Recognition: unknown
The Parameterized Complexity of Scheduling with Precedence Delays: Shuffle Product and Directed Bandwidth
Pith reviewed 2026-05-07 04:00 UTC · model grok-4.3
The pith
Shuffle Product and Directed Bandwidth are XNLP-complete, settling the parameterized complexity of scheduling with precedence delays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
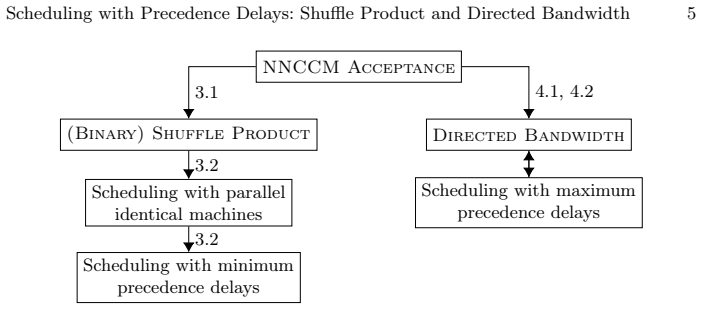
The central discovery is that Shuffle Product is XNLP-complete and Directed Bandwidth is XNLP-complete even when restricted to trees and parameterized by the target bandwidth value. These completeness results are obtained via polynomial-time reductions from known XNLP-complete problems that preserve the relevant parameters, such as the width of the input DAG for scheduling variants with minimum or maximum delays.
What carries the argument
The key machinery consists of parameterized reductions from established XNLP-complete problems to Shuffle Product and Directed Bandwidth, which maintain bounded growth in parameters like DAG width, maximum delay, and target bandwidth value. These reductions allow transferring hardness results to the scheduling problems with precedence delays.
Load-bearing premise
The specific polynomial-time reductions from known XNLP-complete problems preserve the relevant parameters such as DAG width or target bandwidth value without introducing large constants or input-size dependencies that would invalidate the parameterized hardness.
What would settle it
An algorithm that solves Directed Bandwidth on trees in time f(b) * n^{O(1)} where b is the target bandwidth value would falsify the XNLP-completeness unless the XNLP hierarchy collapses.
Figures




read the original abstract
In this paper, we study the parameterized complexity of several variants of scheduling with precedence constraints between jobs. Namely, we consider the single machine setting with delay values on top of the precedence constraints. Such scheduling problems are related to several decades-old problems with open parameterized complexity status, notably Shuffle Product and Directed Bandwidth. We obtain XNLP-completeness results for both problems, and derive implications to scheduling with minimum (resp. maximum) delays parameterized by the width of the directed acyclic graph giving the precedence constraints, and/or by the maximum delay value in the input. Regarding Directed Bandwidth, we also settle the case of trees by showing XNLP-completeness parameterized by the target value. Beyond these results, we believe that Shuffle Product is an unusual and promising addition to the list of XNLP-complete problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the parameterized complexity of single-machine scheduling with precedence constraints and delay values. It proves XNLP-completeness for Shuffle Product and for Directed Bandwidth (including the restriction to trees when parameterized by the target bandwidth value). These results are used to obtain XNLP-completeness for scheduling with minimum delays and with maximum delays, parameterized by the width of the precedence DAG and/or by the maximum delay value in the input.
Significance. If the reductions are correct, the results are significant: they resolve the parameterized complexity status of several problems that have been open for decades and add Shuffle Product to the short list of XNLP-complete problems, which may prove useful for future reductions. The tree case for Directed Bandwidth is a clean additional contribution. The work provides tight hardness results that connect scheduling directly to established XNLP-complete problems.
major comments (2)
- [proofs of XNLP-completeness for Directed Bandwidth (including trees) and the derived scheduling results] The central XNLP-hardness claims rest on polynomial-time reductions that must map the source parameter k to a target parameter (bandwidth value, DAG width, or maximum delay) bounded by some computable f(k) with no dependence on the instance size n. The manuscript should explicitly state the concrete bound f(k) achieved in each reduction (particularly the tree case for Directed Bandwidth and the subsequent implications for the scheduling problems) so that readers can verify that the hardness is indeed XNLP-hardness rather than merely para-NP-hardness or W[1]-hardness.
- [Directed Bandwidth on trees] The reduction establishing XNLP-completeness of Directed Bandwidth on trees must preserve the tree structure while keeping the target bandwidth value bounded by f(k). Any construction step that sets the target bandwidth to a value linear in the number of vertices (or otherwise n-dependent) would invalidate the claimed XNLP-completeness; the paper should include a short paragraph confirming that the produced instance remains a tree and that the new bandwidth parameter is f(k).
minor comments (2)
- [Abstract] The abstract is concise but would be improved by naming the specific theorems that contain the XNLP-completeness statements for Shuffle Product, Directed Bandwidth, and the scheduling implications.
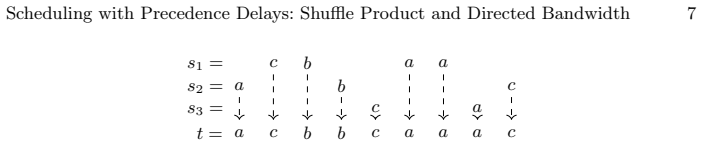
- [Introduction] A small illustrative example of a precedence DAG with delays and the corresponding scheduling instance would help readers follow the connection between the graph problems and the scheduling variants.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work and for the detailed comments. We address each major comment below and will update the manuscript to incorporate the clarifications requested.
read point-by-point responses
-
Referee: [proofs of XNLP-completeness for Directed Bandwidth (including trees) and the derived scheduling results] The central XNLP-hardness claims rest on polynomial-time reductions that must map the source parameter k to a target parameter (bandwidth value, DAG width, or maximum delay) bounded by some computable f(k) with no dependence on the instance size n. The manuscript should explicitly state the concrete bound f(k) achieved in each reduction (particularly the tree case for Directed Bandwidth and the subsequent implications for the scheduling problems) so that readers can verify that the hardness is indeed XNLP-hardness rather than merely para-NP-hardness or W[1]-hardness.
Authors: We agree that making the parameter bounds explicit will help readers verify the XNLP-completeness. In our reduction from Shuffle Product (parameterized by the number of shuffles k) to Directed Bandwidth, the target bandwidth is bounded by 2k. For the scheduling problems, the DAG width is bounded by k and the maximum delay by k. For the tree case of Directed Bandwidth, the bandwidth parameter is bounded by k. We will revise the manuscript by adding a dedicated paragraph after each reduction (in Sections 3, 4, and 5) that explicitly states these bounds f(k) and confirms they are independent of n. This will also cover the composition for the derived results. revision: yes
-
Referee: [Directed Bandwidth on trees] The reduction establishing XNLP-completeness of Directed Bandwidth on trees must preserve the tree structure while keeping the target bandwidth value bounded by f(k). Any construction step that sets the target bandwidth to a value linear in the number of vertices (or otherwise n-dependent) would invalidate the claimed XNLP-completeness; the paper should include a short paragraph confirming that the produced instance remains a tree and that the new bandwidth parameter is f(k).
Authors: The reduction for Directed Bandwidth on trees is constructed by taking a tree from a known XNLP-complete problem and attaching constant-size gadgets that maintain the tree property (no cycles or additional edges that would create non-tree structures). The target bandwidth is set to the original parameter k, which is independent of the instance size. We will add the requested short paragraph in Section 4.2, explicitly confirming that the output instance is a tree and that the bandwidth parameter equals k. revision: yes
Circularity Check
No significant circularity in XNLP-completeness derivations
full rationale
The paper derives XNLP-completeness for Shuffle Product and Directed Bandwidth (including on trees) via polynomial-time reductions from established XNLP-complete problems. These reductions are independent of the current work, map source parameters to target parameters (bandwidth value, DAG width, or max delay) via some f(k), and yield the stated implications for scheduling variants. No self-definitional equations, fitted inputs renamed as predictions, load-bearing self-citations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation appear in the derivation chain. The results are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The standard definition of the XNLP complexity class and the notion of parameterized reductions.
- domain assumption Basic properties of directed acyclic graphs (DAGs) and precedence constraints in scheduling.
Reference graph
Works this paper leans on
-
[1]
In: Kochetov, Y., Khachay, M., Beresnev, V., Nurminski, E., Parda- los, P
van Bevern, R., Bredereck, R., Bulteau, L., Komusiewicz, C., Talmon, N., Woeg- inger, G.J.: Precedence-constrained scheduling problems parameterized by partial order width. In: Kochetov, Y., Khachay, M., Beresnev, V., Nurminski, E., Parda- los, P. (eds.) Discrete Optimization and Operations Research, DOOR 2016. pp. 105–120. Springer (2016). https://doi.or...
-
[2]
In: Kowalik, L., Pilipczuk, M., Rzazewski, P
Bodlaender, H.L.: Parameterized complexity of bandwidth of caterpillars and weighted path emulation. In: Kowalik, L., Pilipczuk, M., Rzazewski, P. (eds.) 47th International Workshop on Graph-Theoretic Concepts in Computer Science, WG
-
[3]
Lecture Notes in Computer Science, vol. 12911, pp. 15–27. Springer (2021). https://doi.org/10.1007/978-3-030-86838-3_2
-
[4]
Bodlaender, H.L., Groenland, C., Jacob, H., Jaffke, L., Lima, P.T.: XNLP- completeness for parameterized problems on graphs with a linear structure. In: Dell, H., Nederlof, J. (eds.) 17th International Symposium on Parameterized and Exact Computation, IPEC 2022. LIPIcs, vol. 249, pp. 8:1–8:18. Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2022). http...
-
[5]
In: Dell, H., Nederlof, J
Bodlaender, H.L., Groenland, C., Jacob, H., Pilipczuk, M., Pilipczuk, M.: On the complexity of problems on tree-structured graphs. In: Dell, H., Nederlof, J. (eds.) 17th International Symposium on Parameterized and Exact Computation, IPEC
-
[6]
LIPIcs, vol. 249, pp. 6:1–6:17. Schloss Dagstuhl - Leibniz-Zentrum für Infor- matik (2022). https://doi.org/10.4230/LIPIcs.IPEC.2022.6
-
[7]
A black box for online approximate pattern matching.Inf
Bodlaender, H.L., Groenland, C., Nederlof, J., Swennenhuis, C.M.F.: Parameter- ized problems complete for nondeterministic FPT time and logarithmic space. Information and Computation300, 105195 (2024). https://doi.org/10.1016/J.IC. 2024.105195
-
[8]
Bodlaender, H.L., Hermelin, D., van Leeuwen, E.J.: Concurrency constrained scheduling with tree-like constraints. In: Fernau, H., Kindermann, P. (eds.) Pro- ceedings 51th International Workshop on Graph-Theoretic Concepts in Computer 24 H. L. Bodlaender, M. Mallem Science, WG 2025. pp. 105–120. Lecture Notes in Computer Science, Springer (2025). https://d...
-
[9]
Bodlaender, H.L., van der Wegen, M.: Parameterized complexity of scheduling chains of jobs with delays. In: Cao, Y., Pilipczuk, M. (eds.) 15th International Symposium on Parameterized and Exact Computation, IPEC 2020. pp. 4:1–4:15. LIPIcs, Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2020). https://doi.org/ 10.4230/LIPICS.IPEC.2020.4, full version: ...
-
[10]
IEEE Transactions on ComputersC-29(4), 308–316 (1980)
Bruno, Jones, So, K.: Deterministic scheduling with pipelined processors. IEEE Transactions on ComputersC-29(4), 308–316 (1980). https://doi.org/10.1109/ TC.1980.1675569
-
[11]
Eu- ropean Journal of Operational Research94(2), 231–241 (1996)
Błażwicz, J., Liu, Z.: Scheduling multiprocessor tasks with chain constraints. Eu- ropean Journal of Operational Research94(2), 231–241 (1996). https://doi.org/ 10.1016/0377-2217(96)00126-9
-
[12]
Fomin and Lukasz Kowalik and Daniel Lokshtanov and D
Cygan, M., Fomin, F.V., Kowalik, Ł., Lokshtanov, D., Marx, D., Pilipczuk, M., Pilipczuk, M., Saurabh, S.: Parameterized Algorithms. Springer (2015). https:// doi.org/10.1007/978-3-319-21275-3
-
[13]
Algorithmica71(3), 661–701 (2015)
Elberfeld, M., Stockhusen, C., Tantau, T.: On the space and circuit complexity of parameterized problems: Classes and completeness. Algorithmica71(3), 661–701 (2015). https://doi.org/10.1007/s00453-014-9944-y
-
[14]
Engels, D.W.: Scheduling for Hardware/Software Partitioning in Embedded Sys- tem Design. Ph.D. thesis, Massachusetts Institute of Technology (2000), https: //dspace.mit.edu/bitstream/handle/1721.1/86443/46804459-MIT.pdf
2000
-
[15]
SIAM Journal on Applied Mathematics34(3), 477–495 (1978)
Garey, M.R., Graham, R.L., Johnson, D.S., Knuth, D.E.: Complexity results for bandwidth minimization. SIAM Journal on Applied Mathematics34(3), 477–495 (1978). https://doi.org/10.1137/0134037
-
[16]
Garey, M.R., Johnson, D.S.: Computers and Intractability, vol. 174. freeman San Francisco (1979)
1979
-
[17]
In: Hammer, P., Johnson, E., Korte, B
Graham, R., Lawler, E., Lenstra, J., Kan, A.: Optimization and approximation in deterministic sequencing and scheduling: a survey. In: Hammer, P., Johnson, E., Korte, B. (eds.) Discrete Optimization II, Annals of Discrete Mathematics, vol. 5, pp. 287–326. Elsevier (1979). https://doi.org/10.1016/S0167-5060(08)70356-X
-
[18]
Journal of Algorithms5, 531–546 (1984)
Gurari, E.M., Sudborough, I.H.: Improved dynamic programming algorithms for bandwidth minimization and the MinCut linear arrangement problem. Journal of Algorithms5, 531–546 (1984). https://doi.org/10.1016/0196-6774(84)90006-3
-
[19]
Gurski, F., Rehs, C., Rethmann, J.: Knapsack problems: A parameterized point of view. Theor. Comput. Sci.775, 93–108 (2019). https://doi.org/10.1016/J.TCS. 2018.12.019
-
[20]
Journal of Computer and System Sciences79(1), 39–49 (2013)
Jansen, K., Kratsch, S., Marx, D., Schlotter, I.: Bin packing with fixed number of bins revisited. Journal of Computer and System Sciences79(1), 39–49 (2013). https://doi.org/10.1016/j.jcss.2012.04.004
-
[21]
Math- ematics of Operations Research8(4), 538–548 (1983)
Lenstra Jr, H.W.: Integer programming with a fixed number of variables. Math- ematics of Operations Research8(4), 538–548 (1983). https://doi.org/10.1287/ moor.8.4.538
1983
-
[22]
Leung, J.T., Vornberger, O., Witthoff, J.: On some variants of the bandwidth minimization problem. SIAM J. Comput.13(3), 650–667 (1984). https://doi.org/ 10.1137/0213040
-
[23]
Mallem, M.: Parameterized Complexity and New Efficient Enumerative Schemes for RCPSP. Ph.D. thesis, Sorbonne Université (Oct 2024), https://theses.hal. science/tel-04910718v1/file/146301_MALLEM_2024_archivage.pdf Scheduling with Precedence Delays: Shuffle Product and Directed Bandwidth 25
2024
-
[24]
Journal of Combinatorial Optimization51(3), 33 (2026)
Mallem, M., Hanen, C., Munier-Kordon, A.: Single machine scheduling with prece- dence constraints and bounded maximum delay value. Journal of Combinatorial Optimization51(3), 33 (2026). https://doi.org/10.1007/s10878-026-01411-w
-
[25]
Discrete Applied Mathematics5(1), 119–122 (1983)
Mansfield, A.: On the computational complexity of a merge recognition prob- lem. Discrete Applied Mathematics5(1), 119–122 (1983). https://doi.org/10.1016/ 0166-218X(83)90021-5
1983
-
[26]
ACM Transactions on Computation Theory9(4), 18:1–18:36 (2018)
Pilipczuk, M., Wrochna, M.: On space efficiency of algorithms working on struc- tural decompositions of graphs. ACM Transactions on Computation Theory9(4), 18:1–18:36 (2018). https://doi.org/10.1145/3154856
-
[27]
Rizzi,R.,Vialette,S.:Onrecognizingwordsthataresquaresfortheshuffleproduct. In: Bulatov, A.A., Shur, A.M. (eds.) Computer Science – Theory and Applications. pp. 235–245. Springer Berlin Heidelberg, Berlin, Heidelberg (2013). https://doi. org/10.1007/978-3-642-38536-0_21
-
[28]
SIAM Journal on Algebraic Discrete Methods1(4), 363–369 (1980)
Saxe, J.B.: Dynamic-programming algorithms for recognizing small-bandwidth graphs in polynomial time. SIAM Journal on Algebraic Discrete Methods1(4), 363–369 (1980). https://doi.org/10.1137/0601042
-
[29]
Journal of Computer and System Sciences10(3), 384–393 (1975)
Ullman, J.: NP-complete scheduling problems. Journal of Computer and System Sciences10(3), 384–393 (1975). https://doi.org/10.1016/S0022-0000(75)80008-0
-
[30]
Journal of Computer and System Sciences28(3), 345–358 (1984)
Warmuth, M.K., Haussler, D.: On the complexity of iterated shuffle. Journal of Computer and System Sciences28(3), 345–358 (1984). https://doi.org/10.1016/ 0022-0000(84)90018-7 A Unary Bin Packing In this appendix, we show the equivalence betweenUnary Bin Packingand single machine scheduling of (unary) chains of unit-time jobs with equal-length exact delay...
1984
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.