Recognition: unknown
SprayCheck: Finding Gray Failures in Adaptive Routing Networks
Pith reviewed 2026-05-07 12:42 UTC · model grok-4.3
The pith
SprayCheck detects gray failures in adaptive routing networks by passively observing traffic spraying patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SprayCheck is a passive gray failure detection system that leverages the statistical properties of adaptive routing and network load balancing combined with flow-level information to identify and localize single-link packet drop rates as low as 1.5% in one iteration or 0.5% in five iterations of Llama-3 70B training in a 64-spine topology.
What carries the argument
The combination of statistical properties from adaptive routing traffic spraying and flow-level information, used to detect anomalies in packet delivery without active probing.
If this is right
- Preemptive rerouting becomes possible before gray failures impact application performance significantly.
- Network operators can maintain high utilization in adaptive-routed clusters without added monitoring overhead.
- Scales to clusters with hundreds of thousands of GPUs by relying on existing traffic patterns.
- Improves overall performance of ML workloads by addressing failures that prior methods could not handle at scale.
Where Pith is reading between the lines
- Similar passive techniques might extend to detecting other subtle network issues like latency variations in non-ML workloads.
- Integration with existing network management tools could allow automated responses to detected failures.
- Testing in topologies larger than 64 spines would confirm scalability claims.
- Comparison with active probing methods in real deployments could quantify the passive advantage.
Load-bearing premise
The statistical properties of adaptive routing and network load balancing, when combined with flow-level information, are sufficient to identify and localize gray failures through passive observation alone.
What would settle it
Running SprayCheck on a 64-spine topology with Llama-3 70B training traffic containing a single link with exactly 1% packet drop rate and checking if it correctly identifies and localizes the failure within the claimed iterations.
Figures










read the original abstract
Distributed machine learning (ML) training has become a dominant workload in modern data center networks, operating at massive scale with clusters comprising tens to hundreds of thousands of GPUs. The scale of these networks makes failures, and particularly gray failures, inevitable. Gray failures can significantly degrade both network and application performance, yet they are notoriously difficult to detect, localize, and debug. To meet the performance demands of ML workloads, adaptive routing is widely deployed to maximize network utilization by dynamically spreading traffic across many paths. While adaptive routing increases network utilization, it also greatly intensifies the effect of gray failures. Prior work has either dismissed gray failures as negligible or proposed detection mechanisms that fail to scale, rendering these approaches increasingly impractical for large-scale clusters. We present SprayCheck, a passive gray failure detection system that leverages the statistical properties of adaptive routing and network load balancing. By combining these properties with flow-level information, SprayCheck can identify failures before they significantly impact application performance, enabling preemptive rerouting and improving overall performance. Importantly, this is achieved through passive observation of traffic spraying, without introducing additional load on the network. We evaluate SprayCheck and show that it can detect and localize a single-link packet-drop-rate $1.5\%$ within a single iteration and as little as $0.5\%$ within 5 training iterations of Llama-3 70B in a 64 spine topology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SprayCheck, a passive gray-failure detection and localization system for large-scale data-center networks running distributed ML training under adaptive routing. It claims that, by exploiting the statistical properties of traffic spraying together with flow-level observations, the system can identify a single-link packet drop rate of 1.5 % within one training iteration and as little as 0.5 % within five iterations of Llama-3 70B on a 64-spine topology, all without injecting additional traffic.
Significance. If the statistical separation can be shown to hold under realistic load-balancing variance, SprayCheck would address a practically important gap: gray failures that are invisible to conventional monitoring yet degrade collective-communication performance at hyperscale. The passive, zero-overhead design is a clear strength for production fabrics. The concrete detection thresholds reported for a realistic ML workload and topology give the result immediate engineering relevance, provided the supporting analysis is supplied.
major comments (2)
- [Abstract] Abstract: the central claim that a 0.5 % single-link drop is detectable and localizable within five Llama-3 iterations rests on the unproven assertion that the drop-induced deviation exceeds the variance produced by adaptive spraying and load balancing. No derivation of required per-link sample counts, no bound on spraying-induced variance, and no sensitivity analysis appear in the manuscript; without these the separability result cannot be assessed.
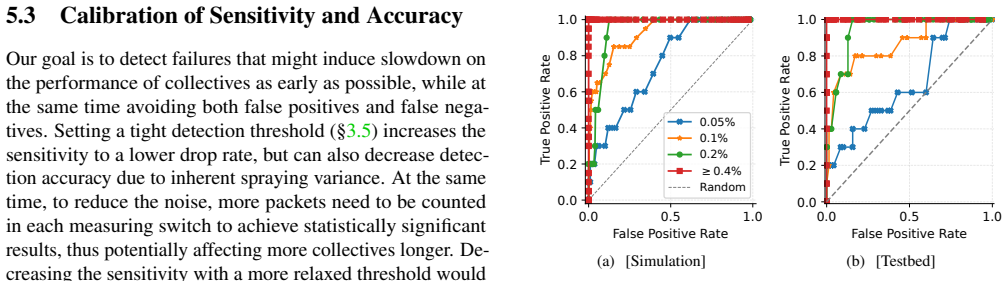
- [Evaluation] Evaluation section (implied by the reported detection rates): the abstract states concrete performance numbers (1.5 % in one iteration, 0.5 % in five) yet supplies neither the number of flows observed, the iteration length, the false-positive threshold, nor any statistical test. This omission is load-bearing because the headline result is precisely a claim about statistical distinguishability.
minor comments (1)
- [Abstract] The abstract asserts that prior work either dismisses gray failures or fails to scale, but provides no citations; adding the relevant references would clarify the novelty positioning.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need for explicit statistical grounding of our detection thresholds. We agree that the separability claims require clearer derivation and supporting parameters. We will revise the manuscript to include these elements while preserving the passive, zero-overhead design focus. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that a 0.5 % single-link drop is detectable and localizable within five Llama-3 iterations rests on the unproven assertion that the drop-induced deviation exceeds the variance produced by adaptive spraying and load balancing. No derivation of required per-link sample counts, no bound on spraying-induced variance, and no sensitivity analysis appear in the manuscript; without these the separability result cannot be assessed.
Authors: We accept that the abstract states the 0.5 % / five-iteration threshold without an accompanying derivation in the current text. The full evaluation section reports empirical separation from ns-3 simulations under realistic Llama-3 70B spraying, but we agree a formal treatment is needed. In revision we will add a dedicated subsection deriving the minimum per-link flow samples required for distinguishability. We will bound spraying-induced variance via a multinomial model of adaptive routing combined with Hoeffding-type concentration inequalities, then perform sensitivity analysis across flow counts, ECMP group sizes, and load-balancing entropy. This will directly support the headline numbers. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the reported detection rates): the abstract states concrete performance numbers (1.5 % in one iteration, 0.5 % in five) yet supplies neither the number of flows observed, the iteration length, the false-positive threshold, nor any statistical test. This omission is load-bearing because the headline result is precisely a claim about statistical distinguishability.
Authors: The evaluation reports results from packet-level simulations of the 64-spine topology driven by Llama-3 70B collective traces, but we acknowledge the referee's point that key parameters are not stated explicitly. In the revised manuscript we will add a table and accompanying text specifying: (i) average flows observed per link per iteration (~1.2×10^5), (ii) modeled iteration communication phase length (100 ms), (iii) false-positive threshold (1 % at the chosen operating point), and (iv) the statistical procedure (two-sample Kolmogorov-Smirnov test on per-link drop-rate empirical distributions, with p-value < 0.01 for detection). We will also include the corresponding ROC curves and variance plots to make the separability transparent. revision: yes
Circularity Check
No circularity: detection claims rest on external observations and evaluation, not self-referential definitions
full rationale
The provided abstract and context describe SprayCheck as a passive system that combines statistical properties of adaptive routing, load balancing, and flow-level information to detect gray failures. No equations, parameter-fitting steps, or derivations are shown that would reduce the claimed detection thresholds (1.5% drop in one iteration, 0.5% in five iterations of Llama-3 70B) to tautological inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way. The performance results are framed as outcomes of evaluation in a 64-spine topology rather than predictions forced by the method's own definitions. This satisfies the criteria for a self-contained, non-circular derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Adaptive routing produces statistically observable traffic spreading patterns that differ detectably when a link experiences gray failure.
- domain assumption Flow-level information combined with spraying statistics is adequate to localize single-link failures before application impact.
invented entities (1)
-
SprayCheck detection system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
007: Democratically finding the cause of packet drops
Behnaz Arzani, Selim Ciraci, Luiz Chamon, Yibo Zhu, Hongqiang Harry Liu, Jitu Padhye, Boon Thau Loo, and Geoff Outhred. 007: Democratically finding the cause of packet drops. In15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), pages 419–435, 2018
2018
-
[2]
PINT: Probabilistic in-band network telemetry
Ran Ben Basat, Sivaramakrishnan Ramanathan, Yuliang Li, Gianni Antichi, Minian Yu, and Michael Mitzen- macher. PINT: Probabilistic in-band network telemetry. InProceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the applications, technologies, architectures, and protocols for computer communication, pages 662–680, 2020
2020
-
[3]
Tommaso Bonato, Abdul Kabbani, Ahmad Gha- layini, Michael Papamichael, Mohammad Dohadwala, Lukas Gianinazzi, Mikhail Khalilov, Elias Achermann, Daniele De Sensi, and Torsten Hoefler. Reps: Recycled entropy packet spraying for adaptive load balancing and failure mitigation.arXiv preprint arXiv:2407.21625, 2025
-
[4]
Per-packet load- balanced, low-latency routing for clos-based data center networks
Jiaxin Cao, Rui Xia, Pengkun Yang, Chuanxiong Guo, Guohan Lu, Lihua Yuan, Yixin Zheng, Haitao Wu, Yongqiang Xiong, and Dave Maltz. Per-packet load- balanced, low-latency routing for clos-based data center networks. InProceedings of the ninth ACM conference on Emerging networking experiments and technologies, pages 49–60, 2013
2013
-
[5]
RFC 1157: A Simple Network Man- agement Protocol (SNMP)
Jeffrey D Case, Mark Fedor, Martin L Schoffstall, and James Davin. RFC 1157: A Simple Network Man- agement Protocol (SNMP). Technical report, Internet Engineering Task Force, 1990
1990
-
[6]
Intel Intelligent Fabric Processors
Intel Corporation. Intel Intelligent Fabric Processors. https://www.intel.com/content/www/us/en/ products/network-io/programmable-ethernet- switch.html, accessed Apr 15, 2026
2026
-
[7]
Intel P4 Studio Software Devel- opment Environment (SDE)
Intel Corporation. Intel P4 Studio Software Devel- opment Environment (SDE). https://github.com/ p4lang/open-p4studio, accessed Apr 6, 2026
2026
-
[8]
Datasheet: NVIDIA CONNECTX-6 DX Ethernet SmartNIC
NVIDIA Corporation. Datasheet: NVIDIA CONNECTX-6 DX Ethernet SmartNIC. https://www.nvidia.com/content/dam/en-zz/ Solutions/networking/ethernet-adapters/ ConnectX-6-Dx-Datasheet.pdf , accessed Apr 7, 2026
2026
-
[9]
NVIDIA Spectrum SN6000 Ethernet Switch Series Datasheet
NVIDIA Corporation. NVIDIA Spectrum SN6000 Ethernet Switch Series Datasheet. https://resources.nvidia.com/en-us- accelerated-networking-resource-library/ ethernet-datasheet-spectrum-sn6000-switch , accessed Apr 21, 2026
2026
-
[10]
NVIDIA Spectrum- X Network Platform Architecture
NVIDIA Corporation. NVIDIA Spectrum- X Network Platform Architecture. https: //resources.nvidia.com/en-us-accelerated- networking-resource-library/nvidia- spectrum-x, 2024
2024
-
[11]
NVIDIA Super- charges Ethernet Networking for Generative AI
NVIDIA Corporation. NVIDIA Super- charges Ethernet Networking for Generative AI. https://nvidianews.nvidia.com/news/ nvidia-supercharges-ethernet-networking- for-generative-ai, 2024
2024
-
[12]
NVIDIA Spectrum-X Ethernet Networking Platform
NVIDIA Corporation. NVIDIA Spectrum-X Ethernet Networking Platform . https://www.nvidia.com/en- us/networking/spectrumx/, accessed Apr 21, 2026, 2026
2026
-
[13]
On the impact of packet spraying in data center networks
Advait Dixit, Pawan Prakash, Y Charlie Hu, and Ra- mana Rao Kompella. On the impact of packet spraying in data center networks. In2013 Proceedings IEEE INFOCOM, pages 2130–2138. IEEE, 2013
2013
-
[14]
Rdma over ethernet for distributed training at meta scale
Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Ro- hit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, et al. Rdma over ethernet for distributed training at meta scale. InProceedings of the ACM SIGCOMM 2024 Conference, pages 57–70, 2024
2024
-
[15]
Yunqi Gao, Bing Hu, Mahdi Boloursaz Mashhadi, A Jin, Yanfeng Zhang, Pei Xiao, Rahim Tafazolli, Mérouane Debbah, et al. FlowMoE: A Scalable Pipeline Scheduling Framework for Distributed Mixture- of-Experts Training.arXiv preprint arXiv:2510.00207, 2025
-
[16]
Drill: Micro load balancing for low-latency data center networks
Soudeh Ghorbani, Zibin Yang, P Brighten Godfrey, Yashar Ganjali, and Amin Firoozshahian. Drill: Micro load balancing for low-latency data center networks. In Proceedings of the Conference of the ACM Special In- terest Group on Data Communication, pages 225–238, 2017
2017
-
[17]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, An- thony Hartshorn, Aobo Yang, Archi Mitra, Archie Sra- vankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, A...
2024
-
[18]
Teleme- try Report Format Specification Version 2.0
The P4.org Applications Working Group. Teleme- try Report Format Specification Version 2.0. https://github.com/p4lang/p4-applications/ blob/master/docs/telemetry_report_v2_0.pdf, accessed Apr 17, 2026, 2020
2026
-
[19]
What bugs live in the cloud? a study of 3000+ issues in cloud systems
Haryadi S Gunawi, Mingzhe Hao, Tanakorn Leesata- pornwongsa, Tiratat Patana-Anake, Thanh Do, Jeffry Adityatama, Kurnia J Eliazar, Agung Laksono, Jeffrey F Lukman, Vincentius Martin, et al. What bugs live in the cloud? a study of 3000+ issues in cloud systems. InPro- ceedings of the ACM symposium on cloud computing, pages 1–14, 2014
2014
-
[20]
Fail-slow at scale: Evidence of hardware performance faults in large production sys- tems.ACM Transactions on Storage (TOS), 14(3):1–26, 2018
Haryadi S Gunawi, Riza O Suminto, Russell Sears, Casey Golliher, Swaminathan Sundararaman, Xing Lin, Tim Emami, Weiguang Sheng, Nematollah Bidokhti, Caitie McCaffrey, et al. Fail-slow at scale: Evidence of hardware performance faults in large production sys- tems.ACM Transactions on Storage (TOS), 14(3):1–26, 2018
2018
-
[21]
Pingmesh: A large-scale system for data center network latency measurement and analysis
Chuanxiong Guo, Lihua Yuan, Dong Xiang, Yingnong Dang, Ray Huang, Dave Maltz, Zhaoyi Liu, Vin Wang, Bin Pang, Hua Chen, et al. Pingmesh: A large-scale system for data center network latency measurement and analysis. InProceedings of the 2015 ACM Confer- ence on Special Interest Group on Data Communication, pages 139–152, 2015
2015
-
[22]
Scaling beyond packet switch limits with multiple dataplanes
Yibo Guo, William M Mellette, Alex C Snoeren, and George Porter. Scaling beyond packet switch limits with multiple dataplanes. InProceedings of the 18th International Conference on emerging Networking EX- periments and Technologies, pages 214–231, 2022
2022
-
[23]
Gray failure: The achilles’ heel of cloud- scale systems
Peng Huang, Chuanxiong Guo, Lidong Zhou, Jacob R Lorch, Yingnong Dang, Murali Chintalapati, and Ran- dolph Yao. Gray failure: The achilles’ heel of cloud- scale systems. InProceedings of the 16th Workshop on Hot Topics in Operating Systems, pages 150–155, 2017
2017
-
[24]
IEEE Standard for Local and Metropolitan Area Networks–Bridges and Bridged Networks.IEEE Std 802.1Q-2022 (Revision of IEEE Std 802.1Q-2018), pages 1–2163, 2022
IEEE. IEEE Standard for Local and Metropolitan Area Networks–Bridges and Bridged Networks.IEEE Std 802.1Q-2022 (Revision of IEEE Std 802.1Q-2018), pages 1–2163, 2022
2022
-
[25]
Cisco Nexus 9000 Se- ries NX-OS Unicast Routing Configuration Guide, Configure Dynamic Load Balancing
Cisco Systems Inc. Cisco Nexus 9000 Se- ries NX-OS Unicast Routing Configuration Guide, Configure Dynamic Load Balancing. https://www.cisco.com/c/en/us/td/docs/ dcn/nx-os/nexus9000/105x/unicast-routing- configuration/cisco-nexus-9000-series-nx- os-unicast-routing-configuration-guide/m- configure-dynamic-load-balancing.html, 2025
2025
-
[26]
Rapid detection and localization of gray failures in data centers via in-band network telemetry
Chenhao Jia, Tian Pan, Zizheng Bian, Xingchen Lin, Enge Song, Cheng Xu, Tao Huang, and Yunjie Liu. Rapid detection and localization of gray failures in data centers via in-band network telemetry. InNOMS 2020- 2020 IEEE/IFIP Network Operations and Management Symposium, pages 1–9. IEEE, 2020
2020
-
[27]
Cognitive routing in the Tomahawk 5 data 15 center switch
Mohan Kalkunte, Niranjan Vaidya, and Pete Del Vecchio. Cognitive routing in the Tomahawk 5 data 15 center switch. https://www.broadcom.com/blog/ cognitive-routing-in-the-tomahawk-5-data- center-switch, 2023
2023
-
[28]
AI Fabric Resiliency and Why Network Convergence Matters
Berkin Kartal. AI Fabric Resiliency and Why Network Convergence Matters. https: //developer.nvidia.com/blog/ai-fabric- resiliency-and-why-network-convergence- matters/, accessed Apr 23, 2026, 2025
2026
-
[29]
Dally, and Dennis Abts
John Kim, William J. Dally, and Dennis Abts. Adap- tive routing in high-radix clos network. InProceedings of the 2006 ACM/IEEE Conference on Supercomput- ing, SC ’06, page 92–es, New York, NY , USA, 2006. Association for Computing Machinery
2006
-
[30]
Revisiting reliability in large-scale machine learn- ing research clusters
Apostolos Kokolis, Michael Kuchnik, John Hoffman, Adithya Kumar, Parth Malani, Faye Ma, Zachary De- Vito, Shubho Sengupta, Kalyan Saladi, and Carole-Jean Wu. Revisiting reliability in large-scale machine learn- ing research clusters. In2025 IEEE International Sym- posium on High Performance Computer Architecture (HPCA), pages 1259–1274. IEEE, 2025
2025
-
[31]
FlowPulse: Catching Network Failures in ML Clusters
Jakob Krebs, Dimitry Gavrilenko, Daniel Amir, Shir Landau Feibish, and Mark Silberstein. FlowPulse: Catching Network Failures in ML Clusters. InPro- ceedings of the 24th ACM Workshop on Hot Topics in Networks, pages 139–148, 2025
2025
-
[32]
Accelerating distributed {MoE} training and inference with lina
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. Accelerating distributed {MoE} training and inference with lina. In2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 945–959, 2023
2023
-
[33]
Understanding stragglers in large model training using what-if analy- sis
Jinkun Lin, Ziheng Jiang, Zuquan Song, Sida Zhao, Menghan Yu, Zhanghan Wang, Chenyuan Wang, Zuocheng Shi, Xiang Shi, Wei Jia, et al. Understanding stragglers in large model training using what-if analy- sis. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 483–498, 2025
2025
-
[34]
R-pingmesh: A service-aware roce network monitoring and diagnostic system
Kefei Liu, Zhuo Jiang, Jiao Zhang, Shixian Guo, Xuan Zhang, Yangyang Bai, Yongbin Dong, Feng Luo, Zhang Zhang, Lei Wang, et al. R-pingmesh: A service-aware roce network monitoring and diagnostic system. In Proceedings of the ACM SIGCOMM 2024 Conference, pages 554–567, 2024
2024
-
[35]
SkeletonHunter: Diagnosing and Localizing Network Failures in Containerized Large Model Training
Wei Liu, Kun Qian, Zhenhua Li, Tianyin Xu, Yunhao Liu, Weicheng Wang, Yun Zhang, Jiakang Li, Shuhong Zhu, Xue Li, et al. SkeletonHunter: Diagnosing and Localizing Network Failures in Containerized Large Model Training. InProceedings of the ACM SIGCOMM 2025 Conference, pages 527–540, 2025
2025
-
[36]
Load balancing for AI training workloads
Sarah McClure, Evyatar Cohen, Alex Shpiner, Mark Silberstein, Sylvia Ratnasamy, Scott Shenker, and Isaac Keslassy. Load balancing for AI training workloads. arXiv preprint arXiv:2507.21372, 2025
-
[37]
Revisiting network support for RDMA
Radhika Mittal, Alexander Shpiner, Aurojit Panda, Eitan Zahavi, Arvind Krishnamurthy, Sylvia Ratnasamy, and Scott Shenker. Revisiting network support for RDMA. InProceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, pages 313–326, 2018
2018
-
[38]
The power of two choices in randomized load balancing.IEEE transactions on par- allel and distributed systems, 12(10):1094–1104, 2002
Michael Mitzenmacher. The power of two choices in randomized load balancing.IEEE transactions on par- allel and distributed systems, 12(10):1094–1104, 2002
2002
-
[39]
Cornelis CN5000 Omni-Path Switch
Cornelis Networks. Cornelis CN5000 Omni-Path Switch. https://www.cornelis.com/product/ cornelis-cn5000-omni-path-switch?tab= Highlights, 2025
2025
-
[40]
Weighted Packet Spray – AI-ML Data Center Feature Guide
Juniper Networks. Weighted Packet Spray – AI-ML Data Center Feature Guide. https: //www.juniper.net/documentation/us/en/ software/junos/ai-ml-evo/topics/topic- map/weighted-packet-spray.html, accessed Apr 21, 2026
2026
-
[41]
NS-3 Network Simulator
NS3 Contributors and Maintainers. NS-3 Network Simulator. https://www.nsnam.org/, 2025
2025
-
[42]
Alibaba hpn: A data center network for large language model training
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, et al. Alibaba hpn: A data center network for large language model training. InProceedings of the ACM SIGCOMM 2024 Conference, pages 691–706, 2024
2024
-
[43]
Turbocharging Generative AI Work- loads with NVIDIA Spectrum-X Networking Platform
Peter Rizk. Turbocharging Generative AI Work- loads with NVIDIA Spectrum-X Networking Platform. https://developer.nvidia.com/blog/ turbocharging-ai-workloads-with-nvidia- spectrum-x-networking-platform/, 2023
2023
-
[44]
Adaptive routing in infiniband hardware
José Rocher-González, Ernst Gunnar Gran, Sven-Arne Reinemo, Tor Skeie, Jesús Escudero-Sahuquillo, Pe- dro Javier García, and Francisco J Quiles Flor. Adaptive routing in infiniband hardware. In2022 22nd IEEE International Symposium on Cluster, Cloud and Internet Computing (CCGrid), pages 463–472. IEEE, 2022
2022
-
[45]
Arjun Roy, Hongyi Zeng, Jasmeet Bagga, and Alex C. Snoeren. Passive Realtime Datacenter Fault Detection and Localization. In14th USENIX Symposium on Net- worked Systems Design and Implementation (NSDI 17), pages 595–612, Boston, MA, March 2017. USENIX Association. 16
2017
-
[46]
Training LLMs with Fault Tolerant HSDP on 100,000 GPUs, 2026
Omkar Salpekar, Rohan Varma, Kenny Yu, Vladimir Ivanov, Yang Wang, Ahmed Sharif, Min Si, Shawn Xu, Feng Tian, Shengbao Zheng, Tristan Rice, Ankush Garg, Shangfu Peng, Shreyas Siravara, Wenyin Fu, Rodrigo de Castro, Adithya Gangidi, Andrey Obraztsov, Sharan Narang, Sergey Edunov, Maxim Naumov, Chunqiang Tang, and Mathew Oldham. Training LLMs with Fault Tol...
2026
-
[47]
UCX: an open source framework for HPC network APIs and beyond
Pavel Shamis, Manjunath Gorentla Venkata, M Graham Lopez, Matthew B Baker, Oscar Hernandez, Yossi Itigin, Mike Dubman, Gilad Shainer, Richard L Graham, Liran Liss, et al. UCX: an open source framework for HPC network APIs and beyond. In2015 IEEE 23rd Annual Symposium on High-Performance Interconnects, pages 40–43. IEEE, 2015
2015
-
[48]
NVIDIA Ethernet Networking Acceler- ates World’s Largest AI Supercomputer, Built by xAI
Alex Shapiro. NVIDIA Ethernet Networking Acceler- ates World’s Largest AI Supercomputer, Built by xAI. https://nvidianews.nvidia.com/news/spectrum- x-ethernet-networking-xai-colossus, 2024
2024
-
[49]
Drag- onfly+: Low cost topology for scaling datacenters
Alexander Shpiner, Zachy Haramaty, Saar Eliad, Vladimir Zdornov, Barak Gafni, and Eitan Zahavi. Drag- onfly+: Low cost topology for scaling datacenters. In2017 IEEE 3rd International Workshop on High- Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB), pages 1–8. IEEE, 2017
2017
-
[50]
Collective Communication for 100k+ GPUs
Min Si, Pavan Balaji, Yongzhou Chen, Ching-Hsiang Chu, Adi Gangidi, Saif Hasan, Subodh Iyengar, Dan Johnson, Bingzhe Liu, Regina Ren, Deep Shah, Ashmitha Jeevaraj Shetty, Greg Steinbrecher, Yulun Wang, Bruce Wu, Xinfeng Xie, Jingyi Yang, Mingran Yang, Kenny Yu, Minlan Yu, Cen Zhao, Wes Bland, Denis Boyda, Suman Gumudavelli, Prashanth Kan- nan, Cristian Lu...
-
[51]
Surviving switch failures in cloud datacenters.ACM SIGCOMM Computer Communication Review, 51(2):2– 9, 2021
Rachee Singh, Muqeet Mukhtar, Ashay Krishna, Aniruddha Parkhi, Jitendra Padhye, and David Maltz. Surviving switch failures in cloud datacenters.ACM SIGCOMM Computer Communication Review, 51(2):2– 9, 2021
2021
-
[52]
NetBouncer: Active device and link failure localization in data center networks
Cheng Tan, Ze Jin, Chuanxiong Guo, Tianrong Zhang, Haitao Wu, Karl Deng, Dongming Bi, and Dong Xiang. NetBouncer: Active device and link failure localization in data center networks. In16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), pages 599–614, 2019
2019
-
[53]
Unified collective communication (UCC): An unified library for cpu, gpu, and dpu collectives
Manjunath Gorentla Venkata, Valentine Petrov, Sergey Lebedev, Devendar Bureddy, Ferrol Aderholdt, Joshua Ladd, Gil Bloch, Mike Dubman, and Gilad Shainer. Unified collective communication (UCC): An unified library for cpu, gpu, and dpu collectives. In2024 IEEE Symposium on High-Performance Interconnects (HOTI), pages 37–46. IEEE, 2024
2024
-
[54]
First Principles: Oracle Acceleron Multiplanar Networking Architecture
Pradeep Vincent, Jag Brar, and David Becker. First Principles: Oracle Acceleron Multiplanar Networking Architecture. https://blogs.oracle.com/cloud- infrastructure/first-principles-acceleron- multiplanar-networking, accessed Apr 22, 2026
2026
-
[55]
Recommended Topolo- gies for Implementing an HPC Cluster with NVIDIA Quantum InfiniBand Solutions - Part 2 - Adaptive routing, HBF and SHIELD
Koushnir Vladimir. Recommended Topolo- gies for Implementing an HPC Cluster with NVIDIA Quantum InfiniBand Solutions - Part 2 - Adaptive routing, HBF and SHIELD. https://enterprise-support.nvidia.com/ s/article/Recommended-Topologies-for- Implementing-an-HPC-Cluster-with-NVIDIA- Quantum-InfiniBand-Solutions-Part-2, 2024
2024
-
[56]
Astra-sim2
William Won, Taekyung Heo, Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna. Astra-sim2. 0: Modeling hierarchical networks and disaggregated systems for large-model training at scale. In2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), pages 283–
-
[57]
SuperBench: Improving Cloud AI Infrastructure Reliability with Proactive Vali- dation
Yifan Xiong, Yuting Jiang, Ziyue Yang, Lei Qu, Gu- oshuai Zhao, Shuguang Liu, Dong Zhong, Boris Pinzur, Jie Zhang, Yang Wang, et al. SuperBench: Improving Cloud AI Infrastructure Reliability with Proactive Vali- dation. In2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 835–850, 2024
2024
-
[58]
Packet-level telemetry in large datacenter networks
Zhu Yibo, Kang Nanxi, Cao Jiaxin, et al. Packet-level telemetry in large datacenter networks. InProc of the 2015 ACM Conference on Special Interest Group on Data Communication. New York: ACM Press, pages 479–491, 2015
2015
-
[59]
Understanding the micro-behaviors of hardware offloaded network stacks with lumina
Zhuolong Yu, Bowen Su, Wei Bai, Shachar Raindel, Vladimir Braverman, and Xin Jin. Understanding the micro-behaviors of hardware offloaded network stacks with lumina. InProceedings of the ACM SIGCOMM 2023 Conference, pages 1074–1087, 2023
2023
-
[60]
Congestion control for large-scale RDMA de- ployments.ACM SIGCOMM Computer Communica- tion Review, 45(4):523–536, 2015
Yibo Zhu, Haggai Eran, Daniel Firestone, Chuanxiong Guo, Marina Lipshteyn, Yehonatan Liron, Jitendra Pad- hye, Shachar Raindel, Mohamad Haj Yahia, and Ming Zhang. Congestion control for large-scale RDMA de- ployments.ACM SIGCOMM Computer Communica- tion Review, 45(4):523–536, 2015. 17
2015
-
[61]
Understanding and mitigating packet corrup- tion in data center networks
Danyang Zhuo, Monia Ghobadi, Ratul Mahajan, Klaus- Tycho Förster, Arvind Krishnamurthy, and Thomas An- derson. Understanding and mitigating packet corrup- tion in data center networks. InProceedings of the Conference of the ACM Special Interest Group on Data Communication, pages 362–375, 2017. A Additional Experiments Fig. 11 corroborates the robustness c...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.