Recognition: unknown
Doubly Robust Instrumented Difference-in-Differences
Pith reviewed 2026-05-07 04:14 UTC · model grok-4.3
The pith
This paper derives efficient influence functions to construct doubly robust estimators for the local average treatment effect on the treated in instrumented difference-in-differences designs with staggered instrument exposure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We study estimation of the local average treatment effect on the treated (LATT) in instrumented difference-in-differences (IDiD) designs with covariates and staggered instrument exposure. We derive the efficient influence function (EIF) of the target parameter in both panel and repeated cross-sections settings, allowing for two classes of control groups: never-exposed and not-yet-exposed. Building on the EIF, we construct doubly robust estimands and corresponding estimators from first principles. The resulting procedures are the IDiD analogues of the difference-in-differences (DiD) procedures targeting ATT rather than LATT. We further establish a Bloom-type result under one-sided compliance,
What carries the argument
Efficient influence function of the LATT parameter, from which doubly robust estimands and estimators are derived for panel and repeated cross-section IDiD data with never-exposed or not-yet-exposed controls.
If this is right
- Doubly robust estimators for LATT become available in panel data settings using either never-exposed or not-yet-exposed control groups.
- Equivalent doubly robust procedures apply directly to repeated cross-sections data.
- Under one-sided compliance and absorbing treatment, LATT equals a convex combination of exposure-cohort-specific ATT(g, t) parameters.
- Asymptotic normality holds under conditions on the remainder term together with Donsker or cross-fitting assumptions, including via double machine learning.
- Simulations confirm that the estimators retain double robustness and exhibit good finite-sample behavior.
Where Pith is reading between the lines
- The explicit mapping from LATT to standard ATT(g, t) parameters suggests that existing DiD software routines can be adapted with modest changes to produce instrumented analogues.
- Cross-fitting versions of the estimators open the door to high-dimensional nuisance estimation via modern machine learning without sacrificing robustness.
- Applied researchers can now compare instrumented and non-instrumented estimates of the same policy within one study to assess the role of compliance.
- The framework naturally extends to other staggered designs once the appropriate efficient influence function is obtained.
Load-bearing premise
Standard instrumented DiD identification conditions hold, including instrument validity and no anticipation, or at least one of the outcome regression or instrument propensity score is correctly specified.
What would settle it
A Monte Carlo simulation or empirical example with known true LATT in which the proposed doubly robust estimator fails to recover the parameter when both the outcome regression and the instrument propensity score are misspecified, yet succeeds when exactly one is correct.
Figures
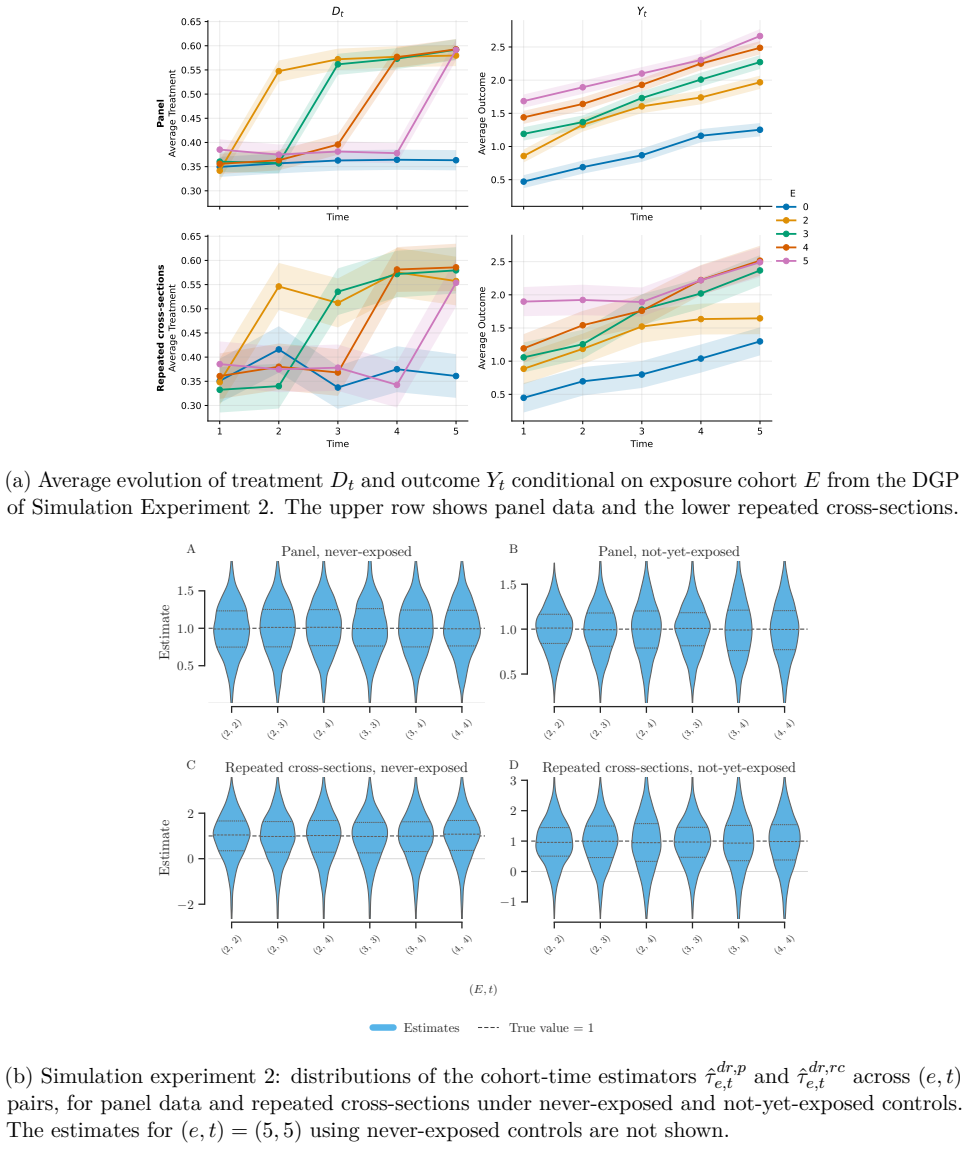

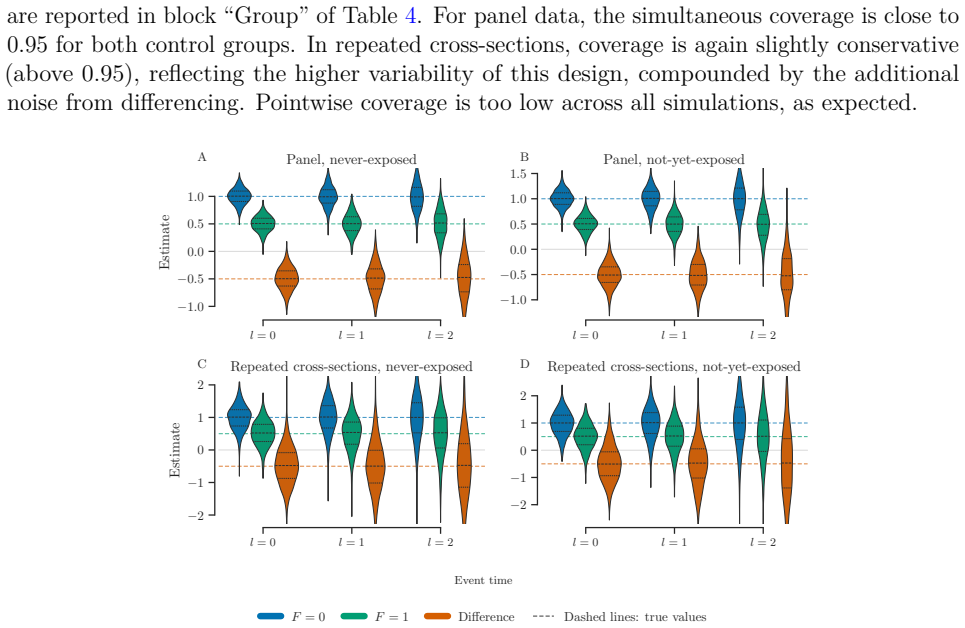

read the original abstract
We study estimation of the local average treatment effect on the treated ($LATT$) in instrumented difference-in-differences (IDiD) designs with covariates and staggered instrument exposure. We derive the efficient influence function (EIF) of the target parameter in both panel and repeated cross-sections settings, allowing for two classes of control groups: never-exposed and not-yet-exposed. Building on the EIF, we construct doubly robust estimands and corresponding estimators from first principles. The resulting procedures are the IDiD analogues of the difference-in-differences (DiD) procedures in Callaway and Sant'Anna (2021), targeting $LATT$ rather than $ATT$. We further establish a Bloom-type result under one-sided compliance and absorbing treatment, linking $LATT$ to a convex combination of exposure-cohort-specific $ATT(g, t)$ parameters, making the connection between IDiD and DiD explicit. Asymptotic properties are established under conditions on the remainder term and either Donsker conditions or via cross-fitting. We also construct double machine learning (DML) estimators for the $LATT$ in both data settings and show their equivalence to cross-fitted estimators. Simulations assess the double robustness and finite-sample performance of the proposed methods. An implementation is available in the Python package \texttt{idid}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives the efficient influence function (EIF) of the local average treatment effect on the treated (LATT) for instrumented difference-in-differences (IDiD) designs with covariates and staggered instrument exposure. It does so for both panel and repeated cross-section data, allowing never-exposed and not-yet-exposed control groups. From the EIF the authors construct doubly robust estimands and estimators, establish a Bloom-type result linking LATT to a convex combination of cohort-specific ATT(g,t) under one-sided compliance and absorbing treatment, prove asymptotic normality under remainder-term and Donsker/cross-fitting conditions, implement double machine learning estimators, and report Monte Carlo evidence on double robustness and finite-sample behavior. A Python package 'idid' is provided.
Significance. If the EIF derivations and remainder-term bounds hold, the paper supplies a practical, doubly robust toolkit that extends Callaway and Sant'Anna (2021) to instrumented staggered-adoption settings. The explicit Bloom-type decomposition is valuable for interpretation, and the double-robustness property is especially useful when either the outcome regression or the instrument propensity score can be modeled plausibly. The provision of reproducible code and simulation results strengthens the contribution for applied work in labor and development economics.
minor comments (5)
- [§2.1] §2.1: The target parameter LATT is defined verbally; an explicit integral or summation expression would help readers verify the subsequent EIF derivation.
- [§5.2] §5.2, Assumption 5: The remainder-term condition is stated at a high level; adding primitive conditions (e.g., for random forests or neural nets under cross-fitting) would make the asymptotic result more immediately usable.
- [Table 2] Table 2: Bias and RMSE are reported, but the table would be clearer if it also included Monte Carlo standard errors or coverage rates for the proposed confidence intervals.
- [References] References: The citation to Bloom (2009) for the Bloom-type result is present but the full reference entry should include the journal and DOI for completeness.
- [Abstract] Abstract and §1: The acronym 'IDiD' is introduced without spelling out 'instrumented difference-in-differences' on first use; this is a minor but standard clarity fix.
Simulated Author's Rebuttal
We thank the referee for their positive and accurate summary of our manuscript, as well as for recommending minor revision. The report correctly identifies the core contributions, including the EIF derivations for the LATT in staggered IDiD settings (both panel and repeated cross-section), the doubly robust estimators, the Bloom-type decomposition under one-sided compliance, and the DML implementation with accompanying code and simulations. No specific major comments were raised.
Circularity Check
Derivations proceed from first principles without reduction to inputs by construction
full rationale
The paper explicitly derives the EIF for the LATT parameter in IDiD settings from first principles for both panel and repeated cross-section data, allowing never-exposed and not-yet-exposed controls. It then constructs doubly robust estimands and estimators directly from that EIF, with asymptotics under standard Donsker or cross-fitting conditions. The Bloom-type link to cohort-specific ATT(g,t) is presented as an additional result under one-sided compliance and absorbing treatment, not as a definitional equivalence. Citations to external DiD literature (Callaway and Sant'Anna 2021) supply context for the ATT analogue but do not carry the load of the central EIF derivation or double robustness property. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior author work appear in the derivation chain. The procedures are self-contained against the stated identification assumptions (instrument validity, no anticipation, correct regression or propensity score) and do not reduce the target parameter to its own inputs.
Axiom & Free-Parameter Ledger
axioms (4)
- domain assumption Instrument validity (relevance and exclusion restriction) conditional on covariates
- domain assumption No anticipation effects and suitable parallel trends or instrumented analogue for control groups
- domain assumption Correct specification of at least one nuisance function (outcome or treatment model) for double robustness
- domain assumption One-sided compliance and absorbing treatment for the Bloom-type result
Reference graph
Works this paper leans on
-
[1]
Callaway, Brantly and Sant'Anna, Pedro H. C. , year = 2021, month = dec, journal =. Difference-in-. doi:10.1016/j.jeconom.2020.12.001 , url =
-
[2]
Journal of Econometrics , volume =
Doubly Robust Difference-in-Differences Estimators , author =. Journal of Econometrics , volume =. doi:10.1016/j.jeconom.2020.06.003 , url =
-
[3]
Semiparametric Doubly Robust Targeted Double Machine Learning: A Review
Kennedy, Edward H. , year = 2023, month = jan, number =. Semiparametric Doubly Robust Targeted Double Machine Learning: A Review , shorttitle =. arXiv , keywords =:2203.06469 , primaryclass =
-
[5]
Miyaji, Sho , year = 2026, month = feb, journal =. Instrumented. doi:10.48550/arXiv.2405.12083 , url =. arXiv , keywords =:2405.12083 , primaryclass =
-
[6]
Abadie, Alberto , year = 2005, month = jan, journal =. Semiparametric. doi:10.1111/0034-6527.00321 , url =
-
[7]
Fr. Exploiting. Journal of the American Statistical Association , volume =. doi:10.1198/jasa.2010.ap08148 , url =
-
[8]
Chen, Xiaohong and Sant'Anna, Pedro H. C. and Xie, Haitian , year = 2025, month = jun, number =. Efficient. doi:10.48550/arXiv.2506.17729 , url =. arXiv , keywords =:2506.17729 , primaryclass =
-
[9]
Double/Debiased Machine Learning for Treatment and Structural Parameters , author =. The Econometrics Journal , volume =. doi:10.1111/ectj.12097 , url =
-
[10]
The Econometrics Journal , volume =
Double/Debiased Machine Learning for Difference-in-Differences Models , author =. The Econometrics Journal , volume =. doi:10.1093/ectj/utaa001 , url =
-
[11]
Lan, Hui and Chang, Haoge and Dillon, Eleanor and Syrgkanis, Vasilis , year = 2025, month = apr, number =. A. doi:10.48550/arXiv.2502.04699 , url =. arXiv , langid =:2502.04699 , primaryclass =
-
[12]
Improved Two-Period Difference-in-Differences by Targeted Estimation , author =. Economics Letters , volume =. doi:10.1016/j.econlet.2025.112600 , url =
-
[13]
Journal of Machine Learning Research , volume =
On doubly robust inference for double machine learning in semiparametric regression , author =. Journal of Machine Learning Research , volume =
-
[14]
Handbook of labor economics , volume =
Instrumental variables with unobserved heterogeneity in treatment effects , author =. Handbook of labor economics , volume =. 2024 , publisher =
2024
-
[15]
Journal of Applied Econometrics , volume =
Semiparametric Efficiency Bounds , author =. Journal of Applied Econometrics , volume =. doi:10.1002/jae.3950050202 , url =
-
[16]
Angrist, Joshua D. and Pischke, J. Mostly. doi:10.2307/j.ctvcm4j72 , url =. j.ctvcm4j72 , eprinttype =
-
[17]
Journal of Human Resources , pages =
Estimating the effect of job-training programs, using longitudinal data: Ashenfelter's findings reconsidered , author =. Journal of Human Resources , pages =. 1984 , publisher =
1984
-
[18]
Tan, Zhiqiang , year = 2006, month = dec, journal =. Regression and. doi:10.1198/016214505000001366 , url =
-
[19]
Mark J van der Laan and James M Robins.Unified methods for censored longitudinal data and causality
Tsiatis, Anastasios , year = 2006, series =. Semiparametric. doi:10.1007/0-387-37345-4 , url =
-
[20]
Amstat News , volume =
Statistics as a science, not an art: the way to survive in data science , author =. Amstat News , volume =
-
[21]
Van Der Laan, Mark J. and Rose, Sherri , year = 2011, series =. Targeted. doi:10.1007/978-1-4419-9782-1 , url =
-
[22]
Journal of Machine Learning Research , volume =
DoubleML-an object-oriented implementation of double machine learning in python , author =. Journal of Machine Learning Research , volume =
-
[23]
On the Equivalence between Neyman Orthogonality and Pathwise Differentiability
On the Equivalence between Neyman Orthogonality and Pathwise Differentiability , author =. arXiv preprint arXiv:2603.15817 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.