embeddings, causing spatio-temporal positional leakage. Moreover, they supervise inter-frame motion with deterministic proxy targets that systematically discard distributional structure by collapsing multimodal trajectory uncertainty into conditional means. To address these limitations, we propose Diffusion Masked Pretraining (DiMP), a unified self-supervised framework for dynamic point clouds. DiMP introduces diffusion modeling into both positional inference and motion learning. It first applies forward diffusion noise only to masked tube centers, then predicts clean centers from visible spatio-temporal context. This removes positional leakage while preserving visible coordinates as clean temporal anchors. DiMP also reformulates point-wise inter-frame displacement supervision as a DDPM noise-prediction objective conditioned on decoded representations. This design drives the encoder to target the full conditional distribution of plausible motions under a variational surrogate, rather than collapsing to a single deterministic estimate. Extensive experiments demonstrate that DiMP consistently improves downstream accuracy over the backbone alone, with absolute gains of 11.21% on offline action segmentation and 13.65% under causally constrained online inference.Codes are available at https://github.com/InitalZ/DiMP.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Diffusion Masked Pretraining (DiMP), a self-supervised framework for dynamic point clouds that integrates diffusion modeling into masked pretraining. It applies forward diffusion only to masked tube centers and predicts clean centers from visible spatio-temporal context to eliminate positional leakage while retaining clean anchors. It further reformulates point-wise inter-frame displacement learning as a conditioned DDPM noise-prediction objective to capture the full conditional motion distribution rather than collapsing to deterministic means. Experiments report absolute gains of 11.21% on offline action segmentation and 13.65% under causally constrained online inference relative to the backbone alone, with code released at https://github.com/InitalZ/DiMP.git.
Significance. If the reported gains can be isolated to the diffusion-based positional inference and noise-prediction components, the work offers a principled way to address leakage and distributional collapse in dynamic point cloud pretraining, which could improve representations for downstream video and 3D tasks. The release of reproducible code is a clear strength that supports verification and extension.
major comments (1)
- [Abstract and Experiments] Abstract and Experiments section: The headline claim attributes the 11.21% offline and 13.65% online gains specifically to the diffusion positional inference (removing leakage while preserving visible anchors) and the DDPM noise-prediction objective (modeling full conditional motion distributions). No description is given of matched ablations that hold optimizer schedule, total epochs, data augmentations, decoder architecture, and loss weighting fixed while toggling only these two diffusion elements. Without such controls, the improvements cannot be confidently attributed to the proposed components rather than incidental training differences.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific backbone architecture and the datasets used for the reported action segmentation results to allow immediate assessment of the scope of the gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript to provide tighter experimental controls.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The headline claim attributes the 11.21% offline and 13.65% online gains specifically to the diffusion positional inference (removing leakage while preserving visible anchors) and the DDPM noise-prediction objective (modeling full conditional motion distributions). No description is given of matched ablations that hold optimizer schedule, total epochs, data augmentations, decoder architecture, and loss weighting fixed while toggling only these two diffusion elements. Without such controls, the improvements cannot be confidently attributed to the proposed components rather than incidental training differences.
Authors: We thank the referee for this important observation on experimental rigor. Our current backbone baseline employs the identical architecture, optimizer schedule, epoch count, data augmentations, decoder design, and loss weighting as DiMP; the sole difference is the pretraining objective (standard masked reconstruction versus our diffusion positional inference plus DDPM noise prediction). This already isolates the effect of the two diffusion components. To provide the requested matched ablations that toggle only these elements, we will add new tables in the revised Experiments section that independently enable/disable the diffusion positional inference and the conditioned DDPM motion objective while freezing all other training details. These results will confirm that the reported gains arise from the proposed diffusion modeling. revision: yes
Circularity Check
DiMP proposes independent diffusion objectives with no self-referential derivation chain
full rationale
The paper introduces a new self-supervised pretraining framework that augments masked reconstruction with forward diffusion on masked tube centers and DDPM noise prediction on displacements. No equations, parameters, or claims reduce the reported downstream gains (11.21% offline, 13.65% online) to quantities defined by construction from the same paper's fitted inputs or prior self-citations. The method is presented as an empirical training paradigm whose benefits are measured on downstream tasks rather than derived tautologically from its own definitions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DiMP introduces diffusion modeling into both positional inference and motion learning... reformulates point-wise inter-frame displacement supervision as a DDPM noise-prediction objective
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
applies forward diffusion noise only to masked tube centers... predicts clean centers from visible spatio-temporal context
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[2]
Masked autoencoders for point cloud self-supervised learning
Yatian Pang, Wenxiao Wang, Francis EH Tay, Wei Liu, Yonghong Tian, and Li Yuan. Masked autoencoders for point cloud self-supervised learning. InEuropean Conference on Computer Vision (ECCV), 2022
work page 2022
-
[3]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[4]
Hyperpoint: Multimodal 3d foundation model in hyperbolic space.Pattern Recognition (PR), 2025
Yiding Sun, Haozhe Cheng, Chaoyi Lu, Zhengqiao Li, Minghong Wu, Huimin Lu, and Jihua Zhu. Hyperpoint: Multimodal 3d foundation model in hyperbolic space.Pattern Recognition (PR), 2025
work page 2025
-
[5]
Pointdico: Contrastive 3d representation learning guided by diffusion models
Pengbo Li, Yiding Sun, and Haozhe Cheng. Pointdico: Contrastive 3d representation learning guided by diffusion models. In2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 2025
work page 2025
-
[6]
Point cloud pre-training with diffusion models
Xiao Zheng, Xiaoshui Huang, Guofeng Mei, Yuenan Hou, Zhaoyang Lyu, Bo Dai, Wanli Ouyang, and Yongshun Gong. Point cloud pre-training with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[7]
Diffpmae: diffusion masked autoen- coders for point cloud reconstruction
Yanlong Li, Chamara Madarasingha, and Kanchana Thilakarathna. Diffpmae: diffusion masked autoen- coders for point cloud reconstruction. InProceedings of the European Conference on Computer Vision (ECCV). Springer, 2024
work page 2024
-
[8]
Point-madi: Masked autoencoding with diffusion for point cloud pre-training
Xiaoyang Xiao, Runzhao Yao, Zhiqiang Tian, and Shaoyi Du. Point-madi: Masked autoencoding with diffusion for point cloud pre-training. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[9]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems (NeurIPS), 2020
work page 2020
-
[10]
Representation learning by detecting incorrect location embeddings
Sepehr Sameni, Simon Jenni, and Paolo Favaro. Representation learning by detecting incorrect location embeddings. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2023
work page 2023
-
[11]
Haochen Wang, Junsong Fan, Yuxi Wang, Kaiyou Song, Tong Wang, and ZHAO-XIANG ZHANG. Droppos: Pre-training vision transformers by reconstructing dropped positions.Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[12]
Location-aware self-supervised transformers for semantic segmentation
Mathilde Caron, Neil Houlsby, and Cordelia Schmid. Location-aware self-supervised transformers for semantic segmentation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024
work page 2024
-
[13]
Align then Adapt: Rethinking Parameter-Efficient Transfer Learning in 4D Perception
Yiding Sun, Jihua Zhu, Haozhe Cheng, Chaoyi Lu, Zhichuan Yang, Lin Chen, and Yaonan Wang. Align then adapt: Rethinking parameter-efficient transfer learning in 4d perception.arXiv preprint arXiv:2602.23069, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Masked spatio-temporal structure prediction for self-supervised learning on point cloud videos
Zhiqiang Shen, Xiaoxiao Sheng, Hehe Fan, Longguang Wang, Yulan Guo, Qiong Liu, Hao Wen, and Xi Zhou. Masked spatio-temporal structure prediction for self-supervised learning on point cloud videos. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[15]
Masked motion prediction with semantic contrast for point cloud sequence learning
Yuehui Han, Can Xu, Rui Xu, Jianjun Qian, and Jin Xie. Masked motion prediction with semantic contrast for point cloud sequence learning. InProceedings of the European Conference on Computer Vision (ECCV). Springer, 2024
work page 2024
-
[16]
Social GAN: Socially acceptable trajectories with generative adversarial networks
Agrim Gupta, Justin Johnson, Li Fei-Fei, Silvio Savarese, and Alexandre Alahi. Social GAN: Socially acceptable trajectories with generative adversarial networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[17]
Trajectron++: Dynamically- feasible trajectory forecasting with heterogeneous data
Tim Salzmann, Boris Ivanovic, Punarjay Chakravarty, and Marco Pavone. Trajectron++: Dynamically- feasible trajectory forecasting with heterogeneous data. InProceedings of the European Conference on Computer Vision (ECCV). Springer, 2020
work page 2020
-
[18]
Qi, Leonidas Guibas, and Or Litany
Saining Xie, Jiatao Gu, Demi Guo, Charles R. Qi, Leonidas Guibas, and Or Litany. Pointcontrast: Unsupervised pre-training for 3D point cloud understanding. InProceedings of the European Conference on Computer Vision (ECCV). Springer, 2020. 10
work page 2020
-
[19]
Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding
Mohamed Afham, Isuru Dissanayake, Dinithi Dissanayake, Amaya Dharmasiri, Kanchana Thilakarathna, and Ranga Rodrigo. Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[20]
Point-M2AE: Multi-scale masked autoencoders for hierarchical point cloud pre-training
Renrui Zhang, Ziyu Guo, Peng Gao, Rongyao Fang, Bin Zhao, Dong Wang, Yu Qiao, and Hongsheng Li. Point-M2AE: Multi-scale masked autoencoders for hierarchical point cloud pre-training. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[21]
Learning 3d representations from 2d pre-trained models via image-to-point masked autoencoders
Renrui Zhang, Liuhui Wang, Yu Qiao, Peng Gao, and Hongsheng Li. Learning 3d representations from 2d pre-trained models via image-to-point masked autoencoders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[22]
Dongxu Zhang, Yiding Sun, Pengcheng Li, Yumou Liu, Hongqiang Lin, Haoran Xu, Xiaoxuan Mu, Liang Lin, Wenbiao Yan, Ning Yang, et al. Pointcot: A multi-modal benchmark for explicit 3d geometric reasoning.arXiv preprint arXiv:2602.23945, 2026
-
[23]
Yankai Wang, Yiding Sun, Qirui Wang, Pengbo Li, Chaoyi Lu, and Dongxu Zhang. Pointrft: Explicit reinforcement fine-tuning for point cloud few-shot learning.arXiv preprint arXiv:2603.23957, 2026
-
[24]
Contrast with reconstruct: Contrastive 3d representation learning guided by generative pretraining
Zekun Qi, Runpei Dong, Guofan Fan, Zheng Ge, Xiangyu Zhang, Kaisheng Ma, and Li Yi. Contrast with reconstruct: Contrastive 3d representation learning guided by generative pretraining. InProceedings of the International Conference on Machine Learning (ICML). PMLR, 2023
work page 2023
-
[25]
Haiyan Wang, Liang Yang, Xuejian Rong, Jinglun Feng, and Yingli Tian. Self-supervised 4d spatio- temporal feature learning via order prediction of sequential point cloud clips. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021
work page 2021
-
[26]
Contrastive predictive autoencoders for dynamic point cloud self-supervised learning
Xiaoxiao Sheng, Zhiqiang Shen, and Gang Xiao. Contrastive predictive autoencoders for dynamic point cloud self-supervised learning. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2023
work page 2023
-
[27]
Pointcmp: Contrastive mask prediction for self-supervised learning on point cloud videos
Zhiqiang Shen, Xiaoxiao Sheng, Longguang Wang, Yulan Guo, Qiong Liu, and Xi Zhou. Pointcmp: Contrastive mask prediction for self-supervised learning on point cloud videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[28]
Xiaoxiao Sheng, Zhiqiang Shen, Gang Xiao, Longguang Wang, Yulan Guo, and Hehe Fan. Point contrastive prediction with semantic clustering for self-supervised learning on point cloud videos. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[29]
Zhi Zuo, Chenyi Zhuang, Pan Gao, Jie Qin, Hao Feng, and Nicu Sebe. Uni4d: A unified self-supervised learning framework for point cloud videos.arXiv preprint arXiv:2504.04837, 2025
-
[30]
Point 4d transformer networks for spatio-temporal modeling in point cloud videos
Hehe Fan, Yi Yang, and Mohan Kankanhalli. Point 4d transformer networks for spatio-temporal modeling in point cloud videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[31]
Corrnet3d: Unsupervised end-to-end learning of dense correspondence for 3d point clouds
Yiming Zeng, Yue Qian, Zhiyu Zhu, Junhui Hou, Hui Yuan, and Ying He. Corrnet3d: Unsupervised end-to-end learning of dense correspondence for 3d point clouds. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[32]
Point primitive transformer for long-term 4d point cloud video understanding
Hao Wen, Yunze Liu, Jingwei Huang, Bo Duan, and Li Yi. Point primitive transformer for long-term 4d point cloud video understanding. InProceedings of the European Conference on Computer Vision (ECCV). Springer, 2022
work page 2022
-
[33]
Spatio-temporal self-supervised representation learning for 3d point clouds
Siyuan Huang, Yichen Xie, Song-Chun Zhu, and Yixin Zhu. Spatio-temporal self-supervised representation learning for 3d point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021
work page 2021
-
[34]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[35]
Complete-to-partial 4d distillation for self-supervised point cloud sequence representation learning
Zhuoyang Zhang, Yuhao Dong, Yunze Liu, and Li Yi. Complete-to-partial 4d distillation for self-supervised point cloud sequence representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 11
work page 2023
-
[36]
Pstnet: Point spatio-temporal convolution on point cloud sequences
Hehe Fan, Xin Yu, Yuhang Ding, Yi Yang, and Mohan Kankanhalli. Pstnet: Point spatio-temporal convolution on point cloud sequences. InProceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[37]
Hehe Fan, Yezhou Yang, and Mohan Kankanhalli. Point spatio-temporal transformer networks for point cloud video modeling.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022
work page 2022
-
[38]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[39]
Yunze Liu, Zifan Wang, Peiran Wu, and Jiayang Ao. Pointnet4d: A lightweight 4d point cloud video backbone for online and offline perception in robotic applications. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026
work page 2026
-
[40]
Yuhao Dong et al. Nsm4d: Neural scene model based online 4d point cloud sequence understanding.arXiv preprint arXiv:2310.08326, 2023
-
[41]
Hoi4d: A 4d egocentric dataset for category-level human-object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. Hoi4d: A 4d egocentric dataset for category-level human-object interaction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[42]
Action recognition based on a bag of 3d points
Wanqing Li, Zhengyou Zhang, and Zicheng Liu. Action recognition based on a bag of 3d points. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops). IEEE, 2010
work page 2010
-
[43]
Shrec’17 track: 3d hand gesture recognition using a depth and skeletal dataset
Quentin De Smedt, Hazem Wannous, Jean-Philippe Vandeborre, Joris Guerry, Bertrand Le Saux, and David Filliat. Shrec’17 track: 3d hand gesture recognition using a depth and skeletal dataset. InProceedings of the Eurographics Workshop on 3D Object Retrieval (3DOR), 2017
work page 2017
-
[44]
Pavlo Molchanov, Xiaodong Yang, Shalini Gupta, Kihwan Kim, Stephen Tyree, and Jan Kautz. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[45]
Boris Ivanovic and Marco Pavone. The trajectron: Probabilistic multi-agent trajectory modeling with dynamic spatiotemporal graphs. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 12 Appendix table of contents A Preliminaries 14 B Experimental details 14 C Additional ablation studies 15 D Additional experimental resu...
work page 2019
-
[46]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.