Recognition: unknown
Enhancing Visual Question Answering with Multimodal LLMs via Chain-of-Question Guided Retrieval-Augmented Generation
Pith reviewed 2026-05-07 17:43 UTC · model grok-4.3
The pith
A prompting strategy that fuses chain-of-thought with question decomposition guides retrieval to improve multimodal LLMs on visual question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that introducing CoVQD, a fusion of Chain-of-Thought reasoning with Visual Question Decomposition, to guide retrieval-augmented generation enables MLLMs to access more comprehensive and coherent external knowledge while benefiting from structured visual-text reasoning guidance, thereby improving generalization and reliability in complex cross-domain VQA scenarios.
What carries the argument
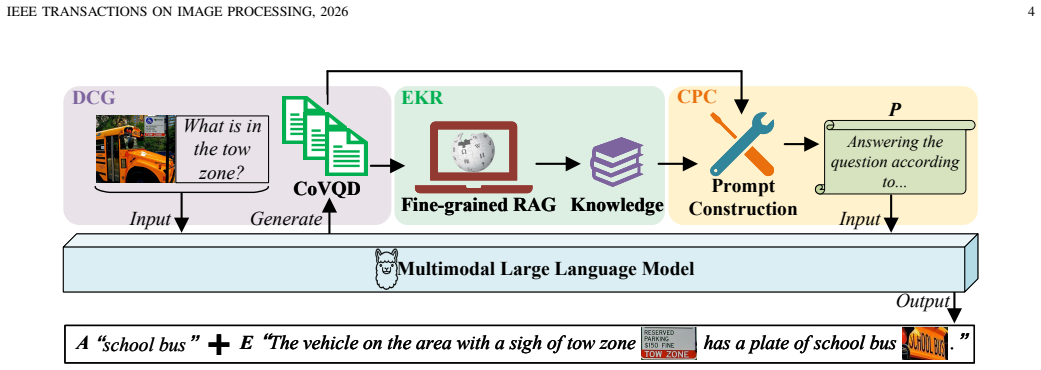
The CoVQD prompting strategy, which fuses Chain-of-Thought reasoning with Visual Question Decomposition to guide retrieval in a retrieval-augmented generation framework for multimodal large language models.
Load-bearing premise
Fusing Chain-of-Thought with Visual Question Decomposition will reliably steer retrieval toward accurate and relevant external knowledge without introducing decomposition errors or irrelevant retrieved content that harms the final model output.
What would settle it
A direct comparison on the OKVQA or InfoSeek benchmarks in which the full framework performs no better than or worse than a baseline retrieval-augmented generation setup without the CoVQD guidance would falsify the central claim.
Figures







read the original abstract
With advances in multimodal research and deep learning, Multimodal Large Language Models (MLLMs) have emerged as a powerful paradigm for a wide range of multimodal tasks. As a core problem in vision-language research, Visual Question Answering (VQA) has increasingly employed MLLMs to improve performance, particularly in open-domain settings where external knowledge is essential. In this work, we aim to further enhance retrieval-based VQA by more effectively integrating MLLMs with structured reasoning and knowledge acquisition. We introduce a logical prompting strategy that fuses Chain-of-Thought (CoT) reasoning with Visual Question Decomposition (VQD), termed CoVQD, to guide retrieval toward more accurate and relevant knowledge for MLLM inference. Building on this idea, we propose a new framework, CoVQD-guided RAG (CgRAG), which enables MLLMs to access more comprehensive and coherent external knowledge while benefiting from structured visual-text reasoning guidance, thereby improving generalization and reliability in complex cross-domain VQA scenarios. Extensive experiments on E-VQA, InfoSeek, and OKVQA benchmarks demonstrate the effectiveness of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoVQD, a logical prompting strategy fusing Chain-of-Thought (CoT) reasoning with Visual Question Decomposition (VQD), and builds the CgRAG framework on top of it to guide retrieval-augmented generation for multimodal LLMs in visual question answering. The central claim is that this structured visual-text reasoning guidance enables MLLMs to retrieve more comprehensive and coherent external knowledge, thereby improving generalization and reliability on complex cross-domain VQA tasks, with effectiveness shown via experiments on the E-VQA, InfoSeek, and OKVQA benchmarks.
Significance. If the empirical claims are substantiated with quantitative results and controls, the work could offer a practical way to combine explicit reasoning chains with external retrieval in MLLMs, addressing a real limitation in open-domain VQA where knowledge is required. The approach is timely given the growing use of MLLMs for knowledge-intensive multimodal tasks.
major comments (2)
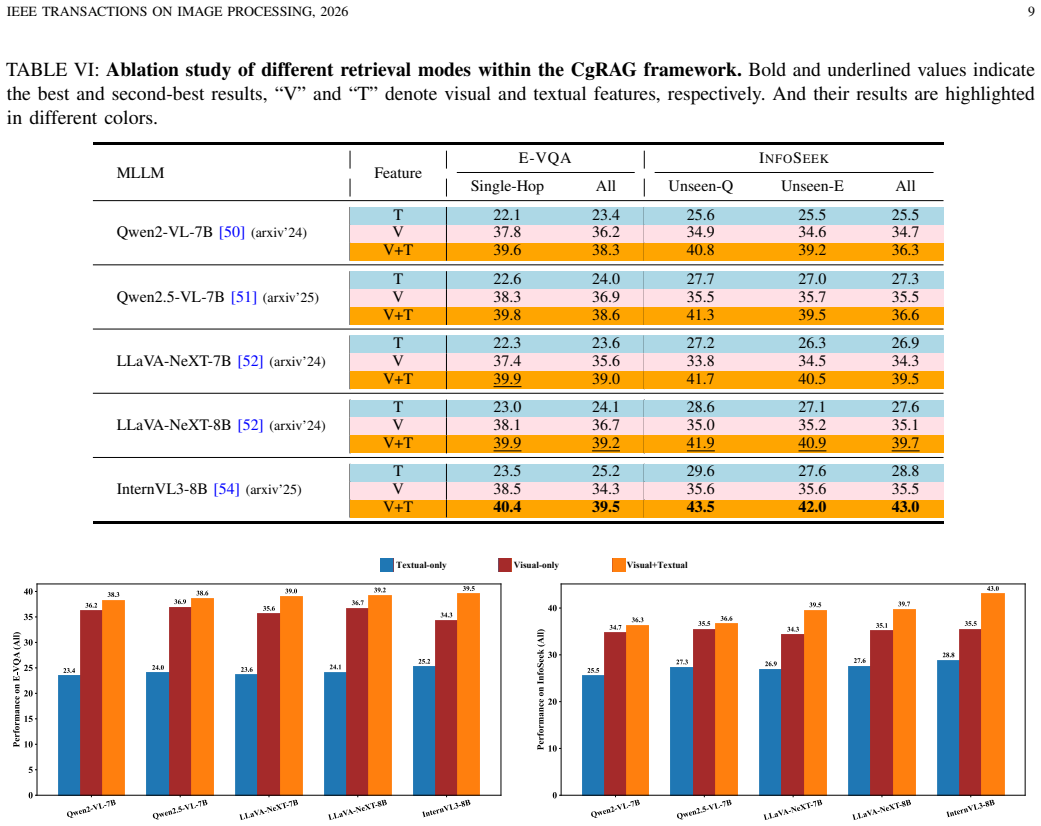
- [Abstract] Abstract: The manuscript asserts that 'extensive experiments on E-VQA, InfoSeek, and OKVQA benchmarks demonstrate the effectiveness' of CgRAG yet supplies no quantitative results, baselines, ablation studies, or error analysis. This is load-bearing for the central claim because the asserted gains over standard RAG or plain CoT cannot be evaluated without those data; the skeptic concern that VQD decomposition errors may retrieve off-topic or contradictory passages is left unaddressed.
- [Abstract] Abstract: No mechanism is described for filtering or mitigating irrelevant or contradictory passages that could be retrieved when CoVQD sub-questions contain errors (a known risk in visual question decomposition). Without such a safeguard or validation of sub-question quality, the claim that the fusion 'guides retrieval toward more accurate and relevant knowledge' rests on an untested assumption.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have made revisions to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that 'extensive experiments on E-VQA, InfoSeek, and OKVQA benchmarks demonstrate the effectiveness' of CgRAG yet supplies no quantitative results, baselines, ablation studies, or error analysis. This is load-bearing for the central claim because the asserted gains over standard RAG or plain CoT cannot be evaluated without those data; the skeptic concern that VQD decomposition errors may retrieve off-topic or contradictory passages is left unaddressed.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The detailed experimental results, baseline comparisons, ablation studies, and error analysis are presented in Sections 4 and 5 of the manuscript. We will revise the abstract to report specific performance gains on E-VQA, InfoSeek, and OKVQA (e.g., accuracy improvements relative to standard RAG and CoT baselines) to make the central claims more self-contained. revision: yes
-
Referee: [Abstract] Abstract: No mechanism is described for filtering or mitigating irrelevant or contradictory passages that could be retrieved when CoVQD sub-questions contain errors (a known risk in visual question decomposition). Without such a safeguard or validation of sub-question quality, the claim that the fusion 'guides retrieval toward more accurate and relevant knowledge' rests on an untested assumption.
Authors: This is a fair observation. The current version of the manuscript does not explicitly describe a filtering or mitigation mechanism for erroneous sub-questions in the abstract or methods overview. We will revise the paper to add a relevance-thresholding step and passage reranking in the CgRAG retrieval module, include a brief description of this safeguard in the abstract, and report sub-question quality validation results in the experiments section. revision: yes
Circularity Check
No circularity: architectural framework validated on external benchmarks
full rationale
The paper proposes an architectural framework (CgRAG) that fuses CoT with VQD to guide RAG for MLLM-based VQA. All performance claims are measured against independent external benchmarks (E-VQA, InfoSeek, OKVQA) with no internal equations, fitted parameters, or self-referential definitions that reduce the reported gains to quantities defined by the method itself. No load-bearing step collapses by construction to prior self-citations or ansatzes; the derivation chain consists of design choices whose value is asserted via empirical comparison rather than algebraic identity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The chosen benchmarks (E-VQA, InfoSeek, OKVQA) are valid proxies for complex cross-domain VQA performance.
- domain assumption Structured CoT+VQD prompting produces retrieval queries that are more accurate and relevant than unguided retrieval.
invented entities (2)
-
CoVQD
no independent evidence
-
CgRAG
no independent evidence
Reference graph
Works this paper leans on
-
[1]
StoryLLaV A: enhancing visual storytelling with multi-modal large language models,
L. Yang, Z. Xiao, W. Huang, and X. Zhong, “StoryLLaV A: enhancing visual storytelling with multi-modal large language models,” inProc. Int. Conf. Comput. Linguistics, pp. 3936–3951, 2025
2025
-
[2]
Refined semantic enhancement towards frequency diffusion for video captioning,
X. Zhong, Z. Li, S. Chen, K. Jiang, C. Chen, and M. Ye, “Refined semantic enhancement towards frequency diffusion for video captioning,” inProc. AAAI Conf. Artif. Intell., pp. 3724–3732, 2023
2023
-
[3]
Action-aware linguistic skeleton optimization network for non-autoregressive video captioning,
S. Chen, X. Zhong, Y . Zhang, L. Zhu, P. Li, X. Yang, and B. Sheng, “Action-aware linguistic skeleton optimization network for non-autoregressive video captioning,”ACM Trans. Multimedia Comput. Commun. Appl., vol. 20, no. 10, pp. 326:1–326:24, 2024
2024
-
[4]
VQA: visual question answering,
S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, “VQA: visual question answering,” inProc. IEEE/CVF Int. Conf. Comput. Vis., pp. 2425–2433, 2015
2015
-
[5]
Making the V in VQA matter: Elevating the role of image understanding in visual question answering,
Y . Goyal, T. Khot, A. Agrawal, D. Summers-Stay, D. Batra, and D. Parikh, “Making the V in VQA matter: Elevating the role of image understanding in visual question answering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 6904–6913, 2017
2017
-
[6]
KVQA: knowledge- aware visual question answering,
S. Shah, A. Mishra, N. Yadati, and P. P. Talukdar, “KVQA: knowledge- aware visual question answering,” inProc. AAAI Conf. Artif. Intell., pp. 8876–8884, 2019
2019
-
[7]
Augmenting multimodal LLMs with self-reflective tokens for knowledge- based visual question answering,
F. Cocchi, N. Moratelli, M. Cornia, L. Baraldi, and R. Cucchiara, “Augmenting multimodal LLMs with self-reflective tokens for knowledge- based visual question answering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 9199–9209, 2025
2025
-
[8]
Fine-grained retrieval- augmented generation for visual question answering,
Z. Zhang, Y . Wu, Y . Luo, and N. Tang, “Fine-grained retrieval- augmented generation for visual question answering,”arXiv preprint arXiv:2502.20964, 2025
-
[9]
MMKB-RAG: a multi-modal knowledge-based retrieval- augmented generation framework,
Z. Ling, Z. Guo, Y . Huang, Y . An, S. Xiao, J. Lan, X. Zhu, and B. Zheng, “MMKB-RAG: a multi-modal knowledge-based retrieval- augmented generation framework,”arXiv preprint arXiv:2504.10074, 2025
-
[10]
Knowledge-based visual question answer with multimodal processing, retrieval and filtering,
Y . Hong, J. Gu, Q. Yang, L. Fan, Y . Wu, Y . Wang, K. Ding, S. Xiang, and J. Ye, “Knowledge-based visual question answer with multimodal processing, retrieval and filtering,”arXiv preprint arXiv:2510.14605, 2025
-
[11]
Idealgpt: Iteratively decomposing vision and language reasoning via large language models,
H. You, R. Sun, Z. Wang, L. Chen, G. Wang, H. A. Ayyubi, K.-W. Chang, and S.-F. Chang, “Idealgpt: Iteratively decomposing vision and language reasoning via large language models,” inFindings EMNLP, pp. 11289–11303, 2023
2023
-
[12]
The art of SOCRATIC questioning: Recursive thinking with large language models,
J. Qi, Z. Xu, Y . Shen, M. Liu, D. Jin, Q. Wang, and L. Huang, “The art of SOCRATIC questioning: Recursive thinking with large language models,” inProc. Conf. Empir . Methods Nat. Lang. Process., pp. 4177–4199, 2023
2023
-
[13]
Chatterbox: Multimodal referring and grounding with chain-of-questions,
Y . Tian, T. Ma, L. Xie, and Q. Ye, “Chatterbox: Multimodal referring and grounding with chain-of-questions,” inProc. AAAI Conf. Artif. Intell., pp. 7401–7409, 2025
2025
-
[14]
Perception tokens enhance visual reasoning in multimodal language models,
M. Bigverdi, Z. Luo, C.-Y . Hsieh, E. Shen, D. Chen, L. G. Shapiro, and R. Krishna, “Perception tokens enhance visual reasoning in multimodal language models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 3836–3845, 2025
2025
-
[15]
Wiki-llava: Hierarchical retrieval-augmented generation for multimodal LLMs,
D. Caffagni, F. Cocchi, N. Moratelli, S. Sarto, M. Cornia, L. Baraldi, and R. Cucchiara, “Wiki-llava: Hierarchical retrieval-augmented generation for multimodal LLMs,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, pp. 1818–1826, 2024
2024
-
[16]
arXiv preprint arXiv:2410.08876 (2024),https://arxiv.org/abs/2410.08876
J. Qi, Z. Xu, R. Shao, Y . Chen, D. Jin, Y . Cheng, Q. Wang, and L. Huang, “Rora-vlm: Robust retrieval-augmented vision language models,”arXiv preprint arXiv:2410.08876, 2024
-
[17]
Echosight: Advancing visual-language models with wiki knowledge,
Y . Yan and W. Xie, “Echosight: Advancing visual-language models with wiki knowledge,” inFindings EMNLP, pp. 1538–1551, 2024
2024
-
[18]
Playing Atari with Deep Reinforcement Learning
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wier- stra, and M. A. Riedmiller, “Playing atari with deep reinforcement learning,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review arXiv 2013
-
[19]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
Y . Yang, X. He, H. Pan, X. Jiang, Y . Deng, X. Yang, H. Lu, D. Yin, F. Rao, M. Zhu, B. Zhang, and W. Chen, “R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization,” arXiv preprint arXiv:2503.10615, 2025
-
[21]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inProc. Adv. Neural Inf. Process. Syst., 2023
2023
-
[23]
Towards more faithful natural language explanation using multi-level contrastive learning in VQA,
C. Lai, S. Song, S. Meng, J. Li, S. Yan, and G. Hu, “Towards more faithful natural language explanation using multi-level contrastive learning in VQA,” inProc. AAAI Conf. Artif. Intell., pp. 2849–2857, 2024
2024
-
[24]
Few-shot multimodal explanation for visual question answering,
D. Xue, S. Qian, and C. Xu, “Few-shot multimodal explanation for visual question answering,” inProc. ACM Int. Conf. Multimedia, pp. 1875–1884, 2024
2024
-
[25]
An empirical study of GPT-3 for few-shot knowledge-based VQA,
Z. Yang, Z. Gan, J. Wang, X. Hu, Y . Lu, Z. Liu, and L. Wang, “An empirical study of GPT-3 for few-shot knowledge-based VQA,” inProc. AAAI Conf. Artif. Intell., pp. 3081–3089, 2022
2022
-
[26]
Exploring question decomposition for zero-shot VQA,
Z. Khan, V . K. B. G, S. Schulter, M. Chandraker, and Y . Fu, “Exploring question decomposition for zero-shot VQA,” inProc. Int. Conf. Neural Inf. Process. Syst., 2023
2023
-
[27]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Am...
2020
-
[28]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 26286–26296, 2024
2024
-
[29]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond,”arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review arXiv 2023
-
[30]
Visual question decomposition on multimodal large language models,
H. Zhang, J. Liu, Z. Han, S. Chen, B. He, V . Tresp, Z. Xu, and J. Gu, “Visual question decomposition on multimodal large language models,” inFindings EMNLP, pp. 1926–1949, 2024
1926
-
[31]
Logical impli- cations for visual question answering consistency,
S. Tascon-Morales, P. Márquez-Neila, and R. Sznitman, “Logical impli- cations for visual question answering consistency,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 6725–6735, 2023
2023
-
[32]
BERT: pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” inProc. Conf. North Amer . Chapter Assoc. Comput. Linguistics: Hum. Lang. Technol., pp. 4171–4186, 2019
2019
-
[33]
Scaling laws for reward model overoptimization,
L. Gao, J. Schulman, and J. Hilton, “Scaling laws for reward model overoptimization,” inProc. Int. Conf. Mach. Learn., pp. 10835–10866, 2023
2023
-
[34]
Rank analysis of incomplete block designs: I. the method of paired comparisons,
R. A. Bradley and M. E. Terry, “Rank analysis of incomplete block designs: I. the method of paired comparisons,”Biometrika, vol. 39, no. 3/4, pp. 324–345, 1952
1952
-
[35]
mDPO: conditional preference optimization for multimodal large language models,
F. Wang, W. Zhou, J. Y . Huang, N. Xu, S. Zhang, H. Poon, and M. Chen, “mDPO: conditional preference optimization for multimodal large language models,” inProc. Conf. Empir . Methods Nat. Lang. Process., pp. 8078–8088, 2024
2024
-
[36]
Evaluating and mitigating object hallucination in large vision- language models: Can they still see removed objects?,
Y . He, H. Sun, P. Ren, J. Wang, H. Wang, Q. Qi, Z. Zhuang, and J. Wang, “Evaluating and mitigating object hallucination in large vision- language models: Can they still see removed objects?,” inProc. Conf. North Amer . Chapter Assoc. Comput. Linguistics: Hum. Lang. Technol., pp. 6841–6858, 2025
2025
-
[37]
Vinvl: Revisiting visual representations in vision-language models,
P. Zhang, X. Li, X. Hu, J. Yang, L. Zhang, L. Wang, Y . Choi, and J. Gao, “Vinvl: Revisiting visual representations in vision-language models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 5579–5588, 2021
2021
-
[38]
BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. C. H. Hoi, “BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models,” inProc. Int. Conf. Mach. Learn., pp. 19730–19742, 2023
2023
-
[39]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” inProc. Int. Conf. Mach. Learn., pp. 8748–8763, 2021
2021
-
[40]
BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. C. H. Hoi, “BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation,” inProc. Int. Conf. Mach. Learn., vol. 162, pp. 12888– 12900, 2022
2022
-
[41]
OK-VQA: a visual question answering benchmark requiring external knowledge,
K. Marino, M. Rastegari, A. Farhadi, and R. Mottaghi, “OK-VQA: a visual question answering benchmark requiring external knowledge,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 3195–3204, 2019
2019
-
[42]
Encyclopedic VQA: visual questions about detailed properties of fine-grained categories,
T. Mensink, J. R. R. Uijlings, L. Castrejón, A. Goel, F. Cadar, H. Zhou, F. Sha, A. Araújo, and V . Ferrari, “Encyclopedic VQA: visual questions about detailed properties of fine-grained categories,” inProc. IEEE/CVF Int. Conf. Comput. Vis., pp. 3090–3101, 2023. IEEE TRANSACTIONS ON IMAGE PROCESSING, 2026 12
2023
-
[43]
Can pre-trained vision and language models answer visual information-seeking questions?,
Y . Chen, H. Hu, Y . Luan, H. Sun, S. Changpinyo, A. Ritter, and M.- W. Chang, “Can pre-trained vision and language models answer visual information-seeking questions?,” inProc. Conf. Empir . Methods Nat. Lang. Process., pp. 14948–14968, 2023
2023
-
[44]
Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities,
H. Hu, Y . Luan, Y . Chen, U. Khandelwal, M. Joshi, K. Lee, K. Toutanova, and M.-W. Chang, “Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities,” inProc. IEEE/CVF Int. Conf. Comput. Vis., pp. 12031–12041, 2023
2023
-
[45]
REX: reasoning-aware and grounded explanation,
S. Chen and Q. Zhao, “REX: reasoning-aware and grounded explanation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 15565– 15574, 2022
2022
-
[46]
GQA: a new dataset for real- world visual reasoning and compositional question answering,
D. A. Hudson and C. D. Manning, “GQA: a new dataset for real- world visual reasoning and compositional question answering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 6700–6709, 2019
2019
-
[47]
Roses are red, violets are blue... but should VQA expect them to?,
C. Kervadec, G. Antipov, M. Baccouche, and C. Wolf, “Roses are red, violets are blue... but should VQA expect them to?,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 2776–2785, 2021
2021
-
[48]
Instructblip: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. C. H. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,” inProc. Adv. Neural Inf. Process. Syst., 2023
2023
-
[49]
OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman,et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review arXiv 2024
-
[50]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, “Qwen2-VL: enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review arXiv 2024
-
[51]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang,et al., “Qwen2.5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review arXiv 2025
-
[52]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
F. Li, R. Zhang, H. Zhang, Y . Zhang, B. Li, W. Li, Z. Ma, and C. Li, “LLaV A-NeXT-Interleave: tackling multi-image, video, and 3D in large multimodal models,”arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review arXiv 2024
-
[53]
Cross-modal retrieval for knowledge-based visual question answering,
P. Lerner, O. Ferret, and C. Guinaudeau, “Cross-modal retrieval for knowledge-based visual question answering,” inProc. Eur . Conf. Inf. Retr ., pp. 421–438, 2024
2024
-
[54]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shao,et al., “Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models,”arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review arXiv 2025
-
[55]
A large annotated corpus for learning natural language inference,
S. R. Bowman, G. Angeli, C. Potts, and C. D. Manning, “A large annotated corpus for learning natural language inference,” inProc. Conf. Empir . Methods Nat. Lang. Process., pp. 632–642, 2015
2015
-
[56]
Squinting at VQA models: Introspecting VQA models with sub-questions,
R. R. Selvaraju, P. Tendulkar, D. Parikh, E. Horvitz, M. T. Ribeiro, B. Nushi, and E. Kamar, “Squinting at VQA models: Introspecting VQA models with sub-questions,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 10000–10008, 2020
2020
-
[57]
VQA-E: explaining, elaborating, and enhancing your answers for visual questions,
Q. Li, Q. Tao, S. R. Joty, J. Cai, and J. Luo, “VQA-E: explaining, elaborating, and enhancing your answers for visual questions,” inProc. Eur . Conf. Comput. Vis., vol. 11211, pp. 570–586, 2018
2018
-
[58]
Faithful multimodal explanation for visual question answering,
J. Wu and R. J. Mooney, “Faithful multimodal explanation for visual question answering,” inProc. ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 103–112, 2019
2019
-
[59]
Variational causal inference network for explanatory visual question answering,
D. Xue, S. Qian, and C. Xu, “Variational causal inference network for explanatory visual question answering,” inProc. IEEE/CVF Int. Conf. Comput. Vis., pp. 2515–2525, 2023
2023
-
[60]
Multimodal rationales for explainable visual question answering,
K. Li, G. V osselman, and M. Y . Yang, “Multimodal rationales for explainable visual question answering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, pp. 191–201, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.