Recognition: 1 theorem link
· Lean TheoremCarbon-Aware Compute--Power Scheduling for AI Data Centers with Microgrid Prosumer Operations
Pith reviewed 2026-05-14 21:05 UTC · model grok-4.3
The pith
A joint MILP model for scheduling AI workloads and microgrid power operations raises total operational benefit while cutting emissions compared to separate baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a mixed-integer linear program that simultaneously optimizes heterogeneous AI workload placement and microgrid prosumer actions (local generation, storage, and bidirectional grid flows) delivers higher total operational benefit and lower emissions than either a compute-only scheduler or an energy-only scheduler on the same instances.
What carries the argument
The joint MILP formulation that treats rigid training jobs, elastic inference routing, local generation dispatch, battery state-of-charge, and carbon-budget tracking as coupled decision variables under power-balance and latency constraints.
If this is right
- Inference-routing flexibility accounts for a large share of the total value created by the joint schedule.
- Battery storage supplies useful time-shifting that improves both economics and emission outcomes.
- Sites with substantial local generation see larger gains from the joint approach than grid-dependent sites.
- The framework remains tractable for realistic numbers of jobs and time periods while respecting all listed constraints.
Where Pith is reading between the lines
- The same joint-model structure could be used to study how carbon budgets propagate across a fleet of data centers when some sites have different renewable profiles.
- Operators could test whether relaxing latency constraints on a subset of inference traffic further amplifies the reported benefits.
- The model offers a concrete way to quantify the grid-stabilization service that flexible AI loads could provide to utilities.
Load-bearing premise
The synthetic test cases used for experiments capture the main interactions between workload flexibility, prosumer energy operations, and the listed operational constraints well enough that the observed gains would appear on real systems.
What would settle it
Running the same joint model on actual operational traces from a multi-site AI operator and finding that the reported benefit and emission reductions disappear or reverse.
Figures
read the original abstract
AI data centers are increasingly becoming tightly coupled compute--energy systems, where workload placement, cooling demand, electricity procurement, storage operation, and carbon emissions interact over time. This paper studies carbon-aware compute--power scheduling for geographically distributed AI data centers with microgrid prosumer capabilities. We propose a mixed-integer linear programming (MILP) framework that jointly schedules rigid training jobs, routes elastic inference workloads, dispatches local generation and battery storage, and manages bidirectional grid interaction under latency, continuity, power-balance, and carbon-budget constraints. The model captures two key features of emerging AI infrastructure: heterogeneous workload flexibility and site-level energy prosumer operation. Experiments on synthetic yet practically motivated instances show that the proposed joint MILP substantially improves total operational benefit over compute-only and energy-only baselines while reducing emissions. The results further indicate that inference-routing flexibility is a major source of value, battery storage provides useful temporal flexibility, and local-generation-rich settings are particularly favorable. The framework provides a tractable optimization abstraction for sustainable and grid-interactive AI data centers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a mixed-integer linear programming (MILP) framework for carbon-aware joint scheduling of compute workloads (rigid training jobs and elastic inference) and power operations (local generation, battery storage, bidirectional grid interaction) in geographically distributed AI data centers with microgrid prosumer capabilities. The model incorporates constraints on latency, continuity, power balance, and carbon budgets. Experiments on synthetic yet practically motivated instances claim that the joint optimization substantially increases total operational benefit relative to compute-only and energy-only baselines while also reducing emissions, highlighting the value of inference routing flexibility and battery storage.
Significance. If the synthetic results generalize, the framework could provide a tractable optimization abstraction for AI data center operators to co-optimize economic performance and sustainability under carbon constraints and renewable integration. It addresses timely issues in grid-interactive computing by treating heterogeneous workload flexibility and site-level prosumer operations as coupled decisions.
major comments (1)
- [Experiments] Experiments section: The central claim of substantial improvements in operational benefit and emissions reduction rests entirely on synthetic instances generated from assumed distributions. No calibration against real data-center workload or energy traces is reported, nor is there out-of-sample testing on held-out operational data. This leaves open whether the observed gaps versus baselines would persist when workload-energy correlations, battery degradation, or tariff structures deviate from the modeled assumptions.
minor comments (2)
- [Abstract] Abstract: Including at least one concrete quantitative result (e.g., average percentage improvement in benefit or emission reduction) would better convey the magnitude of the claimed gains.
- [Model] Model formulation: Clarify the exact definition and units of the carbon-budget constraint and how it interacts with the objective weights; the current description leaves the scaling between benefit and emissions terms ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment regarding the experimental validation below and outline planned revisions to improve transparency.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim of substantial improvements in operational benefit and emissions reduction rests entirely on synthetic instances generated from assumed distributions. No calibration against real data-center workload or energy traces is reported, nor is there out-of-sample testing on held-out operational data. This leaves open whether the observed gaps versus baselines would persist when workload-energy correlations, battery degradation, or tariff structures deviate from the modeled assumptions.
Authors: We agree that our experiments rely exclusively on synthetic instances and do not include calibration against real data-center workload or energy traces, nor out-of-sample testing on held-out data. The instances were constructed using parameter distributions informed by publicly available industry reports, academic studies on AI workloads, renewable generation profiles, and electricity tariffs to reflect realistic operating conditions. We acknowledge that this leaves open questions about robustness to deviations in workload-energy correlations, battery degradation, or tariff structures. In the revised manuscript we will expand the Experiments section with a detailed description of the instance generation methodology (including all distributions and parameter sources) and add a dedicated Limitations subsection. This subsection will discuss the modeling assumptions, potential sensitivity to the factors raised by the referee, and the practical difficulties of obtaining synchronized real-world traces that capture both compute and microgrid operations at the required resolution. These changes will not alter the core results but will provide readers with a clearer basis for assessing generalizability. revision: partial
Circularity Check
No significant circularity in MILP formulation or experimental evaluation
full rationale
The paper proposes a new MILP optimization model that jointly schedules workloads, generation, storage, and grid interactions under explicit constraints. The claimed improvements in operational benefit and emissions are obtained by solving this model to optimality on synthetic instances; no equation reduces to a fitted parameter by construction, no prediction is statistically forced from a subset of data, and no load-bearing premise relies on self-citation chains. The derivation is therefore self-contained: the model definition plus the instance generator directly produce the reported outcomes without circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Objective weights for benefit versus emissions
axioms (1)
- domain assumption All relevant constraints (latency, continuity, power balance, carbon budget) can be expressed as linear or mixed-integer linear inequalities
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe propose a mixed-integer linear programming (MILP) framework that jointly schedules rigid training jobs, routes elastic inference workloads, dispatches local generation and battery storage...
Reference graph
Works this paper leans on
-
[1]
Cutting the electric bill for internet-scale systems,
A. Qureshi, R. Weber, H. Balakrishnan, J. Guttag, and B. Maggs, “Cutting the electric bill for internet-scale systems,” inProceedings of the ACM SIGCOMM 2009 Conference on Data Communication, 2009, pp. 123– 134
2009
-
[2]
Greening geographical load balancing,
Z. Liu, M. Lin, A. Wierman, S. H. Low, and L. L. H. Andrew, “Greening geographical load balancing,” inProceedings of the 2011 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, 2011, pp. 233–244
2011
-
[3]
Parasol and greenswitch: Managing datacenters powered by renewable energy,
I. nigo Goiri, W. Katsak, K. Le, T. D. Nguyen, and R. Bianchini, “Parasol and greenswitch: Managing datacenters powered by renewable energy,” inProceedings of the 18th International Conference on Architectural Support for Programming Languages and Operating Systems, 2013, pp. 51–64
2013
-
[4]
Review of energy efficiency and technological trends in data centers and power supply systems,
A. Khosraviet al., “Review of energy efficiency and technological trends in data centers and power supply systems,”Energy, 2024
2024
-
[5]
A model predictive control approach to microgrid operation optimization,
A. Parisio, E. Rikos, and L. Glielmo, “A model predictive control approach to microgrid operation optimization,”IEEE Transactions on Control Systems Technology, vol. 22, no. 5, pp. 1813–1827, 2014
2014
-
[6]
A review of energy management systems and organizational structures of prosumers,
N. Mišljenovi´c, M. Žnidarec, G. Kneževi ´c, D. Šljivac, and A. Sumper, “A review of energy management systems and organizational structures of prosumers,”Energies, vol. 16, no. 7, p. 3179, 2023
2023
-
[7]
Cost-effective operation of microgrids: A MILP-based energy management system for active and reactive power control,
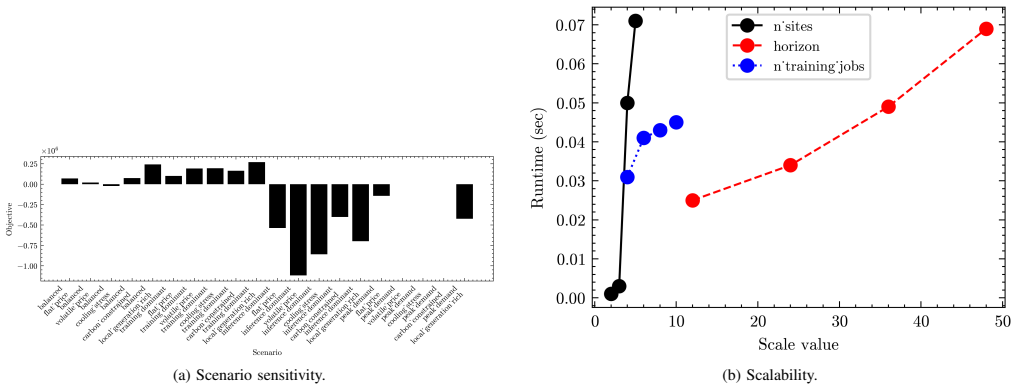
S. García, S. Bracco, A. Parejo, M. Fresia, J. I. Guerrero, and C. León, “Cost-effective operation of microgrids: A MILP-based energy management system for active and reactive power control,”International Journal of Electrical Power & Energy Systems, vol. 165, p. 110458, 2025. (a) Scenario sensitivity. (b) Scalability. Fig. 1. Sensitivity and scalability ...
2025
-
[8]
Gandiva: Introspective cluster scheduling for deep learning,
W. Xiao, R. Bhardwaj, R. Ramjee, M. Sivathanu, N. Kwatra, Z. Han, P. Patel, X. Peng, H. Zhao, Q. Zhang, F. Yang, and L. Zhou, “Gandiva: Introspective cluster scheduling for deep learning,” in13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). USENIX Association, 2018, pp. 595–610
2018
-
[9]
Tiresias: A GPU cluster manager for distributed deep learning,
J. Gu, M. Chowdhury, K. G. Shin, Y . Zhu, M. Jeon, J. Qian, H. Liu, and C. Guo, “Tiresias: A GPU cluster manager for distributed deep learning,” in16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19). USENIX Association, 2019, pp. 485– 500
2019
-
[10]
Deep learning workload scheduling in gpu datacenters: A survey,
Z. Yeet al., “Deep learning workload scheduling in gpu datacenters: A survey,”ACM Computing Surveys, vol. 56, no. 6, pp. 146:1–146:38, 2024
2024
-
[11]
MAST: Global scheduling of ML training across geo-distributed datacenters at hyperscale,
A. Choudhury, Y . Wang, T. Pelkonen, K. Srinivasan, A. Jain, S. Lin, D. David, S. Soleimanifard, M. Chen, A. Yadav, R. Tijoriwala, D. Samoylov, and C. Tang, “MAST: Global scheduling of ML training across geo-distributed datacenters at hyperscale,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, 2024, p...
2024
-
[12]
Online 3d printing remote monitoring and control system based on internet of things and cloud platform,
H. Guo, Z. Huo, R. Zhang, T. Qu, C. Li, B. Chao, X. Luo, and Z. He, “Online 3d printing remote monitoring and control system based on internet of things and cloud platform,” inProceedings of the 25th International Conference on Industrial Engineering and Engineering Management, 2020
2020
-
[13]
Sustainable quality control mechanism of heavy truck production process for plant-wide production process,
H. Guo, R. Zhang, Y . Zhu, T. Qu, M. Zou, X. Chen, Y . Ren, and Z. He, “Sustainable quality control mechanism of heavy truck production process for plant-wide production process,”International Journal of Production Research, vol. 58, no. 24, pp. 7548–7564, 2020
2020
-
[14]
Research on task pricing of self-service platform of product-service system,
H. Guo, R. Zhang, Z. Lin, T. Qu, G. Huang, J. Shi, M. Chen, H. Gu, C. Deng, and J. Li, “Research on task pricing of self-service platform of product-service system,” inProcedia CIRP, vol. 83, 2019, pp. 380–383
2019
-
[15]
An approach to discovering product/service improvement priorities: Using dynamic importance- performance analysis,
J. Wu, Y . Wang, R. Zhang, and J. Cai, “An approach to discovering product/service improvement priorities: Using dynamic importance- performance analysis,”Sustainability, vol. 10, no. 10, p. 3564, 2018
2018
-
[16]
Carbon-aware load balancing for geo-distributed cloud services,
Z. Zhou, F. Liu, Z. Li, H. Jin, and B. Li, “Carbon-aware load balancing for geo-distributed cloud services,” in2013 IEEE 21st International Symposium on Modelling, Analysis and Simulation of Computer and Telecommunication Systems, 2013, pp. 232–241
2013
-
[17]
Carbon-aware computing for datacenters,
A. Radovanovic, R. Koningstein, I. Schneider, B. Chen, A. Duarte, B. Roy, D. Xiao, M. Haridasan, P. Hung, N. Care, S. Talukdar, E. Mullen, K. Smith, M. Cottman, and W. Cirne, “Carbon-aware computing for datacenters,”IEEE Transactions on Power Systems, vol. 38, no. 2, pp. 1270–1280, 2023
2023
-
[18]
Carbon explorer: A holistic framework for designing carbon aware datacenters,
B. Acun, B. Lee, F. Kazhamiaka, K. Maeng, U. Gupta, M. Chakkaravarthy, D. Brooks, and C.-J. Wu, “Carbon explorer: A holistic framework for designing carbon aware datacenters,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 2, 2023, pp. 118–132
2023
-
[19]
Clover: Toward sustainable ai with carbon-aware machine learning inference service,
B. Li, S. Samsi, V . Gadepally, and D. Tiwari, “Clover: Toward sustainable ai with carbon-aware machine learning inference service,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2023, pp. 1–15
2023
-
[20]
J. R. Zhang, X. Mi, G. Du, Q. Sun, S. Wang, J. Li, and W. Zhou, “A universal banach–bregman framework for stochastic iterations: Unifying stochastic mirror descent, learning and llm training,”arXiv preprint arXiv:2509.14216, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.