Recognition: unknown
AdapShot: Adaptive Many-Shot In-Context Learning with Semantic-Aware KV Cache Reuse
Pith reviewed 2026-05-07 16:34 UTC · model grok-4.3
The pith
AdapShot selects the optimal number of in-context examples for each query by measuring output entropy in a probe run and reuses KV cache with reordering to enable efficient many-shot learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
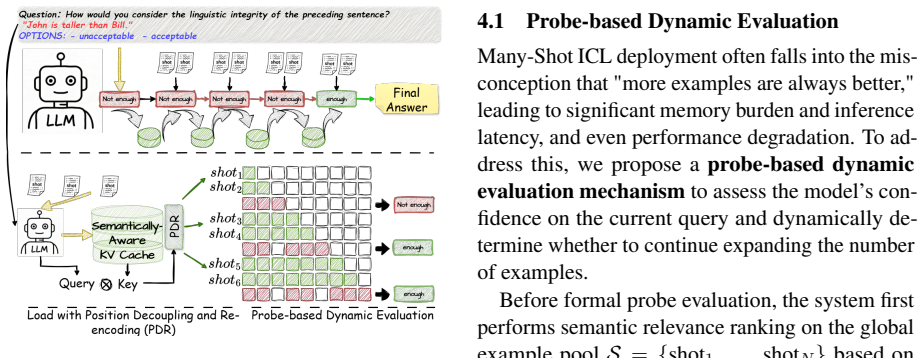
AdapShot dynamically optimizes shot counts using a probe-based evaluation with output entropy and employs a semantics-aware KV cache reuse strategy with decoupling and re-encoding to bypass redundant prefilling, achieving better performance and efficiency in many-shot in-context learning.
What carries the argument
Probe-based entropy evaluation for choosing shot count, together with decoupling and re-encoding to reorder cached key-value pairs for semantic-aware reuse.
If this is right
- Queries receive different numbers of shots according to their measured entropy rather than a single fixed value.
- Prefilling work is skipped for both probes and final inference by reusing and reordering existing KV pairs.
- Positional encoding incompatibilities are handled so that reordered cache entries remain compatible with the model.
- Overall inference becomes faster while average accuracy rises compared with static or prior adaptive baselines.
Where Pith is reading between the lines
- The entropy probe could serve as a lightweight signal for adapting other ICL choices such as example ordering or format.
- Similar decoupling techniques might reduce recomputation in other long-context tasks like retrieval-augmented generation.
- If the reordering preserves accuracy across model families, the method points toward query-adaptive prompting that requires no per-model tuning.
Load-bearing premise
Output entropy from a short probe run is a sufficient and unbiased signal for selecting the globally optimal shot count, and the decoupling-plus-re-encoding step for KV cache reordering introduces no accuracy degradation.
What would settle it
Measure whether accuracy using the entropy-selected shot count matches or exceeds the accuracy obtained by exhaustively testing several shot counts on the same query, or compare final accuracy when the KV cache is reordered versus when the entire context is recomputed from scratch.
Figures




read the original abstract
Many-Shot In-Context Learning (ICL) has emerged as a promising paradigm, leveraging extensive examples to unlock the reasoning potential of Large Language Models (LLMs). However, existing methods typically rely on a predetermined, fixed number of shots. This static approach often fails to adapt to the varying difficulty of different queries, leading to either insufficient context or interference from noise. Furthermore, the prohibitive computational and memory costs of long contexts severely limit Many-Shot's feasibility. To address the above limitations, we propose AdapShot, which dynamically optimizes shot counts and leverages KV cache reuse for efficient inference. Specifically, we design a probe-based evaluation mechanism that utilizes output entropy to determine the optimal number of shots. To bypass the redundant prefilling computation during both the probing and inference phases, we incorporate a semantics-aware KV cache reuse strategy. Within this reuse strategy, to address positional encoding incompatibilities, we introduce a decoupling and re-encoding method that enables the flexible reordering of cached key-value pairs. Extensive experiments demonstrate that AdapShot achieves an average performance gain of around 10% and a 4.64x speedup compared to state-of-the-art DBSA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdapShot for adaptive many-shot in-context learning in LLMs. It uses a probe-based mechanism that measures output entropy on a short run to dynamically select the per-query optimal shot count, combined with a semantic-aware KV cache reuse strategy. To handle positional encoding incompatibilities when reordering cached KV pairs, it introduces a decoupling step followed by re-encoding. The central empirical claim is an average ~10% performance improvement and 4.64x speedup relative to the state-of-the-art DBSA baseline.
Significance. If the reported gains are robust, the work would be a practically significant engineering contribution to making many-shot ICL feasible at scale by reducing both compute waste on easy queries and the cost of long-context prefilling. The combination of entropy-driven adaptation and KV-cache reordering addresses two real deployment bottlenecks. The manuscript receives credit for focusing on an empirical, reproducible-style engineering solution rather than purely theoretical claims.
major comments (3)
- [§3.2] §3.2 (Probe-based shot selection): The central performance claim rests on the assumption that output entropy from a short probe run is a sufficient and unbiased signal for the globally optimal shot count. No oracle comparison, failure-case analysis, or statistical test is provided showing that the entropy threshold reliably selects the shot count that would have been chosen by exhaustive search; if the probe is noisy or local, the reported 10% average gain cannot be attributed to the method.
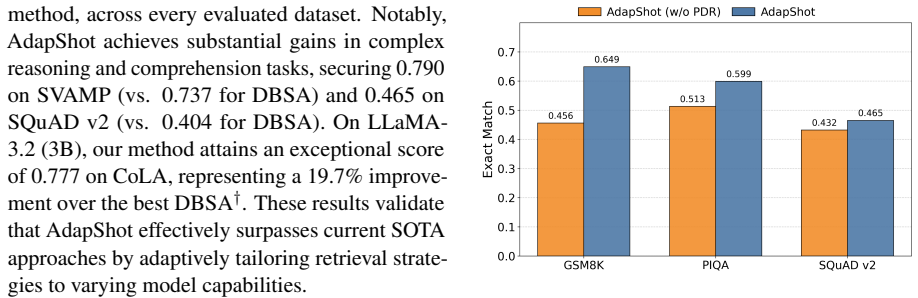
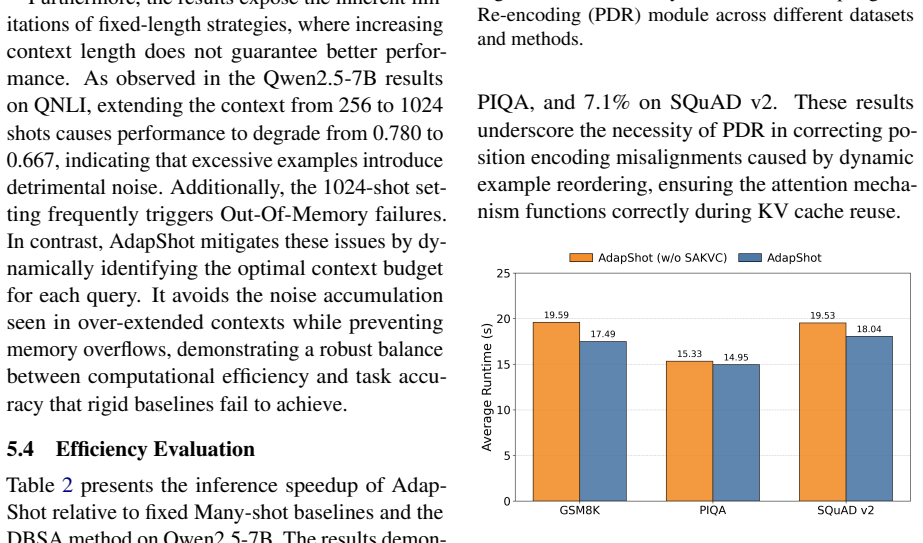
- [§3.3] §3.3 (Decoupling and re-encoding): The KV-cache reuse strategy claims to preserve model behavior after reordering via decoupling plus re-encoding. No ablation isolating the re-encoding step, no verification that attention scores and positional encodings remain equivalent post-reordering, and no measurement of accuracy degradation on the same queries are reported. This directly undermines attribution of both the accuracy gain and the 4.64x speedup to the proposed technique.
- [§4] §4 (Experiments): The experimental section reports aggregate gains versus DBSA but supplies no protocol details (random seeds, number of runs, exact prompt templates, dataset splits), no statistical significance tests, no full baseline list with hyper-parameters, and no ablation tables on the entropy threshold or re-encoding component. These omissions make the central claims unverifiable from the presented data.
minor comments (2)
- [Abstract] The acronym DBSA is used without an initial expansion or citation; a reference or definition should be added on first use.
- [§3.3] Figure captions for the KV-cache diagrams could more explicitly label the decoupling and re-encoding operations to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where additional analysis or details are needed to strengthen the claims, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Probe-based shot selection): The central performance claim rests on the assumption that output entropy from a short probe run is a sufficient and unbiased signal for the globally optimal shot count. No oracle comparison, failure-case analysis, or statistical test is provided showing that the entropy threshold reliably selects the shot count that would have been chosen by exhaustive search; if the probe is noisy or local, the reported 10% average gain cannot be attributed to the method.
Authors: We agree that direct validation of the probe's reliability against an oracle would strengthen attribution of the gains. The manuscript shows consistent outperformance over fixed-shot and DBSA baselines, with the entropy threshold chosen via validation-set tuning. In the revision we will add an oracle comparison on a query subset (exhaustive search for per-query optimal shots vs. probe selection), failure-case analysis, and correlation statistics between probe entropy and accuracy lift. These will appear in an expanded §3.2 and new Appendix C. revision: yes
-
Referee: [§3.3] §3.3 (Decoupling and re-encoding): The KV-cache reuse strategy claims to preserve model behavior after reordering via decoupling plus re-encoding. No ablation isolating the re-encoding step, no verification that attention scores and positional encodings remain equivalent post-reordering, and no measurement of accuracy degradation on the same queries are reported. This directly undermines attribution of both the accuracy gain and the 4.64x speedup to the proposed technique.
Authors: We acknowledge the need for explicit verification. The decoupling step removes positional information before semantic matching, and re-encoding restores compatibility. In the revised manuscript we will add an ablation isolating the re-encoding component, report attention-score distribution comparisons before/after reordering on representative queries, and measure accuracy on the same queries with and without the full reuse pipeline. Results will be placed in §3.3 and a new experimental table. revision: yes
-
Referee: [§4] §4 (Experiments): The experimental section reports aggregate gains versus DBSA but supplies no protocol details (random seeds, number of runs, exact prompt templates, dataset splits), no statistical significance tests, no full baseline list with hyper-parameters, and no ablation tables on the entropy threshold or re-encoding component. These omissions make the central claims unverifiable from the presented data.
Authors: We apologize for the missing protocol details. Experiments used 5 random seeds, standard dataset splits and default prompt templates from the source papers (MMLU, GSM8K, BBH, etc.). We will expand §4 with a dedicated Experimental Setup subsection containing all protocol information, baseline hyper-parameters, paired t-test results with p-values, and full ablation tables for the entropy threshold and re-encoding component. This will render the claims fully reproducible. revision: yes
Circularity Check
No circularity: empirical engineering contribution with independent experimental validation
full rationale
The paper presents AdapShot as an empirical system for adaptive many-shot ICL using an entropy-based probe for shot selection and a KV-cache reuse mechanism with decoupling/re-encoding. No derivation chain, equations, or first-principles results are claimed; performance gains (~10%) and speedups (4.64x) are reported solely from experiments against baselines like DBSA. The method does not define any quantity in terms of itself, rename fitted parameters as predictions, or rely on self-citations for load-bearing uniqueness theorems. The approach is self-contained as an engineering artifact whose claims rest on external benchmarks rather than internal reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Output entropy computed from a short probe run correlates with the number of shots that maximizes final-task accuracy.
- domain assumption Decoupling positional encodings and re-applying them to reordered KV pairs leaves the model's attention computation unchanged.
Reference graph
Works this paper leans on
-
[1]
Shantanu Acharya, Fei Jia, and Boris Ginsburg. 2024. Star attention: Efficient llm inference over long sequences. In Forty-second International Conference on Machine Learning
2024
-
[2]
Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, and 1 others. 2024. Many-shot in-context learning. Advances in Neural Information Processing Systems, 37:76930--76966
2024
-
[3]
Amanda Bertsch, Maor Ivgi, Emily Xiao, Uri Alon, Jonathan Berant, Matthew R Gormley, and Graham Neubig. 2025. In-context learning with long-context models: An in-depth exploration. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Paper...
2025
- [4]
-
[5]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
- [6]
- [7]
-
[8]
Zihan Chen, Song Wang, Zhen Tan, Jundong Li, and Cong Shen. 2025 b . Maple: Many-shot adaptive pseudo-labeling for in-context learning. In Forty-second International Conference on Machine Learning
2025
-
[9]
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. 2019. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509
work page internal anchor Pith review arXiv 2019
-
[10]
Shahriar Golchin, Yanfei Chen, Rujun Han, Manan Gandhi, Tianli Yu, Swaroop Mishra, Mihai Surdeanu, Rishabh Agarwal, Chen-Yu Lee, and Tomas Pfister. 2025. Towards compute-optimal many-shot in-context learning. In Second Conference on Language Modeling
2025
-
[11]
Zhengyao Gu, Henry Peng Zou, Aiwei Liu, Yankai Chen, Weizhi Zhang, and Philip S Yu. 2025. Scaling laws for many-shot in-context learning with self-generated annotations. In ICML 2025 Workshop on Long-Context Foundation Models
2025
-
[12]
Yinhan He, Wendy Zheng, Song Wang, Zaiyi Zheng, Yushun Dong, Yaochen Zhu, and Jundong Li. 2024. Hierarchical demonstration order optimization for many-shot in-context learning
2024
- [13]
- [14]
-
[15]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. Snapkv: Llm knows what you are looking for before generation. Advances in Neural Information Processing Systems, 37:22947--22970
2024
-
[16]
Akide Liu, Jing Liu, Zizheng Pan, Yefei He, Gholamreza Haffari, and Bohan Zhuang. 2024. Minicache: Kv cache compression in depth dimension for large language models. Advances in Neural Information Processing Systems, 37:139997--140031
2024
- [17]
-
[18]
Saeed Moayedpour, Alejandro Corrochano-Navarro, Faryad Sahneh, Alexander Koetter, Ji r \' Vym e tal, Lorenzo Kogler Anele, Pablo Mas, Yasser Jangjoo, Sizhen Li, Michael Bailey, and 1 others. 2024. Many-shot in-context learning for molecular inverse design. In ICML 2024 AI for Science Workshop
2024
-
[19]
Nir Ratner, Yoav Levine, Yonatan Belinkov, Ori Ram, Inbal Magar, Omri Abend, Ehud Karpas, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. Parallel context windows for large language models. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 6383--6402
2023
-
[20]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288
work page internal anchor Pith review arXiv 2023
-
[21]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30
2017
-
[22]
Xingchen Wan, Han Zhou, Ruoxi Sun, and Sercan O Arik. 2025. From few to many: Self-improving many-shot reasoners through iterative optimization and generation. In The Thirteenth International Conference on Learning Representations
2025
-
[23]
Haonan Wang, Qian Liu, Chao Du, Tongyao Zhu, Cunxiao Du, Kenji Kawaguchi, and Tianyu Pang. 2024. When precision meets position: Bfloat16 breaks down rope in long-context training. Transactions on Machine Learning Research
2024
-
[24]
Emily Xiao, Chin-Jou Li, Yilin Zhang, Graham Neubig, and Amanda Bertsch. 2025. https://doi.org/10.18653/v1/2025.acl-long.1542 Efficient many-shot in-context learning with dynamic block-sparse attention . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 31946--31958, Vienna, Austria. ...
-
[25]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2023. Efficient streaming language models with attention sinks. In The Twelfth International Conference on Learning Representations
2023
-
[26]
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. Hierarchical attention networks for document classification. In Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, pages 1480--1489
2016
-
[27]
Qingyu Yin, Xuzheng He, Chak Tou Leong, Fan Wang, Yanzhao Yan, Xiaoyu Shen, and Qiang Zhang. 2024. Deeper insights without updates: The power of in-context learning over fine-tuning. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4138--4151
2024
-
[28]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and 1 others. 2020. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33:17283--17297
2020
-
[29]
Jiaquan Zhang, Qigan Sun, Chaoning Zhang, Xudong Wang, Zhenzhen Huang, Yitian Zhou, Pengcheng Zheng, Chi-lok Andy Tai, Sung-Ho Bae, Zeyu Ma, and 1 others. 2026 a . Tda-rc: Task-driven alignment for knowledge-based reasoning chains in large language models. arXiv preprint arXiv:2604.04942
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [30]
- [31]
-
[32]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R \'e , Clark Barrett, and 1 others. 2023. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36:34661--34710
2023
- [33]
- [34]
-
[35]
Kaijian Zou, Muhammad Khalifa, and Lu Wang. 2025. On many-shot in-context learning for long-context evaluation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25605--25639
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.